【Android数据结构与算法大揭秘】:10大技巧提升开发效率
发布时间: 2024-09-10 02:08:22 阅读量: 89 订阅数: 60 
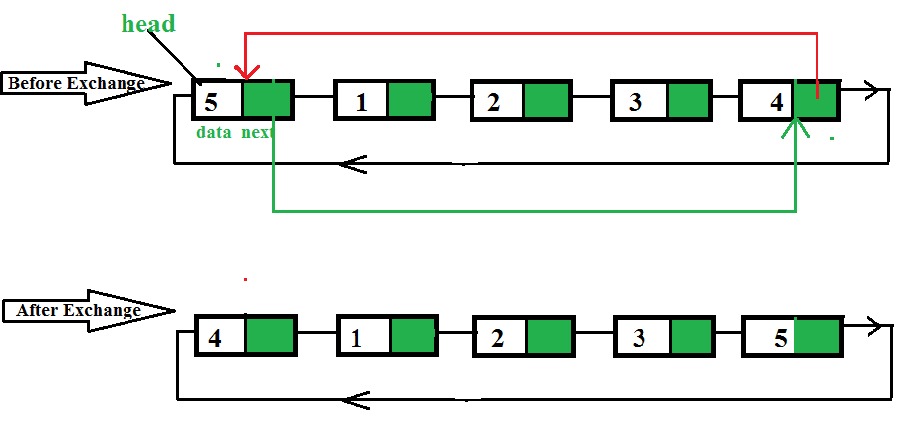
# 1. Android数据结构与算法概述
在本章中,我们将介绍数据结构和算法在Android开发中的基本概念。数据结构是计算机存储、组织数据的方式,它决定了数据的存取效率。算法则是解决特定问题的一系列操作步骤。在Android应用开发中,合理地使用数据结构和算法,不仅可以优化程序的性能,还可以提升用户体验。
## 1.1 数据结构与算法的重要性
数据结构与算法对于Android开发者来说至关重要。它们是构建高效应用程序的基石。了解和掌握这些基础知识能够帮助开发者设计出响应快速、内存消耗少的应用。
## 1.2 数据结构在Android中的应用
在Android平台上,数据结构用于管理UI组件、处理网络请求以及优化数据存储等。例如,使用列表视图时,使用合适的数据结构可以提高滚动性能。
## 1.3 算法在Android中的作用
算法在Android开发中用于优化搜索、排序等操作,提高应用的运行速度和效率。掌握算法还能帮助开发者设计更智能的应用功能,如语音识别和图像处理。
本章将为我们后续章节中深入探讨具体数据结构与算法的使用打下基础。接下来的章节将会涉及Android中常用数据结构的细节,以及它们的实际应用场景,带领我们走进更加专业和深入的Android数据结构与算法世界。
# 2. Android中的数据结构精讲
### 2.1 核心数据结构
#### 2.1.1 数组与链表的使用
在Android开发中,数组和链表是最基本的数据结构,它们各有优缺点,在不同场景下有不同的应用。数组具有固定大小,而链表可以通过指针动态增加和删除元素,不会受到内存限制。
以下是数组和链表的基础使用示例:
**数组的使用示例(Java):**
```java
int[] numbers = new int[10]; // 创建一个长度为10的整型数组
numbers[0] = 1; // 数组元素赋值
// 访问数组元素
for (int i = 0; i < numbers.length; i++) {
System.out.print(numbers[i] + " ");
}
```
**链表的使用示例(Java):**
```java
LinkedList<String> list = new LinkedList<>(); // 创建一个字符串类型的链表
list.add("Android"); // 向链表添加元素
// 遍历链表
for (String element : list) {
System.out.print(element + " ");
}
```
在实际应用中,数组适合于元素数量固定、不需要频繁增删改查的场景,例如定义常量表。而链表则适合于需要频繁插入和删除操作的场景,例如实现一个简单的消息队列。
**数组与链表的性能对比表格:**
| 数据结构 | 时间复杂度 | 空间复杂度 | 优点 | 缺点 |
|----------|------------|------------|------|------|
| 数组 | O(1) | O(n) | 随机访问快 | 插入删除慢,大小固定 |
| 链表 | O(n) | O(n) | 插入删除快 | 随机访问慢,需要额外空间存放指针 |
### 2.2 复杂数据结构
#### 2.2.1 树形结构:二叉树与B树
树形结构,如二叉树和B树,是Android应用中处理层次关系非常重要的数据结构,它们分别适用于不同的存储和检索需求。
**二叉树示例(Java):**
```java
class TreeNode {
int val;
TreeNode left;
TreeNode right;
public TreeNode(int x) {
val = x;
}
}
// 二叉树的基本操作,如插入
public void insert(TreeNode root, int val) {
if (root == null) {
root = new TreeNode(val);
return;
}
if (val < root.val) {
insert(root.left, val);
} else {
insert(root.right, val);
}
}
```
B树特别适用于读写大量数据的场景,如数据库索引和文件系统。B树通过平衡树的大小和结构,保持树的高度最小,从而实现高效的磁盘读写。
### 2.3 数据结构的性能分析
#### 2.3.1 时间复杂度与空间复杂度
时间复杂度和空间复杂度是衡量数据结构性能的关键指标。时间复杂度描述了算法执行的时间随输入数据量增加的增长趋势,而空间复杂度描述了算法占用内存空间随输入数据量增加的增长趋势。
例如,数组的查找时间复杂度为O(1),插入和删除的时间复杂度为O(n);而链表的查找时间复杂度为O(n),插入和删除的时间复杂度为O(1)。
#### 2.3.2 数据结构选择的权衡
在选择数据结构时,开发者需要根据实际的业务需求进行权衡。例如,如果应用需要快速访问元素,可能会优先选择数组;如果应用需要高效处理大量动态变化的数据,则可能会选择链表、二叉树或B树等。
在性能要求严格的情况下,这种权衡尤为重要,因为不同的数据结构会直接影响到程序的效率和响应时间。开发者应根据算法的需求、执行环境以及资源限制等因素,做出最合适的选择。
# 3. Android中的常用算法解析
## 3.1 排序算法
排序算法是软件开发中最为常见的算法之一,它们在处理大量数据时能够显著提高性能。了解排序算法的原理及效率,对于进行有效编程至关重要。本节将详细介绍几种常用的排序算法,并着重分析快速排序和归并排序的实现方式。
### 3.1.1 常见排序算法的原理与效率
排序算法主要分为比较型排序和非比较型排序。常见的比较型排序算法包括冒泡排序、选择排序、插入排序、快速排序、归并排序和堆排序等。而非比较型排序算法包括计数排序、基数排序、桶排序等。
- **冒泡排序**:通过重复遍历要排序的数列,一次比较两个元素,如果顺序错误就把它们交换过来。算法的时间复杂度为O(n^2),适合小规模数据的简单排序。
- **选择排序**:首先在未排序序列中找到最小(或最大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(或最大)元素,以此类推。时间复杂度也是O(n^2)。
- **插入排序**:通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。时间复杂度为O(n^2),但对小数组来说是相对高效的。
- **快速排序**:通过选择一个基准元素,将数据分为两个子序列,一个子序列的所有元素都比基准小,另一个子序列的所有元素都比基准大,然后递归地排序两个子序列。平均时间复杂度为O(n log n),是效率较高的排序算法。
- **归并排序**:将数组分成两半,分别进行归并排序,然后将结果合并。其平均时间复杂度为O(n log n),由于需要额外的空间来合并,故空间复杂度为O(n)。
- **堆排序**:利用堆这种数据结构所设计的一种排序算法,时间复杂度为O(n log n),堆排序是一种不稳定的排序算法。
### 3.1.2 实现快速排序与归并排序
快速排序与归并排序是两种效率较高的排序算法。快速排序通过分治法实现,而归并排序则是将已有序的子序列合并,得到完全有序的序列。
**快速排序算法实现示例(Java)**:
```java
public void quickSort(int[] arr, int low, int high) {
if (low < high) {
int pivot = partition(arr, low, high); // 分区操作
quickSort(arr, low, pivot - 1); // 递归排序左子数组
quickSort(arr, pivot + 1, high); // 递归排序右子数组
}
}
private int partition(int[] arr, int low, int high) {
int pivot = arr[high]; // 选择基准元素
int i = (low - 1); // i指向比基准小的最后一个元素
for (int j = low; j < high; j++) {
// 如果当前元素小于或等于基准
if (arr[j] <= pivot) {
i++;
// 交换arr[i]和arr[j]
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
// 交换arr[i+1]和arr[high](或基准)
int temp = arr[i + 1];
arr[i + 1] = arr[high];
arr[high] = temp;
return i + 1;
}
```
**归并排序算法实现示例(Java)**:
```java
public void mergeSort(int[] arr, int[] temp, int leftStart, int rightEnd) {
if (leftStart >= rightEnd) {
return;
}
int middle = (leftStart + rightEnd) / 2;
mergeSort(arr, temp, leftStart, middle);
mergeSort(arr, temp, middle + 1, rightEnd);
mergeHalves(arr, temp, leftStart, rightEnd);
}
private void mergeHalves(int[] arr, int[] temp, int leftStart, int rightEnd) {
int leftEnd = (rightEnd + leftStart) / 2;
int rightStart = leftEnd + 1;
int size = rightEnd - leftStart + 1;
int left = leftStart;
int right = rightStart;
int index = leftStart;
while (left <= leftEnd && right <= rightEnd) {
if (arr[left] <= arr[right]) {
temp[index] = arr[left];
left++;
} else {
temp[index] = arr[right];
right++;
}
index++;
}
System.arraycopy(arr, left, temp, index, leftEnd - left + 1);
System.arraycopy(arr, right, temp, index, rightEnd - right + 1);
System.arraycopy(temp, leftStart, arr, leftStart, size);
}
```
快速排序和归并排序都是递归算法,快速排序在平均情况下效率较高,但在最坏情况下效率会退化到O(n^2);归并排序由于需要额外的存储空间,所以在空间效率上不如其他排序算法。不过,归并排序的时间复杂度稳定在O(n log n),而且是稳定的排序算法,适用于大数据量的场景。
## 3.2 查找算法
查找算法在数据管理、数据库和日常编程中有着广泛的应用。在这一部分,我们将详细介绍二分查找法的原理和实现,以及哈希表与散列函数在查找算法中的应用。
### 3.2.1 二分查找法的原理与实现
二分查找是一种在有序数组中查找某一特定元素的搜索算法。搜索过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜索过程结束;如果某一特定元素大于或小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟之前的步骤相同。递归或迭代的二分查找算法的时间复杂度为O(log n)。
**二分查找算法实现示例(Java)**:
```java
public int binarySearch(int[] arr, int target) {
int left = 0, right = arr.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (arr[mid] == target) {
return mid; // 找到目标元素,返回其索引
} else if (arr[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return -1; // 未找到目标元素,返回-1
}
```
### 3.2.2 哈希表与散列函数
哈希表是一种根据关键码的值(Key value)而直接进行访问的数据结构。它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。散列函数将输入(或者称为“键”)映射到数组的索引上,理想情况下不同的输入会有不同的索引,但在实际中会有冲突。解决冲突的方法主要有开放寻址法、链表法等。
**使用哈希表实现查找的示例(Java)**:
```java
import java.util.HashSet;
import java.util.Set;
public class HashTableExample {
public static void main(String[] args) {
Set<String> set = new HashSet<>();
// 假设我们要构建一个单词集合
set.add("apple");
set.add("banana");
set.add("orange");
// 检查某个单词是否存在于集合中
String searchWord = "banana";
boolean found = set.contains(searchWord);
System.out.println("The word '" + searchWord + "' is " + (found ? "found" : "not found"));
}
}
```
在上述示例中,我们使用了Java内置的HashSet,它内部实际使用了哈希表结构。通过调用`add`方法添加元素,调用`contains`方法来快速查找元素。
## 3.3 算法设计技巧
算法设计是解决复杂问题时的关键环节,它决定了程序的效率和资源消耗。动态规划和贪心算法是解决实际问题时常用的两种算法设计技巧。动态规划是通过把原问题分解为相对简单的子问题的方式来求解复杂问题的方法。贪心算法则是在每一步选择中都采取当前状态下最好或最优(即最有利)的选择,从而希望导致结果是全局最好或最优的算法。
### 3.3.1 动态规划基础与案例
动态规划适用于求解最优化问题,它将复杂问题分解为简单子问题,并存储子问题的解,避免重复计算。动态规划通常有最优子结构、边界条件和状态转移方程三个重要特性。
**动态规划算法实现示例(0-1背包问题)**:
```java
public int knapsack(int[] values, int[] weights, int capacity) {
int n = values.length;
int[][] dp = new int[n+1][capacity+1];
for (int i = 1; i <= n; i++) {
for (int w = 1; w <= capacity; w++) {
if (weights[i-1] <= w) {
dp[i][w] = Math.max(dp[i-1][w], dp[i-1][w-weights[i-1]] + values[i-1]);
} else {
dp[i][w] = dp[i-1][w];
}
}
}
return dp[n][capacity];
}
```
在上述代码中,我们实现了一个简单的0-1背包问题的动态规划解法。问题要求在不超过背包容量的前提下,选择物品装入背包,使得总价值最大。
### 3.3.2 贪心算法与回溯算法的应用
贪心算法与回溯算法在某些问题上可以提供非常有效的解决方案。贪心算法在每一步选择中都采取在当前状态下最好或最优的选择,从而希望导致结果是全局最好或最优的算法。而回溯算法是一种通过穷举所有可能情况来找到所有解的算法,如果发现已不满足求解条件,则回退到上一步甚至几步重新尝试其他可能。
**贪心算法实现示例(找零钱问题)**:
```java
public int minCoins(int[] coins, int value) {
int count = 0;
for (int i = coins.length - 1; i >= 0; i--) {
while (value >= coins[i]) {
value -= coins[i];
count++;
}
}
return count;
}
```
在上述例子中,我们通过贪心算法解决了一个找零钱问题。假设有无限的硬币,面值分别为`coins`数组中给出的值,我们需要凑出`value`的零钱,求最少需要多少个硬币。
通过本章节的介绍,我们了解了排序、查找、动态规划以及贪心算法的原理和实现方法。这些算法设计技巧在开发过程中发挥着巨大作用,能够帮助开发者设计出高效、优雅的解决方案。在下一章中,我们将深入探讨这些算法在Android开发实践中的应用,以及如何优化应用性能。
# 4. Android开发中的数据结构与算法实践
## 4.1 数据结构在UI中的应用
### 4.1.1 利用栈实现历史记录功能
在Android开发中,利用栈(Stack)数据结构可以非常方便地实现历史记录功能。栈是一种后进先出(LIFO, Last In First Out)的数据结构,最适合用来处理历史记录这样的场景,因为用户通常希望最后访问的记录是最先被恢复的。
为了实现历史记录功能,我们可以使用Android中的`ArrayDeque`或者`LinkedList`来模拟栈的行为。以下是一个简单的示例:
```java
import java.util.LinkedList;
public class HistoryStack {
private LinkedList<String> history = new LinkedList<>();
public void push(String item) {
// 添加新的记录项到栈顶
history.addFirst(item);
}
public String pop() {
// 从栈顶移除并返回记录项
if (history.isEmpty()) {
throw new IllegalStateException("History stack is empty.");
}
return history.removeFirst();
}
public String peek() {
// 查看但不移除栈顶的记录项
if (history.isEmpty()) {
throw new IllegalStateException("History stack is empty.");
}
return history.getFirst();
}
public boolean isEmpty() {
// 检查栈是否为空
return history.isEmpty();
}
}
```
在UI层面上,每当用户进行页面跳转或者数据查看时,我们调用`push`方法将当前页面的标识添加到历史栈中。当用户想要返回上一个页面时,调用`pop`方法,就可以从历史栈中获取前一个页面的标识并进行跳转。
### 4.1.2 队列在消息处理中的应用
队列(Queue)是另一种常用的数据结构,其特点是先进先出(FIFO, First In First Out)。在Android应用中,队列常用于处理后台线程与UI线程间的消息传递,例如在使用`Handler`和`Looper`的场景。
消息队列可以确保消息的顺序性,这对于事件驱动型的应用是至关重要的。例如,在一个聊天应用中,消息按接收的时间顺序进行排列,并在用户界面上按顺序显示。
实现一个简单的消息队列可以使用`LinkedList`,如下面的代码片段所示:
```java
import java.util.LinkedList;
import java.util.Queue;
public class MessageQueue {
private Queue<Message> queue = new LinkedList<>();
public void enqueue(Message message) {
// 将消息放入队列尾部
queue.add(message);
}
public Message dequeue() {
// 从队列头部移除并返回消息
if (queue.isEmpty()) {
throw new IllegalStateException("Message queue is empty.");
}
return queue.remove();
}
public boolean isEmpty() {
// 检查队列是否为空
return queue.isEmpty();
}
}
```
当接收到新的消息时,通过调用`enqueue`方法将消息加入到队列中。UI线程会定期调用`dequeue`方法来获取并处理消息队列中的下一个消息。
## 4.2 算法优化应用性能
### 4.2.1 利用二分查找提升搜索效率
在数据量较大的应用中,搜索功能的效率至关重要。对于已排序的数据集,使用二分查找算法能显著提升搜索效率。二分查找的基本思想是将数据集分成两半,然后确定目标值位于哪一半中,再对选定的一半进行查找。
这里是一个简单的二分查找算法实现示例:
```java
public int binarySearch(int[] array, int target) {
int left = 0;
int right = array.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (array[mid] == target) {
return mid; // 找到了目标值
} else if (array[mid] < target) {
left = mid + 1; // 目标值在右半部分
} else {
right = mid - 1; // 目标值在左半部分
}
}
return -1; // 未找到目标值
}
```
在Android开发中,当处理大量静态数据或在应用启动时加载数据集时,考虑使用二分查找算法来提升性能。对于动态数据集,二分查找也适用,只要确保数据集在使用前是已排序的。
### 4.2.2 散列表在缓存机制中的应用
散列表(Hash Table)是一种使用键值对(key-value pairs)存储数据的数据结构。在Android应用中,散列表可以被用作缓存机制的核心,来存储临时数据,避免重复计算或网络请求。
Java中`HashMap`类提供了散列表的实现,下面是使用`HashMap`来存储数据缓存的简单示例:
```java
import java.util.HashMap;
import java.util.Map;
public class Cache {
private Map<String, Object> cache = new HashMap<>();
public void put(String key, Object value) {
cache.put(key, value);
}
public Object get(String key) {
return cache.get(key);
}
public void remove(String key) {
cache.remove(key);
}
}
```
通过维护一个散列表,当用户需要访问某些数据时,应用首先检查散列表中是否存在该数据。如果存在,则直接从散列表中读取,从而减少加载时间;如果不存在,再进行网络请求或计算,然后将结果存入缓存。
## 4.3 解决实际问题的算法案例
### 4.3.1 排序算法在数据展示中的优化
当需要向用户展示大量数据时,例如在社交媒体应用的动态信息流中,合理的排序算法是必须的。使用快速排序或者归并排序算法可以有效地处理大量数据的排序问题。
快速排序是一个典型的分治算法,其基本思想是在数据集中选择一个基准值,然后将数据集分为两部分,一部分包含小于基准值的所有元素,另一部分包含大于基准值的所有元素,并递归地对这两部分继续进行快速排序。
以下是一个快速排序算法实现的简化示例:
```java
public void quickSort(int[] array, int low, int high) {
if (low < high) {
int pivotIndex = partition(array, low, high);
quickSort(array, low, pivotIndex - 1);
quickSort(array, pivotIndex + 1, high);
}
}
private int partition(int[] array, int low, int high) {
int pivot = array[high];
int i = low - 1;
for (int j = low; j < high; j++) {
if (array[j] <= pivot) {
i++;
swap(array, i, j);
}
}
swap(array, i + 1, high);
return i + 1;
}
private void swap(int[] array, int i, int j) {
int temp = array[i];
array[i] = array[j];
array[j] = temp;
}
```
在展示动态信息流时,可以使用快速排序算法对数据集进行排序,根据时间戳等标准将数据按照新旧顺序排列。
### 4.3.2 查找算法在内容索引中的运用
在搜索引擎或全文搜索功能中,查找算法尤其是二分查找算法被广泛运用于索引中。有效的查找算法可以极大地提高用户查询信息的速度和准确性。
例如,如果建立了一个字典树(Trie)结构作为搜索的索引,可以在该结构上使用二分查找来加速对特定关键字的检索。字典树结构适合于存储和查找大量的字符串,例如单词。
以下是一个字典树的实现简化示例:
```java
public class TrieNode {
Map<Character, TrieNode> children;
boolean isEndOfWord;
public TrieNode() {
children = new HashMap<>();
isEndOfWord = false;
}
public void insert(String word) {
TrieNode node = this;
for (char ch : word.toCharArray()) {
node = ***puteIfAbsent(ch, k -> new TrieNode());
}
node.isEndOfWord = true;
}
public boolean search(String word) {
TrieNode node = this;
for (char ch : word.toCharArray()) {
node = node.children.get(ch);
if (node == null) {
return false;
}
}
return node.isEndOfWord;
}
}
```
在搜索引擎中,字典树可以用于索引所有可以搜索的词或短语。当用户输入搜索词时,应用可以快速在字典树中检索到该词,从而迅速提供搜索结果。
以上就是关于在Android开发中如何将数据结构与算法应用到实践中的部分案例。这些实际问题的解决方案不但能提升应用性能,而且还能改善用户体验。在下一章节中,我们将探索更高级的技巧和对未来技术趋势的展望。
# 5. 高级技巧与未来展望
## 5.1 Android性能优化高级技巧
在当前Android应用开发领域,性能优化已成为开发者必须掌握的核心技能之一。性能优化不仅涉及到提高应用的运行效率,还包括了内存使用、电量消耗、以及启动速度等多个方面。如何利用原生代码与JIT技术,以及如何在多线程环境中合理运用数据结构与算法,是本节将深入探讨的问题。
### 5.1.1 原生代码与JIT技术的应用
Java虚拟机(JVM)在Android平台上具有重要的地位,但它并不总是最优选择。JIT(Just-In-Time)技术是一种在运行时将字节码编译成机器码的技术,而原生代码(Native Code)通常指的是直接编译成机器码的代码。原生代码与JIT技术结合使用可以极大提升Android应用的性能。
在某些需要高性能计算的场景下,例如游戏引擎或者复杂的图像处理,开发者可以将热点代码(频繁执行的代码段)使用C或C++进行编写,然后通过Android的NDK(Native Development Kit)来编译成原生库供Java代码调用。这样可以减少JIT编译的开销,直接利用CPU的计算能力。
### 5.1.2 数据结构与算法在多线程中的运用
多线程编程是提高Android应用性能的另一个关键因素。在多线程环境中合理运用数据结构与算法,不仅能够保证线程安全,还能有效减少资源竞争和死锁的发生。
例如,在设计线程安全的队列时,可以使用阻塞队列(BlockingQueue),它结合了队列与锁的特性,允许在多线程中安全地添加和移除元素。对于链表,可以使用并发集合如`ConcurrentLinkedQueue`来保证多线程下的线程安全。
此外,在复杂的算法实现中,如图的搜索和遍历,在多线程环境下可以使用并行算法来提高效率。并行算法通常需要设计良好的分治策略,将大数据集分割成小部分,分配给不同的线程去处理,最终合并结果。
## 5.2 算法创新与人工智能
随着人工智能的兴起,算法创新成为了推动技术发展的新引擎。机器学习与深度学习等技术正在被越来越多地集成到Android应用中,为用户带来前所未有的体验。
### 5.2.1 机器学习算法在Android中的应用
在Android应用中嵌入机器学习模型,可以实现智能的场景识别、文字识别、用户行为预测等功能。例如,使用TensorFlow Lite可以在Android设备上部署轻量级的机器学习模型,用于实时的图像识别。
机器学习模型的训练通常在服务器端完成,然后将训练好的模型压缩并转换为TensorFlow Lite格式。在Android应用中,使用TensorFlow Lite的API来加载模型,并将用户输入的图像数据进行预处理,然后传递给模型进行推断,最终获取结果并响应用户操作。
### 5.2.2 未来数据结构与算法的发展趋势
随着计算能力的提升和数据量的激增,数据结构和算法将会持续进化以适应新的挑战。除了传统的优化方法外,量子计算、生物计算等前沿技术将会对未来数据结构与算法的研究带来重大影响。
量子计算有可能为某些问题提供指数级的加速,例如在优化问题、搜索问题和模拟问题上的应用。而生物计算则可能从自然界中汲取灵感,创造出更加高效和节能的算法。
## 5.3 深入理解和实践
掌握理论是基础,但更重要的是将理论应用于实践。本节将介绍两个方面的实践:代码效率分析工具的使用和实战演练。
### 5.3.1 代码效率分析工具的使用
在开发高性能Android应用时,有效地分析代码效率是必不可少的。Android Studio内置了Profiler工具,可以用来分析CPU、内存、网络和能量消耗情况。此外,还有如LeakCanary用于内存泄漏检测,MAT(Memory Analyzer Tool)用于分析堆内存使用情况。
使用这些工具可以帮助开发者快速定位性能瓶颈,从而有针对性地进行优化。例如,通过CPU Profiler可以观察到函数调用的热点,从而发现是否有过度的计算或者不合理的数据结构使用。
### 5.3.2 实战演练:构建一个高效的数据结构库
构建高效的数据结构库是数据结构与算法实践中的重要环节。在本实战演练中,我们将通过一个简单的案例来展示如何构建一个高效的数据结构库。
假设我们需要一个线程安全的Map实现,在多线程环境下读写高效且无锁。我们可以基于`ConcurrentHashMap`来构建,或者设计自己的无锁哈希表。以下是使用`ConcurrentHashMap`的简单示例:
```java
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap<>();
map.put("key1", 1);
map.putIfAbsent("key2", 2);
Integer value = map.get("key1");
```
对于更高级的应用,可以参考开源项目如`Disruptor`或`Agrona`来实现复杂的无锁数据结构。通过实战演练,开发者能够深刻理解数据结构与算法的实际应用场景,为解决实际问题打下坚实基础。
在进行实战演练时,切记要不断地测试和优化。编写单元测试来验证数据结构的正确性和性能,并使用性能分析工具来检查效率。只有这样,我们才能构建出既高效又可靠的代码库。
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到“Android数据结构算法”专栏,这是一个全面的指南,旨在帮助Android开发人员掌握数据结构和算法的精髓。本专栏深入探讨了这些概念在Android开发中的应用,包括性能优化、内存管理、UI渲染和网络通信。
通过一系列深入的文章,您将了解10种提高开发效率的技巧、数据结构在Android性能优化中的关键作用、链表、数组和ArrayList之间的权衡、树结构的应用案例、图结构优化技巧、单向和双向链表、递归和迭代的对比、数据结构在UI渲染中的作用、动态规划和分治算法、散列表的应用、数据结构在多线程编程中的高级应用,以及解决编程难题的算法思维。
无论您是Android开发新手还是经验丰富的专业人士,本专栏都将为您提供宝贵的见解和实用策略,帮助您提升开发技能并创建高效、可扩展的Android应用程序。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Styling Scrollbars in Qt Style Sheets: Detailed Examples on Beautifying Scrollbar Appearance with QSS
# Chapter 1: Fundamentals of Scrollbar Beautification with Qt Style Sheets
## 1.1 The Importance of Scrollbars in Qt Interface Design
As a frequently used interactive element in Qt interface design, scrollbars play a crucial role in displaying a vast amount of information within limited space. In
Technical Guide to Building Enterprise-level Document Management System using kkfileview
# 1.1 kkfileview Technical Overview
kkfileview is a technology designed for file previewing and management, offering rapid and convenient document browsing capabilities. Its standout feature is the support for online previews of various file formats, such as Word, Excel, PDF, and more—allowing user
Expert Tips and Secrets for Reading Excel Data in MATLAB: Boost Your Data Handling Skills
# MATLAB Reading Excel Data: Expert Tips and Tricks to Elevate Your Data Handling Skills
## 1. The Theoretical Foundations of MATLAB Reading Excel Data
MATLAB offers a variety of functions and methods to read Excel data, including readtable, importdata, and xlsread. These functions allow users to
Statistical Tests for Model Evaluation: Using Hypothesis Testing to Compare Models
# Basic Concepts of Model Evaluation and Hypothesis Testing
## 1.1 The Importance of Model Evaluation
In the fields of data science and machine learning, model evaluation is a critical step to ensure the predictive performance of a model. Model evaluation involves not only the production of accura
Installing and Optimizing Performance of NumPy: Optimizing Post-installation Performance of NumPy
# 1. Introduction to NumPy
NumPy, short for Numerical Python, is a Python library used for scientific computing. It offers a powerful N-dimensional array object, along with efficient functions for array operations. NumPy is widely used in data science, machine learning, image processing, and scient
PyCharm Python Version Management and Version Control: Integrated Strategies for Version Management and Control
# Overview of Version Management and Version Control
Version management and version control are crucial practices in software development, allowing developers to track code changes, collaborate, and maintain the integrity of the codebase. Version management systems (like Git and Mercurial) provide
Analyzing Trends in Date Data from Excel Using MATLAB
# Introduction
## 1.1 Foreword
In the current era of information explosion, vast amounts of data are continuously generated and recorded. Date data, as a significant part of this, captures the changes in temporal information. By analyzing date data and performing trend analysis, we can better under
Image Processing and Computer Vision Techniques in Jupyter Notebook
# Image Processing and Computer Vision Techniques in Jupyter Notebook
## Chapter 1: Introduction to Jupyter Notebook
### 2.1 What is Jupyter Notebook
Jupyter Notebook is an interactive computing environment that supports code execution, text writing, and image display. Its main features include:
-
[Frontier Developments]: GAN's Latest Breakthroughs in Deepfake Domain: Understanding Future AI Trends
# 1. Introduction to Deepfakes and GANs
## 1.1 Definition and History of Deepfakes
Deepfakes, a portmanteau of "deep learning" and "fake", are technologically-altered images, audio, and videos that are lifelike thanks to the power of deep learning, particularly Generative Adversarial Networks (GANs
Parallelization Techniques for Matlab Autocorrelation Function: Enhancing Efficiency in Big Data Analysis
# 1. Introduction to Matlab Autocorrelation Function
The autocorrelation function is a vital analytical tool in time-domain signal processing, capable of measuring the similarity of a signal with itself at varying time lags. In Matlab, the autocorrelation function can be calculated using the `xcorr
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )