【LSTM调参秘籍】:打造高性能模型,训练技巧大公开
发布时间: 2024-09-05 23:02:02 阅读量: 115 订阅数: 78 
# 1. LSTM模型基础与应用背景
在当今的人工智能领域,长短期记忆网络(LSTM)是一种在处理序列数据方面特别有用的循环神经网络(RNN)架构。本章将为您梳理LSTM的基本概念,并探讨其在各行业中的应用背景。
## 1.1 LSTM的诞生与发展
LSTM由Hochreiter与Schmidhuber在1997年提出,目的在于解决传统RNN在学习长期依赖问题时遇到的难题。由于其独特的门控结构,LSTM能够有效地捕捉序列中的长期依赖关系,避免了传统RNN遇到的梯度消失问题。
## 1.2 LSTM的适用场景
LSTM因其卓越的记忆能力,广泛应用于自然语言处理(NLP)、语音识别、时间序列分析等领域。在处理文本、语音和各种时间相关的数据时,LSTM能展示其强大的序列学习能力。
## 1.3 LSTM的优势分析
相较于其他机器学习模型,LSTM主要优势在于其内部复杂的门控机制,这使得它能够调节信息流动,保留有用的信息并遗忘掉不相关的信息。这一点对许多实际问题,特别是那些需要记忆历史信息的问题至关重要。
在接下来的章节中,我们将深入探讨LSTM的网络结构、理论基础以及如何进行调参和优化,以适应更复杂的应用需求。
# 2. LSTM网络结构与理论基础
## 2.1 LSTM单元的工作原理
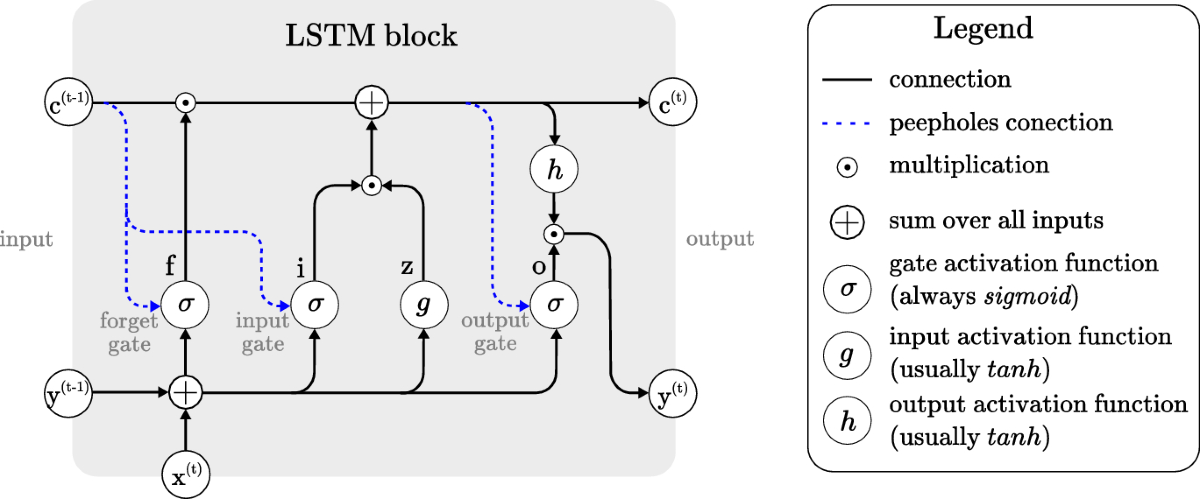
### 2.1.1 LSTM单元的结构介绍
长短期记忆(LSTM)网络是一种特殊的循环神经网络(RNN),能够学习长期依赖信息。LSTM的核心在于其精心设计的单元结构,每个单元包括一个细胞状态、三个门(忘记门、输入门、输出门)以及一个隐藏状态。这种结构使得LSTM能够在必要时保持信息不变,并在适当的时候添加或移除信息。
细胞状态类似于一个传送带,贯穿整个LSTM单元链,携带着长期状态信息。门控机制则由sigmoid神经网络层和点乘操作组成,它们决定信息的保留与传递。
一个典型的LSTM单元可以表示为以下数学公式:
- **忘记门**:决定要从细胞状态中丢弃什么信息。这个门使用sigmoid层生成0到1之间的数,表示每项信息的重要性。
\[ f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) \]
- **输入门**:决定新输入的数据中,哪些部分将被存储到细胞状态中。它同样使用sigmoid层,而候选值的更新则通过tanh层来进行。
\[ i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) \]
\[ \tilde{C}_t = \text{tanh}(W_C \cdot [h_{t-1}, x_t] + b_C) \]
- **细胞状态更新**:通过忘记门决定丢弃的信息和输入门确定的新信息来更新细胞状态。
\[ C_t = f_t * C_{t-1} + i_t * \tilde{C}_t \]
- **输出门**:决定输出什么信息,通常是基于当前细胞状态的信息,通过tanh函数进行规范化后,再乘以sigmoid门的输出结果。
\[ o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o) \]
\[ h_t = o_t * \text{tanh}(C_t) \]
其中,\( \sigma \) 表示sigmoid激活函数,\( \text{tanh} \) 是双曲正切函数,\( W \) 和 \( b \) 表示权重和偏置参数。
### 2.1.2 LSTM中的门控机制详解
LSTM的门控机制是其核心,它通过几个专门设计的门来控制信息的流动,包括哪些信息被遗忘,哪些新信息被添加到细胞状态中。这一机制可以有效地解决传统RNN在处理长序列数据时遇到的梯度消失和梯度爆炸问题。
- **忘记门**:此门负责审视当前输入和上一时刻的隐藏状态,决定哪些信息应该从细胞状态中删除。它学习到的数据范围介于0到1之间,0表示完全忘记,1表示完全保留。
- **输入门**:此门决定了哪些新的候选信息可以被添加到细胞状态。它的工作流程是两步:首先,一个sigmoid层决定了输入信息中哪些部分需要更新;然后一个tanh层创建了新的候选值向量,这个向量将被添加到状态中。
- **细胞状态更新**:细胞状态会根据忘记门和输入门的决定更新。它通过逐元素的方式结合旧状态和新候选状态来实现。忘记门控制了哪些信息需要丢弃,而输入门决定了哪些新信息要被添加。
- **输出门**:决定下一个隐藏状态的输出,这个隐藏状态包含了网络决定输出的信息。它首先通过sigmoid层决定哪些信息将被输出,然后将细胞状态通过tanh函数正规化后与这个信息相乘。
这种门控机制让LSTM单元能够有选择地记住或遗忘信息,从而捕捉长期依赖性,这是LSTM模型的关键优势。
## 2.2 LSTM与RNN的对比分析
### 2.2.1 循环神经网络(RNN)回顾
传统的循环神经网络(RNN)是为了处理序列数据而设计的网络结构,其核心在于循环连接。在时间步\(t\),RNN接收当前输入\(x_t\)和前一时间步的隐藏状态\(h_{t-1}\),通过一个简单的权重矩阵\(W\)和激活函数(如tanh或ReLU)来计算当前的隐藏状态\(h_t\)。
数学上,RNN的隐藏状态更新可以表示为:
\[ h_t = f(W \cdot [h_{t-1}, x_t]) \]
其中,\(f\)是激活函数,如tanh。
虽然RNN理论上具有处理序列数据的潜力,但是它存在两个主要问题:梯度消失问题和梯度爆炸问题。这些问题限制了RNN在长序列数据上的表现。
### 2.2.2 LSTM解决RNN的长期依赖问题
LSTM正是为了解决RNN在学习长期依赖时的不足而提出的。LSTM通过引入复杂的门控机制来有效地避免梯度消失和梯度爆炸问题。
LSTM不仅保留了RNN处理序列数据的优势,还通过其独特的门控单元结构增加了对长期依赖的捕获能力。相比RNN,LSTM能够更好地在序列的不同时间步之间传递信息,这使其在处理如自然语言处理、语音识别等依赖长期上下文的任务上表现出色。
LSTM的门控结构也允许它对序列信息进行有选择的记忆和遗忘,这为学习任务提供了更大的灵活性。例如,在自然语言处理任务中,LSTM能够记住句子中的关键部分,而忽略掉不重要的部分。
## 2.3 LSTM在各领域的应用案例
### 2.3.1 自然语言处理(NLP)
LSTM由于其强大的序列处理能力,在自然语言处理领域得到广泛的应用。它能够学习语言序列中的长期依赖关系,例如,用于句子分类、机器翻译、文本摘要、情感分析等任务。
使用LSTM的典型架构是将输入序列编码为固定长度的向量表示。例如,在机器翻译任务中,LSTM可以用于读取源语言句子,并将其编码为一个上下文相关的表示。然后,另一个LSTM或不同类型的解码器可以生成目标语言的翻译句子。
LSTM在NLP的成功应用主要得益于其能够通过门控机制记住和遗忘特定的信息,这对于理解复杂的语言结构和含义至关重要。
### 2.3.2 语音识别与合成
语音识别系统需要将连续的音频信号转换为文本,这涉及到对声音信号的时间序列进行建模和分析。LSTM网络在此任务中扮演了重要角色,尤其是在处理具有复杂时序动态变化的语音信号时。
LSTM可以通过对语音信号的时间序列进行有效的学习,来捕捉音频中的长期依赖和时序模式。这允许系统能够更准确地识别说话人的语音,并将其转换为文字。
在语音合成领域,LSTM同样扮演了核心角色,它用于生成自然听起来的语音波形。通过LSTM,可以学习文本到语音的映射关系,生成高质量的语音输出,从而改善如电子书朗读、语音助手和语音交互系统的用户体验。
### 2.3.3 时间序列预测
时间序列预测是分析时间序列数据,预测未来的数据点。LSTM特别适合这类任务,因为它能够记忆过去的信息,并将其用于对未来事件的预测。LSTM在金融市场分析、能源需求预测、库存管理等领域都有应用。
例如,在金融市场中,LSTM可以用来分析股票价格的历史数据,并预测未来的股价。LSTM网络可以捕捉价格变动的长期趋势和季节性模式,这对于制定投资策略非常有用。
在能源需求预测方面,LSTM能够理解天气变化、假期效应等因素对能源消耗的影响,然后预测未来一段时间内的能源需求量。通过有效的预测,能源公司可以更加高效地管理资源和减少浪费。
在这些应用中,LSTM的优势在于其对时间序列数据的长期依赖关系的建模能力,这使得它在处理非平稳时间序列数据时具有较高的准确性和鲁棒性。
# 3. LSTM模型的关键调参技巧
长短期记忆网络(LSTM)在时间序列分析、自然语言处理等领域取得了显著的成果。然而,要想从这些复杂的模型中获得最佳性能,关键在于调参技巧。通过理解模型的超参数作用与影响,掌握超参数调优方法论,以及深入探讨梯度消失与梯度爆炸的解决策略,我们可以实现LSTM模型性能的最优化。
## 3.1 理解超参数的作用与影响
### 3.1.1 超参数的基本概念
在机器学习模型的训练过程中,超参数是预先设定的参数,它们不能直接从数据中学习得到。超参数的选取对于模型的性能有着决定性的影响。在LSTM模型中,常见的超参数包括学习率、隐藏层单元数、批次大小(batch size)、序列长度、正则化系数等。理解这些超参数的含义及其对模型的影响是调参的第一步。
### 3.1.2 各超参数对模型性能的影响
- **学习率**:学习率决定了权重更新的速度。学习率过低会导致训练过程缓慢,而学习率过高可能会导致模型无法收敛。正确的学习率设置是模型能否快速收敛的关键。
- **隐藏层单元数**:隐藏层单元数影响模型的容量,即模型的复杂度。单元数太少可能无法捕捉数据中的复杂模式,太多又可能引起过拟合。
- **批次大小**:批次大小决定了每次迭代中使用的样本数。较大的批次大小可以加快训练速度,但也可能导致梯度估计的方差增大。
- **序列长度**:在处理时间序列数据时,序列长度的选择至关重要。过短的序列可能无法提供足够的上下文信息,过长则可能因为梯度消失问题

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
《长短期记忆网络(LSTM)详解》专栏深入剖析了 LSTM 的原理、变体、调参技巧和应用领域。从入门到精通,该专栏全面阐述了 LSTM 在时间序列分析和自然语言处理中的优势。此外,还探讨了 LSTM 的局限性,并提供了优化内存使用和并行计算的策略。通过实战案例和算法比较,专栏展示了 LSTM 在股市预测、机器翻译和深度学习框架中的卓越表现。此外,还提供了数据预处理指南,以确保 LSTM 模型的训练效果。本专栏为读者提供了全面了解 LSTM 的宝贵资源,帮助他们掌握这一强大的神经网络技术。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【状态机深度解析】:在Verilog中如何设计高效自动售货机
# 摘要
本文系统地探讨了状态机的设计与应用,首先介绍了状态机设计的基础知识,并详细阐述了在Verilog中实现状态机的设计原则,包括状态的分类、建模方法、状态编码及转换表的设计。接着,针对自动售货机的场景,本文详细描述了状态机的设计实现过程,包括用户界面交互、商品选择、货币处理和状态转换逻辑编写等。此外,还探讨了状态机的设计验证与测试,包括测试环境构建、仿真测试、调试和硬件实现验证。最后,本文提出了状态机优化的方法,并讨论了状态机在其他领域中的应
【MATLAB高级索引攻略】:解锁数据处理的隐藏技能

# 摘要
MATLAB作为一种高效的数据处理工具,其高级索引技术在数据科学领域发挥着重要作用。本文首先概述了MATLAB高级索引的基本概念与作用,随后深入探讨了索引操作的数学原理及数据结构。进一步,文章详细介绍了MATLAB高级索引实践技巧,包括复杂条件下的索引应用和高效数据提取与处理方法。在数据处理应用方面,本文阐述了处理大型数据集的索引策略、多维数据的可视化索引技术,以及M
C语言高级编程:子程序参数传递的全面解析
# 摘要
本文深入探讨了C语言中子程序参数传递的机制及其优化技术,首先概述了参数传递的基础知识,随后详细分析了按值传递和按引用传递的优缺点,以及在实现机制中的具体应用,包括内存中的参数布局、指针的作用和复合数据类型的传递。文章进一步探讨了高级参数传递技术,如指针的指针、const修饰符的使用以及可变参数列表的处理,并通过实践案例和最佳实践,讨论了在实际项目中应用这些技术的策略和技巧。本文旨在为C语言开发者提供系
【故障无忧】:西门子SINUMERIK 840D sl_828D测量循环问题全解析及解决之道

# 摘要
本文对西门子数控系统的核心组件SINUMERIK 840D sl/828D的测量循环功能进行了详尽的探讨。文章首先概述了测量循环的基本概念及其在制造业中的应用价值,然后详细介绍了测量循环的操作流程、编程指令以及高级应用技巧。通过故障分析章节,本文分类并识别了测量循环中常见的硬件和软件故障,提供了故障案例分析以及预防和监控策略。进一步地
数字签名机制全解析:RSA和ECDSA的工作原理及应用

# 摘要
本文全面概述了数字签名机制,详细介绍了公钥加密的理论基础,包括对称与非对称加密的原理和局限性、大数分解及椭圆曲线数学原理。通过深入探讨RSA和ECDSA算法的工作原理,本文揭示了两种算法在密钥生成、加密解密、签名验证等方面的运作机制,并分析了它们相对于传统加密方式
【CAD2002高级技巧】
# 摘要
本文对CAD2002软件进行全面的介绍和分析,从软件概述、界面布局、基础操作深入剖析,到绘图与编辑技巧实战,再到高级功能拓展以及优化与故障排除。文章详细阐述了CAD2002的工具与命令高级使用技巧、图层管理、块与外部参照应用等基础操作,深入探讨了精确绘图、高级编辑命令和综合绘图案例。此外,还介绍了CAD2002的参数化绘图、数据交换、自定义脚本编写等高级功能,以及性
Word 2016 Endnotes加载项疑难杂症:专家级解决方案
# 摘要
本文详细介绍了Word 2016中Endnotes功能的概述、工作原理、常见问题诊断以及应用实践,并展望了其发展。首先,对Endnotes功能进行了基础性的介绍,并探讨了其加载项的结构和作用。接着,分析了在使用Endnotes加载项时可能遇到的问题,包括不工作、冲突以及性能问题,并提
【搜索引擎查询优化】:提速与相关性提升的双重攻略

# 摘要
本文旨在综述搜索引擎查询优化的各个方面,从搜索引擎的工作原理、查询优化策略到实践案例分析,再到未来趋势。首先介绍了搜索引擎的基础工作流程,包括爬虫抓取、索引构建、查询处理和排名算法。随后,探讨了提升网页相关性、前端性能优化以及CDN和缓存机制的使用。案例分析部分深入研究了相关性改进、响应时间加
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )