【基础】掌握Python变量和数据类型
发布时间: 2024-06-26 08:10:12 阅读量: 82 订阅数: 153 

python变量和数据类型
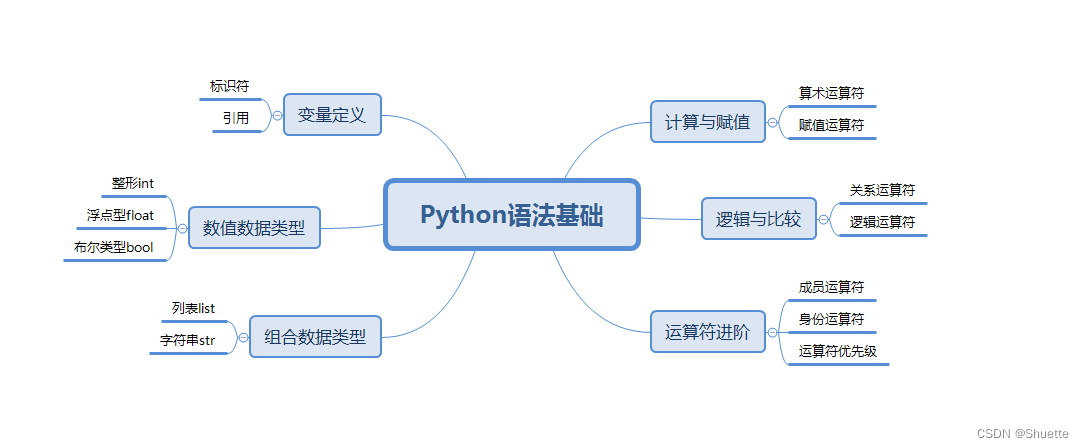
# 2.1 变量的定义和赋值
在 Python 中,变量用于存储数据。变量的定义使用赋值运算符 `=`, 赋值运算符的左边是变量名,右边是变量的值。例如:
```python
# 定义变量并赋值
name = "John Doe"
age = 30
```
变量名可以是字母、数字或下划线开头的任意组合,但不能以数字开头。变量名应具有描述性,以反映其存储的值。
赋值运算符将右边的值分配给左边的变量。变量的值可以随时更改,通过再次使用赋值运算符。例如:
```python
# 更改变量的值
age = 31
```
# 2. Python变量的深入理解
### 2.1 变量的定义和赋值
在Python中,变量是用于存储数据的命名内存位置。变量的定义使用`=`赋值运算符,其语法如下:
```python
variable_name = value
```
例如:
```python
name = "John Doe"
age = 30
```
### 2.2 数据类型的分类和转换
Python支持多种数据类型,用于表示不同类型的数据。主要数据类型包括:
- **数值类型:**int(整数)、float(浮点数)、complex(复数)
- **序列类型:**list(列表)、tuple(元组)、range(范围)
- **映射类型:**dict(字典)、set(集合)
- **布尔类型:**bool(布尔值)
- **NoneType:**None(空值)
数据类型转换可以通过内置函数完成,例如:
```python
# 将字符串转换为整数
num = int("123")
# 将浮点数转换为字符串
str_num = str(123.45)
```
#### 代码块逻辑分析
`int()`函数将字符串转换为整数,返回一个int类型的对象。`str()`函数将浮点数转换为字符串,返回一个str类型的对象。
#### 参数说明
- `int()`函数:将字符串、浮点数或其他可以转换为整数的对象转换为int类型。
- `str()`函数:将整数、浮点数或其他可以转换为字符串的对象转换为str类型。
# 3. Python变量的应用技巧
### 3.1 变量作用域和生命周期
变量的作用域是指变量在程序中可以被访问的范围,它由变量的声明位置决定。Python中的变量作用域分为局部作用域和全局作用域:
- **局部作用域:**变量在函数或代码块内声明,只在该函数或代码块内有效。
- **全局作用域:**变量在函数或代码块外声明,可以在整个程序中访问。
变量的生命周期是指变量从创建到销毁的过程。Python中的变量生命周期由垃圾回收机制管理,当变量不再被引用时,它将被自动释放。
### 3.2 变量的内存管理和优化
Python使用引用计数机制进行内存管理。每个对象都有一个引用计数,表示引用该对象的变量数量。当变量不再引用对象时,引用计数减 1;当引用计数为 0 时,对象将被销毁。
为了优化内存管理,可以采用以下技巧:
- **使用局部变量:**尽量在函数或代码块内声明变量,以避免创建不必要的全局变量。
- **及时释放变量:**当变量不再需要时,使用 `del` 语句显式释放变量。
- **使用弱引用:**使用 `weakref` 模块中的 `WeakReference` 类,可以创建弱引用,当对象不再被强引用时,弱引用将被自动释放。
#### 代码示例
```python
# 局部变量
def my_function():
local_var = 10
# 全局变量
global_var = 20
# 释放变量
del local_var
```
#### 代码逻辑分析
- `my_function()` 函数中声明的 `local_var` 是局部变量,只在函数内有效。
- `global_var` 是全局变量,可以在整个程序中访问。
- `del local_var` 语句释放了 `local_var` 变量,使引用计数减 1。由于 `local_var` 不再被引用,它将被垃圾回收机制销毁。
- `global_var` 仍然被全局变量引用,因此不会被释放。
# 4. Python数据类型的进阶应用
### 4.1 数据结构的定义和使用
数据结构是组织和存储数据的形式化方式。Python提供了多种内置数据结构,包括列表、元组、字典和集合,它们可以满足各种数据存储和处理需求。
#### 4.1.1 列表和元组
**列表**是一种可变序列数据结构,可以存储任意类型的数据元素。列表可以使用方括号 `[]` 创建,元素之间用逗号分隔。列表支持索引、切片、追加、删除等操作。
```python
# 创建一个列表
my_list = [1, 2, 3, 'a', 'b', 'c']
# 获取列表元素
print(my_list[0]) # 输出:1
# 切片列表
print(my_list[1:3]) # 输出:[2, 3]
# 追加元素
my_list.append(4)
# 删除元素
del my_list[2]
```
**元组**是一种不可变序列数据结构,与列表类似,但元素不能被修改或删除。元组使用小括号 `()` 创建,元素之间用逗号分隔。元组支持索引和切片操作。
```python
# 创建一个元组
my_tuple = (1, 2, 3, 'a', 'b', 'c')
# 获取元组元素
print(my_tuple[0]) # 输出:1
# 切片元组
print(my_tuple[1:3]) # 输出:(2, 3)
```
#### 4.1.2 字典和集合
**字典**是一种无序映射数据结构,用于存储键值对。字典使用大括号 `{}` 创建,键和值之间用冒号 `:` 分隔。字典支持键值访问、添加、删除等操作。
```python
# 创建一个字典
my_dict = {'name': 'John', 'age': 30, 'city': 'New York'}
# 获取字典值
print(my_dict['name']) # 输出:John
# 添加键值对
my_dict['email'] = 'john@example.com'
# 删除键值对
del my_dict['age']
```
**集合**是一种无序集合数据结构,用于存储唯一元素。集合使用大括号 `{}` 创建,元素之间用逗号分隔。集合支持元素添加、删除、交集、并集等操作。
```python
# 创建一个集合
my_set = {1, 2, 3, 'a', 'b', 'c'}
# 添加元素
my_set.add(4)
# 删除元素
my_set.remove(2)
# 交集
print(my_set & {2, 3, 4, 'd'}) # 输出:{2, 3, 4}
```
### 4.2 数据处理和分析
Python提供了强大的数据处理和分析功能,包括数据清洗、预处理、统计和可视化。
#### 4.2.1 数据清洗和预处理
数据清洗是将数据转换为适合分析的格式的过程,包括删除重复值、处理缺失值、转换数据类型等。Python提供了 `pandas` 库,可以轻松地进行数据清洗操作。
```python
import pandas as pd
# 读取数据
df = pd.read_csv('data.csv')
# 删除重复值
df = df.drop_duplicates()
# 处理缺失值
df = df.fillna(0)
# 转换数据类型
df['age'] = df['age'].astype(int)
```
#### 4.2.2 数据统计和可视化
数据统计和可视化可以帮助我们了解数据的分布和趋势。Python提供了 `numpy` 和 `matplotlib` 库,可以轻松地进行数据统计和可视化。
```python
import numpy as np
import matplotlib.pyplot as plt
# 计算数据统计
mean = np.mean(df['age'])
std = np.std(df['age'])
# 绘制直方图
plt.hist(df['age'])
plt.xlabel('Age')
plt.ylabel('Frequency')
plt.show()
```
# 5.1 变量命名规范和可读性
变量命名是 Python 编程中一个至关重要的方面,它影响着代码的可读性、可维护性和可调试性。遵循合理的命名规范可以极大地提高代码的质量。
### 命名规范
* **使用有意义的名称:**变量名应该清晰地描述变量所代表的值或对象。避免使用模糊或通用的名称,如 `x` 或 `y`。
* **使用小写字母和下划线:** Python 中的变量名通常使用小写字母和下划线连接单词。例如: `my_variable`、`user_name`。
* **避免使用特殊字符:**除了下划线之外,避免在变量名中使用特殊字符,如 `$`、`#` 或 `.`。
* **使用驼峰命名法:**对于多单词变量名,可以使用驼峰命名法,即首字母大写,其余字母小写。例如: `myVariable`、 `userName`。
### 可读性
变量命名不仅要符合规范,还应该具有可读性。以下是一些提高可读性的建议:
* **使用一致的风格:**在整个代码库中保持一致的命名风格。例如,如果使用驼峰命名法,则应始终使用驼峰命名法。
* **避免缩写:**除非缩写非常常见且易于理解,否则应避免使用缩写。例如,使用 `user_name` 而不是 `uname`。
* **使用注释:**如果变量名不够明确,可以添加注释来解释其含义。
### 示例
以下是一些遵循最佳实践的变量命名示例:
```python
# 有意义的名称
user_name = "John Doe"
total_cost = 100.00
# 小写字母和下划线
my_list = [1, 2, 3]
user_input = input("Enter your name: ")
# 驼峰命名法
my_variable = 10
userName = "Jane Doe"
```
遵循这些最佳实践可以显著提高 Python 代码的可读性、可维护性和可调试性。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏是一个全面的 Python 游戏开发指南,涵盖从基础到进阶的各个方面。它从 Python 语言的基础开始,逐步介绍 PyGame 库的使用,包括事件处理、图形绘制、音效和音乐管理。
进阶部分深入探讨了游戏开发的复杂技术,例如精灵管理、动画、碰撞检测、AI 实现、性能优化和网络通信。专栏还提供了多个实战演练,指导读者开发各种类型的游戏,包括打地鼠、拼图、2048、跑酷、塔防、打砖块、井字棋、俄罗斯方块、回合制策略、卡牌、迷宫探险、平台跳跃、模拟城市、足球和文字冒险。
通过本专栏,读者将掌握 Python 游戏开发所需的知识和技能,并能够创建自己的有趣且引人入胜的游戏。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【ITU-T G.704 信号质量分析】:误码率检测与管理的实战策略

# 摘要
本文全面介绍了ITU-T G.704信号的基本概念、误码率检测的理论基础,以及误码率对信号质量的影响。通过探讨误码率的定义、检测方法、技术和标准,阐述了误码率与信噪比及网络层信号质量的关联。接着,文章聚焦于实战策略,包括误码率监测工具的选择、管理策略的制定、故障排查和性能调优。案例研究部分展
IEC 61800-5-2标准技术深度解析:掌握安全要求功能的细节与实施要点

# 摘要
IEC 61800-5-2标准作为工业自动化领域内调节和控制电气设备的重要规范,涵盖了广泛的安全要求功能。本文旨在概述该标准的基本框架,并深入探讨其安全要求功能的理论基础,包括安全相关概念的定义、理论模型以及性能指标。同时,文章将提供基于该标准的实践应用指南,涵盖安全功能的实现、测试与验证以及部署与运维的实际操作。通过对行
如何利用ArcGIS进行高效流域划分:数字高程模型最佳实践指南

# 摘要
本文系统介绍流域划分的基本概念及其在ArcGIS平台上的实践应用。首先,概述了流域划分的理论基础,强调数字高程模型(DEM)在定义流域特征中的重要性,并详细介绍了DEM数据的获取、预处理及操作分析方法。其次,本文详细阐述了利用ArcGIS进行流域划分的具体操作步骤,包括创建水文分析工具箱和流域特征参数的计算与分析。进一步地,本文探讨了高级流域分析技术,并通过实际案例研究展示了分析
网络管理新手必备:W5500+STM32项目的快速启动与实现

# 摘要
随着物联网技术的发展,网络管理成为嵌入式系统设计中的关键组成部分。本文首先介绍了网络管理与W5500以太网控制器的基础知识,然后详细讲解了STM32微控制器的开发环境搭建、硬件连接和网络编程基础。文章深入探讨了W5500与STM32的硬件连接设计、
【信号处理技术】:位置随动系统中的黑科技,效率倍增

# 摘要
位置随动系统作为现代自动化设备的关键部分,其性能在很大程度上依赖于信号处理技术的先进程度。本文首先概述了位置随动系统的基本概念及其在信号处理中的应用,随后深入探讨了信号处理基础理论,包括信号的基本概念、数学工具和滤波技术。文章接着详细分析了信号处理技术在位置随动系统中的实际应用,例如位置检测、实时信号处理和硬件与软件的协同。第四章通过实践案例分析,展示了信号处理技术在系统性能优化和
【Verilog设计模式】:generate与参数传递的案例研究

# 摘要
随着集成电路设计的日益复杂化,Verilog设计模式在数字电路设计领域扮演着关键角色。本文全面介绍了Verilog的参数化设计模式及generate语句的深入分析,探讨了其优势、使用场景以及参数传递的原理和最佳实践。通过案例研究,本文展示了参数化模块设计、动态参数的generate应用以及两者联合使用的高级应用和设计模式优化。文章强
邮件编码的秘密武器:Quoted-printable编码的艺术与实战技巧

# 摘要
本文系统地介绍了邮件编码的基础知识,特别是Quoted-printable编码机制。章节一提供Quoted-printable的基础知识简介,接下来章节二深入分析其编码机制,包括理论基础、实现原理和应用场景。章节三讨论Quoted-printable编码的实战技巧,包括编码工具的使用、解码技巧以及性能优化。第四章深入探讨Qu
华为设计方案背后的逻辑:系统化思维与技术创新的深度解析

# 摘要
华为作为领先的全球通信技术公司,在其设计方案中深度融入了系统化思维,这种思维方式对于需求分析、系统设计、模块化解决方案的集成和持续迭代优化起着至关重要的作用。同时,华为的技术创新机制是其设计方案的核心驱动力,涵盖了研发投资、知识产权策略、跨界合作及人才培养等多个方面。本文还探讨了华为如何在5G通信、智能终端与云计算融合、以及AI技术应用中实施关键技术
SONET_SDH到OTN的演进:下一代传输技术的前瞻与应用
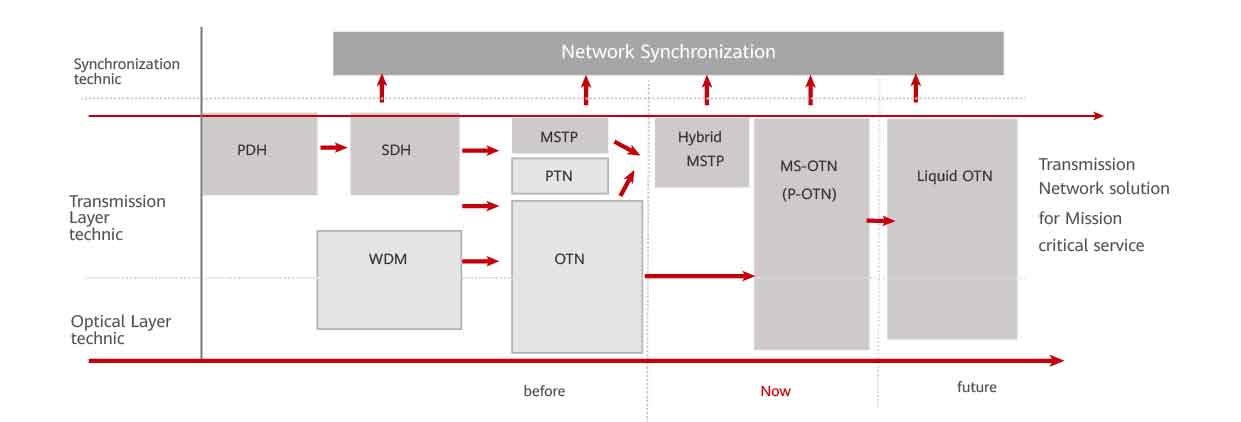
# 摘要
随着通信技术的快速发展,传输网络经历了从SONET/SDH到OTN的演进。本文首先介绍了SONET/SDH技术的基础知识,随后深入探讨了OTN技术原理、框架结构及关键技术特性,并分
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )