Python Operations on MySQL Data: Revealing Real-world CRUD Tips
发布时间: 2024-09-12 14:44:56 阅读量: 66 订阅数: 48 
# Python Operations on MySQL Data: Advanced CRUD Techniques Revealed
In today's field of information technology, Python has become a popular programming language, offering great convenience and flexibility when interacting with MySQL databases. This chapter will serve as an introductory guide, leading readers through the basics of using Python to connect to MySQL databases and perform foundational database operations. This includes installing the necessary Python libraries, configuring database connections, and executing simple data queries and updates.
## 1.1 Installation and Configuration of Database Connections
Before you begin writing Python code to interact with MySQL, you must first ensure that MySQL is installed and that you have installed Python's database interface library. The most commonly used library is `mysql-connector-python`, which can be installed using pip:
```bash
pip install mysql-connector-python
```
Once installed, to configure your database connection, you will need to specify the database address, username, password, and the name of the database you wish to connect to. Below is a simple example of connection code:
```python
import mysql.connector
# Configure database connection parameters
db_config = {
'host': 'localhost',
'user': 'your_username',
'password': 'your_password',
'database': 'your_database'
}
# Create a database connection
cnx = mysql.connector.connect(**db_config)
# Create a cursor object
cursor = cnx.cursor()
```
## 1.2 Executing Basic Database Operations
With the cursor object created above, we can execute SQL statements to perform basic CRUD (Create, Read, Update, Delete) operations on a MySQL database. Below are some basic operation code examples:
```python
# Insert data
cursor.execute("INSERT INTO table_name (column1, column2) VALUES (%s, %s)", (value1, value2))
# Query data
cursor.execute("SELECT * FROM table_name")
rows = cursor.fetchall()
for row in rows:
print(row)
# Update data
cursor.execute("UPDATE table_name SET column1 = %s WHERE column2 = %s", (value1, value2))
# Delete data
cursor.execute("DELETE FROM table_name WHERE column1 = %s", (value1,))
```
Beyond the basic content introduced above, operating MySQL databases in Python also includes more advanced topics such as exception handling, connection pooling, and performance optimization. These will be explained in detail in subsequent chapters. With the introduction of this chapter, you will lay a solid foundation for in-depth learning of advanced Python and MySQL interactions.
# 2. Detailed Explanation of CRUD Operations
## 2.1 Create Operation
### 2.1.1 Basic Method of Inserting Data
In database operations, creating (Create) is the first and crucial step. In Python, we typically use MySQLdb or PyMySQL libraries to create and manage databases. First, we need to establish a connection to the MySQL database, and then execute SQL statements to insert data.
```python
import MySQLdb
# Connect to the database
db = MySQLdb.connect("host", "user", "password", "database")
cursor = db.cursor()
# Prepare SQL statement for inserting data
sql = "INSERT INTO table_name (column1, column2) VALUES (%s, %s)"
val = ("value1", "value2")
try:
# Execute SQL statement
cursor.execute(sql, val)
# Commit transaction
***mit()
except MySQLdb.Error as e:
# Roll back transaction
db.rollback()
print(e)
finally:
# Close cursor and connection
cursor.close()
db.close()
```
This code demonstrates the basic method of inserting data using the MySQLdb library in Python. It shows the connection to the database, the creation of a cursor object, the execution of an insert statement, and the importance of committing the transaction and closing the cursor and connection to ensure proper resource release. Exception handling is also essential to properly manage any errors that may occur during the operation.
### 2.1.2 Batch Insertion and Performance Optimization
While inserting single pieces of data is simple, it can be highly inefficient when dealing with large amounts of data. Therefore, batch insertion is an effective method to improve insertion efficiency.
```python
import MySQLdb
# Connect to the database
db = MySQLdb.connect("host", "user", "password", "database")
cursor = db.cursor()
# Prepare batch insertion data
values = [
("value1", "value2"),
("value3", "value4"),
("value5", "value6"),
]
sql = "INSERT INTO table_name (column1, column2) VALUES (%s, %s)"
try:
# Execute batch insertion
cursor.executemany(sql, values)
***mit()
except MySQLdb.Error as e:
db.rollback()
print(e)
finally:
cursor.close()
db.close()
```
In the above code, the `cursor.executemany()` ***pared to inserting data row by row, `executemany()` can insert multiple pieces of data at once, significantly improving the efficiency of data insertion. Additionally, when processing a large amount of data, you can also consider turning on transactions, disabling auto-commit mode, to reduce database I/O operations, thus further optimizing performance.
## 2.2 Read Operation
### 2.2.1 Building Basic Query Statements
Query operations are the most frequent and important part of database operations. Building basic query statements usually involves the use of the SELECT statement, which can retrieve data from the database.
```python
import MySQLdb
# Connect to the database
db = MySQLdb.connect("host", "user", "password", "database")
cursor = db.cursor()
# Build basic query statement
sql = "SELECT column1, column2 FROM table_name WHERE condition"
try:
# Execute query statement
cursor.execute(sql)
# Get all query results
results = cursor.fetchall()
for row in results:
print(row)
except MySQLdb.Error as e:
print(e)
finally:
cursor.close()
db.close()
```
Executing the above Python script can retrieve the required data from the specified table based on conditions and return it as tuples. Here, the `fetchall()` method is used to obtain all results. If pagination is required, it can be combined with LIMIT and OFFSET.
### 2.2.2 Implementation Tips for Complex Queries
In real-world application scenarios, we often need to perform complex query operations, such as multi-table join queries, subqueries, and aggregate queries. This requires the use of SQL statements' powerful features to achieve complex data retrieval.
```python
import MySQLdb
# Connect to the database
db = MySQLdb.connect("host", "user", "password", "database")
cursor = db.cursor()
# Build complex query statement
sql = """
SELECT table1.column1, ***
***mon_field = ***mon_field
WHERE table1.column3 > %s
GROUP BY table1.column1
HAVING COUNT(*) > %s
ORDER BY table1.column1
LIMIT %s, %s
"""
try:
# Execute complex query statement
cursor.execute(sql, (value1, value2, offset, limit))
# Get paginated query results
results = cursor.fetchall()
for row in results:
print(row)
except MySQLdb.Error as e:
print(e)
finally:
cursor.close()
db.close()
```
In this example, we implemented an inner join query, grouped and aggregated results by a column, and then sorted and paginated the results. This is a relatively complex query operation, and through the understanding and application of SQL statements, we can effectively implement various data retrieval needs.
## 2.3 Update Operation
### 2.3.1 Strategies for Updating a Single Table
Data update operations are typically performed using the `UPDATE` statement, which allows us to modify existing records in a table. The correct update strategy is crucial for maintaining data integrity and accuracy.
```python
import MySQLdb
# Connect to the database
db = MySQLdb.connect("host", "user", "password", "database")
cursor = db.cursor()
# Build update statement
sql = "UPDATE table_name SET column1 = %s, column2 = %s WHERE condition"
try:
# Execute update operation
cursor.execute(sql, (value1, value2))
***mit()
except MySQLdb.Error as e:
db.rollback()
print(e)
finally:
cursor.close()
db.close()
```
In this example, we updated the `column1` and `column2` fields in the `table_name` table with new values and only modified records that met the `condition`. ***revent data conflicts and inconsistencies, it is common practice to lock the relevant records before updating.
### 2.3.2 Multi-table Joint Updates in Real-world Scenarios
In some complex business scenarios, it is necessary to update data in a table based on data from other tables, and this is where multi-table joint updates come into play.
```python
import MySQLdb
# Connect to the database
db = MySQLdb.connect("host", "user", "password", "database")
cursor = db.cursor()
# Build multi-table joint update statement
sql = """
UPDATE table1
SET table1.column = (SELECT column FROM table2 WHERE condition)
WHERE exists (***mon_field = ***mon_field AND condition)
"""
try:
# Execute multi-table joint update operation
cursor.execute(sql)
***mit()
except MySQLdb.Error as e:
db.rollback()
print(e)
finally:
cursor.close()
db.close()
```
This example demonstrates the application of updates across multiple tables. With subqueries, we can update corresponding data in `table1` based on data from `table2`. It is important to ensure that subqueries return the expected results and to pay attention to the performance impact of SQL statements, especially when dealing with large amounts of data.
## 2.4 Delete Operation
### 2.4.1 Principles of Safe Data Deletion
Data deletion should follow the principle of minimizing operations to ensure it does not affect the integrity of other related data. Before performing deletion operations, data should be fully backed up to prevent any mishaps.
```python
import MySQLdb
# Connect to the database
db = MySQLdb.connect("host", "user", "password", "database")
cursor = db.cursor()
# Build delete statement
sql = "DELETE FROM table_name WHERE condition"
try:
# Execute delete operation
cursor.execute(sql)
***mit()
except MySQLdb.Error as e:
db.rollback()
print(e)
finally:
cursor.close()
db.close()
```
In the above Python code, we used the `DELETE FROM` statement to delete records that met specific conditions. When executing delete operations, make sure the conditions are accurate to avoid accidentally deleting important data. Before deleting a large amount of data, consider using the `TRUNCATE` statement, which can more efficiently clear all data from a table.
### 2.4.2 The Difference Between Batch Deletion and L

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
WinRAR CVE-2023-38831漏洞快速修复解决方案

# 摘要
本文详细阐述了WinRAR CVE-2023-38831漏洞的技术细节、影响范围及利用原理,并探讨了系统安全防护理论,包括安全防护层次结构和防御策略。重点介绍了漏洞快速检测与响应方法,包括使用扫描工具、风险评估、优先级划分和建立应急响应流程。文章进一步提供了WinRAR漏洞快速修复的实践
【QWS数据集实战案例】:深入分析数据集在实际项目中的应用
# 摘要
数据集是数据科学项目的基石,它在项目中的基础角色和重要性不可小觑。本文首先讨论了数据集的选择标准和预处理技术,包括数据清洗、标准化、特征工程等,为数据分析打下坚实基础。通过对QWS数据集进行探索性数据分析,文章深入探讨了统计分析、模式挖掘和时间序列分析,揭示了数据集内在的统计特性、关联规则以及时间依赖性。随后,本文分析了QWS数据集在金融、医疗健康和网络安全等特定领域的应用案例,展现了其在现实世界问题中
【跨平台远程管理解决方案】:源码视角下的挑战与应对
# 摘要
随着信息技术的发展,跨平台远程管理成为企业维护系统、提升效率的重要手段。本文首先介绍了跨平台远程管理的基础概念,随后探讨了在实施过程中面临的技术挑战,包括网络协议的兼容性、安全性问题及跨平台兼容性。通过实际案例分析,文章阐述了部署远程管理的前期准备、最佳实践以及性能优化和故障排查的重要性。进阶技术章节涵盖自动化运维、集群管理与基于云服务的远程管理。最后
边缘检测技术大揭秘:成像轮廓识别的科学与艺术

# 摘要
边缘检测技术是图像处理和计算机视觉领域的重要分支,对于识别图像中的物体边界、特征点以及进行场景解析至关重要。本文旨在概述边缘检测技术的理论基础,包括其数学模型和图像处理相关概念,并对各种边缘检测方法进行分类与对比。通过对Sobel算法和Canny边缘检测器等经典技术的实战技巧进行分析,探讨在实际应用中如何选择合适的边缘检测算法。同时,本文还将关注边缘检测技术的
Odroid XU4性能基准测试

# 摘要
Odroid XU4作为一款性能强大且成本效益高的单板计算机,其性能基准测试成为开发者和用户关注的焦点。本文首先对Odroid XU4硬件规格和测试环境进行详细介绍,随后深入探讨了性能基准测试的方法论和工具。通过实践测试,本文对CPU、内存与存储性能进行了全面分析,并解读了测试
TriCore工具使用手册:链接器基本概念及应用的权威指南

# 摘要
本文深入探讨了TriCore工具与链接器的原理和应用。首先介绍了链接器的基本概念、作用以及其与编译器的区别,然后详细解析了链接器的输入输出、链接脚本的基础知识,以及链接过程中的符号解析和内存布局控制。接着,本文着重于TriCore链接器的配置、优化、高级链
【硬件性能革命】:揭秘液态金属冷却技术对硬件性能的提升

# 摘要
液态金属冷却技术作为一种高效的热管理方案,近年来受到了广泛关注。本文首先介绍了液态金属冷却的基本概念及其理论基础,包括热传导和热交换原理,并分析了其与传统冷却技术相比的优势。接着,探讨了硬件性能与冷却技术之间的关系,以及液态金属冷却技术在实践应用中的设计、实现、挑战和对策。最后,本文展望了液态金属冷却技术的未来,包括新型材料的研究和技术创新的
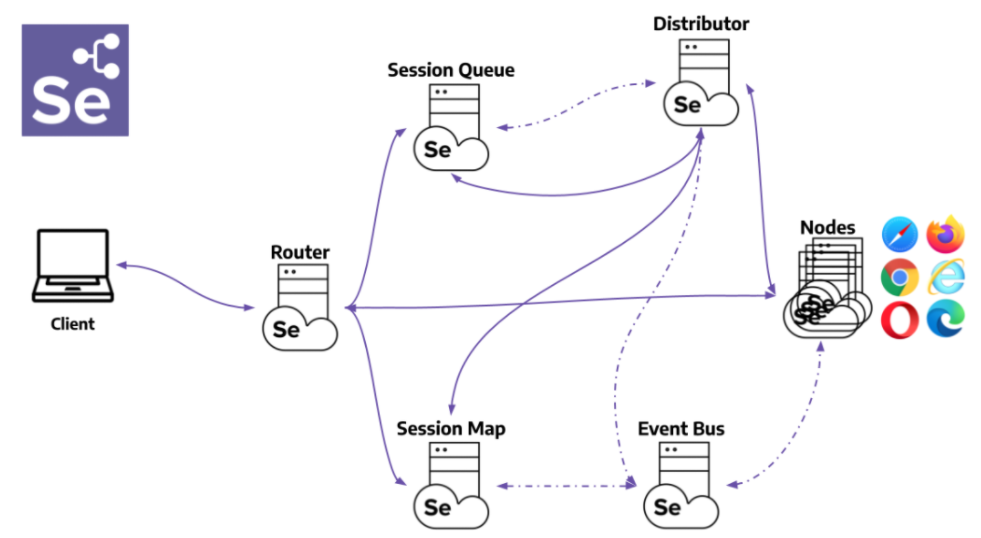
【企业级测试解决方案】:C# Selenium自动化框架的搭建与最佳实践
# 摘要
随着软件开发与测试需求的不断增长,企业级测试解决方案的需求也在逐步提升。本文首先概述了企业级测试解决方案的基本概念,随后深入介绍了C#与Selenium自动化测试框架的基础知识及搭建方法。第三章详细探讨了Selenium自动化测试框架的实践应用,包括测试用例设计、跨浏览器测试的实现以及测试数据的管理和参数化测试。第四章则聚焦于测试框架的进阶技术与优化,包括高级操作技巧、测试结果的分析与报告生成以及性能和负
三菱PLC-FX3U-4LC高级模块应用:详解与技巧

# 摘要
本论文全面介绍了三菱PLC-FX3U-4LC模块的技术细节与应用实践。首先概述了模块的基本组成和功能特点,接着详细解析了其硬件结构、接线技巧以及编程基础,包括端口功能、
【CAN总线通信协议】:构建高效能系统的5大关键要素

# 摘要
CAN总线作为一种高可靠性、抗干扰能力强的通信协议,在汽车、工业自动化、医疗设备等领域得到广泛应用。本文首先对CAN总线通信协议进行了概述,随后深入分析了CAN协议的理论基础,包括数据链路层与物理层的功能、CAN消息的传输机制及错误检测与处理机制。在实践应用方面,讨论了CAN网络的搭建、消息过滤策略及系统集成和实时性优化。同时,本文还探讨了CAN协议在不同行业的具体应用案例,及其在安全性和故障诊断方面的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )