【深度学习自编码器实战】:无监督学习的秘密武器使用手册
发布时间: 2024-09-03 10:15:23 阅读量: 112 订阅数: 59 

基于FPGA深度学习的Block 模块方案实战,适合FPGA初学者
# 1. 自编码器的理论基础
自编码器(Autoencoder)是一种无监督的神经网络,主要用于数据的降维和特征学习。其工作原理是通过一个编码过程将输入数据映射到一个隐藏的表示,再通过一个解码过程重构原始输入数据。本章将介绍自编码器的基本概念,包括其工作原理和相关术语的定义。
## 1.1 自编码器的工作原理
自编码器的结构主要由编码器(encoder)和解码器(decoder)两部分组成。编码器负责将输入数据压缩成内部表示(隐层编码),而解码器负责将这个表示重构回原始数据。在训练过程中,通过最小化输入和重构输出之间的差异,即损失函数的值,来更新网络参数,从而获得有效的特征表示。
自编码器的关键在于学习到输入数据的有效压缩表示,这种表示应当尽可能保留原始数据的重要信息,同时去除冗余部分。这就需要网络足够复杂,以学习到非线性的数据结构,同时又要防止过拟合,确保学到的表示具有泛化能力。
## 1.2 自编码器的类型
自编码器根据其结构和功能的不同,有多种变体,包括稀疏自编码器、去噪自编码器和卷积自编码器等。稀疏自编码器通过引入稀疏性惩罚项,鼓励网络学习更加稀疏的特征表示,以提高模型的泛化能力。去噪自编码器则是在输入数据中加入噪声,迫使网络学习一个更鲁棒的特征表示,从而提升模型的抗干扰能力。卷积自编码器则是专为处理图像数据设计,利用卷积层代替传统的全连接层,以利用图像的空间结构信息。
在接下来的章节中,我们将深入探讨自编码器的数学模型、损失函数以及优化算法的选择,以确保能够构建出高效准确的自编码器模型。
# 2. 自编码器算法详解
## 2.1 自编码器的数学模型
### 2.1.1 输入层、隐藏层和输出层的数学表示
在自编码器的数学模型中,输入层、隐藏层和输出层都是通过权重矩阵和偏置向量来表示的。以一个简单的一层隐藏层的自编码器为例,其网络结构可以用以下数学公式表示:
- 输入层:\(x\) 是输入向量,\(x \in \mathbb{R}^n\),其中 \(n\) 是输入维度。
- 隐藏层:\(h\) 是隐藏层的激活值向量,\(h \in \mathbb{R}^m\),其中 \(m\) 是隐藏层维度。隐藏层的激活值计算公式为 \(h = f(Wx + b)\),其中 \(W\) 是输入到隐藏层的权重矩阵,\(b\) 是隐藏层的偏置向量,\(f\) 是激活函数。
- 输出层:\(\hat{x}\) 是输出向量,\(\hat{x} \in \mathbb{R}^n\)。输出层的激活值计算公式为 \(\hat{x} = g(Vh + c)\),其中 \(V\) 是隐藏层到输出层的权重矩阵,\(c\) 是输出层的偏置向量,\(g\) 是激活函数。
在编码过程中,输入数据 \(x\) 经过隐藏层转换为隐表示 \(h\)。在解码过程中,隐表示 \(h\) 经过输出层重建为输出 \(\hat{x}\)。目标是使输出 \(\hat{x}\) 尽可能接近原始输入 \(x\)。
### 2.1.2 权重和偏置的初始化方法
权重和偏置的初始化是神经网络训练中的重要步骤,合理的初始化方法可以影响到模型的收敛速度和最终性能。以下是一些常用的初始化方法:
- 随机初始化(Random Initialization):权重以很小的随机数初始化,例如使用均匀分布 \(U(-\epsilon, \epsilon)\) 或正态分布 \(N(0, \epsilon)\)。这种方法适用于所有层。
- 用0初始化(Zero Initialization):偏置通常初始化为0,权重也可以初始化为0,但会导致所有神经元输出相同的值,因此在实际中较少使用。
- He初始化和Xavier初始化:这两种方法都是根据前一层的节点数来调整权重的缩放因子。He初始化常用于ReLU激活函数,Xavier初始化常用于tanh和sigmoid激活函数。He初始化的权重缩放因子为 \(\sqrt{2/n_{\text{in}}}\),Xavier初始化的权重缩放因子为 \(\sqrt{1/n_{\text{in}}}\),其中 \(n_{\text{in}}\) 是输入节点数。
在自编码器中,初始化方法的选择会影响到编码器和解码器的效率和准确性。合理选择初始化方法可以提高模型的训练速度和降低过拟合风险。
```python
import numpy as np
def initialize_parameters(n_x, n_h, n_y):
# n_x, n_h, n_y 是输入、隐藏和输出层的节点数
np.random.seed(1)
W1 = np.random.randn(n_h, n_x) * np.sqrt(2. / n_x)
b1 = np.zeros((n_h, 1))
W2 = np.random.randn(n_y, n_h) * np.sqrt(2. / n_h)
b2 = np.zeros((n_y, 1))
parameters = {
"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2
}
return parameters
parameters = initialize_parameters(n_x=12288, n_h=100, n_y=12288)
```
在上面的Python代码中,我们使用了He初始化方法,即权重通过缩放的随机值初始化,而偏置初始化为0。这种初始化方法对深度自编码器特别有效。
## 2.2 自编码器的变体
### 2.2.1 稀疏自编码器
稀疏自编码器是在传统自编码器基础上增加一个稀疏约束,使得隐藏层中的大部分神经元的激活值接近于零。这种稀疏性促使模型学习到更加有区分度的特征表示,特别适合于数据降维和特征提取。
稀疏性可以通过一个稀疏惩罚项来实现,常见的稀疏惩罚项有L1正则化项和Kullback-Leibler (KL) 散度项。稀疏自编码器的目标函数通常表示为:
\[ L(x, \hat{x}) = L_{\text{reconstruction}}(x, \hat{x}) + \beta \cdot L_{\text{sparse}}(h) \]
其中,\(L_{\text{reconstruction}}\) 是重建损失项,如均方误差 (MSE) 或交叉熵损失;\(L_{\text{sparse}}\) 是稀疏惩罚项;\(\beta\) 是平衡两者之间权重的超参数。
### 2.2.2 去噪自编码器
去噪自编码器(Denoising Autoencoder, DAE)是一种特殊的自编码器,它在训练过程中向输入数据中加入噪声,然后尝试重建原始无噪声的输入。这种结构迫使网络学习到更鲁棒的特征表示,因为它不能依赖于噪声,而是必须发现输入数据的内在结构。
去噪自编码器的一个关键点是如何在输入中添加噪声。通常有以下几种方法:
- 高斯噪声:向输入数据中添加符合高斯分布的噪声。
- 随机掩码:随机将输入数据的一部分设置为零,让网络学会忽略这些丢失的信息。
- 布尔噪声:随机将输入数据的元素翻转,例如,将0变为1,或1变为0。
去噪自编码器通过这种方式,可以防止模型过拟合,同时提高模型在面对真实世界数据时的泛化能力。
```python
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_squared_error
import numpy as np
def add_gaussian_noise(X, noise_level):
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
noise = np.random.normal(0, noise_level, X_scaled.shape)
X_noisy = X_scaled + noise
return scaler.inverse_transform(X_noisy), X_scaled
# 假设原始数据集为X,噪声水平设置为0.1
X_noisy, X = add_gaussian_noise(X, noise_level=0.1)
```
在上面的Python代码中,我们创建了一个添加高斯噪声的函数,并应用在输入数据集 `X` 上。然后,我们可以使用去噪自编码器的结构去训练模型,让模型学会从噪声数据中恢复出原始数据。
### 2.2.3 卷积自编码器
卷积自编码器是一种特殊的自编码器,它使用卷积层来构建编码器和解码器网络。由于卷积层可以有效提取局部特征并具有参数共享的特点,卷积自编码器在图像处理领域表现出色。
卷积自编码器的编码器部分通常使用卷积层来压缩数据,而解码器部分使用转置卷积层(也称为反卷积层)来恢复图像到原始尺寸。卷积层通过滑动窗口的方式提取图像中的特征,而转置卷积层则可以生成图像的细节信息。
卷积自编码器对于图像去噪、特征提取、数据生成等任务非常有效。此外,由于卷积层的特性,卷积自编码器可以处理比输入更小的输出尺寸,这对于降维应用特别有用。
```python
from keras.layers import Input, Conv2D, UpSampling2D
from keras.models import Model
def build_cnn_autoencoder(input_shape):
input_img = Input(shape=input_shape)
# 编码器
encoded = Conv2D(32, (3, 3), activation='relu', padding='same')(input_img)
encoded = Conv2D(16, (3, 3), activation='relu', padding='same')(encoded)
encoded = MaxPooling2D((2, 2), padding='same')(encoded)
# 解码器
decoded = Conv2D(16, (3, 3), activation='relu', padding='same')(encoded)
decoded = UpSampling2D((2, 2))(decoded)
decoded = Conv2D(input_shape[2], (3, 3)
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏汇集了深度学习算法优化方面的实用技巧和指南,旨在帮助开发者提升算法性能和效率。内容涵盖算法选择、硬件加速、模型压缩、过拟合防范、超参数优化、框架对比、分布式训练、注意力机制、循环神经网络和强化学习等关键领域。通过深入浅出的讲解和实战案例,专栏旨在为开发者提供全面且实用的知识,助力他们打造更强大、更稳定的深度学习解决方案。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
NC65数据库索引优化实战:提升查询效率的关键5步骤

# 摘要
随着数据库技术的快速发展,NC65数据库索引优化已成为提高数据库查询性能和效率的关键环节。本文首先概述了NC65数据库索引的基础知识,包括索引的作用、数据结构以及不同类型的索引和选择标准。随后,文章深入探讨了索引优化的理论基础,着重分析性能瓶颈并提出优化目标与策略。在实践层面,本文分享了诊断和优化数据库查询性能的方法,阐述了创建与调整索引的具体策略和维护的最佳实践。此外,通过对成功案例的分析,本
用户体验升级:GeNIe模型汉化界面深度优化秘籍

# 摘要
用户体验在基于GeNIe模型的系统设计中扮演着至关重要的角色,尤其在模型界面的汉化过程中,需要特别关注本地化原则和文化差异的适应。本文详细探讨了GeNIe模型界面汉化的流程,包括理解模型架构、汉化理论指导、实施步骤以及实践中的技巧和性能优化。深入分析了汉化过程中遇到的文本扩展和特殊字符问题,并提出了相应的解决方案。同时,本研究结合最新的技术创新,探讨了用户体验研究与界面设计美学原则在深度优化策略
Android Library模块AAR依赖管理:5个步骤确保项目稳定运行
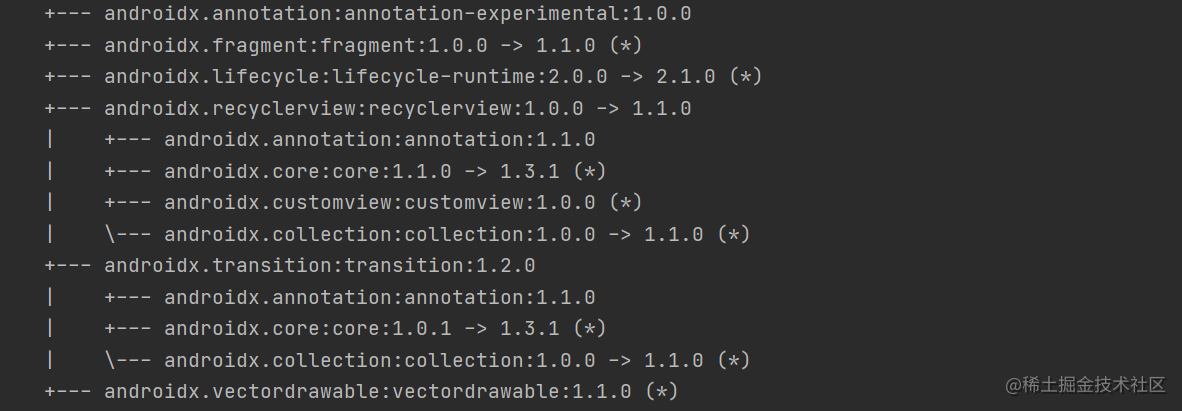
# 摘要
本文旨在全面探讨Android Library模块中AAR依赖管理的策略和实践。通过介绍AAR依赖的基础理论,阐述了AAR文件结构、区别于JAR的特点以及在项目中的具体影响。进一步地,文章详细介绍了如何设计有效的依赖管理策略,解决依赖
【用友NC65安装全流程揭秘】:打造无误的企业级系统搭建方案

# 摘要
本文旨在提供用友NC65系统的全面介绍,包括系统概览、安装前的准备工作、详细的安装步骤、高级配置与优化,以及维护与故障排除方法。首先概述了NC65系统的主要特点和架构,接着详述了安装前硬件与软件环境的准备,包括服务器规格和操作系统兼容性要求。本文详细指导了安装过程,包括介质检查、向导操作流程和后续配置验证。针对系统高级
BAPI在SAP中的极致应用:自定义字段传递的8大策略

# 摘要
BAPI(Business Application Programming Interface)是SAP系统中的关键组件,用于集成和扩展SAP应用程序。本文全面探讨了BAPI在SAP中的角色、功能以及基础知识,着重分析了BAPI的技术特性和与远程函数调用(RFC)的集成方式。此外,文章深入阐述了
【数据传输高效化】:FIBOCOM L610模块传输效率提升的6个AT指令

# 摘要
FIBOCOM L610模块作为一款先进的无线通信设备,其AT指令集对于提升数据传输效率和网络管理具有至关重要的作用。本文首先介绍了FIBOCOM L610模块的基础知识及AT指令集的基本概念和功能,然后深入分析了关键AT指令在提高传输速率、网络连接管理、数
PacDrive入门秘籍:一步步带你精通操作界面(新手必备指南)
# 摘要
本文旨在详细介绍PacDrive软件的基础知识、操作界面结构、高效使用技巧、进阶操作与应用以及实践项目。首先,本文对PacDrive的基础功能和用户界面布局进行了全面的介绍,帮助用户快速熟悉软件操作。随后,深入探讨了文件管理、高级搜索、自定义设置等核心功能,以及提升工作效率的技巧,如快速导航、批量操作和安全隐私保护措施。进一步,文章分析了如何将PacDrive与其他工具和服务集成,以及如何应用在个人数据管理和团队协作中。最后,本文提供了常见问题的解决方法和性能优化建议,分享用户经验,并通过案例研究学习成功应用。本文为PacDrive用户提供了实用的指导和深度的操作洞察,以实现软件的最
【I_O端口极致优化】:最大化PIC18F4580端口性能

# 摘要
本文详细介绍了PIC18F4580微控制器端口的功能、配置和性能优化策略。首先概述了PIC18F4580端口的基本结构和工作原理,随后深入探讨了端口配置的理论基础,包括端口寄存器功能和工作模式的详细解析。文章接着阐述了硬件和软件两个层面上的端口性能优
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )