Celery与Kubernetes集成:容器化任务队列的实践之路
发布时间: 2024-10-04 10:54:58 阅读量: 34 订阅数: 22 
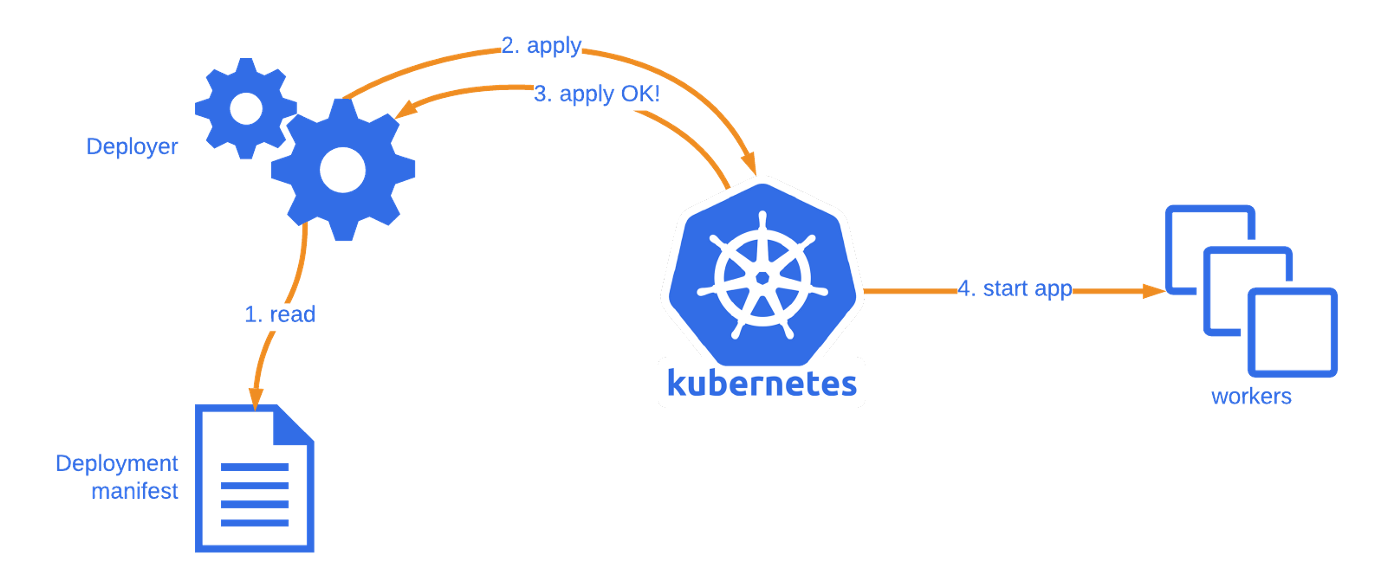
# 1. Celery与Kubernetes集成概述
在当今高度动态的IT环境中,应用需要具备迅速扩展和回收资源的能力,以应对业务负载的波动。使用任务队列来处理后台任务是常见的做法,而Celery作为一个异步任务队列/作业队列,以其简单、可靠和灵活的特点,在IT领域广受欢迎。然而,传统的部署方式在资源管理和扩展性方面有所局限。容器化技术的兴起,尤其是Kubernetes的广泛应用,为Celery带来了新的集成可能性。
Kubernetes作为一个开源的容器编排平台,它管理容器化应用的部署、扩展和操作。通过将Celery集成进Kubernetes,我们能够利用Kubernetes强大的调度和自愈功能,提高任务处理的可靠性和效率。这章我们将探讨Celery与Kubernetes集成的基础概念,为接下来的详细集成实践和高级应用打下基础。
# 2. 容器化任务队列的理论基础
## 2.1 Celery分布式任务队列简介
Celery是一个流行的、分布式的任务队列系统,它的设计目标是支持异步任务处理,从而提高应用的响应性和吞吐量。本小节将深入探讨Celery的工作原理以及在它内部如何使用消息代理和后端存储。
### 2.1.1 Celery的工作原理
Celery的工作流程基于生产者-消费者模型,其中生产者发出任务,消费者执行这些任务。在Celery中,生产者被称为客户端(Client),它使用Celery的API来发送任务到消息代理(Broker)。消费者则是在后台运行的Celery Worker,它们从代理中获取任务并执行。
当客户端提交一个任务时,Celery会将任务序列化并发送给消息代理。消息代理维护一个任务队列,Worker轮询代理,获取任务,并将结果存回代理或直接返回给客户端,如果配置了结果后端(Result Backend)的话。
#### 工作流程图示
以下是Celery工作流程的简化图示:
```mermaid
graph LR
A[客户端] -->|发送任务| B(消息代理)
B -->|轮询获取任务| C[Worker]
C -->|执行任务| D[任务执行结果]
D -->|存储结果| E(结果后端)
```
### 2.1.2 Celery中的消息代理和后端
Celery支持多种消息代理,比如RabbitMQ、Redis、Amazon SQS等。消息代理是任务队列系统的核心组件,它负责接收、保存和转发任务。选择合适的代理可以决定任务队列的性能和可靠性。
此外,Celery还支持不同的后端存储来保存任务执行的结果。这可以是数据库(如MySQL、PostgreSQL)或者是简单存储系统(如Redis、Memcached)。
下表列出了一些常见的代理和后端配置组合,并描述了它们的特性:
| 代理类型 | 后端类型 | 特性 |
| :-------: | :------: | :----: |
| RabbitMQ | Redis | 快速、轻量级,适用于小型到中型应用 |
| Redis | PostgreSQL | 简单、易于配置,适用于需要持久化结果的应用 |
| Amazon SQS | MySQL | 扩展性好,适用于云环境和大型分布式应用 |
使用消息代理和后端可以实现任务的持久化、故障转移和负载均衡等功能。这样即使在系统崩溃的情况下,任务也不会丢失,并且可以自动地在其他节点上重试。
## 2.2 Kubernetes容器编排概述
Kubernetes已经成为容器编排的事实标准,提供了自动化部署、扩展和管理容器化应用的强大能力。本小节将介绍Kubernetes的基本架构和组件,以及如何通过基本操作使用它。
### 2.2.1 Kubernetes架构和组件
Kubernetes架构主要由Master节点和Worker节点组成。Master节点负责集群的管理,而Worker节点则运行实际的容器应用。
#### 核心组件
- **API Server**: 负责处理集群的各种操作请求。
- **Scheduler**: 根据资源需求和约束,调度Pod到合适的Worker节点。
- **Controller Manager**: 运行集群的后台进程,如副本控制器等。
- **etcd**: 一个轻量级、分布式的键值存储系统,用于存储集群状态信息。
#### 节点组件
- **Kubelet**: 确保容器运行在Pod中。
- **Kube-Proxy**: 维护节点网络规则,实现服务抽象。
- **Container Runtime**: 如Docker或rkt,负责运行容器。
#### 对象模型
Kubernetes对象如Pod、Service、Deployment等都是集群状态的一部分,API Server通过这些对象维护集群的状态。
### 2.2.2 Kubernetes的基本操作和概念
使用Kubernetes需要理解其核心概念,如Pods、Services、Deployments、Namespaces等。每个Pod可以包含一个或多个容器,而Service为这些Pod提供一个固定的网络接口。Deployment帮助管理Pod和ReplicaSet,确保应用的正确副本数和自我修复。Namespaces用于隔离资源和用户的访问权限。
下面是创建一个简单的Deployment的基本YAML配置示例:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
```
此配置定义了一个名为`my-nginx-deployment`的Deployment,它创建3个副本,每个副本运行一个使用最新镜像的Nginx容器。
Kubernetes的基本操作还包括了如何管理这些对象,如扩展、更新和回滚等。
## 2.3 集成Celery与Kubernetes的必要性
在动态任务队列和容器编排的世界中,集成Celery与Kubernetes能够提供高可用性和可扩展性,满足现代应用的需求。
### 2.3.1 容器化对于动态任务队列的益处
容器化技术,特别是与Kubernetes集成后,可以为Celery带来以下优势:
- **动态扩展**: 根据任务负载动态地创建或销毁Celery Worker。
- **资源优化**: 灵活地为任务分配合适的资源,避免资源浪费。
- **故障转移**: 在Worker节点或容器出现问题时,自动调度到其他节点。
### 2.3.2 实现可扩展性和高可用性的需求
通过将Celery任务队列部署在Kubernetes之上,可以实现以下目标:
- **水平扩展**: 通过增加Pod数量来处理更多的任务。
- **高可用**: Kubernetes的自我修复机制确保应用永远在线。
- **负载均衡**: Kubernetes的调度器将任务均衡地分配给各个Worker。
这种集成保证了即使在高负载或部分故障的情况下,任务处理的连续性和效率。
[接下来将会是第三章的内容,详细介绍了如何将Celery Worker部署到Kubernetes集群。]
# 3. Celery与Kubernetes集成实践
## 3.1 部署Celery Worker到Kubernetes集群
部署Celery Worker到Kubernetes集群涉及将任务处理器容器化并利用Kubernetes的强大功能来管理这些任务。下面将详细介绍如何创建Docker镜像以及配置和部署Kubernetes Pod和Service。
### 3.1.1 创建Docker镜像
为了在Kubernetes集群中运行Celery Worker,我们首先需要创建一个包含所有Celery依赖项的Docker镜像。以下是一个基本的Dockerfile,用于构建Celery Worker镜像:
```Dockerfile
FROM python:3.8-slim
# 安装依赖包
RUN pip install --upgrade pip
ADD ./requirements.txt /tmp/requirements.txt
RUN pip install --no-cache-dir -r /tmp/requirements.txt
# 添加源代码到镜像中
ADD . /app
# 工
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 库文件学习之 Celery 专栏!本专栏将带你深入了解 Celery,一个强大的分布式任务队列。从入门到精通,我们将探索 Celery 的各个方面,包括任务调度、定时执行、配置、消息代理选择、持久化、故障恢复、监控、日志管理、优先级、路由、在微服务架构中的应用、依赖关系、回调、异常处理、重试机制、预热、冷却以及与其他消息队列技术的对比。通过深入的讲解和丰富的示例,本专栏将帮助你掌握 Celery 的核心概念和最佳实践,从而构建高效、稳定且可扩展的任务队列系统。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
一步步揭秘:安国量产工具故障诊断及常见问题排除指南
# 摘要
本文全面介绍了安国量产工具故障诊断的过程和技巧。首先,概述了量产工具的基本工作原理及故障诊断理论基础,接着详细分析了故障诊断的基本步骤和类型,并提供了一系列实践操作中排故障的技巧。在第四章,本文探讨了高级故障诊断技术,包括特殊工具的使用和系统性能监控。最后一章强调了社区支持在故障诊断中的重要性,并提出了持续学习和技能提升的策略。整体而言,本文旨在为读者提供一套完整且实用的安国量产工具故障诊
EXata-5.1故障排查与性能调优:确保最佳性能的专家技巧
# 摘要
本文全面介绍EXata-5.1的故障诊断与性能调优知识,涵盖了从基础理论到高级技术的综合指南。首先,文章概述了EXata-5.1的架构和工作原理,并准备了故障排查的基础。接着,文章深入分析了故障诊断的理论基础,包括不同故障类型的特征和排查工具的使用。在此基础上,实践技巧章节通过日志分析、性能监控和配置优化为用户提供了故障解决的实用技巧。性能调优方面,文章详细
tc234常见问题解答:专家教你快速解决问题

# 摘要
本文对tc234软件的使用进行全面而深入的分析,涵盖了从基础安装、配置到故障排查、性能优化,以及扩展功能和未来发展趋势。首先介绍了tc234的基本概念和安装配置的详细步骤,强调了环境变量设置的重要性以及常用命令的使用技巧。接着,文章深入探讨了故障排查的策略和高级问题的分析方法,并分享了专家级的故障解决案例。在性能优化部分,结合实际应用案例提供了性能调优的技巧和安全加固措施。最后,展望了tc234的扩展功能、定制开发潜力以及技术发展对行业的影
【ANSYS数据处理新境界】:函数应用在高效结果分析中的应用

# 摘要
ANSYS作为强大的工程仿真软件,其数据处理和结果分析能力对工程设计和科学研究至关重要。本文综述了ANSYS中数据处理的基础知识、函数的
【深入探索TLV3501】:技术规格解读与应用领域拓展
# 摘要
本文深入探讨了TLV3501技术规格及其在数据通信、嵌入式系统集成开发和创新应用拓展中的关键作用。首先,文章详细解读了TLV3501的技术特性以及在数据通信领域中,通过不同通信协议和接口的应用情况。然后,本文分析了TLV3501与嵌入式系统集成的过程,包括开发工具的选择和固件
【Catia轴线在装配体设计中的应用】:4个关键步骤解析

# 摘要
本文探讨了Catia软件中轴线功能在装配体设计中的关键作用。通过分析Catia基础操作与轴线的定义,本文详细介绍了轴线创建、编辑和高级应用的技巧,并针对轴线设计中常见的问题提出了解决方案。此外,本文还探讨了Catia轴线设计的未来趋势,包括与新技术的结合以及创新设计思路的应用,为设计师和工程师提供了提高装配体设计效率与精确度的参考。
# 关键
安川 PLC CP-317编程基础与高级技巧

# 摘要
PLC CP-317编程是工业自动化领域中的关键技能,本文首先对PLC CP-317编程进行概述,随后深入探讨了其基础理论、实践技巧以及高级编程技术。文章详细解析了CP-317的硬件结构、工作原理、编程环境和基础命令,进一步阐述了数据处理、过程控制和网络通信等编程实践要点。在高级编程技术方面,文中讨论了复杂算法、安全性和异常处理的应用,以及模块化和标准化
【Matrix Maker 初探】:快速掌握中文版操作的7个技巧

# 摘要
本文系统地介绍了一个名为Matrix Maker的软件,从用户界面布局、基础操作技巧到高级功能应用进行了全面的论述。其中,基础操作技巧章节涵盖了文档的创建、编辑、格式设置及文本排版,使用户能够掌握基本的文档处理技能。在高级功能应用章节中,详细讲解了图表与数据处理、宏和模板的使用,增强了软件在数据管理与自动化处理方面的能力。操作技巧进阶章节则着重于提高用户工作效率,包括自定义工具栏与快捷键、文档安全与共享。
Matlab基础入门:一步到位掌握编程核心技巧!
# 摘要
Matlab作为一种高性能的数值计算和可视化软件,广泛应用于工程、科学和教学领域。本文旨在为读者提供Matlab软件的全面介绍,包括其安装配置、基础语法、编程实践以及高级应用。通过对数组与矩阵操作、GUI设计、数据可视化、脚本编写、文件处理及高级编程技巧等方面的探讨,本文旨在帮助读者快速掌握Matlab的核心功能,并通过综合项目实践环节强化学习效果。同时,本文还介绍了Matlab工具箱的使用,以及如何利用开源项目和社
FEKO5.5进阶调整法

# 摘要
FEKO5.5是一款广泛应用的电磁仿真软件,该软件在电磁工程领域具有显著的应用价值和优势。本文首先介绍了FEKO5.5的基础知识,然后重点分析了其建模技术的提升,包括几何模型构建、材料与边界条件设置、以及参数化建模与优化设计方法。接着,本文深入探讨了FEKO5.5仿真分析方法,涵盖频域分析技术、时域分析技术和多物理场耦合分析,这些分析方法对于提高仿真精度和效率至关重
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )