揭秘并查集算法的奥秘:从原理到实战应用
发布时间: 2024-08-24 01:55:28 阅读量: 13 订阅数: 12 
# 1. 并查集算法的理论基础
并查集算法是一种高效的数据结构,用于维护一组元素的连通性信息。它支持两种基本操作:查找和合并。
查找操作用于确定一个元素所属的连通分量。合并操作用于将两个连通分量合并为一个。并查集算法的效率取决于其实现技巧,例如路径压缩和按秩合并等优化策略。
# 2. 并查集算法的实现技巧
### 2.1 并查集算法的两种基本操作
#### 2.1.1 查找操作
查找操作用于确定给定元素所属的连通分量。它通过递归地向上查找元素的父节点,直到找到根节点,来实现这一目的。
```python
def find(x):
if x != parent[x]:
parent[x] = find(parent[x])
return parent[x]
```
**代码逻辑分析:**
* 如果当前元素 `x` 不是其自身的父节点,则继续向上查找其父节点。
* 否则,说明 `x` 是根节点,直接返回 `x`。
**参数说明:**
* `x`:要查找的元素
#### 2.1.2 合并操作
合并操作用于将两个连通分量合并为一个。它通过将一个连通分量的根节点设置为另一个连通分量的根节点的子节点来实现这一目的。
```python
def union(x, y):
x_root = find(x)
y_root = find(y)
if x_root != y_root:
parent[y_root] = x_root
```
**代码逻辑分析:**
* 首先找到元素 `x` 和 `y` 所属的连通分量的根节点 `x_root` 和 `y_root`。
* 如果 `x_root` 和 `y_root` 不同,则将 `y_root` 设置为 `x_root` 的子节点,从而将两个连通分量合并为一个。
**参数说明:**
* `x`:第一个元素
* `y`:第二个元素
### 2.2 并查集算法的优化策略
#### 2.2.1 路径压缩
路径压缩是一种优化策略,用于减少查找操作的平均时间复杂度。它通过在查找过程中将每个节点的父节点直接设置为根节点来实现这一目的。
```python
def find(x):
if x != parent[x]:
parent[x] = find(parent[x])
return parent[x]
```
**代码逻辑分析:**
* 在查找元素 `x` 的根节点时,同时更新 `x` 的父节点为根节点。
* 这样,下次查找 `x` 的子节点时,可以直接找到根节点,从而减少了查找的时间复杂度。
#### 2.2.2 按秩合并
按秩合并是一种优化策略,用于减少合并操作的平均时间复杂度。它通过将秩较小的连通分量的根节点设置为秩较大的连通分量的根节点的子节点来实现这一目的。
```python
def union(x, y):
x_root = find(x)
y_root = find(y)
if x_root != y_root:
if rank[x_root] < rank[y_root]:
parent[x_root] = y_root
else:
parent[y_root] = x_root
if rank[x_root] == rank[y_root]:
rank[x_root] += 1
```
**代码逻辑分析:**
* 在合并两个连通分量时,比较它们的秩。
* 如果秩较小,则将秩较小的连通分量的根节点设置为秩较大的连通分量的根节点的子节点。
* 如果秩相等,则将秩较大的连通分量的秩加 1。
* 这样,可以确保合并后的连通分量的秩总是大于或等于其子连通分量的秩,从而减少了合并操作的时间复杂度。
### 2.3 并查集算法的复杂度分析
#### 2.3.1 时间复杂度
* **查找操作:**平均时间复杂度为 O(α(n)),其中 α(n) 是反阿克曼函数,是一个非常缓慢增长的函数。
* **合并操作:**平均时间复杂度为 O(α(n))。
#### 2.3.2 空间复杂度
并查集算法的空间复杂度为 O(n),其中 n 是元素的总数。
# 3.1 并查集算法在连通性检测中的应用
#### 3.1.1 连通性检测的定义和应用场景
**连通性检测**是指判断给定图中任意两点是否连通,即是否存在一条路径将它们连接起来。连通性检测在实际应用中有着广泛的应用,例如:
- 社交网络:判断两个用户是否通过好友关系链间接相识。
- 图像处理:识别图像中的连通区域,例如分割物体。
- 网络通信:检测网络中哪些设备可以相互通信。
#### 3.1.2 并查集算法解决连通性检测问题的步骤
并查集算法通过维护一个集合来记录图中各个连通分量的代表元素,并通过两个基本操作(查找和合并)来实现连通性检测:
**查找操作**:给定一个元素,找到它所属的连通分量的代表元素。
**合并操作**:将两个连通分量的代表元素合并到同一个连通分量中。
具体步骤如下:
1. **初始化:**将图中每个顶点初始化为一个独立的连通分量。
2. **查找操作:**对于要查询的两个顶点,通过递归查找操作找到它们各自的连通分量代表元素。
3. **合并操作:**如果两个顶点的连通分量代表元素不同,则执行合并操作,将它们合并到同一个连通分量中。
4. **判断连通性:**如果两个顶点的连通分量代表元素相同,则它们连通;否则,它们不连通。
**代码示例:**
```python
class UnionFind:
def __init__(self, n):
self.parents = [i for i in range(n)]
self.ranks = [0 for _ in range(n)]
def find(self, x):
if self.parents[x] != x:
self.parents[x] = self.find(self.parents[x])
return self.parents[x]
def union(self, x, y):
x_root = self.find(x)
y_root = self.find(y)
if x_root != y_root:
if self.ranks[x_root] < self.ranks[y_root]:
self.parents[x_root] = y_root
else:
self.parents[y_root] = x_root
if self.ranks[x_root] == self.ranks[y_root]:
self.ranks[x_root] += 1
```
**代码逻辑分析:**
- `__init__` 函数初始化并查集,将每个顶点设为自己的父节点,秩为 0。
- `find` 函数使用路径压缩优化,递归查找顶点 `x` 的根节点,并更新 `x` 的父节点为根节点。
- `union` 函数使用按秩合并优化,比较两个顶点 `x` 和 `y` 的根节点的秩,秩较小的根节点成为另一个根节点的子节点。如果秩相等,则将秩较大的根节点的秩加 1。
**复杂度分析:**
- 时间复杂度:查找操作和合并操作的平均时间复杂度均为 O(α(n)),其中 α(n) 是阿克曼函数的反函数,对于实际应用中的图来说,α(n) 非常小,接近于 4。
- 空间复杂度:O(n),其中 n 是图中顶点的数量。
# 4. 并查集算法的进阶应用
### 4.1 并查集算法在图论中的应用
#### 4.1.1 图论中并查集算法的应用场景
并查集算法在图论中有着广泛的应用,主要用于解决图的连通性问题和生成树问题。
* **连通性检测:**判断图中是否存在从一个顶点到另一个顶点的路径。
* **生成树:**找到图中所有顶点都连接在一起,但没有环的最小权重子图。
#### 4.1.2 并查集算法解决图论问题的示例
**连通性检测:**
```python
def is_connected(graph, source, destination):
"""
判断图中是否存在从 source 到 destination 的路径。
参数:
graph: 图的邻接表表示
source: 起始顶点
destination: 目标顶点
返回:
True 如果存在路径,否则返回 False
"""
# 初始化并查集
disjoint_set = DisjointSet()
for vertex in graph:
disjoint_set.make_set(vertex)
# 查找 source 和 destination 的根节点
source_root = disjoint_set.find_set(source)
destination_root = disjoint_set.find_set(destination)
# 如果根节点相同,则说明存在路径
return source_root == destination_root
```
**生成树:**
```python
def kruskal_mst(graph):
"""
使用克鲁斯卡尔算法找到图的最小生成树。
参数:
graph: 图的邻接表表示
返回:
最小生成树的边集
"""
# 初始化并查集
disjoint_set = DisjointSet()
for vertex in graph:
disjoint_set.make_set(vertex)
# 初始化边集
edges = []
for vertex in graph:
for neighbor, weight in graph[vertex]:
edges.append((vertex, neighbor, weight))
# 对边集进行排序
edges.sort(key=lambda edge: edge[2])
# 遍历边集
mst = []
for edge in edges:
# 查找边两个端点的根节点
source_root = disjoint_set.find_set(edge[0])
destination_root = disjoint_set.find_set(edge[1])
# 如果根节点不同,则添加边到 MST 并合并根节点
if source_root != destination_root:
mst.append(edge)
disjoint_set.union_set(source_root, destination_root)
return mst
```
### 4.2 并查集算法在数据结构中的应用
#### 4.2.1 并查集算法在数据结构中的应用场景
并查集算法在数据结构中也有着重要的应用,主要用于维护集合的并集和交集。
* **集合并集:**将两个集合合并为一个集合。
* **集合交集:**找到两个集合的交集。
#### 4.2.2 并查集算法解决数据结构问题的示例
**集合并集:**
```python
def union_sets(set1, set2):
"""
将两个集合合并为一个集合。
参数:
set1: 第一个集合
set2: 第二个集合
返回:
合并后的集合
"""
# 初始化并查集
disjoint_set = DisjointSet()
for element in set1:
disjoint_set.make_set(element)
for element in set2:
disjoint_set.make_set(element)
# 查找 set1 和 set2 的根节点
set1_root = disjoint_set.find_set(set1[0])
set2_root = disjoint_set.find_set(set2[0])
# 合并根节点
disjoint_set.union_set(set1_root, set2_root)
# 返回合并后的集合
return disjoint_set.get_sets()
```
**集合交集:**
```python
def intersection_sets(set1, set2):
"""
找到两个集合的交集。
参数:
set1: 第一个集合
set2: 第二个集合
返回:
交集
"""
# 初始化并查集
disjoint_set = DisjointSet()
for element in set1:
disjoint_set.make_set(element)
for element in set2:
disjoint_set.make_set(element)
# 查找 set1 和 set2 的根节点
set1_root = disjoint_set.find_set(set1[0])
set2_root = disjoint_set.find_set(set2[0])
# 如果根节点相同,则说明有交集
if set1_root == set2_root:
return disjoint_set.get_set(set1_root)
else:
return set()
```
# 5. 并查集算法的扩展和变种
### 5.1 带权并查集扩展
**5.1.1 带权并查集的定义和应用场景**
带权并查集是在并查集算法的基础上进行扩展,在每个并查集节点中增加一个权重值。权重值可以表示节点的某种属性或重要性,例如节点的距离、大小或优先级。
带权并查集的应用场景包括:
- **最小生成树算法:** 克鲁斯卡尔算法在构建最小生成树时,需要对边进行排序,而带权并查集可以快速找到边权最小的边。
- **最短路径算法:** 迪杰斯特拉算法在寻找最短路径时,需要维护一个优先队列,而带权并查集可以快速找到优先级最高的节点。
- **网络流算法:** 在最大流算法中,需要维护一个残余网络,而带权并查集可以快速找到残余网络中流量最大的路径。
### 5.1.2 带权并查集的实现和优化
带权并查集的实现和优化与并查集算法类似,主要包括:
**查找操作:**
```python
def find(x):
if x != parent[x]:
parent[x] = find(parent[x])
return parent[x]
```
**合并操作:**
```python
def union(x, y):
x_root = find(x)
y_root = find(y)
if x_root != y_root:
if rank[x_root] < rank[y_root]:
parent[x_root] = y_root
else:
parent[y_root] = x_root
if rank[x_root] == rank[y_root]:
rank[x_root] += 1
```
**权重更新:**
在带权并查集中,需要维护每个节点的权重值。在合并操作中,可以将两个节点的权重值进行合并,例如取最大值或平均值。
```python
def update_weight(x, weight):
parent[x] = weight
```
### 5.2 离线并查集变种
**5.2.1 离线并查集的定义和应用场景**
离线并查集是一种并查集算法的变种,它处理的是一组离线查询。离线查询是指在算法执行之前,所有查询都已知,并且算法只能在所有查询都已知后才能执行。
离线并查集的应用场景包括:
- **处理海量数据:** 当数据量非常大时,在线并查集算法可能会耗费大量时间,而离线并查集算法可以将所有查询离线处理,提高效率。
- **并行计算:** 离线并查集算法可以并行处理查询,提高计算速度。
- **数据分析:** 离线并查集算法可以用于分析离线数据,例如日志文件或历史记录。
### 5.2.2 离线并查集的实现和优化
离线并查集的实现和优化与并查集算法类似,主要包括:
**查询预处理:**
在离线并查集算法中,需要对查询进行预处理,将所有查询按时间顺序排序。
**并查集维护:**
与在线并查集算法类似,需要维护一个并查集数据结构,对查询进行处理。
**查询处理:**
对于每个查询,需要根据查询的时间戳,将并查集数据结构恢复到查询发生时的状态,然后执行查询操作。
```python
def offline_union_find(queries):
# 对查询进行预处理
queries.sort(key=lambda x: x[2])
# 初始化并查集
parent = [i for i in range(n)]
rank = [0 for i in range(n)]
# 遍历查询
for query in queries:
op, x, y = query
if op == 'U':
# 合并操作
x_root = find(x)
y_root = find(y)
if x_root != y_root:
if rank[x_root] < rank[y_root]:
parent[x_root] = y_root
else:
parent[y_root] = x_root
if rank[x_root] == rank[y_root]:
rank[x_root] += 1
elif op == 'F':
# 查找操作
x_root = find(x)
if x_root == y:
print("YES")
else:
print("NO")
```
# 6. 并查集算法的应用案例
### 6.1 并查集算法在社交网络中的应用
#### 6.1.1 社交网络中并查集算法的应用场景
在社交网络中,并查集算法可以用于解决以下问题:
- **好友关系查询:**判断两个用户是否为好友。
- **朋友圈分组:**将用户划分为不同的朋友圈。
- **传播范围计算:**计算信息在社交网络中传播的范围。
#### 6.1.2 并查集算法解决社交网络问题的示例
**好友关系查询**
```python
def find_friend(parent, x):
"""
查找元素 x 的祖先节点。
"""
if parent[x] != x:
parent[x] = find_friend(parent, parent[x])
return parent[x]
def is_friend(parent, x, y):
"""
判断元素 x 和 y 是否为好友。
"""
return find_friend(parent, x) == find_friend(parent, y)
```
**朋友圈分组**
```python
def make_friend_group(parent, n):
"""
将 n 个用户划分为不同的朋友圈。
"""
for i in range(n):
if parent[i] == i:
print("朋友圈", i, ": ", end="")
for j in range(n):
if find_friend(parent, j) == i:
print(j, end=" ")
print()
```
### 6.2 并查集算法在图像处理中的应用
#### 6.2.1 图像处理中并查集算法的应用场景
在图像处理中,并查集算法可以用于解决以下问题:
- **连通域检测:**识别图像中连通的区域。
- **图像分割:**将图像分割成不同的区域。
- **形态学操作:**执行图像的形态学操作,如膨胀和腐蚀。
#### 6.2.2 并查集算法解决图像处理问题的示例
**连通域检测**
```python
def find_connected_component(image):
"""
识别图像中连通的区域。
"""
parent = [[-1 for _ in range(image[0])] for _ in range(len(image))]
for i in range(len(image)):
for j in range(len(image[0])):
if image[i][j] == 1:
if i > 0 and image[i - 1][j] == 1:
parent[i][j] = find_friend(parent, i - 1, j)
elif j > 0 and image[i][j - 1] == 1:
parent[i][j] = find_friend(parent, i, j - 1)
else:
parent[i][j] = i * len(image[0]) + j
return parent
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 送3个月
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
**并查集算法专栏**
本专栏深入剖析并查集算法的原理和应用,从基础概念到实战场景,全方位解读这一高效的数据结构。专栏涵盖了并查集算法的优化秘籍、与图论的结合、在社交网络、网络流、数据挖掘、机器学习、游戏开发、分布式系统、物联网、云计算、人工智能、金融科技、教育科技、交通运输和制造业等领域的应用。通过深入浅出的讲解和丰富的实战案例,本专栏旨在帮助读者掌握并查集算法的精髓,并将其应用于解决实际问题,提升算法效率和数据处理能力。
专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Advanced Network Configuration and Port Forwarding Techniques in MobaXterm
# 1. Introduction to MobaXterm
MobaXterm is a powerful remote connection tool that integrates terminal, X11 server, network utilities, and file transfer tools, making remote work more efficient and convenient.
### 1.1 What is MobaXterm?
MobaXterm is a full-featured terminal software designed spec
希尔排序的并行潜力:多核处理器优化的终极指南
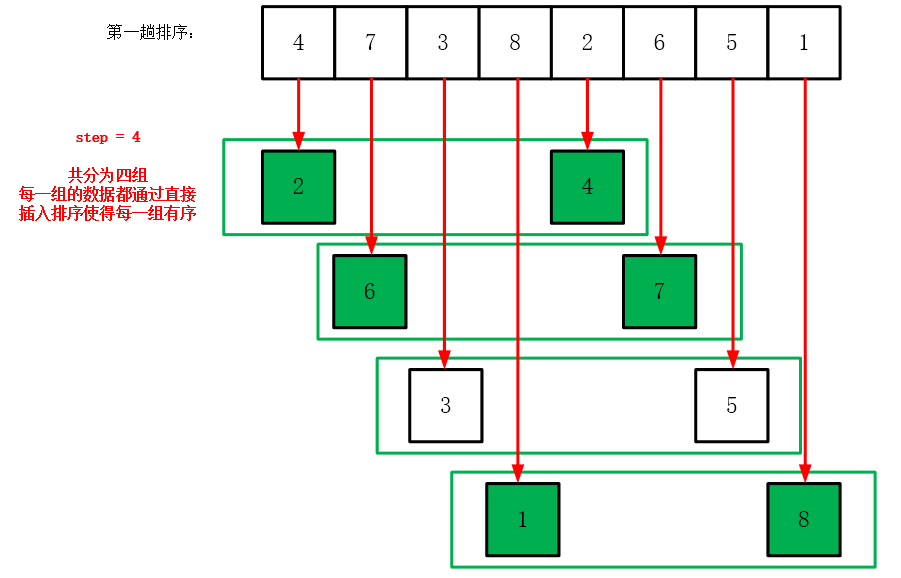
# 1. 希尔排序算法概述
希尔排序算法,作为插入排序的一种更高效的改进版本,它是由数学家Donald Shell在1959年提出的。希尔排序的核心思想在于先将整个待排序的记录序列分割成若干子序列分别进行直接插入排序,待整个序列中的记录"基本有序"时,再对全体记录进行一次直接插入排序。这样的方式大大减少了记录的移动次数,从而提升了算法的效率。
## 1.1 希尔排序的起源与发展
希尔排序算法的提出,旨在解决当时插入排序在处理大数据量
The Application and Challenges of SPI Protocol in the Internet of Things
# Application and Challenges of SPI Protocol in the Internet of Things
The Internet of Things (IoT), as a product of the deep integration of information technology and the physical world, is gradually transforming our lifestyle and work patterns. In IoT systems, each physical device can achieve int
Clock Management in Verilog and Precise Synchronization with 1PPS Signal
# 1. Introduction to Verilog
Verilog is a hardware description language (HDL) used for modeling, simulating, and synthesizing digital circuits. It provides a convenient way to describe the structure and behavior of digital circuits and is widely used in the design and verification of digital system
MATLAB Versions and Deep Learning: Model Development Training, Version Compatibility Guide
# 1. Introduction to MATLAB Deep Learning
MATLAB is a programming environment widely used for technical computation and data analysis. In recent years, MATLAB has become a popular platform for developing and training deep learning models. Its deep learning toolbox offers a wide range of functions a
【Advanced】Introduction to the MATLAB_Simulink Power System Simulation Toolbox
# 1. Overview of MATLAB_Simulink Power System Simulation Toolbox
The MATLAB_Simulink Power System Simulation Toolbox is a powerful toolkit designed for modeling, simulating, and analyzing power systems. It offers a comprehensive library of power system components, including generators, transformers
【树结构遍历操作】:JavaScript深度优先与广度优先算法详解

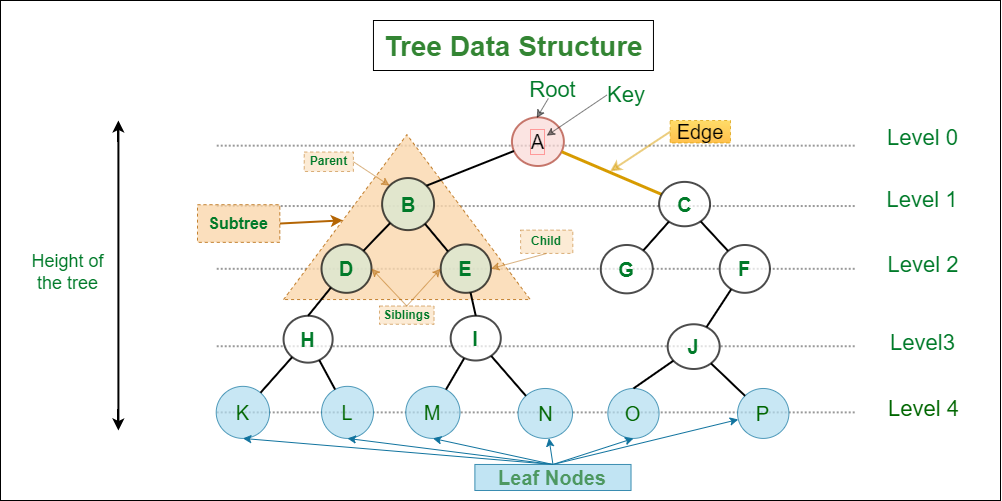
# 1. 树结构遍历操作概述
在计算机科学中,树结构是表示数据的一种重要方式,尤其在处理层次化数据时显得尤为重要。树结构遍历操作是树上的核心算法,它允许我们访问树中每一个节点一次。这种操作广泛应用于搜索、排序、以及各种优化问题中。本章将概览树结构遍历的基本概念、方法和实际应用场景。
## 1.1 树结构的定义与特性
树是由一个集合作为节点和一组连接这些节点的边构成的图。在树结构中,有一个特殊
The Status and Role of Tsinghua Mirror Source Address in the Development of Container Technology
# Introduction
The rapid advancement of container technology is transforming the ways software is developed and deployed, making applications more portable, deployable, and scalable. Amidst this technological wave, the image source plays an indispensable role in containers. This chapter will first
【JS树结构转换新手入门指南】:快速掌握学习曲线与基础
# 1. JS树结构转换基础知识
## 1.1 树结构转换的含义
在JavaScript中,树结构转换主要涉及对树型数据结构进行处理,将其从一种形式转换为另一种形式,以满足不同的应用场景需求。转换过程中可能涉及到节点的添加、删除、移动等操作,其目的是为了优化数据的存储、检索、处理速度,或是为了适应新的数据模型。
## 1.2 树结构转换的必要性
树结构转
The Prospects of YOLOv8 in Intelligent Transportation Systems: Vehicle Recognition and Traffic Optimization
# 1. Overview of YOLOv8 Target Detection Algorithm**
YOLOv8 is the latest iteration of the You Only Look Once (YOLO) target detection algorithm, released by the Ultralytics team in 2022. It is renowned for its speed, accuracy, and efficiency, making it an ideal choice for vehicle identification and
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
送3个月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )