基于TextBlob的语料库构建:数据准备与预处理秘籍
发布时间: 2024-10-04 19:22:25 阅读量: 44 订阅数: 46 

微博文本情感分析语料库

# 1. TextBlob介绍与语料库构建基础
## TextBlob简介
TextBlob是一个用于处理文本数据的Python库,它简化了自然语言处理(NLP)任务,提供易于使用的接口,用于常见的文本处理需求,如词性标注、情感分析、名词短语提取等。TextBlob的背后是NLTK和Pattern库,但其优势在于用户无需深入了解底层NLP工具包即可快速开始工作。
## 语料库构建的重要性
语料库是NLP研究和开发中的基石,它是大量语言材料的集合,被用来训练语言模型、进行语言分析、验证语言理论等。一个构建良好的语料库应当具有高质量的文本样本,覆盖广泛的语言用法,且更新及时,以适应语言的不断变化。
## 使用TextBlob构建基础语料库
构建基础语料库时,TextBlob可以快速帮助我们进行文本的分词、词性标注、解析等任务。举个例子,以下是一个简单的分词和词性标注的代码示例:
```python
from textblob import TextBlob
blob = TextBlob("TextBlob is amazingly simple to use.")
print(blob.words) # 输出分词结果:['TextBlob', 'is', 'amazingly', 'simple', 'to', 'use', '.']
print(blob.tags) # 输出词性标注结果:[('TextBlob', 'NNP'), ('is', 'VBZ'), ('amazingly', 'RB'), ('simple', 'JJ'), ('to', 'TO'), ('use', 'VB'), ('.', '.')]
```
通过这段代码,我们可以快速得到文本的分词和词性标注结果,这对于初步建立语料库的结构化非常有帮助。在后续的章节中,我们将详细介绍如何使用TextBlob进行更深入的文本预处理和语料库构建。
# 2. 数据收集与清洗技术
## 2.1 数据收集方法
### 2.1.1 网络爬虫技术简介
网络爬虫是自动化获取网页内容的程序,是数据收集中的关键工具。其工作原理包括发送请求、接收响应、解析内容、提取数据和存储结果。现代网络爬虫通常使用Python语言,通过库如Requests获取网页,BeautifulSoup或lxml解析内容,Scrapy框架则提供了一个完整的爬虫解决方案。
```python
import requests
from bs4 import BeautifulSoup
# 示例:使用Requests和BeautifulSoup爬取网页标题
url = "***"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.find('title').text
print(title)
```
上述代码使用了Requests库发送HTTP请求,并将响应内容传递给BeautifulSoup进行解析,最后提取出网页的标题。网络爬虫在爬取时需要遵守Robots协议,尊重目标网站的爬取规则。
### 2.1.2 公开数据集的获取途径
除了自行爬取数据,公开数据集是数据收集的重要来源。许多组织和研究机构都会提供用于教育和研究的公开数据集。例如,Kaggle、UCI Machine Learning Repository、以及政府公开数据集等平台,都是获取高质量数据集的好地方。
```python
import pandas as pd
# 示例:使用pandas加载UCI机器学习库中的鸢尾花数据集
iris_data = pd.read_csv("***", header=None)
print(iris_data.head())
```
在上述代码中,我们使用了pandas库的`read_csv`方法,从UCI机器学习库中直接加载了一个公开数据集。这类数据集通常已经清洗过,可以直接用于分析和训练模型。
## 2.2 数据清洗过程
### 2.2.1 缺失数据的处理策略
数据集中可能存在缺失数据,处理策略有删除含有缺失值的记录、填充缺失值以及估算缺失值。对于连续变量,常用均值、中位数或众数来填充;对于分类变量,可以使用众数填充。在某些情况下,需要根据数据的分布和业务场景来决定缺失值处理方法。
```python
import numpy as np
# 示例:填充缺失值
data = pd.DataFrame([[1, np.nan, 3], [4, 5, 6], [7, 8, np.nan]])
data_filled = data.fillna(data.mean())
print(data_filled)
```
### 2.2.2 异常值和噪声的识别与处理
异常值指的是那些显著偏离其他观测值的点。检测异常值可以使用箱形图、标准差、Z分数等方法。处理异常值的方式包括删除、填充、或转换。噪声则是数据集中随机误差的体现,可以通过平滑技术、滤波器或转换数据来减少噪声的影响。
```python
# 示例:使用标准差识别异常值
from scipy import stats
data = pd.DataFrame({'A': [1, 2, 3, 100]})
z_scores = np.abs(stats.zscore(data))
print(z_scores)
```
### 2.2.3 数据格式化与统一标准
数据集中的时间戳、数值、文本等格式需要统一,以确保数据一致性。例如,日期格式需标准化、数值需统一小数点位置、字符串要统一大小写或编码。这能有效避免后续数据处理时出现的问题。
```python
# 示例:时间戳标准化
data['timestamp'] = pd.to_datetime(data['timestamp'], format='%Y-%m-%d %H:%M:%S')
print(data['timestamp'])
```
在本章节中,我们介绍了数据收集的方法,包括网络爬虫技术简介以及公开数据集的获取途径,并且探讨了数据清洗过程中的主要策略,如缺失数据的处理、异常值和噪声的识别与处理,以及数据格式化与统一标准的必要性。这些步骤是构建高质量语料库不可或缺的一部分,它们确保了数据的准确性和可用性,为后续的文本处理和自然语言处理应用打下坚实基础。
# 3. TextBlob在文本预处理中的应用
TextBlob是一个强大的Python库,它提供了简单直观的API来处理和分析文本数据。它基于NLTK(自然语言处理工具包)构建,适用于常见的自然语言处理任务,尤其是文本预处理。在本章节中,我们将深入探讨TextBlob在文本预处理方面的实际应用,包括文本的分词与标注、文本清洗与标准化、以及特征提取与向量化。
## 3.1 文本的分词与标注
### 3.1.1 分词技术的基本原理
分词是自然语言处理的第一步,它将文本序列切分为更小的单元,通常是词汇。在不同的语言中,分词的方法也有所不同。例如,英文中通常以空格为分隔符,而中文则需要更复杂的算法来识别词汇边界。
在TextBlob中,分词过程是自动进行的。TextBlob利用了NLTK中的分词算法,通过预训练的语言模型来识别词汇边界。这种分词方法适用于多语言环境,用户无需为每种语言编写特定的分词代码。
### 3.1.2 使用TextBlob进行词性标注
词性标注(Part-of-Speech Tagging, POS Tagging)是将词汇分类为名词、动词、形容词等的自然语言处理任务。TextBlob在NLTK的基础上提供了POS标注功能,能够快速识别出文本中的词性。
TextBlob中的`pos_tag()`函数接收一个字符串或分词后的文本列表,返回一个包含词性和词汇的元组列表。例如:
```python
from textblob import TextBlob
blob = TextBlob("She sat on the bank of the river.")
print(blob.tags)
```
输出将会是一个包含每个词及其POS标记的列表,如下:
```plaintext
[('She', 'PRP'), ('sat', 'VBD'), ('on', 'IN'), ('the', 'DT'), ('bank', 'NN'), ('of', 'IN'), ('the', 'DT'), ('river', 'NN'), ('.', '.')]
```
在上述代码中,`PRP`代表代词,`VBD`是过去式动词,`NN`是单数普通名词,`IN`是介词,而`.`表示标点符号。
## 3.2 文本清洗与标准化
### 3.2.1 常见文本清洗技术
文本清洗是指去除文本中的无用信息,如HTML标签、特殊符号、停用词等。TextBlob提供了许多内置的清洗方法,使得清洗工作变得简单。例如,去除HTML标签可以使用`clean_html()`方法,而去除标点符号则可以使用`str.replace()`方法。
```python
from textblob import TextBlob
blob = TextBlob("<div>Hello, world!</div>")
print(blob.clean_html())
```
以上代码将输出:
```plaintext
Hello, world!
```
### 3.2.2 文本标准化的方法与实践
文本标准化是指将文本转换为统一格式的过程,包括小写转换、词形还原(lemmatization)等。TextBlob中的`normalize()`方法可以将文本转换为小写形式,而词形还原功能则需要结合NLTK的`WordNetLemmatizer`。
```python
from textblob import TextBlob
from textblob.nltk import WordNetLemmatizer
b
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 库文件学习之 TextBlob 专栏!这个专栏将带领你深入探索 TextBlob,一个强大的 Python 自然语言处理库。从初学者到高级用户,我们为你准备了全面的指南和教程。
专栏涵盖了 TextBlob 的各个方面,包括情感分析、词性标注、命名实体识别、文本分类、语料库构建、文本清洗、新闻情感分析、库扩展和定制、机器翻译、深度学习集成以及与其他 NLP 库的比较。
通过一系列循序渐进的示例和代码片段,你将掌握使用 TextBlob 进行文本分析和处理的技巧。无论你是数据科学家、语言学家还是开发人员,这个专栏都将帮助你提升你的 NLP 技能并解锁文本数据的强大潜力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
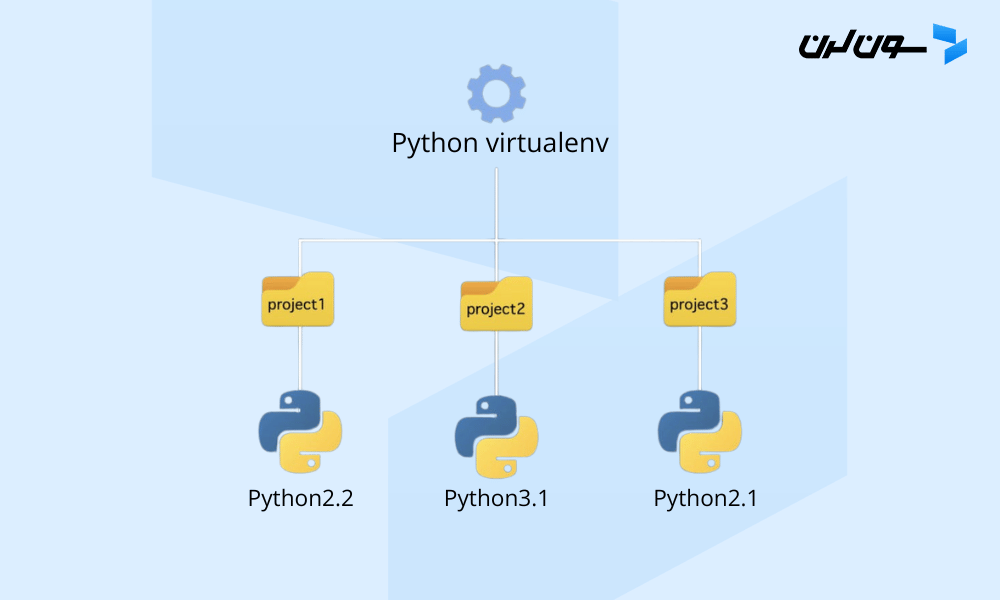
【Python降级实战秘籍】:精通版本切换的10大步骤与技巧
# 摘要
本文针对Python版本管理的需求与实践进行了全面探讨。首先介绍了版本管理的必要性与基本概念,然后详细阐述了版本切换的准备工作,包括理解命名规则、安装和配置管理工具以及环境变量的设置。进一步,本文提供了一个详细的步骤指南,指导用户如何执行Python版本的切换、降级操作,并提供实战技巧和潜在问题的解决方案。最后,文章展望了版本管理的进阶应用和降级技术的未来,讨论了新兴工具的发展趋势以及降级技术面临的挑战和创新方
C++指针解密:彻底理解并精通指针操作的终极指南
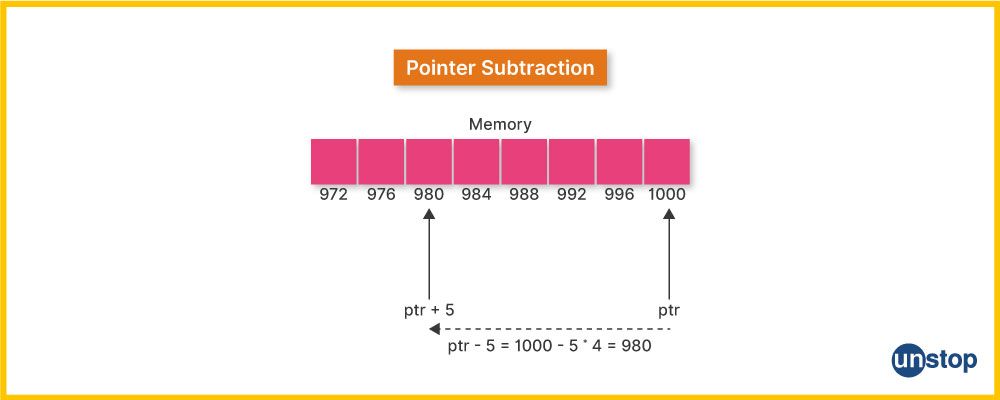
# 摘要
指针作为编程中一种核心概念,贯穿于数据结构和算法的实现。本文系统地介绍了指针的基础知识、与数组、字符串、函数以及类对象的关系,并探讨了指针在动态内存管理、高级技术以及实际应用中的关键角色。同时,本文还涉及了指针在并发编程和编译器优化中的应用,以及智能指针等现代替代品的发展。通过分析指针的多种用途和潜在问题,本文旨
CANoe J1939协议全攻略:车载网络的基石与实践入门

# 摘要
本文系统地介绍并分析了车载网络中广泛采用的J1939协议,重点阐述了其通信机制、数据管理以及与CAN网络的关系。通过深入解读J1939的消息格式、传输类型、参数组编号、数据长度编码及其在CANoe环境下的集成与通信测试,本文为读者提供了全面理解J1939协议的基础知识。此外,文章还讨论了J1
BES2300-L新手指南:7步快速掌握芯片使用技巧

# 摘要
BES2300-L芯片作为本研究的焦点,首先对其硬件连接和初始化流程进行了详细介绍,包括硬件组件准
数字电路设计者的福音:JK触发器与Multisim的终极融合
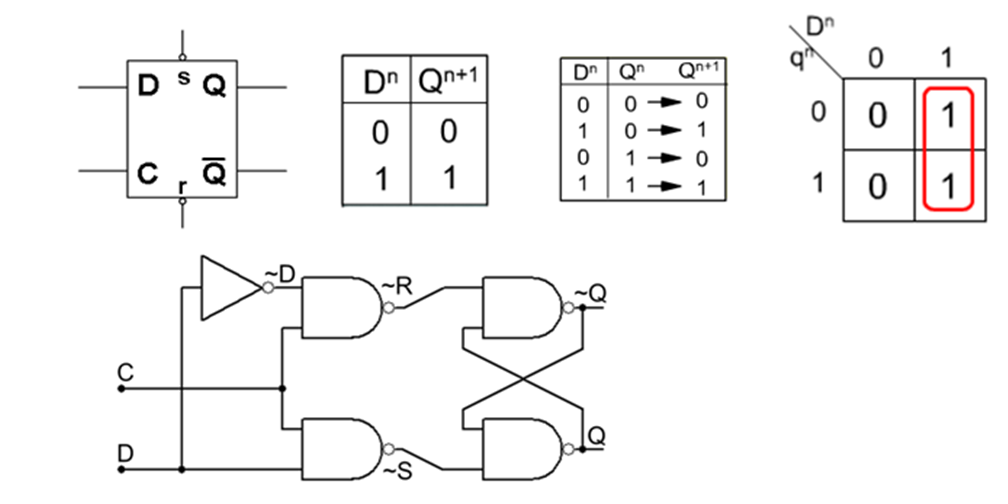
# 摘要
本文首先介绍了数字逻辑与JK触发器的基础知识,并深入探讨了JK触发器的工作原理、类型与特性,以及其在数字电路中的应用,如计数器和顺序逻辑电路设计。随后,文章转向使用Multisim仿真软件进行JK触发器设计与测试的入门知识。在此基础上,作者详细讲解了JK触发器的基本设计实践,包括电路元件的选择与搭建,以及多功能JK触发器设计的逻辑分析和功能验证。最后,文章提供了
企业级自动化调度:实现高可用与容错机制(专家秘籍)

# 摘要
企业级自动化调度系统是现代企业IT基础设施中的核心组成部分,它能够有效提升任务执行效率和业务流程的自动化水平。本文首先介绍了自动化调度的基础概念,包括其理论框架和策略算法,随后深入探讨了高可用性设计原理,涵盖多层架构、负载均衡技术和数据复制策略。第三章着重论述了容错机制的理论基础和实现步骤,包括故障检测、自动恢复以及FMEA分析。第四章则具体说明了自动化调度系统的设计与实践,包括平台选型、
【全面揭秘】:富士施乐DocuCentre SC2022安装流程(一步一步,轻松搞定)

# 摘要
本文全面介绍富士施乐DocuCentre SC2022的安装流程,从前期准备工作到硬件组件安装,再到软件安装与配置,最后是维护保养与故障排除。重点阐述了硬件需求、环境布局、软件套件安装、网络连接、功能测试和日常维护建议。通过详细步骤说明,旨在为用户提供一个标准化的安装指南,确保设备能够顺利运行并达到最佳性能,同时强调预防措施和故障处理的重要性,以减少设备故障率和延长使用寿命。
XJC-CF3600F保养专家

# 摘要
本文综述了XJC-CF3600F设备的概况、维护保养理论与实践,以及未来展望。首先介绍设备的工作原理和核心技术,然后详细讨论了设备的维护保养理论,包括其重要性和磨损老化规律。接着,文章转入操作实践,涵盖了日常检查、定期保养、专项维护,以及故障诊断与应急响应的技巧和流程。案例分析部分探讨了成功保养的案例和经验教训,并分析了新技术在案例中的应用及其对未来保养策略的
生产线应用案例:OpenProtocol-MTF6000的实践智慧

# 摘要
本文详细介绍了OpenProtocol-MTF6000协议的特点、数据交换机制以及安全性分析,并对实际部署、系统集成与测试进行了深入探讨。文中还分析了OpenProtocol-MTF6000在工业自动化生产线、智能物流管理和远程监控与维护中的应用案例,展示了其在多种场景下的解决方案与实施步骤。最后,本文对OpenProtocol-MTF6000未来的发
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )