深度学习集成:构建基于TextBlob的NLP模型
发布时间: 2024-10-04 19:46:42 阅读量: 23 订阅数: 46 

一些经常需要用到的NLP算法包,有助于学习和使用基于深度学习的文本处理.zip
# 1. 深度学习集成概述
在过去的十年中,深度学习的发展经历了从理论到应用的转变,它在图像识别、语音识别、自然语言处理等领域的应用已经变得越来越普遍。深度学习集成(Ensemble Learning)是指将多个学习算法(通常是深度学习模型)组合在一起,以期望获得比单个模型更优的预测性能。这一策略在提高准确性、减少过拟合以及增强模型泛化能力方面表现出色。
## 1.1 集成学习的概念
集成学习是一种机器学习范式,旨在构建并结合多个学习器以解决同一问题。基本思想是通过结合多个模型做出决策,可以有效提高模型的准确度和鲁棒性。常见的集成方法有Bagging、Boosting和Stacking等。
## 1.2 集成方法的工作机制
不同的集成方法工作原理各异。例如,Bagging通过并行训练多个模型,并对结果进行投票或平均,减少方差。Boosting则通过顺序学习,每个模型都尝试纠正前一个模型的错误,通常会获得更低的偏差。Stacking则是训练一个元模型来组合不同模型的预测。
集成学习不仅在理论上有其独特的地位,而且在实践中也已经证明其有效性。接下来的章节,我们将深入探讨TextBlob在自然语言处理中的应用,并通过实践来展示深度学习集成技术如何在NLP领域发挥作用。
# 2. TextBlob与自然语言处理基础
## 2.1 TextBlob的安装与配置
### 2.1.1 安装TextBlob的方法
安装TextBlob包通常很简单,可使用Python的包管理工具pip来完成。以下是安装TextBlob的基本命令:
```sh
pip install textblob
```
在某些环境下,可能需要安装额外的语言数据包,以便进行更深入的语言处理:
```sh
python -m textblob.download_corpora
```
安装TextBlob后,可以使用Python的交互式解释器导入并检查版本:
```python
import textblob
print(textblob.__version__)
```
### 2.1.2 TextBlob的版本兼容性问题
在使用TextBlob时,需要注意其依赖的其他包的版本兼容性问题。TextBlob 0.15.0版本开始支持Python 3,而且对NLTK库有特定版本要求。例如,TextBlob 0.17.1需要NLTK 3.2.5或更高版本。因此,如果遇到版本不兼容的问题,可能需要更新NLTK或其他相关库:
```sh
pip install -U nltk
```
或者指定版本进行安装:
```sh
pip install nltk==3.2.5
```
## 2.2 NLP基础理论
### 2.2.1 自然语言处理的定义和目的
自然语言处理(Natural Language Processing,NLP)是人工智能和语言学领域中的一个分支,旨在使计算机能够理解、解释和生成人类语言。其主要目的是跨越语言沟通的障碍,让计算机能够处理大量的非结构化文本数据,从中提取信息、推理、翻译等。
NLP的应用领域包括搜索引擎、自动翻译、语音识别、情感分析、文本摘要等。这些应用的核心在于让机器理解和处理人类的语言,从而为用户提供更智能的服务。
### 2.2.2 NLP中的主要技术和方法
NLP涉及众多技术和方法,其中包括但不限于:
- 分词(Tokenization):将文本切分成有意义的单元,如单词或短语。
- 词性标注(Part-of-Speech Tagging):将单词分类为名词、动词等。
- 依存句法分析(Dependency Parsing):分析句子中单词之间的依赖关系。
- 命名实体识别(Named Entity Recognition, NER):识别文本中的特定实体,如人名、地名等。
- 主题模型(Topic Modeling):发现大量文档中的主题。
- 机器翻译(Machine Translation):将一种语言翻译成另一种语言。
## 2.3 TextBlob功能解析
### 2.3.1 Tokenization和词性标注
TextBlob提供了简单的分词和词性标注功能。下面的代码展示了如何使用TextBlob进行分词和获取词性信息:
```python
from textblob import TextBlob
blob = TextBlob("This is an example of tokenization and POS tagging.")
# Tokenization
print(blob.words) # ['This', 'is', 'an', 'example', 'of', 'tokenization', 'and', 'POS', 'tagging']
# Part-of-Speech Tagging
print(blob.tags) # [('This', 'DT'), ('is', 'VBZ'), ('an', 'DT'), ('example', 'NN'), ('of', 'IN'), ('tokenization', 'NN'), ('and', 'CC'), ('POS', 'NNP'), ('tagging', 'NN')]
```
### 2.3.2 语义分析和情感分析
TextBlob同样提供了语义分析和情感分析的功能。语义分析主要用于理解句子的含义,而情感分析用于判断文本表达的情感倾向,是正面还是负面。
```python
# Semantic Analysis - Extract the first sentence of the textblob documentation
blob = TextBlob(textblob.__doc__)
print(blob.sentences[0].sentiment) # Sentiment(polarity=0.0, subjectivity=0.0)
```
情感分析的返回值是一个包含极性和主观性的元组,其中极性在-1(非常负面)到1(非常正面)之间,主观性在0(非常客观)到1(非常主观)之间。
以上为章节2的全部内容,接下来将继续按照要求撰写下一章节内容。
# 3. 深度学习集成的实践操作
## 3.1 数据预处理与TextBlob
在深度学习模型训练中,数据预处理是关键步骤之一,这包括数据清洗、数据标注与格式化,确保数据质量,从而提高模型的性能和准确性。
### 3.1.1 数据清洗
数据清洗是处理原始数据,确保数据质量的过程。TextBlob库提供了一系列工具来辅助文本数据的清洗,例如去除无用字符、规范化文本格式等。
```python
from textblob import TextBlob
import re
def clean_text(text):
# 移除非ASCII字符
text = re.sub(r'[^\x00-\x7F]', '', text)
# 移除网址、标点符号等
text = re.sub(r'(?:(?:\r\n|\r|\n)\s*){2,}', '\n', text)
text = re.sub(r'[^a-zA-Z0-9 ]+', '', text)
return text
# 示例文本
sample_text = "This is a sample text with @websites and... punctuations!!!"
cleaned_text = clean_text(sample_text)
print(cleaned_text)
```
### 3.1.2 数据标注与格式化
数据标注是指将文本数据中的关键信息标记出来,而数据格式化则是为了使数据符合后续处理的格式要求。TextBlob可用于快速标注文本,并将其格式化为结构化的形式,以便用于模型训练。
```python
from textblob import TextBlob
blob = TextBlob(sample_text)
print(blob.tags) # 输出文本中的词性标注
# 格式化为CSV格式
def format_to_csv(blob_list):
return "\n".join([f'"{blob}"' for blob in blob_list])
formatted_data = format_to_csv([blob for blob in TextBlob(text)])
print(formatted_data)
```
## 3.2

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 库文件学习之 TextBlob 专栏!这个专栏将带领你深入探索 TextBlob,一个强大的 Python 自然语言处理库。从初学者到高级用户,我们为你准备了全面的指南和教程。
专栏涵盖了 TextBlob 的各个方面,包括情感分析、词性标注、命名实体识别、文本分类、语料库构建、文本清洗、新闻情感分析、库扩展和定制、机器翻译、深度学习集成以及与其他 NLP 库的比较。
通过一系列循序渐进的示例和代码片段,你将掌握使用 TextBlob 进行文本分析和处理的技巧。无论你是数据科学家、语言学家还是开发人员,这个专栏都将帮助你提升你的 NLP 技能并解锁文本数据的强大潜力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
CDD版本控制实战:最佳实践助你事半功倍

# 摘要
本文详细探讨了CDD(Configuration-Driven Development)版本控制的理论与实践操作,强调了版本控制在软件开发生命周期中的核心作用。文章首先介绍了版本控制的基础知识,包括其基本原理、优势以及应用场景,并对比了不同版本控制工具的特点和选择标准。随后,以Git为例,深入阐述了版本控制工具的安装配置、基础使用方法以及高
Nginx与CDN的完美结合:图片快速加载的10大技巧
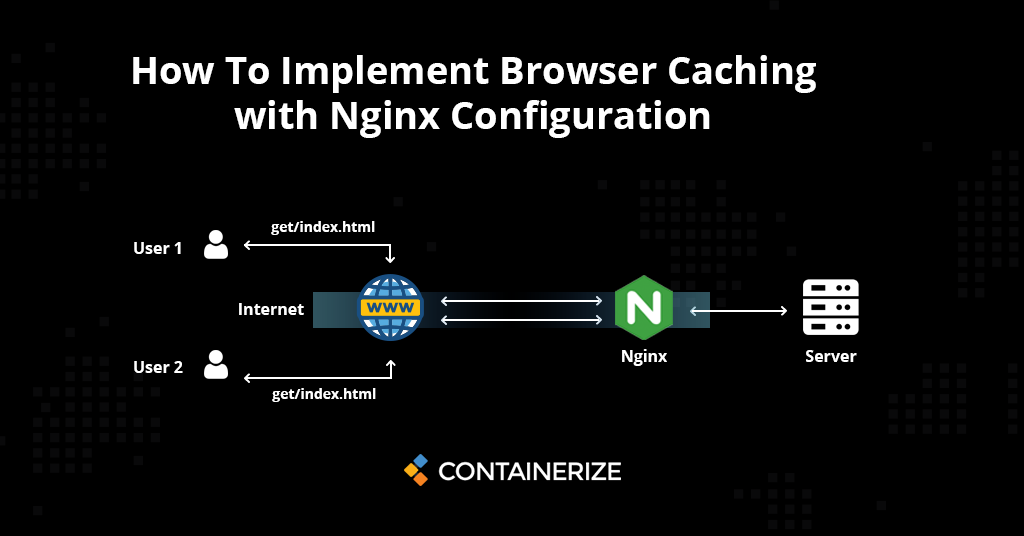
# 摘要
本文详细探讨了Nginx和CDN在图片处理和加速中的应用。首先介绍了Nginx的基础概念和图片处理技巧,如反向代理优化、模块增强、日志分析和性能监控。接着,阐述了CDN的工作原理、优势及配置,重点在于图片加
高速数据处理关键:HMC7043LP7FE技术深度剖析
# 摘要
HMC7043LP7FE是一款集成了先进硬件架构和丰富软件支持的高精度频率合成器。本文全面介绍了HMC7043LP7FE的技术特性,从硬件架构的时钟管理单元和数字信号处理单元,到信号传输技术中的高速串行接口与低速并行接口,以及性能参数如数据吞吐率和功耗管理。此外,详细阐述了其软件支持与开发环境,包括驱动与固件开发、
安全通信基石:IEC103协议安全特性解析
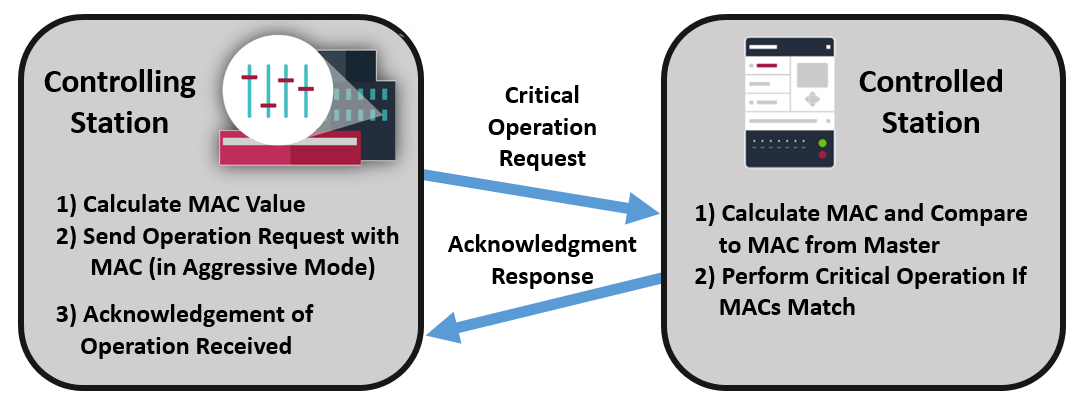
# 摘要
IEC 103协议是电力自动化领域内广泛应用于远动通信的一个重要标准。本文首先介绍了IEC 103协议的背景和简介,然后详细阐述了其数据传输机制,包括帧结构定义、数据封装过程以及数据交换模式。接下来,本文深
EB工具错误不重演:诊断与解决观察角问题的黄金法则

# 摘要
EB工具在错误诊断领域发挥着重要作用,特别是在观察角问题的识别和分析中。本文从EB工具的基础知识开始,深入探讨观察角问题的理论与实践,涵盖了理论基础、诊断方法和预防策略。文章接着介绍了EB工具的高级诊断技术,如问题定位、根因分析以及修复策略,旨在提高问题解决的效率和准确性。通过实践案例的分析,本文展示了EB工具的应用效果,并从失败案例中总结了宝贵经验。最后,文章展望了EB工具未来的发展趋势和挑战,并提出了全方位优化EB工具的综合应用指南,以
深入STM32F767IGT6:架构详解与外设扩展实战指南
# 摘要
本文详细介绍了STM32F767IGT6微控制器的核心架构、内核功能以及与之相关的外设接口与扩展模块。首先概览了该芯片的基本架构和特性,进一步深入探讨了其核心组件,特别是Cortex-M7内核的架构与性能,以及存储器管理和系统性能优化技巧。在第三章中,具体介绍了各种通信接口、多媒体和显示外设的应用与扩展。随后,第四章阐述了开发环境的搭建,包括STM32CubeMX配置工具的应用、集成开发环境的选择与设置,以及调试与性能测试的方法。最后,第五章通过项目案例与实战演练,展示了STM32F767IGT6在嵌入式系统中的实际应用,如操作系统移植、综合应用项目构建,以及性能优化与故障排除的技巧
以太网技术革新纪元:深度解读802.3BS-2017标准及其演进
# 摘要
以太网技术作为局域网通讯的核心,其起源与发展见证了计算技术的进步。本文回顾了以太网技术的起源,深入分析了802.3BS-2017标准的理论基础,包括数据链路层的协议功能、帧结构与传输机制,以及该标准的技术特点和对网络架构的长远影响。实践中,802.3BS-2017标准的部署对网络硬件的适配与升级提出了新要求,其案例分析展示了数据中心和企业级应用中的性能提升。文章还探讨
日鼎伺服驱动器DHE:从入门到精通,功能、案例与高级应用
# 摘要
日鼎伺服驱动器DHE作为一种高效能的机电控制设备,广泛应用于各种工业自动化场景中。本文首先概述了DHE的理论基础、基本原理及其在市场中的定位和应用领域。接着,深入解析了其基础操作,包括硬件连接、标准操作和程序设置等。进一步地,文章详细探讨了DHE的功能,特别是高级控制技术、通讯网络功能以及安全特性。通过工业自动化和精密定位的应用案例,本文展示了DHE在实际应用中的性能和效果。最后,讨论了DHE的高级应用技巧,如自定义功能开发、系统集成与兼容性,以及智能控制技术的未来趋势。
# 关键字
伺服驱动器;控制技术;通讯网络;安全特性;自动化应用;智能控制
参考资源链接:[日鼎DHE伺服驱
YC1026案例分析:揭秘技术数据表背后的秘密武器

# 摘要
YC1026案例分析深入探讨了数据表的结构和技术原理,强调了数据预处理、数据分析和数据可视化在实际应用中的重要性。本研究详细分析了数据表的设计哲学、技术支撑、以及读写操作的优化策略,并应用数据挖掘技术于YC1026案例,包括数据预处理、高级分析方法和可视化报表生成。实践操作章节具体阐述了案例环境的搭建、数据操作案例及结果分析,同时提供了宝贵的经验总结和对技术趋势的展望。此
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )