MATLAB Gaussian Fitting Error Analysis: Evaluating Fitting Results for Accuracy Assurance
发布时间: 2024-09-14 19:26:28 阅读量: 46 订阅数: 26 

Gaussian pdf analysis:高斯pdf分析-matlab开发
# Introduction to MATLAB Gaussian Fitting Error Analysis: Evaluating Fitting Results for Accuracy Assurance
## 1. Brief Introduction to MATLAB Gaussian Fitting
Gaussian fitting is a nonlinear regression technique used to fit data points to a Gaussian function. A Gaussian function is a bell-shaped curve defined by three parameters: mean, standard deviation, and amplitude. MATLAB provides a function named `fit` to perform Gaussian fitting.
```matlab
% Creating data points
x = linspace(-5, 5, 100);
y = exp(-x.^2 / 2) + 0.1 * randn(size(x));
% Gaussian fitting
model = fit(x', y', 'gauss1');
% Extracting fitting parameters
mu = model.b1;
sigma = model.c1;
A = model.a1;
```
With Gaussian fitting, we can obtain the three parameters of the Gaussian function that describe the distribution characteristics of the data.
## 2. Theoretical Aspects of Gaussian Fitting Error Analysis
### 2.1 Sources and Classification of Errors
The errors present in Gaussian fitting can be broadly categorized into two types: random errors and systematic errors.
**2.1.1 Random Errors**
Random errors are unpredictable and are caused by random fluctuations or noise in the measurement process. These errors typically follow a normal distribution, with their magnitude and direction being random.
**2.1.2 Systematic Errors**
Systematic errors are predictable and are caused by systematic biases in the measurement equipment or methodology. These errors are usually asymmetric and can systematically affect fitting results.
### 2.2 Error Evaluation Metrics
To quantify the error in Gaussian fitting, the following metrics can be used:
**2.2.1 Root Mean Square Error (RMSE)**
RMSE is the square root of the sum of squared errors and represents the average deviation of the fitted curve from the actual data. A smaller RMSE indicates a higher fitting accuracy.
**2.2.2 Maximum Absolute Error (MAE)**
MAE is the average of the absolute values of errors and represents the largest deviation between the fitted curve and the actual data. A smaller MAE indicates a higher fitting accuracy.
**2.2.3 Coefficient of Determination (R^2)**
R^2 indicates the degree of correlation between the fitted curve and the actual data. An R^2 value closer to 1 signifies higher fitting accuracy.
## 3. Data Preprocessing and Model Selection
**3.1.1 Data Cleaning and Transformation**
Data preprocessing is crucial before Gaussian fitting. It includes:
- **Outlier Detection and Removal:** Outliers can significantly impact fitting results and should be identified and removed.
- **Data Transformation:** Data may need to be transformed to conform to the assumptions of the Gaussian distribution. For example, logarithmic transformation for non-normal data.
- **Data Normalization:** Data normalization can eliminate scale differences between different features, thus improving fitting accuracy.
**3.1.2 Comparison of Different Models**
When selecting a Gaussian fitting model, consider the following factors:
- **Data Distribution:** The data distribution determines the most suitable model type, such as normal or log-normal distribution.
- **Model Complexity:** There is a trade-off between model complexity and fitting accuracy. More complex models may overfit the data, while simpler models may fail to capture the data's complexity.
- **Computation Time:** The computation time of the model is also a factor to consider, ***
***mon model selection methods include:
- **Akaike Information Criterion (AIC):** AIC measures the trade-off between fitting accuracy and model complexity. A lower AIC value indicates a better model.
- **Bayesian Information Criterion (BIC):** BIC is similar to AIC bu

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【XJC-608T-C控制器与Modbus通讯】:掌握关键配置与故障排除技巧(专业版指南)
.jpg)
# 摘要
本文全面介绍了XJC-608T-C控制器与Modbus通讯协议的应用与实践。首先概述了XJC-608T-C控制器及其对Modbus协议的支持,接着深入探讨了Modbus协议的理论基础,包括其发展历史和帧结构。文章详细说明了XJC-608T-C控制器的通信接口配置,以及如何进行Modbus参数的详细设置。第三章通过实践应用,阐述了Modbus RTU和TCP通讯模
掌握Walktour核心原理:测试框架最佳实践速成

# 摘要
本文详细介绍了Walktour测试框架的结构、原理、配置以及高级特性。首先,概述了测试框架的分类,并阐述了Walktour框架的优势。接着,深入解析了核心概念、测试生命周期、流程控制等关键要素。第三章到第五章重点介绍了如何搭建和自定义Walktour测试环境,编写测试用例,实现异常
【水文模拟秘籍】:HydrolabBasic软件深度使用手册(全面提升水利计算效率)

# 摘要
本文全面介绍HydrolabBasic软件,旨在为水文学研究与实践提供指导。文章首先概述了软件的基本功能与特点,随后详细阐述了安装与环境配置的流程,包括系统兼容性检查、安装步骤、环境变量与路径设置,以及针对安装过程中常见问题的解决方案。第三章重点讲述了水文模拟的基础理论、HydrolabBasic的核心算法以及数据处理技巧。第四章探讨了软件的高级功能,如参数敏感
光盘挂载效率优化指南:提升性能的终极秘籍
# 摘要
本文全面探讨了光盘挂载的基础知识、性能瓶颈、优化理论及实践案例,并展望了未来的发展趋势。文章从光盘挂载的技术原理开始,深入分析了影响挂载性能的关键因素,如文件系统层次结构、挂载点配置、读写速度和缓存机制。接着,提出了针对性的优化策略,包括系统参数调优、使用镜像文件以及自动化挂载脚本的应用,旨在提升光盘挂载的性能和效率。通过实际案例研究,验证了优化措施的有效
STM32F407ZGT6硬件剖析:一步到位掌握微控制器的10大硬件特性
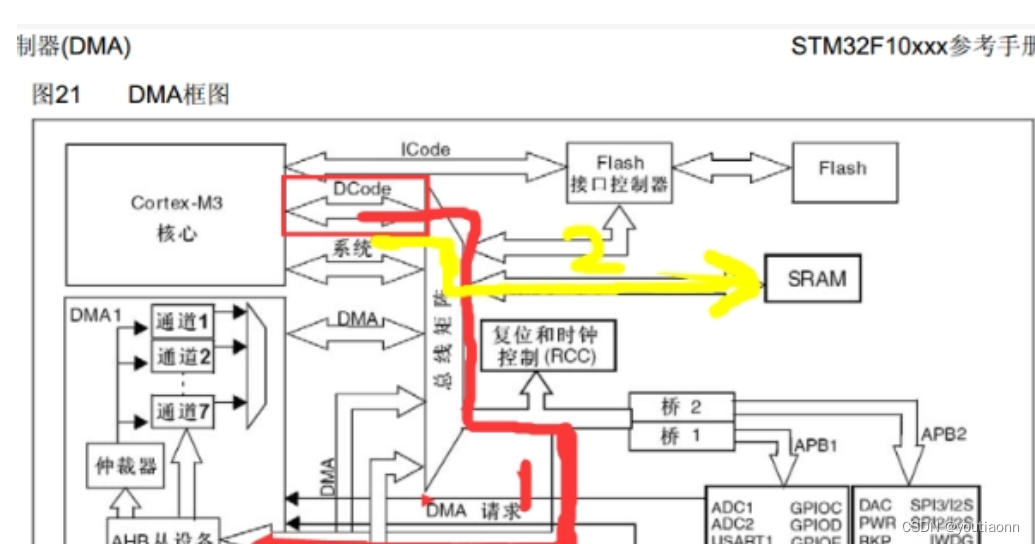
# 摘要
本文针对STM32F407ZGT6微控制器进行了全面的概述,重点分析了其核心处理器与存储架构。文章详细阐述了ARM Cortex-M4内核的特性,包括其性能和功耗管理能力。同时,探讨了内部Flash和RAM的配置以及内存保护与访问机制。此外,本文还介绍了STM32F407ZGT6丰富的外设接口与通信功能,包括高速通信接口和模拟/数字外设的集成。电源管理和低功耗
【系统性能优化】:专家揭秘注册表项管理技巧,全面移除Google软件影响

# 摘要
注册表项管理对于维护和优化系统性能至关重要。本文首先介绍了注册表项的基础知识和对系统性能的影响,继而探讨了优化系统性能的具体技巧,包括常规和高级优化方法及其效果评估。文章进一步深入分析了Google软件对注册表的作用,并提出了清理和维护建议。最后,通过综合案例分析,展示了注册表项优化的实际效果,并对注册表项管理的未来趋势进行了展望。本文旨在为读者提供注册表项管理的全面理解,并帮助他们有效提升系统性能。
SAPRO V5.7高级技巧大公开:提升开发效率的10个实用方法

# 摘要
本文全面介绍SAPRO V5.7系统的核心功能与高级配置技巧,旨在提升用户的工作效率和系统性能。首先,对SAPRO V5.7的基础知识进行了概述。随后,深入探讨了高级配置工具的使用方法,包括工具的安装、设置以及高级配置选项的应用。接着,本文聚焦于编程提升策略,分享了编码优化、IDE高级使用以及版本控制的策略。此外,文章详细讨论了系统维护和监控的
线扫相机选型秘籍:海康vs Dalsa,哪个更适合你?
# 摘要
本文对线扫相机技术进行了全面的市场分析和产品比较,特别聚焦于海康威视和Dalsa两个业界领先品牌。首先概述了线扫相机的技术特点和市场分布,接着深入分析了海康威视和Dalsa产品的技术参数、应用案例以及售后服务。文中对两者的核心性能、系统兼容性、易用性及成本效益进行了详尽的对比,并基于不同行业应用需求提出了选型建议。最后,本文对线扫相机技术的未来发展趋势进行了展望,并给出了综合决策建议,旨在帮助技术人员和采购者更好地理解和选择适合的线扫相机产品。
# 关键字
线扫相机;市场分析;技术参数;应用案例;售后服务;成本效益;选型建议;技术进步
参考资源链接:[线扫相机使用与选型指南——海
【Smoothing-surfer绘图性能飞跃】:图形渲染速度优化实战

# 摘要
图形渲染是实现计算机视觉效果的核心技术,其性能直接影响用户体验和应用的互动性。本文第一章介绍了图形渲染的基本概念,为理解后续内容打下基础。第二章探讨了图形渲染性能的理论基础,包括渲染管线的各个阶段和限制性能的因素,以及各种渲染算法的选择与应用。第三章则专注于性能测试与分析,包括测试工具的选择、常见性能
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )