5 Essential Tips to Master pyMySQL and MySQLdb Libraries for Connecting Python to MySQL
发布时间: 2024-09-12 14:39:15 阅读量: 37 订阅数: 38 

Python:连接mysql数据库的三种方式,mysql.connector, pymysql, MYSQLdb
# 5 Key Techniques to Master pyMySQL and MySQLdb Libraries in Python
In the IT industry, the combination of Python and MySQL has become a common practice for database operations. This chapter will introduce the basic but crucial methods of connecting Python to MySQL, laying the foundation for further in-depth discussions.
## 1.1 Choice of Drivers
When operating MySQL in Python, ***mon ones include `MySQLdb`, `pymysql`, etc. These libraries, based on the MySQL C API, provide a pure Python interface for database interaction.
## 1.2 Connection Methods
First, ensure the appropriate Python libraries are installed. Taking `pymysql` as an example, you can establish a connection through the following steps:
```python
import pymysql
# Establish connection
connection = pymysql.connect(host='localhost', user='root', password='password', db='testdb')
# Create cursor object
cursor = connection.cursor()
# Execute SQL command
cursor.execute("SHOW DATABASES")
# Process the result set
for row in cursor:
print(row)
# Close cursor and connection
cursor.close()
connection.close()
```
This code demonstrates how to install `pymysql`, establish a connection, create a cursor, execute a query, iterate over the query results, and finally close the connection.
## 1.3 Executing SQL Statements
In the code above, the SQL statement is executed through the `cursor.execute()` method. The basic steps to execute SQL statements in Python can be summarized as follows:
1. Establish a database connection.
2. Create a cursor object.
3. Use the cursor to execute SQL commands.
4. Process the results of the SQL command execution (e.g., query results).
***mit or rollback transactions.
6. Close the cursor and database connection.
Mastering the basic connection methods is the first step in database programming. In the next chapter, we will delve into how to install and configure `pyMySQL` and `MySQLdb` libraries and explore their differences.
# 2. In-depth Understanding of pyMySQL and MySQLdb Libraries
## 2.1 Installation and Configuration of pyMySQL and MySQLdb
### 2.1.1 Installing pyMySQL and MySQLdb
Before interacting with MySQL databases using Python, it'***o commonly used libraries in Python for interacting with MySQL databases are `MySQLdb` and `pyMySQL`. `MySQLdb` is a popular third-party library for connecting to MySQL databases, while `pyMySQL` is a pure Python library compatible with `MySQLdb` API and is written entirely in Python, allowing it to run in environments where `MySQLdb` is not supported, such as some virtual environments.
- `MySQLdb` Installation:
```bash
pip install mysqlclient
```
- `pyMySQL` Installation:
```bash
pip install pymysql
```
Before installing these libraries, please ensure that your system has the MySQL Python module and the corresponding database engine installed.
### 2.1.2 Configuring Connection Parameters
After installing the corresponding libraries, the next step is to configure the database connection parameters. These parameters include the database host address, port, username, password, etc. Correct connection parameters are a prerequisite for establishing a database connection.
Here is an example code for configuring connection parameters:
```python
import pymysql
# Connection parameter configuration
db_config = {
'host': 'localhost',
'port': 3306,
'user': 'root',
'password': 'your_password',
'db': 'your_database',
'charset': 'utf8mb4',
'cursorclass': pymysql.cursors.DictCursor
}
# Establish database connection
connection = pymysql.connect(**db_config)
```
In this example, we use the `pymysql` module to configure the connection parameters and create a database connection through the `connect()` method. The parameter `**db_config` uses Python's parameter unpacking syntax to unpack the dictionary as keyword arguments to the `connect()` function.
Important parameter explanations:
- `host`: IP address or hostname of the database server.
- `port`: The listening port of the MySQL service on the database server, defaulting to 3306.
- `user`: MySQL username for connecting to the database.
- `password`: Password corresponding to the aforementioned user.
- `db`: Name of the database to connect to.
- `charset`: Character set used for the connection, defaulting to `utf8mb4`, supporting 4-byte Unicode characters.
- `cursorclass`: Type of cursor used, `pymysql.cursors.DictCursor` indicates that the result set is returned as a dictionary.
After configuring the connection parameters, we can proceed to the next step, which is to establish a connection to MySQL and perform cursor operations.
## 2.2 Use of Database Connections and Cursors
### 2.2.1 Establishing a Connection to MySQL
In the previous section, we configured connection parameters through code and created a database connection object. Establishing a database connection is the first step in performing database operations.
Establishing a connection using `pymysql` or `MySQLdb` typically looks like this:
```python
import pymysql
connection = pymysql.connect(
host='localhost',
port=3306,
user='root',
password='your_password',
db='your_database'
)
```
This code creates a MySQL database connection object `connection`. To prevent resource leaks, the database connection should be closed after use. The best practice is to operate the database within a `try...finally` block to ensure that the database connection is closed even if an exception occurs.
```python
try:
# Database operation code
pass
finally:
connection.close()
```
### 2.2.2 Creation and Basic Operations of a Cursor
A cursor is an important concept in database operations, allowing us to execute SQL commands and retrieve result sets, among other things. In `pymysql` or `MySQLdb`, the cursor object is typically created after establishing a connection.
Here is an example of creating a cursor:
```python
cursor = connection.cursor()
```
With a cursor object, we can execute SQL commands. For example, to execute a simple `SELECT` query:
```python
cursor.execute("SELECT * FROM some_table")
result = cursor.fetchall()
```
The `fetchall()` method retrieves all result sets of the SQL command executed by the cursor. In addition to `fetchall()`, there are other methods such as `fetchone()` to retrieve the next row in the result set, and `fetchmany(size)` to retrieve a number of rows from the result set.
### 2.2.3 Transaction Handling and Optimization
Transactions are a feature of database management systems that allow us to group multiple operations into a single logical unit, either executing all of them or none at all. In Python, we can use `pymysql` or `MySQLdb` to handle transactions to ensure data consistency.
Here is an example of starting a transaction:
```python
connection.autocommit(False) # Disable auto-commit
```
When manually controlling transactions, we need to call the `commit()` method to commit the transaction after all transaction operations are completed, or call the `rollback()` method to roll back the transaction to a previous state in case of a failure.
```python
try:
# ***
***mit() # Commit the transaction
except Exception as e:
connection.rollback() # Roll back the transaction
raise e
finally:
connection.close() # Close the connection
```
When using transactions, optimization should also be considered. For example, performing a large amount of data operations within a single transaction may lead to performance degradation. In such cases, the transaction can be divided into smaller parts to reduce the time resources are locked and improve overall system performance.
## 2.3 Executing SQL Statements in Python
### 2.3.1 Performing Basic CRUD Operations
CRUD operations refer to the database actions of Create, Read, Update, and Delete. Executing these basic database operations through Python can help developers manage the lifecycle of data.
- Create (Insert)
```python
cursor.execute("INSERT INTO some_table (column1, column2) VALUES (%s, %s)", (value1, value2))
***mit()
```
- Read (Select)
```python
cursor.execute("SELECT * FROM some_table")
result = cursor.fetchall()
```
- Update (Update)
```python
cursor.execute("UPDATE some_table SET column1 = %s WHERE column2 = %s", (value1, value2))
***mit()
```
- Delete (Delete)
```python
cursor.execute("DELETE FROM some_table WHERE column1 = %s", (value1,))
***mit()
```
In the CRUD operations above, the `execute()` method is used to perform SQL statements, where for SQL statements containing parameters, `%s` is used as a placeholder and a tuple provides the actual values.
### 2.3.2 Use and Advantages of Prepared Statements
Prepared statements are a technique to optimize database operations, allowing SQL statements to be precompiled and reused multiple times, only changing the parameters without the need to recompile the SQL statement. This can improve performance when executing the same database operation multiple times and reduce the risk of SQL injection.
An example of using prepared statements:
```python
# Prepared statement
prepared_query = "INSERT INTO some_table (column1, column2) VALUES (%s, %s)"
cursor.execute(prepared_query, (value1, value2))
# Reusing the same statement, only changing parameters
cursor.execute(prepared_query, (value3, value4))
***mit()
```
In prepared statements, we first use the `cursor.execute()` method to execute the SQL statement without immediately providing parameter values. Then, the same statement can be used multiple times, each time passing different parameter values. Prepared statements can be reused, which is particularly useful for loops or batch operations.
In this chapter, we have delved into the basic use of `pyMySQL` and `MySQLdb` libraries, including installation, configuring connection parameters, establishing database connections, using cursors, and handling transactions. We have also learned how to execute SQL statements in Python, including basic CRUD operations and the use of prepared statements. This knowledge will lay a solid foundation for the advanced data manipulation techniques introduced in the next chapter.
# 3 Advanced Techniques for Data Manipulation
## 3.1 Complex Queries and Result Processing
### 3.1.1 Pagination Queries and Data Filtering
Pagination queries are a common technique when dealing with large amounts of data, effectively reducing memory consumption and improving the responsiveness of the user interface. In Python, pagination queries are usually implemented by combining the SQL statements' LIMIT and OFFSET clauses. Here is an example of a pagination query:
```python
def fetch_data(page, pagesize):
"""
Fetch paginated data
:param page: Current page number
:param pagesize: Number of data entries per page
:return: List of paginated data
"""
offset = (page - 1) * pagesize
query = """
SELECT * FROM table_name LIMIT %s OFFSET %s;
"""
results = connection.cursor().execute(query, (pagesize, offset))
return results.fetchall()
```
To filter data, we can use the WHERE clause in SQL queries to specify filter conditions. In Python, to prevent SQL injection, we recommend using parameterized query statements.
```python
def fetch_filtered_data(column, condition):
"""
Fetch filtered data
:param column: Column name in the database
:param condition: Filter condition
:return: List of filtered data entries
"""
query = """
SELECT * FROM table_name WHERE {col} {cond};
"""
query = query.format(col=column, cond=condition)
results = connection.cursor().execute(query)
return results.fetchall()
```
### 3.1.2 Efficient Handling of Large Data Volumes
Handling large volumes of data requires considerations of performance and efficiency. Here, we can use some advanced query techniques and optimization strategies.
- Index optimization: Creating indexes can speed up queries but requires a trade-off between write performance and storage space.
- Use specific features provided by the database, such as partitioned tables, to improve query and management performance for large data.
- For very large datasets, consider using batch processing techniques, querying and processing data in segments.
The following code demonstrates how to use batch processing to handle large amounts of data:
```python
def process_large_data(batch_size):
"""
Batch processing technique for handling large amounts of data
:param batch_size: Number of data entries per batch
"""
offset = 0
while True:
query = """
SELECT * FROM table_name LIMIT %s OFFSET %s;
"""
results = connection.cursor().execute(query, (batch_size, offset))
if not results:
break
for row in results:
process_data(row) # Custom data processing function
offset += batch_size
```
### 3.2 Error Handling and Exception Management
#### 3.2.1 Exception Capturing and Logging
When executing database operations, error handling is an essential part. Using try-except statements to catch possible exceptions and logging error messages is the best practice.
```python
import logging
def safe_query(query, params=None):
"""
Safely execute SQL queries
:param query: SQL query statement
:param params: SQL query parameters
:return: Query results
"""
try:
if params:
cursor = connection.cursor()
cursor.execute(query, params)
return cursor.fetchall()
else:
cursor = connection.cursor()
cursor.execute(query)
return cursor.fetchall()
except Exception as e:
logging.error(f"Error occurred: {e}")
raise
logging.basicConfig(filename='db_errors.log', level=logging.ERROR)
```
#### 3.2.2 Graceful Handling of Database Connection Disruptions
Database connections may be disrupted due to network issues or other reasons. To ensure the robustness of applications, we need to be able to handle these situations gracefully.
```python
def execute_query(query, params=None):
"""
Execute queries and gracefully handle database connection disruptions
:param query: SQL query statement
:param params: SQL query parameters
:return: Query results
"""
try:
# Attempt to execute the query
results = safe_query(query, params)
return results
except OperationalError as oe:
if "server has gone away" in str(oe):
logging.warning("Connection is lost, reconnecting...")
connection.close() # Close the current connection
connection = None # Clear the connection object
# Attempt to reconnect
while connection is None:
try:
connection = connect_to_db() # Custom database connection function
except Exception as e:
logging.error(f"Reconnection failed: {e}")
time.sleep(5) # Retry interval
# Re-execute the query
return execute_query(query, params)
else:
raise # Throw other types of exceptions
```
### 3.3 Batch Operations and Performance Optimization
#### 3.3.1 Batch Insertion and Updates
Batch operations can greatly improve the performance of database operations. For example, batch insertion (BULK INSERT) can insert multiple records at once, reducing the number of database I/O operations.
```python
def bulk_insert(data_list):
"""
Perform batch insertion operations
:param data_list: List of data to insert, each element is a tuple or dictionary
"""
# Construct insertion statement based on data format
placeholders = ",".join(["(%s,)"] * len(data_list))
query = f"INSERT INTO table_name (col1, col2) VALUES {placeholders}"
try:
with connection.cursor() as cursor:
cursor.executemany(query, data_list)
***mit()
except Exception as e:
logging.error(f"Failed to insert: {e}")
connection.rollback()
# Example data format
data = [(1, 'data1'), (2, 'data2'), ...]
bulk_insert(data)
```
#### 3.3.2 Performance Optimization Strategies
Performance optimization includes not only batch operations but also index optimization, query optimization, connection pooling, and more.
Index optimization has already been mentioned. Here is an example of using query optimization:
```python
def optimized_query(column_list, join_type='INNER'):
"""
Optimized query example
:param column_list: List of column names to query
:param join_type: Join type, defaults to INNER JOIN
"""
columns = ", ".join(column_list)
query = f"""
SELECT {columns} FROM table1 {join_type} JOIN table2
ON table1.id = table2.foreign_id
WHERE table1.condition_column = %s;
"""
return connection.cursor().execute(query, ('condition_value',))
```
We can identify and optimize slow queries by analyzing the query plan, execution time statistics, and database logs. In addition, advanced query optimization can be achieved in Python projects by integrating specialized tools such as SQLAlchemy.
# 4 Database Practices in Python Projects
During project development, database operations are an indispensable part. Python, as a powerful programming language, can achieve greater effects when combined with databases. This chapter will delve into how to implement advanced applications in Python projects, including using ORM to simplify data operations, implementing database connection pools to improve application performance, and implementing security practices to prevent SQL injection.
## 4.1 Using ORM to Simplify Data Operations
### 4.1.1 Basic Concepts and Advantages of ORM
ORM (Object-Relational Mapping) is a programming technique used to convert data between different systems. In database operations, ORM maps rows in database tables to objects in memory, allowing developers to manipulate databases by operating objects, thus transforming database operations into an object-oriented approach.
The advantages of using ORM include:
- Database independence: ORM abstracts database operations, and developers do not need to be concerned with which type of database is being used at the bottom.
- Increased development efficiency: By mapping objects, developers can perform database operations intuitively, significantly reducing the amount of code.
- Enhanced code readability: Since it is object-oriented, the code is closer to business logic and is easier to understand and maintain.
### 4.1.2 Practical Case: Using SQLAlchemy
SQLAlchemy is a very popular ORM framework in Python. It provides a complete ORM implementation and a wide range of database APIs, suitable for writing complex database operation logic.
Here is a basic example of using SQLAlchemy:
```python
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
# Define the base class
Base = declarative_base()
# Define a model class, mapped to a database table
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
fullname = Column(String)
nickname = Column(String)
# Create a database engine, using SQLite as an example
engine = create_engine('sqlite:///example.db')
# Create all tables
Base.metadata.create_all(engine)
# Create a session
Session = sessionmaker(bind=engine)
session = Session()
# Create a new user
new_user = User(name='John Doe', fullname='John Doe', nickname='johndoe')
session.add(new_user)
# ***
***mit()
# Close the session
session.close()
```
In this example, we first define a base class `Base`, then define a `User` class that maps to a database table named `users`. We then create a SQLite database engine and create all tables. We create a session, add a new user, commit the operation to the database, and finally close the session.
This method of operation is more intuitive than directly using SQL statements and is more convenient for managing complex data operations.
## 4.2 Implementation and Application of Database Connection Pools
### 4.2.1 Basic Principles of Connection Pools
A database connection pool is a technique for managing database connections. It creates and maintains a certain number of database connections in advance and reuses these connections when needed, thereby avoiding the overhead of repeatedly establishing and closing database connections.
The basic principles of a database connection pool are as follows:
- When the application starts, a certain number of database connections are created in advance and kept open.
- When the application needs to interact with the database, it obtains an idle connection from the connection pool.
- After the application completes the database operations, it returns the connection to the connection pool instead of closing it.
- The connection pool manages the lifecycle of connections based on certain strategies, such as setting a maximum connection time, and closing and creating new connections when exceeded.
### 4.2.2 Integrating Connection Pools into Applications
In Python, third-party libraries such as `SQLAlchemy` can be used to implement connection pools. SQLAlchemy defaults to using a connection pool mechanism. Here is an example of using a SQLAlchemy connection pool:
```python
from sqlalchemy import create_engine
# Create a database engine with connection pooling
engine = create_engine('sqlite:///example.db', pool_size=5, max_overflow=10, echo_pool=True)
# Use the engine to operate the database
# ...(The code for operating the database is the same as in the previous section)
```
In this example, `engine` is a database engine with connection pooling. We set the connection pool size to 5, meaning it maintains a maximum of 5 connections. The `max_overflow` parameter specifies the number of connections exceeding the connection pool size, here set to 10. `echo_pool=True` indicates that pool-related log information is output in the log.
By using connection pools, applications can more efficiently utilize database resources in high-concurrency scenarios, avoiding performance loss caused by frequent connection and disconnection.
## 4.3 Security Practices: Preventing SQL Injection
### 4.3.1 Principles and Dangers of SQL Injection
SQL injection (SQL Injection) is a common security attack technique where attackers insert malicious SQL code into input fields, causing the original SQL statement to be modified and bypassing security restrictions to access or tamper with database information.
The dangers of SQL injection include:
- Data leakage: Attackers may obtain sensitive information in the database, such as user passwords and personal information.
- Data tampering: Attackers modify data in the database, which could lead to service interruption or data being maliciously modified.
- Database control: In severe cases, attackers could even obtain database management permissions.
### 4.3.2 Best Practices for Preventing SQL Injection
To prevent SQL injection, developers can adopt the following best practices:
- Use prepared statements (Prepared Statements) and parameterized queries: These methods ensure that input parameters are not executed as SQL instructions, greatly reducing the risk of SQL injection.
- Principle of least privilege: Assign the smallest amount of permissions to the database user, and do not grant more access rights than necessary.
- Input validation and filtering: Validate all input data to ensure it conforms to the expected format. Use whitelist filtering for input values.
- Use ORM frameworks: Many ORM frameworks provide built-in mechanisms to prevent SQL injection, which can significantly reduce the risk.
For example, using parameterized queries with SQLAlchemy:
```python
from sqlalchemy.orm import sessionmaker
from sqlalchemy.sql import text
# Create a session
Session = sessionmaker(bind=engine)
session = Session()
# Use parameterized queries to prevent SQL injection
query = text("SELECT * FROM users WHERE name = :name")
result = session.execute(query, {'name': 'John Doe'}).fetchall()
# Close the session
session.close()
```
In this example, we use the `text()` function to create an SQL statement and pass parameters through the `execute()` function's argument `{'name': 'John Doe'}`. This method can effectively prevent SQL injection.
Through these practices, developers can effectively prevent SQL injection in projects and protect the security of databases and applications.
# 5 Advanced Techniques for Cross-platform Database Operations
## 5.1 Connection and Operation of Remote Databases
### 5.1.1 Configuration for Remote Access to MySQL
In modern IT environments, databases are often distributed across different geographic locations. Therefore, remote database connection has become a necessary skill for database management. To achieve a remote connection to a MySQL database, the following steps are usually required:
1. Ensure that the MySQL server listens for remote connection requests. This involves adding or modifying the `bind-address` directive in the MySQL configuration file (usually `***f` or `my.ini`) within the `[mysqld]` section to `*.*.*.*`, or commenting out this directive to allow access from all IP addresses.
```ini
[mysqld]
bind-address = *.*.*.*
```
2. Configure firewall rules to allow traffic through the default MySQL port (default is 3306).
3. Create a user account for remote access and grant the account remote access permissions.
```sql
GRANT ALL PRIVILEGES ON *.* TO 'remote_user'@'%' IDENTIFIED BY 'password';
FLUSH PRIVILEGES;
```
4. Test the remote connection to ensure that it can be successfully established. You can use the MySQL command-line client or any third-party tool that supports the MySQL protocol to test.
```bash
mysql -h <host> -u remote_user -p
```
### 5.1.2 Handling Network Latency and Security Issues
Network latency is an unavoidable issue when remotely operating databases, which affects data transmission and operation response speed. To optimize remote database operations, consider the following measures:
1. Use compression protocols: Add the `compress=true` parameter to the MySQL connection string to reduce the amount of data transmitted over the network, thus improving efficiency.
2. Optimize network settings: Optimize TCP/IP stack parameters on both the client and server sides, such as increasing the TCP window size or enabling TCP_NODELAY to reduce latency.
3. Choose appropriate client tools: Some database client tools are designed to adapt better to high-latency environments, such as using asynchronous IO to reduce wait times.
In terms of security, remote database connections face more challenges and must take measures to ensure the security of data transmission:
1. Use SSL encryption: Configure the MySQL server to support SSL connections and initiate the connection with the `--ssl` option to ensure encrypted transmission.
```bash
mysql -h <host> -u remote_user -p --ssl
```
2. Strict authentication mechanisms: Use strong passwords or more secure authentication methods, such as two-factor or multi-factor authentication.
3. Record audit logs: Enable MySQL's audit logging feature to record detailed information about all remote operations for tracking and auditing purposes.
## 5.2 Data Compatibility in Cross-database Migrations
### 5.2.1 Data Type Conversion Between Different Databases
Database migration is a common part of database management, typically involving a transition from one database system to another, such as from MySQL to PostgreSQL. During the migration process, data type conversion is a key step.
Each database system has its own unique set of data types. For example, MySQL's `VARCHAR` type and SQL Server's `NVARCHAR` type. During migration, these data types need to be mapped to the appropriate types in the target database. For example, MySQL's `TINYINT(1)` type may need to be mapped to SQLite's `BOOLEAN` type.
In Python, third-party libraries such as `sqlalchemy`'s `type_coerce` can be used to handle these type conversion issues, or data type conversions can be explicitly specified in the migration script.
```python
from sqlalchemy import String, Integer, type_coerce
# Example: Convert MySQL's TINYINT(1) to SQLite's BOOLEAN
def coerce_to_boolean(value):
return bool(int(value))
column = Column('active', type_coerce(Integer, coerce_to_boolean), nullable=False)
```
### 5.2.2 Use of Migration Tools and Case Studies
During the data migration process, using professional migration tools can greatly simplify the process. Popular migration tools such as `MySQL Workbench`, `Oracle SQL Developer Data Modeler`, and open-source solutions such as `Apache NiFi`, `Talend`, etc., can assist in managing the migration process, including data conversion and migration script generation.
When choosing a migration tool, consider the following factors:
1. Database support range: Confirm which source and target databases the tool supports.
2. Data type and structure conversion capabilities: Check if it supports automatic or semi-automatic data type and structure conversion.
3. Data migration strategies: Whether it supports full migration, incremental migration, and data consistency checks.
Case study: Assuming a migration from MySQL to PostgreSQL, the `pgloader` tool can be used for data migration.
```bash
pgloader mysql://remote_user:password@host/dbname pgsql://remote_user:password@host/new_dbname
```
`pgloader` will not only migrate data from MySQL to PostgreSQL but also handle data type conversions, striving to maintain data integrity as much as possible.
## 5.3 Strategies for Data Backup and Recovery
### 5.3.1 Importance of Regular Backups
Database backup is a fundamental part of data management, crucial for preventing data loss, accidental deletion, data corruption, or security breaches. When formulating a backup strategy, consider the following factors:
1. Data importance: According to the importance of the data to the business, different backup frequencies should be formulated. For example, financial data may need daily or even hourly backups.
2. Data size: The size of the data affects backup time and storage requirements.
3. Recovery Time Objective (RTO) and Recovery Point Objective (RPO): Determine the maximum acceptable recovery time and the amount of data loss acceptable based on business continuity requirements.
4. Data growth rate: The data growth rate determines the backup window (required backup time) ***
***mon backup types include full backup, incremental backup, and differential backup. Full backup backs up all data, incremental backup only backs up data changed since the last backup, and differential backup backs up data changed since the last full backup.
### 5.3.2 Comparison of Manual and Automated Backup Methods
Manual and automated backups each have their own advantages and disadvantages, and the choice mainly depends on the specific needs and resources of the organization.
**Manual Backup**:
Advantages:
- High flexibility, backup operations can be performed according to specific needs.
- Full control over the backup process, backup strategies can be adjusted based on actual situations.
Disadvantages:
- Prone to errors, relying on human operations,容易因忘记或错误操作导致备份失败。
- Not suitable for frequent backup scenarios, as each backup requires manual execution.
**Automated Backup**:
Advantages:
- Reduces human errors, automatically executes backup tasks, lowering the risk of failure.
- Can be executed regularly, such as scheduling backups to run at night, ensuring data security.
- Suitable for large-scale data backups, can automate the management of backup tasks.
Disadvantages:
- Requires resources and configuration, ensuring the backup system's stable operation.
- Backup strategies may not be flexible enough, requiring pre-configuration.
Through Python scripts, an automatic backup process can be implemented. Below is a simple example of an automated backup script:
```python
import os
import subprocess
def backup_database():
host = "localhost"
user = "db_user"
password = "db_password"
database = "db_name"
backup_file = f"{database}_backup_`date +%Y%m%d`.sql"
cmd = f"mysqldump -h {host} -u {user} -p{password} {database} > {backup_file}"
subprocess.call(cmd, shell=True)
if __name__ == "__main__":
backup_database()
```
In practical applications, the backup script can also be integrated into scheduled tasks, such as Linux's `cron` or Windows' Task Scheduler, to achieve automated backups.
# 6 Database Design and Optimization for Big Data
With the surge in data volume, traditional database design and optimization methods can no longer meet the needs of big data environments. This chapter will delve into how to design a database architecture for big data environments and provide optimization strategies to ensure the efficiency of data storage and retrieval.
## 6.1 Best Practices for Database Architecture Design
When data volume reaches the TB or PB level, traditional monolithic database architectures can hardly handle such a scale of data. Sharding and replication are two common big data architecture design strategies that can effectively distribute database loads and improve data read/write efficiency.
### 6.1.1 Sharding Strategies
Sharding is a method of horizontally dividing data, distributing it across multiple database instances. Sharding can be based on range, hash, or list.
```python
# Example code: Hash sharding based on user ID
def hash_sharding(user_id):
shard_key = hash(user_id) % number_of_shards
return shard_key
```
The various database instances after sharding are called shards or shard nodes. When querying data, the shard on which the data resides is first calculated, and then operations are directed to that shard.
### 6.1.2 Replication Strategies
Replication refers to saving multiple copies of data on different database instances to improve data availability and read performance. Master-slave replication and multi-master replication are two common replication patterns.
```python
# Example code: Implementing master-slave replication mechanism using Python
class Master(object):
# Master database operation logic
class Slave(object):
# Slave database operation logic
```
Replication technology is often used in read-write separation scenarios, where the master database handles all write operations, and the slave database handles read operations, thereby distributing the load.
## 6.2 Database Optimization Techniques
In big data environments, database performance optimization is a continuous process. In addition to architecture design, database optimization is also crucial.
### 6.2.1 Index Optimization
Indexes are a technique used in databases for quickly locating data. For large data tables, creating and using indexes reasonably can greatly improve query speed. For example, B-tree and hash indexes have different advantages in different scenarios.
```sql
CREATE INDEX idx_user_id ON users(user_id);
```
### 6.2.2 Query Optimization
Complex queries can consume a lot of database resources; optimizing query statements can significantly improve performance. For example, avoid using functions in the WHERE clause and尽量减少数据类型的隐式转换。
```sql
-- Not recommended
SELECT * FROM users WHERE YEAR(birth_date) = 1990;
-- Recommended
SELECT * FROM users WHERE birth_date BETWEEN '1990-01-01' AND '1990-12-31';
```
### 6.2.3 Caching Strategies
Caching is another effective means of improving database performance. By caching hot data, direct access to the backend database can be reduced, thus lowering the pressure on the database.
```python
# Example code: Using Redis as a cache server
import redis
cache = redis.Redis(host='localhost', port=6379, db=0)
def get_user(user_id):
user_data = cache.get('user_%s' % user_id)
if user_data:
return pickle.loads(user_data)
else:
user = db_query('SELECT * FROM users WHERE id = %s', (user_id,))
cache.set('user_%s' % user_id, pickle.dumps(user))
return user
```
By applying caching, database access can be reduced, and overall system performance and response speed can be improved.
## 6.3 Big Data Storage Solutions
For data at the PB level, traditional relational databases may not be able to meet the requirements. In such cases, it is usually necessary to consider using NoSQL or distributed databases.
### 6.3.1 NoSQL Databases
NoSQL databases, with their flexible data models and horizontal scaling capabilities, have become an ideal choice for handling large-scale data. Such as MongoDB, Cassandra, etc., they support non-relational data models and can handle large amounts of distributed data well.
### 6.3.2 Distributed Databases
Distributed databases like Google's Bigtable and Apache Cassandra are designed specifically for processing big data. They process data by distributing nodes across multiple servers, improving data processing efficiency and fault tolerance.
```python
# Example code: Using Apache Cassandra for data insertion operations
from cassandra.cluster import Cluster
cluster = Cluster(['cassandra-node1', 'cassandra-node2'])
session = cluster.connect('keyspace1')
session.execute("""
INSERT INTO users (id, name, email)
VALUES (%s, %s, %s);
""", (1, 'Alice', '***'))
```
In big data scenarios, choosing the right storage solution is crucial for ensuring high availability, stability, and scalability of the business.
Through this chapter, you should have an understanding of database design and optimization strategies for big data, as well as how to apply these strategies to improve database performance in big data environments. In the next chapter, we will discuss database migration and scaling strategies in big data environments.

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
金蝶K3凭证接口性能调优:5大关键步骤提升系统效率
# 摘要
本论文针对金蝶K3凭证接口性能调优问题展开研究,首先对性能调优进行了基础理论的探讨,包括性能指标理解、调优目标与基准明确以及性能监控工具与方法的介绍。接着,详细分析了凭证接口的性能测试与优化策略,并着重讨论了提升系统效率的关键步骤,如数据库和应用程序层面的优化,以及系统配置与环境优化。实施性能调优后,本文还评估了调优效果,并探讨了持续性能监控与调优的重要性。通过案例研究与经验分享,本文总结了在性能调优过程中遇到的问题与解决方案,提出了调优最佳实践与建议。
# 关键字
金蝶K3;性能调优;性能监控;接口优化;系统效率;案例分析
参考资源链接:[金蝶K3凭证接口开发指南](https
【CAM350 Gerber文件导入秘籍】:彻底告别文件不兼容问题
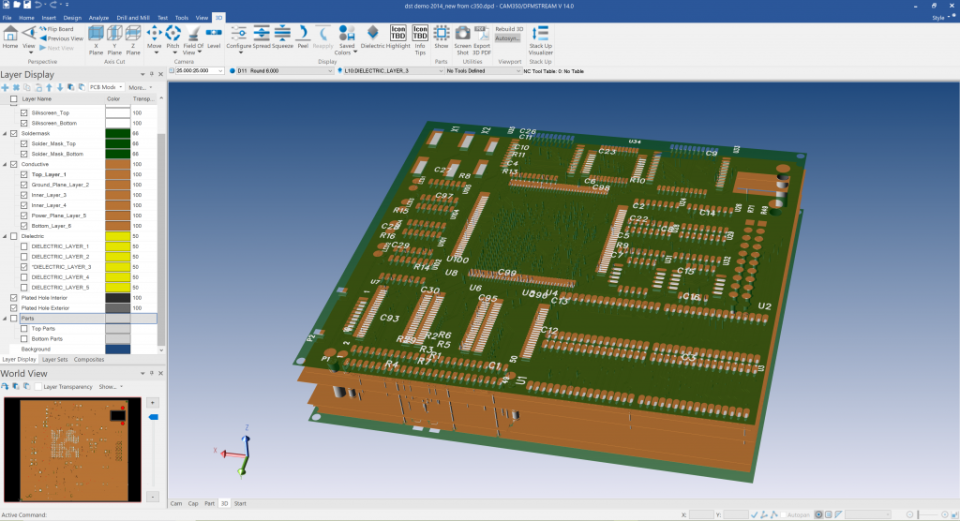
# 摘要
本文全面介绍了CAM350软件中Gerber文件的导入、校验、编辑和集成过程。首先概述了CAM350与Gerber文件导入的基本概念和软件环境设置,随后深入探讨了Gerber文件格式的结构、扩展格式以及版本差异。文章详细阐述了在CAM350中导入Gerber文件的步骤,包括前期
【Python数据处理秘籍】:专家教你如何高效清洗和预处理数据

# 摘要
随着数据科学的快速发展,Python作为一门强大的编程语言,在数据处理领域显示出了其独特的便捷性和高效性。本文首先概述了Python在数据处理中的应用,随后深入探讨了数据清洗的理论基础和实践,包括数据质量问题的认识、数据清洗的目标与策略,以及缺失值、异常值和噪声数据的处理方法。接着,文章介绍了Pandas和NumPy等常用Python数据处理库,并具体演示了这些库在实际数
C++ Builder 6.0 高级控件应用大揭秘:让应用功能飞起来

# 摘要
本文综合探讨了C++ Builder 6.0中的高级控件应用及其优化策略。通过深入分析高级控件的类型、属性和自定义开发,文章揭示了数据感知控件、高级界面控件和系统增强控件在实际项目中的具体应用,如表格、树形和多媒体控件的技巧和集成。同时,本文提供了实用的编
【嵌入式温度监控】:51单片机与MLX90614的协同工作案例

# 摘要
本文详细介绍了嵌入式温度监控系统的设计与实现过程。首先概述了51单片机的硬件架构和编程基础,包括内存管理和开发环境介绍。接着,深入探讨了MLX90614传感器的工作原理及其与51单片机的数据通信协议。在此基础上,提出了温度监控系统的方案设计、硬件选型、电路设计以及
PyCharm效率大师:掌握这些布局技巧,开发效率翻倍提升

# 摘要
PyCharm作为一款流行的集成开发环境(IDE),受到广大Python开发者的青睐。本文旨在介绍PyCharm的基本使用、高效编码实践、项目管理优化、调试测试技巧、插件生态及其高级定制功能。从工作区布局的基础知识到高效编码的实用技巧,从项目管理的优化策略到调试和测试的进阶技术,以及如何通过插件扩展功能和个性化定制IDE,本文系统地阐述了PyCharm在
Geoda操作全攻略:空间自相关分析一步到位
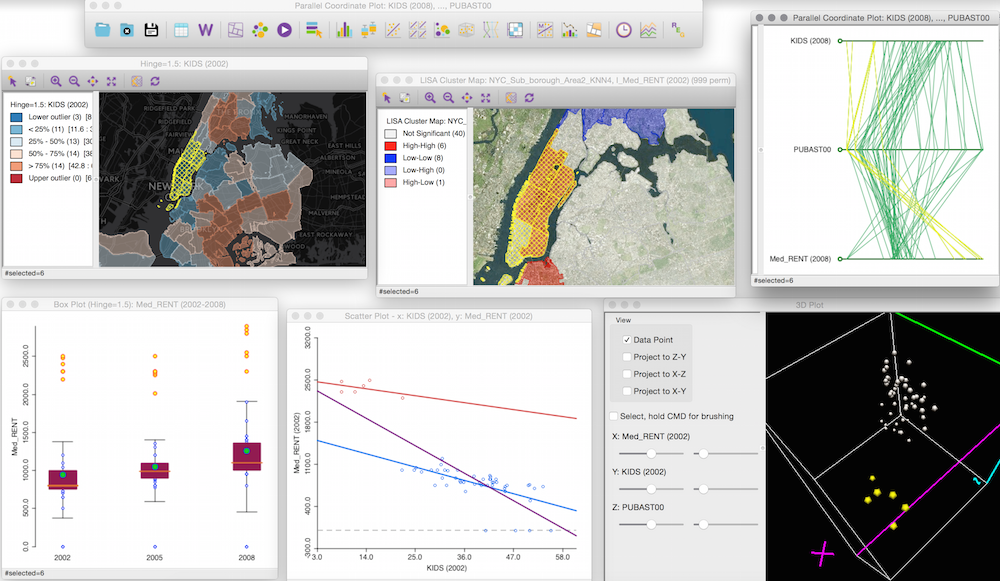
# 摘要
本文深入探讨了空间自相关分析在地理信息系统(GIS)研究中的应用与实践。首先介绍了空间自相关分析的基本概念和理论基础,阐明了空间数据的特性及其与传统数据的差异,并详细解释了全局与局部空间自相关分析的数学模型。随后,文章通过Geoda软件的实践操作,具体展示了空间权重矩阵构建、全局与局部空间自相关分析的计算及结果解读。本文还讨论了空间自相关分析在时间序列和多领域的高级应用,以及计算优化策略。最后,通过案例研究验证了空间自相关分析的实践价值,
【仿真参数调优策略】:如何通过BH曲线优化电磁场仿真
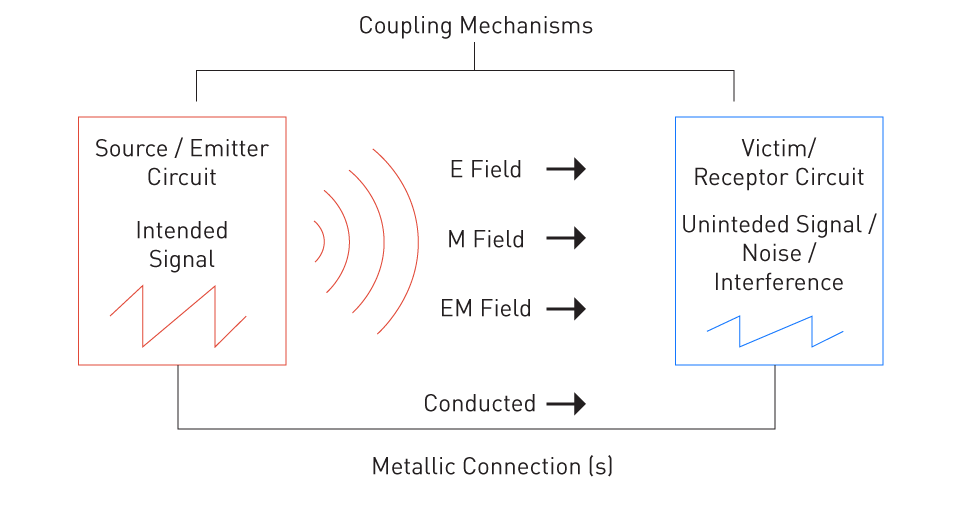
# 摘要
电磁场仿真在工程设计和科学研究中扮演着至关重要的角色,其中BH曲线作为描述材料磁性能的关键参数,对于仿真模型的准确建立至关重要。本文详细探讨了电磁场仿真基础与BH曲线的理论基础,以及如何通过精确的仿真模型建立和参数调优来保证仿真结果的准确性和可靠性。文中不仅介绍了BH曲线在仿真中的重要性,并且提供了仿真模型建立的步骤、仿真验证方法以
STM32高级调试技巧:9位数据宽度串口通信故障的快速诊断与解决

# 摘要
本文重点介绍了STM32微控制器与9位数据宽度串口通信的技术细节和故障诊断方法。首先概述了9位数据宽度串口通信的基础知识,随后深入探讨了串口通信的工作原理、硬件连接、数据帧格式以及初始化与配置。接着,文章详细分析了9位数据宽度通信中的故障诊断技术,包括信号完整性和电气特性标准的测量,以及实际故障案例的分析。在此基础上,本文提出了一系列故障快速解决方法,涵盖常见的问题诊断技巧和优化通
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )