Data Migration Tips: How to Efficiently Store Data in MySQL Using Python
发布时间: 2024-09-12 14:54:53 阅读量: 40 订阅数: 21 

clickhouse-mysql-data-reader:读取mysql数据的实用程序
# Data Migration Tips: Efficient MySQL Data Storage in Python
In the data-driven world, MySQL, as one of the most popular open-source relational database management systems, provides robust support for corporate data storage. As Python becomes increasingly prevalent in the field of data processing, combining Python with MySQL for data migration has become a skill that data engineers must master. This chapter will start with the basics of MySQL and give an overview of the role and necessity of Python in data migration.
## 1.1 Overview of MySQL Database
MySQL is a multi-user, multi-threaded relational database management system that uses structured query language (SQL) for database management. Unlike many other types of databases, MySQL is free and open-source. It was developed by MySQL AB in Sweden, later acquired by Sun Microsystems, which was then acquired by Oracle Corporation in 2010.
## 1.2 Characteristics of the Python Language
Python is a widely-used high-level programming language, famous for its readability and concise syntax. It supports various programming paradigms, including object-oriented, imperative, functional, and procedural programming. Python's simplicity and clear syntax make it an ideal choice for beginners, while also providing powerful functionality, making it widely used in many fields such as data science, machine learning, and web development.
## 1.3 Importance of Data Migration
Data migration is the process of transferring data from one database, system, or platform to another. This process may be for improving performance, upgrading technology, consolidating data, or sharing data during application mergers/separations. With the rapid growth of corporate data, efficient and accurate data migration becomes particularly important. In this process, Python can provide scripting, automation processing, and powerful data processing capabilities, thus playing a key role in data migration tasks.
# 2. Theory and Practice of MySQL Database Operations in Python
### 2.1 Basics of MySQL Database
#### 2.1.1 Concepts and Structure of MySQL Database
MySQL is a widely-used open-source relational database management system (RDBMS) that is based on SQL language and is known for its high performance, reliability, and ease of use. Before understanding how to use Python to operate databases, it is necessary to have an understanding of the basic concepts of MySQL.
- **Database**: A repository for data, a collection of data stored in a structured manner.
- **Table**: A logical object in a database used to store data of a specific type. A table consists of rows and columns.
- **Column**: A field in a table, each column has a data type, such as `INT`, `VARCHAR`, `DATETIME`, etc.
- **Row**: A record in a table, a collection of columns.
- **Index**: A database object that helps to quickly query specific data in a table. Indexes can be created on one or more columns of a table.
When designing a MySQL database, ***mon normal forms include the first normal form (1NF), the second normal form (2NF), the third normal form (3NF), etc.
```sql
-- Create a simple user information table
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
username VARCHAR(255) NOT NULL,
password VARCHAR(255) NOT NULL,
email VARCHAR(255),
created_at DATETIME
);
```
#### 2.1.2 Data Types and Table Design
When designing a table, choosing the appropriate data type is crucial for optimizing performance and storage efficiency. Here are some commonly used data types and their applications:
- `INT`: Used to store integers, suitable for storing user IDs, counts, etc.
- `VARCHAR`: Used to store variable-length strings, such as usernames, addresses, etc.
- `TEXT`: Used to store large text data, such as article content.
- `DATETIME`: Used to store date and time information, suitable for storing timestamps of events.
- `ENUM`: Used to store predefined values, such as user status ('active', 'inactive').
Table design includes not only the selection of columns but also the design of primary keys and indexes. A primary key is a unique identifier for a table, and indexes are used to improve query efficiency. A well-designed table structure can significantly improve database performance.
```sql
-- Add an index to optimize queries
CREATE INDEX idx_username ON users(username);
```
### 2.2 Multiple Methods to Connect MySQL with Python
In Python, there are multiple libraries available to operate MySQL databases. This section will introduce three mainstream methods.
#### 2.2.1 Using MySQL Connector/Python
MySQL Connector/Python is an official database driver that allows Python to connect directly to MySQL databases. After installing this module, it can be used to connect to databases and execute queries.
- Installation: `pip install mysql-connector-python`
- Connecting to the database: Use the `mysql.connector.connect()` method.
- Executing queries: Use the `cursor()` method to create a cursor and execute SQL commands.
```python
import mysql.connector
# Connect to the MySQL database
db = mysql.connector.connect(
host="localhost",
user="user",
password="password",
database="mydb"
)
# Create a cursor object
cursor = db.cursor()
# Execute a query
cursor.execute("SELECT * FROM users")
# Fetch the query results
for (user_id, username, email) in cursor:
print(f"ID: {user_id}, Username: {username}, Email: {email}")
# Close the connection
db.close()
```
#### 2.2.2 Utilizing the Third-Party Library pymysql
pymysql is another popular Python library for connecting to MySQL databases. Its usage is similar to MySQL Connector/Python, but the module name and some function calls are slightly different.
- Installation: `pip install pymysql`
- Connecting to the database: Use the `pymysql.connect()` method.
- Executing queries: Also use a cursor object.
```python
import pymysql
# Connect to the MySQL database
conn = pymysql.connect(host='localhost',
user='user',
password='password',
database='mydb',
cursorclass=pymysql.cursors.DictCursor)
# Create a cursor object
with conn.cursor() as cursor:
# Execute a query
sql = "SELECT * FROM users"
cursor.execute(sql)
# Fetch the query results
results = cursor.fetchall()
for row in results:
print(row['username'])
# Close the connection
conn.close()
```
#### 2.2.3 Using an ORM Framework like SQLAlchemy
SQLAlchemy is an object-relational mapping (ORM) library that can map Python objects to database tables, ***pared to the other two methods, using an ORM framework can make the code more concise and object-oriented.
- Installation: `pip install SQLAlchemy`
- Defining models: By defining classes corresponding to database tables.
- Connecting to the database: Use the `create_engine()` method to create a connection.
- Operating the database: Perform CRUD (Create, Read, Update, Delete) operations through the defined object models.
```python
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
Base = declarative_base()
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
username = Column(String)
email = Column(String)
# Connect to the MySQL database
engine = create_engine('mysql+mysqldb://user:password@localhost/mydb')
# Create all tables
Base.metadata.create_all(engine)
# Create a session
Session = sessionmaker(bind=engine)
session = Session()
# Add a new user
new_user = User(username='new_user', email='new_***')
session.add(new_user)
session.***mit()
# Close the session
session.close()
```
### 2.3 Transaction Management and Exception Handling
In database operations, transaction management is a key mechanism to ensure data consistency and integrity. Python provides various ways to manage transactions.
#### 2.3.1 Concepts and Importance of Transactions
A transaction is a set of operations that are either all completed or all not completed. The characteristics of a transaction are usually referred to as the ACID principle:
- Atomicity: All operations in a transaction must either all be executed or all not executed.
- Consistency: A transaction must ensure that the database transitions from one consistent state to another.
- Isolation: The execution of a transaction should not be interfered with by other transactions.
- Durability: Once a transaction is completed, its results should be permanently saved in the database.
#### 2.3.2 Transaction Control in Python
Python provides transaction control functionality through its database connection libraries. Whether using the native database API or an ORM framework, explicit transaction control is possible.
```python
# Using pymysql to control transactions
conn = pymysql.connect(host='localhost',
user='user',
password='password',
database='mydb',
cursorclass=pymysql.cursors.DictCursor)
try:
with conn.cursor() as cursor:
# Start a transaction
conn.autocommit(False)
# Execute multiple operations
sql1 = "UPDATE users SET email='new_***' WHERE id=1"
sql2 = "UPDATE users SET email='another_new_***' WHERE id=2"
cursor.execute(sql1)
cursor.execute(sql2)
# Commit the transaction
conn.***mit()
except Exception as e:
# Roll back the transaction
conn.rollback()
finally:
conn.close()
```
#### 2.3.3 Best Practices for Exception Handling
Exception handling is a key part of writing reliable database code. In Python, try-except statements can be used to catch and handle exceptions that may occur during database operations.
```python
try:
# A database operation that might fail
db.execute("SELECT * FROM non_existent_table")
except mysql.connector.Error as e:
print(f"Error: {e}")
# You can log the error or return an error message to the user
```
By reasonably using exception handling, stability and predictability can be maintained in the program when errors occur, improving the user experience and data security.
# 3. Data Migration Techniques and Strategies
In today's data-driven era, data migration has become an indispensable part of corporate activities such as system upgrades, cloud migrations, mergers and

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【EDA课程进阶秘籍】:优化仿真流程,强化设计与仿真整合

# 摘要
随着集成电路设计复杂性的增加,EDA(电子设计自动化)课程与设计仿真整合的重要性愈发凸显。本文全面探讨了EDA工具的基础知识与应用,强调了设计流程中仿真验证和优化的重要性。文章分析了仿真流程的优化策略,包括高
DSPF28335 GPIO故障排查速成课:快速解决常见问题的专家指南

# 摘要
本文详细探讨了DSPF28335的通用输入输出端口(GPIO)的各个方面,从基础理论到高级故障排除策略,包括GPIO的硬件接口、配置、模式、功能、中断管理,以及在实践中的故障诊断和高级故障排查技术。文章提供了针对常见故障类型的诊断技巧、工具使用方法,并通过实际案例分析了故障排除的过程。此外,文章还讨论了预防和维护GPIO的策略,旨在帮助
掌握ABB解包工具的最佳实践:高级技巧与常见误区

# 摘要
本文旨在介绍ABB解包工具的基础知识及其在不同场景下的应用技巧。首先,通过解包工具的工作原理与基础操作流程的讲解,为用户搭建起使用该工具的初步框架。随后,探讨了在处理复杂包结构时的应用技巧,并提供了编写自定义解包脚本的方法。文章还分析了在实际应用中的案例,以及如何在面对环境配置错误和操
【精确控制磁悬浮小球】:PID控制算法在单片机上的实现
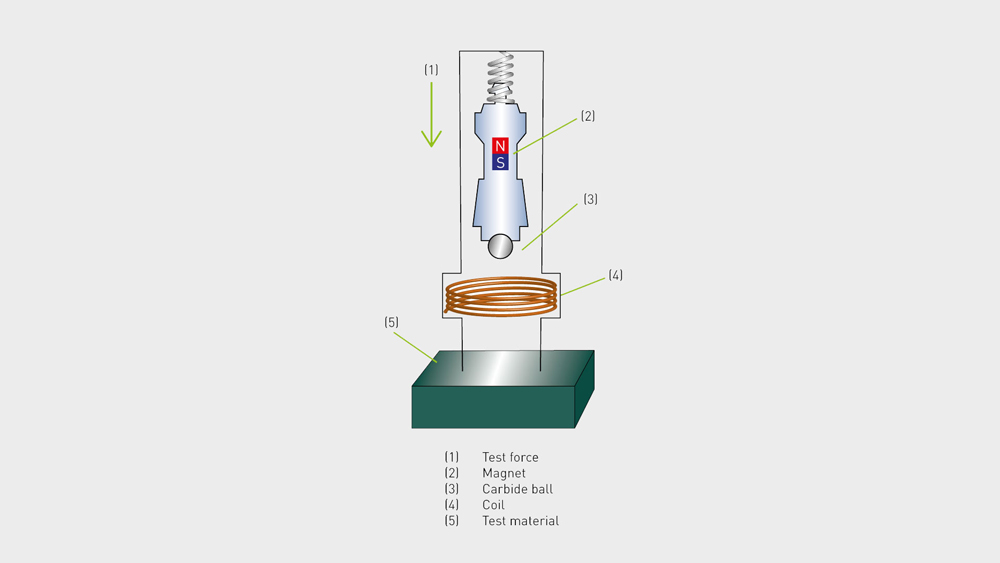
# 摘要
本文综合介绍了PID控制算法及其在单片机上的应用实践。首先概述了PID控制算法的基本原理和参数整定方法,随后深入探讨了单片机的基础知识、开发环境搭建和PID算法的优化技术。通过理论与实践相结合的方式,分析了PID算法在磁悬浮小球系统中的具体实现,并展示了硬件搭建、编程以及调试的过程和结果。最终,文章展望了PID控制算法的高级应用前景和磁悬浮技术在工业与教育中的重要性。本文旨在为控制工程领
图形学中的纹理映射:高级技巧与优化方法,提升性能的5大策略
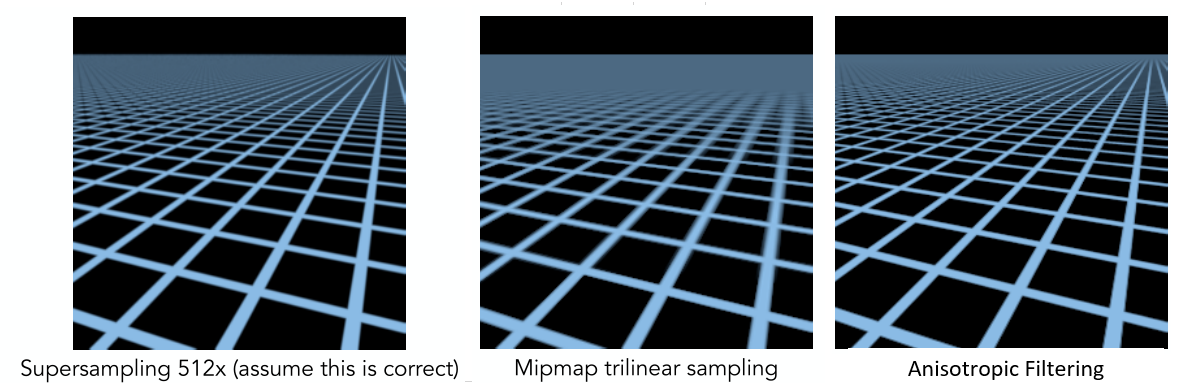
# 摘要
本文系统地探讨了纹理映射的基础理论、高级技术和优化方法,以及在提升性能和应用前景方面的策略。纹理映射作为图形渲染中的核心概念,对于增强虚拟场景的真实感和复杂度至关重要。文章首先介绍了纹理映射的基本定义及其重要性,接着详述了不同类型的纹理映射及应用场景。随后,本文深入探讨了高级纹理映射技术,包括纹理压缩、缓存与内存管理和硬件加速,旨在减少资源消耗并提升
【Typora插件应用宝典】:提升写作效率与体验的15个必备插件
# 摘要
本论文详尽探讨了Typora这款Markdown编辑器的界面设计、编辑基础以及通过插件提升写作效率和阅读体验的方法。文章首先介绍了Typora的基本界面与编辑功能,随后深入分析了多种插件如何辅助文档结构整理、代码编写、写作增强、文献管理、多媒体内容嵌入及个性化定制等方面。此外,文章还讨论了插件管理、故障排除以及如何保证使用插件时
RML2016.10a字典文件深度解读:数据结构与案例应用全攻略
# 摘要
本文全面介绍了RML2016.10a字典文件的结构、操作以及应用实践。首先概述了字典文件的基本概念和组成,接着深入解析了其数据结构,包括头部信息、数据条目以及关键字与值的关系,并探讨了数据操作技术。文章第三章重点分析了字典文件在数据存储、检索和分析中的应用,并提供了实践中的交互实例。第四章通过案例分析,展示了字典文件在优化、错误处理、安全分析等方面的应用及技巧。最后,第五章探讨了字典文件的高
【Ansoft软件精通秘籍】:一步到位掌握电磁仿真精髓
# 摘要
本文详细介绍了Ansoft软件的功能及其在电磁仿真领域的应用。首先概述了Ansoft软件的基本使用和安装配置,随后深入讲解了基础电磁仿真理论,包括电磁场原理、仿真模型建立、仿真参数设置和网格划分的技巧。在实际操作实践章节中,作者通过多个实例讲述了如何使用Ansoft HFSS、Maxwell和Q3D Extractor等工具进行天线、电路板、电机及变压器等的电磁仿真。进而探讨了Ansoft的高级技巧
负载均衡性能革新:天融信背后的6个优化秘密
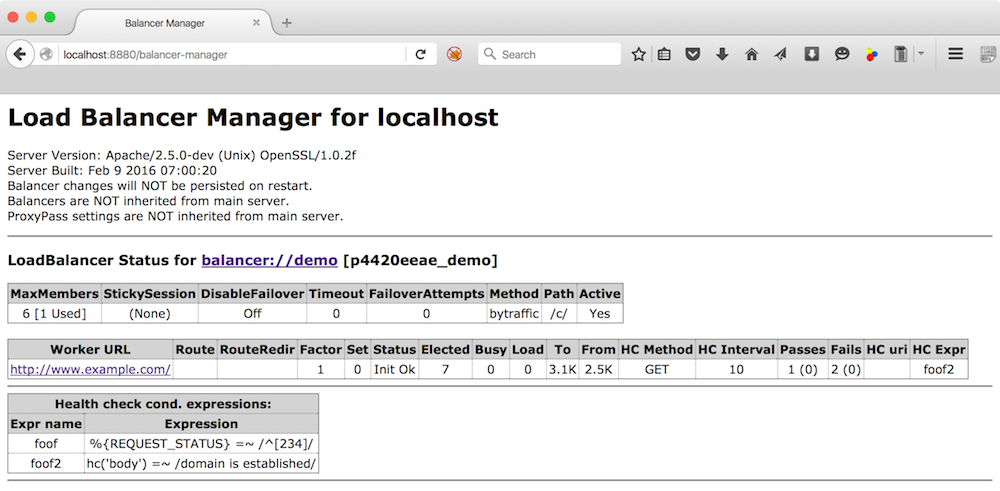
# 摘要
负载均衡技术是保障大规模网络服务高可用性和扩展性的关键技术之一。本文首先介绍了负载均衡的基本原理及其在现代网络架构中的重要性。继而深入探讨了天融信的负载均衡技术,重点分析了负载均衡算法的选择标准、效率与公平性的平衡以及动态资源分配机制。本文进一步阐述了高可用性设计原理,包括故障转移机制、多层备份策略以及状态同步与一致性维护。在优化实践方面,本文讨论了硬件加速、性能调优、软件架构优化以及基于AI的自适应优化算法。通过案例
【MAX 10 FPGA模数转换器时序控制艺术】:精确时序配置的黄金法则
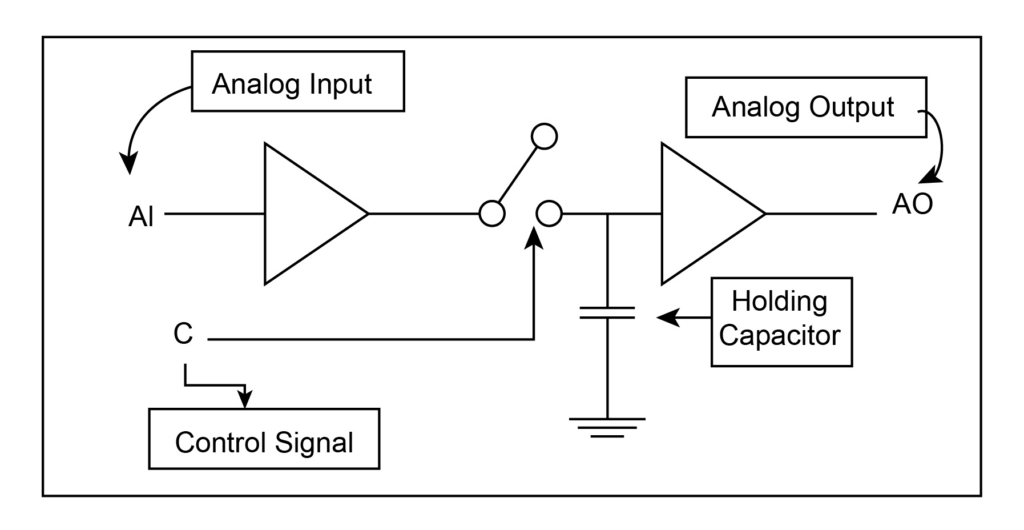
# 摘要
本文主要探讨了FPGA模数转换器时序控制的基础知识、理论、实践技巧以及未来发展趋势。首先,从时序基础出发,强调了时序控制在保证FPGA性能中的重要性,并介绍了时序分析的基本方法。接着,在实践技巧方面,探讨了时序仿真、验证、高级约束应用和动态时序调整。文章还结合MAX 10 FPGA的案例,详细阐述了模数转换器的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )