TextBlob机器翻译潜力:初步探索与实践技巧
发布时间: 2024-10-04 19:43:21 阅读量: 6 订阅数: 7 

# 1. TextBlob机器翻译概述
TextBlob是一个强大的文本处理库,它不仅提供了丰富的文本分析功能,还内置了机器翻译能力,使得开发者能够方便快捷地进行自然语言处理(NLP)和翻译任务。本章将带您了解TextBlob的起源、发展以及它与机器翻译领域的联系。
## 2.1 TextBlob的简介与优势
### 2.1.1 TextBlob的起源与发展
TextBlob诞生于2013年,由Steven Loria等人发起,旨在简化NLP任务,并提供易于使用的接口。它基于NLTK(Natural Language Toolkit)和Pattern两个库,从而继承了大量强大的NLP功能。TextBlob经过多年的演进,已经成为初学者和专业人士广泛使用的工具。
### 2.1.2 TextBlob与机器翻译的关系
TextBlob的机器翻译功能基于Google翻译API,因此它能够提供较为准确和流畅的翻译结果。虽然在深度学习大行其道的今天,TextBlob可能在翻译准确度上不如一些先进的深度学习模型,但它仍然凭借其易用性和灵活性,保持了在快速原型设计和小规模应用中的吸引力。
# 2. TextBlob的文本分析功能
### 词性标注与命名实体识别
词性标注(Part-of-Speech Tagging, POS Tagging)是将文本中的每个词标记为对应的词性,如名词、动词、形容词等。TextBlob库利用一套预先定义的词性标注集来执行这项功能,通过内置的自然语言处理算法为文本中的每个单词分配词性标签。这些标签可以为后续的文本处理提供丰富信息。
命名实体识别(Named Entity Recognition, NER)是指识别文本中具有特定意义的实体,例如人名、地名、组织名、时间表达等。TextBlob同样提供了一系列的命名实体识别功能,能够从给定的文本中提取这些实体信息。
在使用TextBlob进行词性标注和命名实体识别时,代码示例如下:
```python
from textblob import TextBlob
blob = TextBlob("Barack Obama was born in Hawaii. Google was founded by Larry Page and Sergey Brin while they were Ph.D. students at Stanford University.")
print(blob.tags)
print(blob.noun_phrases)
```
#### 代码逻辑分析与参数说明
- 首先,我们从 `textblob` 模块导入 `TextBlob` 类。
- 接着创建一个 `TextBlob` 对象,传入需要处理的文本字符串。
- 使用 `blob.tags` 属性获取文本的词性标注结果。
- 使用 `blob.noun_phrases` 属性获取文本中的名词短语。
执行上述代码后,我们可以得到每个单词的词性标注序列,以及文本中的名词短语。
### 句法分析与依赖解析
句法分析(Syntactic Analysis)是指分析句子中词汇之间的结构和语法关系,而依赖解析(Dependency Parsing)则是关注词与词之间的依存关系,构建出一个句子的依存结构树。在自然语言处理中,句法分析与依赖解析是理解句子结构和含义的重要步骤。
TextBlob使用了`pattern.en`包中的句法分析器来执行这些功能。通过调用 `blob.parse()` 方法,可以获取一个句法树对象,该对象提供了关于句子结构的详细信息。具体实现代码示例如下:
```python
from textblob import TextBlob
blob = TextBlob("The quick brown fox jumps over the lazy dog.")
tree = blob.parse()
print(tree)
```
#### 代码逻辑分析与参数说明
- 同样首先导入 `TextBlob` 类。
- 创建 `TextBlob` 对象,并传入待解析的文本。
- 调用 `blob.parse()` 方法获取句法树对象 `tree`。
- 打印出树状结构的句法分析结果。
运行该代码后,输出的句法树将展示句子中每个单词的依存关系,例如主语、谓语、宾语等,以及它们之间的依赖关系。
TextBlob的这些文本分析功能是构建在NLTK(Natural Language Toolkit)等自然语言处理工具之上的,简化了用户处理自然语言的过程。而其内部算法对于大多数语言分析任务来说已经足够强大,可以为开发者节省大量开发时间。在下一节中,我们将进一步探讨TextBlob在机器翻译中的应用和实践。
# 3. TextBlob文本处理与翻译实践
在本章节中,我们将深入了解TextBlob的文本处理能力,并展示如何将这些功能应用于实际的机器翻译任务中。我们会探讨TextBlob文本分析的核心功能,包括词性标注与命名实体识别以及句法分析与依赖解析。之后,我们将讨论如何运用TextBlob进行基本翻译,并对高级翻译技巧进行探究,以实现翻译质量的提升。最后,我们还会学习如何评估翻译结果,确保输出的翻译达到所需的质量标准。
## 3.1 TextBlob的文本分析功能
TextBlob不仅支持基础的文本翻译,还提供了强大的文本分析功能。这些功能可以帮助开发者更深入地理解文本内容,从而提高翻译的准确度和自然度。
### 3.1.1 词性标注与命名实体识别
词性标注(Part-of-Speech Tagging)和命名实体识别(Named Entity Recognition, NER)是自然语言处理中非常重要的步骤。TextBlob通过其内置的`nltk`库实现了这两种功能,能够识别文本中的单词类别(如名词、动词等)以及关键实体(如人名、地点名等)。
#### 代码块示例:
```python
from textblob import TextBlob
blob = TextBlob("Barack Obama was born in Hawaii.")
print(blob.tags)
print(blob.noun_phrases)
```
#### 输出解释:
```plaintext
[('Barack', 'NNP'), ('Obama', 'NNP'), ('was', 'VBD'), ('born', 'VBN'), ('in', 'IN'), ('Hawaii', 'NNP')]
['Barack Obama', 'Hawaii']
```
**逻辑分析与参数说明:**
- `TextBlob` 对象创建了一个包含文本的实例。
- 使用 `tags` 属性获取文本的词性标注结果。
- 使用 `noun_phrases` 属性提取文本中的命名实体。
词性标注结果展示了每个单词的词性缩写,例如 'NNP' 表示专有名词。名词短语的提取则帮助我们识别出文本中的关键实体。
### 3.1.2 句法分析与依赖解析
TextBlob的句法分析功能可以帮助我们理解句子中的单词是如何相互关联的。TextBlob通过解析句子的依赖关系,提供了一个清晰的语法结构视图。
#### 代码块示例:
```python
from textblob import TextBlob
blob = TextBlob("TextBlob is a Python library for processing textual data.")
print(blob.sentences[0].parse())
```
#### 输出示例:
```
(S
(NP Alice)
(VP
(VP (VBK is)
(ADJP (JJ a) (JJ simple) (NN toolchain)))
(PP (IN for)
(NP (NN data) (NNS scientists))))
(. .))
```
**逻辑分析与参数说明:**
- `TextBlob` 对象被创建并包含了一段文本。
- `sentences[0].parse()` 方法返回了第一个句子的解析结果。
- 输出的结果是依存树状结构,反映了句子内部的语法关系。
这个解析结果可以帮助开发者了解文本的深层语义结构,为翻译工作提供重要的语法信息。
## 3.2 TextBlob机器翻译实践
TextBlob的机器翻译功能是其最受欢迎的特点之一。它提供了一种简单直接的方法来进行文本的翻译工作。
### 3.2.1 基本翻译功能的使用
TextBlob允许用户直接翻译任何给定的字符串到多种语言。它默认使用Google的翻译A

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python并发编程新高度

# 1. Python并发编程概述
在计算机科学中,尤其是针对需要大量计算和数据处理的场景,提升执行效率是始终追求的目标。Python作为一门功能强大、应用广泛的编程语言,在处理并发任务时也展现了其独特的优势。并发编程通过允许多个进程或线程同时执行,可以显著提高程序的运行效率,优化资源的使用,从而满足现代应用程序日益增长的性能需求。
在本章中,我们将探讨Python并发编程的基础知识,为理解后续章节的高级并发技术打下坚实的基础
sgmllib源码深度剖析:构造器与析构器的工作原理

# 1. sgmllib源码解析概述
Python的sgmllib模块为开发者提供了一个简单的SGML解析器,它可用于处理HTML或XML文档。通过深入分析sgmllib的源代码,开发者可以更好地理解其背后的工作原理,进而在实际工作中更有效地使用这一工具。
## 1.1 sgmllib的使用场景
NLTK与其他NLP库的比较:NLTK在生态系统中的定位
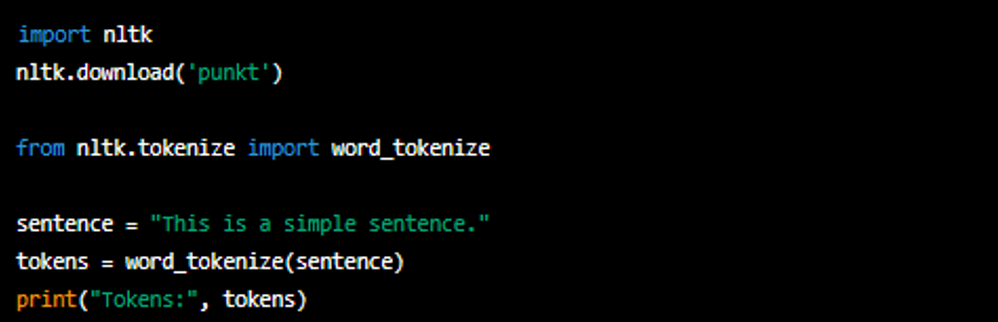
# 1. 自然语言处理(NLP)简介
自然语言处理(NLP)是计算机科学和人工智能领域中一项重要的分支,它致力于使计算机能够理解和处理人类语言。随着人工智能的快速发展,NLP已经成为了连接人类与计算机的重要桥梁。在这一章中,我们将首先对NLP的基本概念进行介绍,随后探讨其在各种实际应用中的表现和影响。
## 1.1 NLP的基本概念
自然语言处理主要涉及计算机理解、解析、生成和操控人类语言的能力。其核心目标是缩小机器理解和人类表达之间的
Polyglot在音视频分析中的力量:多语言字幕的创新解决方案

# 1. 多语言字幕的需求和挑战
在这个信息全球化的时代,跨语言沟通的需求日益增长,尤其是随着视频内容的爆发式增长,对多语言字幕的需求变得越来越重要。无论是在网络视频平台、国际会议、还是在线教育领域,多语言字幕已经成为一种标配。然而,提供高质量的多语言字幕并非易事,它涉及到了文本的提取、
【XML SAX定制内容处理】:xml.sax如何根据内容定制处理逻辑,专业解析
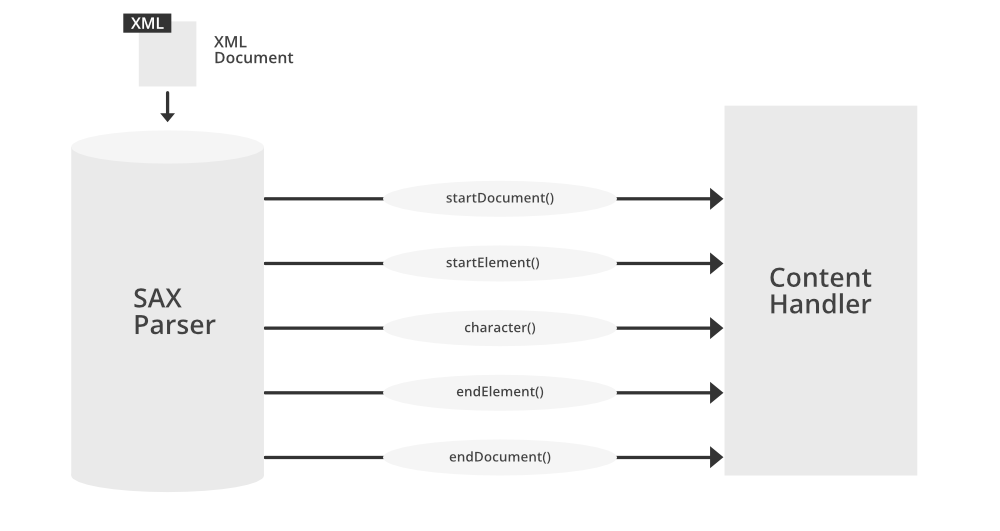
# 1. XML SAX解析基础
## 1.1 SAX解析简介
简单应用程序接口(Simple API for XML,SAX)是一种基于事件的XML解析技术,它允许程序解析XML文档,同时在解析过程中响应各种事件。与DOM(文档对象模型)不同,SAX不需将整个文档加载到内存中,从而具有较低的内存消耗,特别适合处理大型文件。
##
实时通信的挑战与机遇:WebSocket-Client库的跨平台实现

# 1. WebSocket技术的概述与重要性
## 1.1 什么是WebSocket技术
WebSocket是一种在单个TCP连接上进行全双工通信的协议。它为网络应用提供了一种实时的、双向的通信通道。与传统的HTTP请求-响应模型不同,WebSocket允许服务器主动向客户端发送消息,这在需要即时交互的应
FuzzyWuzzy高级应用:自定义匹配权重与分数阈值的最佳实践

# 1. FuzzyWuzzy介绍与基本使用
在当今数据驱动的世界中,文本数据的处理变得越来越重要。FuzzyWuzzy是一个流行的Python库,它可以用于执行字符串的近似匹配并量化字符串之间的相似度。这一章我们将对FuzzyWuzzy库的基础知识进行介绍,并引导读者了解如何在日常工作
【Django信号高效应用】:提升数据库交互性能的5大策略

# 1. Django信号概述
Django框架作为一个高级的Python Web框架,其设计目标之一就是快速开发和干净、实用的设计。为了实现这些目标,Dja
【多语言文本摘要】:让Sumy库支持多语言文本摘要的实战技巧
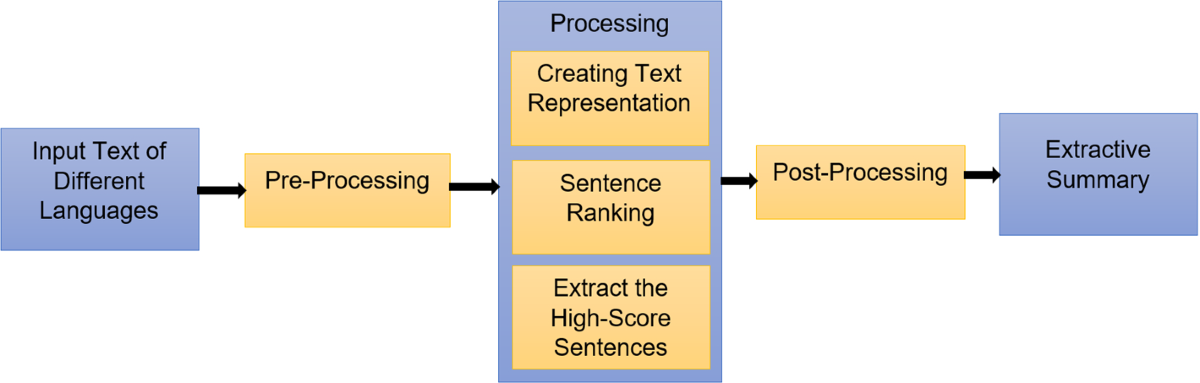
# 1. 多语言文本摘要的重要性
## 1.1 当前应用背景
随着全球化进程的加速,处理和分析多语言文本的需求日益增长。多语言文本摘要技术使得从大量文本信息中提取核心内容成为可能,对提升工作效率和辅助决策具有重要作用。
## 1.2 提升效率与
数据可视化:TextBlob文本分析结果的图形展示方法
# 1. TextBlob简介和文本分析基础
## TextBlob简介
TextBlob是一个用Python编写的库,它提供了简单易用的工具用于处理文本数据。它结合了自然语言处理(NLP)的一些常用任务,如词性标注、名词短语提取、情感分析、分类、翻译等。
## 文本分析基础
文本分析是挖掘文本数据以提取有用信息和见解的过程。通过文本分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )