TextBlob进阶篇:掌握高级文本分类技术
发布时间: 2024-10-04 19:18:59 阅读量: 4 订阅数: 7 

# 1. TextBlob库概述与安装使用
## 1.1 TextBlob简介
TextBlob是一个简单易用的文本处理库,专门用于自然语言处理(NLP)。它建立在NLTK之上,提供了一套简洁的API用于常见的NLP任务,如词性标注、名词短语提取、情感分析、分类、翻译等。TextBlob旨在让NLP工作对初学者和经验丰富的开发者都易于上手。
## 1.2 TextBlob的安装
要安装TextBlob,您可以使用Python的包管理器pip:
```bash
pip install textblob
```
安装完成后,您可以进行基本的操作和文本处理任务。TextBlob的使用非常直观,下面的示例展示了如何使用TextBlob进行情感分析:
```python
from textblob import TextBlob
text = "TextBlob is amazingly simple to use. What great fun!"
blob = TextBlob(text)
# 情感分析
print(blob.sentiment) # 输出: Sentiment(polarity=0.6000, subjectivity=0.8500)
```
## 1.3 TextBlob的使用
TextBlob对多种语言提供了支持,而且其内部实现了多种算法来简化文本分析任务。下面展示了如何进行文本分类:
```python
from textblob import TextBlob
from textblob import classifiers
blob = TextBlob("This is a negative review.")
# 使用朴素贝叶斯分类器
blob.classify(classifiers.NaiveBayesClassifier)
```
TextBlob不仅功能丰富,而且用法简单,非常适合用于教学和快速原型开发。随着对NLP工作的深入,TextBlob提供了强大的基础,让您可以轻松地进行更高级的文本分析任务。在后续章节中,我们将深入了解TextBlob如何在文本预处理、分类和高级特性上提供帮助,以及如何在实战项目中应用。
# 2. 深入理解文本预处理技术
在文本分析和自然语言处理(NLP)任务中,文本预处理是将原始文本数据转化为可供计算机处理的格式的关键步骤。预处理确保了数据质量,并对后续分析的准确性和效率有着直接的影响。
## 2.1 文本预处理的必要性
文本数据通常包含很多对分析任务无用的信息,如标点符号、特殊字符、大小写等。通过预处理,可以提高数据质量,并减少噪声对分析的影响。
### 2.1.1 清洗和格式化文本
清洗文本主要是去除无关的信息,并对文本进行格式化处理,如统一字符大小写、去除重复空格、删除无用的标点符号和特殊字符等。
```python
import re
import string
def clean_text(text):
# 将所有字符转换为小写
text = text.lower()
# 删除所有标点符号
text = text.translate(str.maketrans('', '', string.punctuation))
# 删除数字
text = re.sub(r'\d+', '', text)
# 去除多余空格
text = re.sub(r'\s+', ' ', text).strip()
return text
# 示例文本
example_text = "I love Data Science! 42 is my favorite #number"
print(clean_text(example_text))
```
### 2.1.2 分词与标记化
分词(Tokenization)是将文本切分成独立的词汇单元的过程,标记化(Tokenization)通常是在分词的基础上进一步提取单词的词根(Stemming)或变形(Lemmatization)。
```python
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
from nltk.corpus import stopwords
def tokenize_and_lemmatize(text):
# 下载nltk数据包
import nltk
nltk.download('punkt')
nltk.download('wordnet')
nltk.download('omw-1.4')
nltk.download('stopwords')
# 分词
tokens = word_tokenize(text)
# 词性标注
pos_tags = nltk.pos_tag(tokens)
# 初始化词干提取器
lemmatizer = WordNetLemmatizer()
# 对每个标记进行词根提取或词形还原
lemmas = [lemmatizer.lemmatize(token, pos=tag[0].lower())
if tag.startswith('N') or tag.startswith('V') else token
for token, tag in pos_tags]
return lemmas
# 示例文本
example_text = "I saw saw the sawmill yesterday."
lemmas = tokenize_and_lemmatize(example_text)
print(lemmas)
```
## 2.2 文本向量化技术
文本向量化是将非结构化的文本数据转换为数值型向量的过程,是机器学习模型能够处理的数据格式。
### 2.2.1 Bag of Words模型
Bag of Words模型简单地记录文本中单词的出现次数,忽略单词的顺序和语法结构,将文本转换为词频向量。
```python
from sklearn.feature_extraction.text import CountVectorizer
def convert_to_bow(text_samples):
vectorizer = CountVectorizer()
vectorizer.fit(text_samples)
bow_representation = vectorizer.transform(text_samples).toarray()
return bow_representation, vectorizer.get_feature_names_out()
# 示例文本集
text_samples = ["The cat sat on the mat", "The dog chased the cat"]
bow_representation, features = convert_to_bow(text_samples)
print(bow_representation)
```
### 2.2.2 TF-IDF模型
TF-IDF(Term Frequency-Inverse Document Frequency)模型对词频模型进行了改进,不仅考虑词频还考虑了单词的罕见程度,对常见的词汇进行惩罚,为罕见词汇提供更高的权重。
```python
from sklearn.feature_extraction.text import TfidfVectorizer
def convert_to_tfidf(text_samples):
vectorizer = TfidfVectorizer()
tfidf_representation = vectorizer.fit_transform(text_samples).toarray()
return tfidf_representation, vectorizer.get_feature_names_out()
# 示例文本集
text_samples = ["The cat sat on the mat", "The dog chased the cat"]
tfidf_representation, features = convert_to_tfidf(text_samples)
print(tfidf_representation)
```
## 2.3 特征提取方法
特征提取方法在保留文本中信息的同时,还减少了数据的维度,降低了计算复杂度。
### 2.3.1 n-gram模型
n-gram模型通过提取相邻n个词的组合,来保留文本中词序的信息,可以捕获局部的词组特征。
```python
from sklearn.feature_extraction.text import CountVectorizer
def extract_ngram_features(text_samples, n=2):
vectorizer = CountVectorizer(ngram_range=(n, n))
ngram_representation = vectorizer.fit_transform(text_samples).toarray()
return ngram_representation, vectorizer.get_feature_names_out()
# 示例文本集
text_samples = ["The cat sat on the mat", "The dog chased the cat"]
ngram_representation, features = extract_ngram_features(text_samples)
print(ngram_representation)
```
### 2.3.2 主题模型与词嵌入技术
主题模型,如LDA(Latent Dirichlet Allocation),可以发现文本数据中的隐含主题结构,而词嵌入技术,如Word2Vec或GloVe,通过学习词汇在上下文中的分布来生成词的向量表示,保留了更多语义信息。
```python
import gensim
def train_word2vec_model(text_samples):
# 文本处理为词序列
sentences = [text.split() for text in text_samples]
# 训练Word2Vec模型
model = gensim.models.Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
# 将词汇转换为向量
word_vectors = {word: model.wv[word] for word in model.wv.index_to_key}
return word_vectors
# 示例文本集
text_samples = ["The cat sat on the mat", "The dog chased the cat"]
word_vect
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python并发编程新高度

# 1. Python并发编程概述
在计算机科学中,尤其是针对需要大量计算和数据处理的场景,提升执行效率是始终追求的目标。Python作为一门功能强大、应用广泛的编程语言,在处理并发任务时也展现了其独特的优势。并发编程通过允许多个进程或线程同时执行,可以显著提高程序的运行效率,优化资源的使用,从而满足现代应用程序日益增长的性能需求。
在本章中,我们将探讨Python并发编程的基础知识,为理解后续章节的高级并发技术打下坚实的基础
sgmllib源码深度剖析:构造器与析构器的工作原理

# 1. sgmllib源码解析概述
Python的sgmllib模块为开发者提供了一个简单的SGML解析器,它可用于处理HTML或XML文档。通过深入分析sgmllib的源代码,开发者可以更好地理解其背后的工作原理,进而在实际工作中更有效地使用这一工具。
## 1.1 sgmllib的使用场景
Polyglot在音视频分析中的力量:多语言字幕的创新解决方案

# 1. 多语言字幕的需求和挑战
在这个信息全球化的时代,跨语言沟通的需求日益增长,尤其是随着视频内容的爆发式增长,对多语言字幕的需求变得越来越重要。无论是在网络视频平台、国际会议、还是在线教育领域,多语言字幕已经成为一种标配。然而,提供高质量的多语言字幕并非易事,它涉及到了文本的提取、
高效处理大量数据:FuzzyWuzzy性能优化与内存管理

# 1. FuzzyWuzzy库简介与应用背景
FuzzyWuzzy库是基于Python开发的一个灵活的字符串匹配工具,广泛应用于文本数据处理领域。它特别适合处理自然语言,能够有效识别字符串之间的相似度,并对相似的字符串进行匹配和评估。
## 1.1 库的基本概念与使用场景
【Django信号调试必备】:快速定位与解决信号问题的6个步骤

# 1. Django信号概述
Django作为一款强大的Python Web开发框架,其内置的信号系统为开发者提供了处理业务逻辑的另一种思路。信号允许开
NLTK与其他NLP库的比较:NLTK在生态系统中的定位
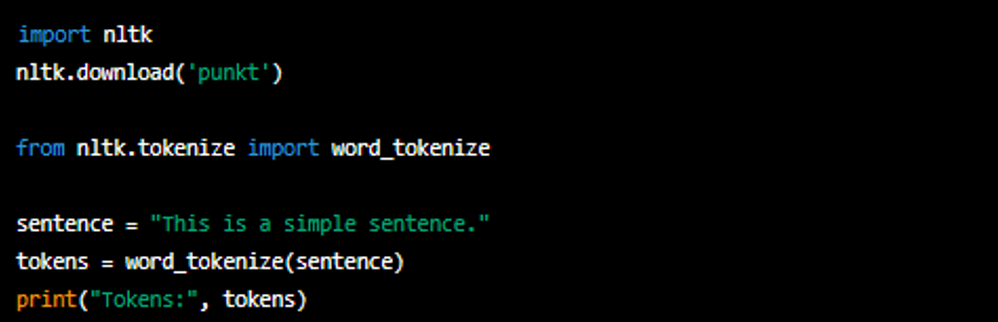
# 1. 自然语言处理(NLP)简介
自然语言处理(NLP)是计算机科学和人工智能领域中一项重要的分支,它致力于使计算机能够理解和处理人类语言。随着人工智能的快速发展,NLP已经成为了连接人类与计算机的重要桥梁。在这一章中,我们将首先对NLP的基本概念进行介绍,随后探讨其在各种实际应用中的表现和影响。
## 1.1 NLP的基本概念
自然语言处理主要涉及计算机理解、解析、生成和操控人类语言的能力。其核心目标是缩小机器理解和人类表达之间的
【多语言文本摘要】:让Sumy库支持多语言文本摘要的实战技巧
# 1. 多语言文本摘要的重要性
## 1.1 当前应用背景
随着全球化进程的加速,处理和分析多语言文本的需求日益增长。多语言文本摘要技术使得从大量文本信息中提取核心内容成为可能,对提升工作效率和辅助决策具有重要作用。
## 1.2 提升效率与
数据可视化:TextBlob文本分析结果的图形展示方法
# 1. TextBlob简介和文本分析基础
## TextBlob简介
TextBlob是一个用Python编写的库,它提供了简单易用的工具用于处理文本数据。它结合了自然语言处理(NLP)的一些常用任务,如词性标注、名词短语提取、情感分析、分类、翻译等。
## 文本分析基础
文本分析是挖掘文本数据以提取有用信息和见解的过程。通过文本分
【XML SAX定制内容处理】:xml.sax如何根据内容定制处理逻辑,专业解析
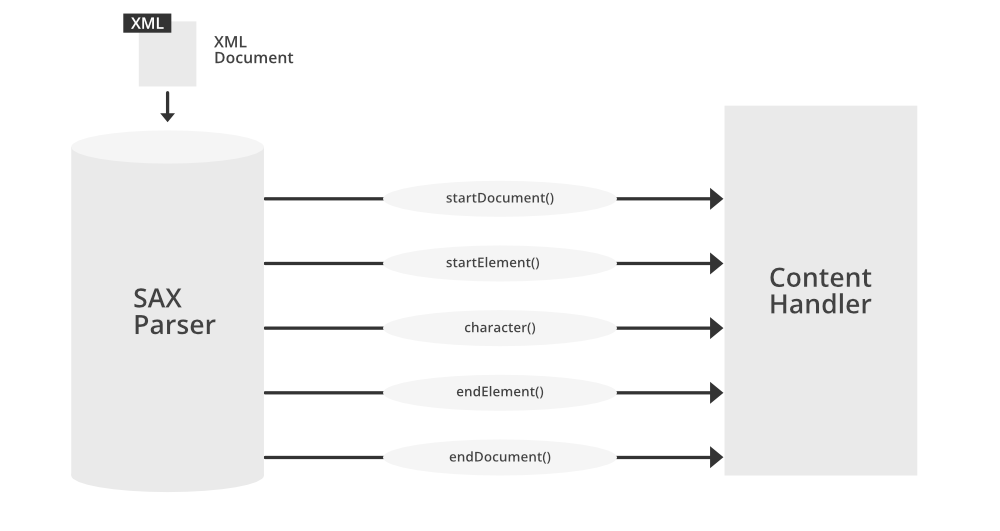
# 1. XML SAX解析基础
## 1.1 SAX解析简介
简单应用程序接口(Simple API for XML,SAX)是一种基于事件的XML解析技术,它允许程序解析XML文档,同时在解析过程中响应各种事件。与DOM(文档对象模型)不同,SAX不需将整个文档加载到内存中,从而具有较低的内存消耗,特别适合处理大型文件。
##
实时通信的挑战与机遇:WebSocket-Client库的跨平台实现

# 1. WebSocket技术的概述与重要性
## 1.1 什么是WebSocket技术
WebSocket是一种在单个TCP连接上进行全双工通信的协议。它为网络应用提供了一种实时的、双向的通信通道。与传统的HTTP请求-响应模型不同,WebSocket允许服务器主动向客户端发送消息,这在需要即时交互的应
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )