Python编程实战:使用itertools模块优化数据处理流程
发布时间: 2024-10-08 21:39:52 阅读量: 32 订阅数: 22 

python itertools.pptx
# 1. Python中itertools模块的介绍与应用基础
Python是一种编程语言,它拥有丰富的库,使得开发者能够轻松地实现各种复杂的功能。在这其中,itertools模块作为Python标准库的一部分,提供了用于创建高效迭代器的工具,特别适合于处理大规模数据集或进行复杂的组合数学运算。
itertools模块中包含了一系列函数,它们可以用来组合迭代对象,并进行迭代操作。这些函数的作用是生成无限和有限的迭代器,使用户可以以惰性的方式处理数据,这样可以节省内存,并在数据处理过程中提高程序的执行效率。例如,`chain` 函数能够将多个迭代器连接起来形成一个连续的迭代器,而 `combinations` 或 `permutations` 函数则可以用来生成所有可能的组合或排列。
学习如何正确使用itertools模块,对于任何希望提高数据处理效率和逻辑清晰度的Python开发者来说都是非常重要的。接下来的章节,我们将深入探讨itertools的核心组件、工作原理以及在数据处理中的实战应用。
# 2. 理解itertools模块的工作原理
### 2.1 itertools模块的核心组件
#### 2.1.1 创建迭代器的工具函数
itertools模块提供了一系列函数,用于从输入数据中创建迭代器。这些工具函数是构建更复杂迭代器的基础,它们包括但不限于`count`, `cycle`, `repeat`等。
```python
from itertools import count, cycle, repeat
# 无限序列,从1开始
counter = count(start=1)
print(next(counter)) # 输出: 1
print(next(counter)) # 输出: 2
# 无限循环序列
cyclic = cycle([1, 2, 3])
print(next(cyclic)) # 输出: 1
print(next(cyclic)) # 输出: 2
print(next(cyclic)) # 输出: 3
# 如果不中断,此序列将无限循环下去
# 无限重复序列
rep = repeat(1)
print(next(rep)) # 输出: 1
print(next(rep)) # 输出: 1
# repeat可以指定次数来重复
```
`count`函数提供了一种方法来创建一个从某个数开始的无限迭代器,而`cycle`则是将任何可迭代对象转换成一个无限循环的迭代器。`repeat`可以用来创建一个无限重复某个值的迭代器,或者通过指定次数来重复。
这些函数背后的工作原理是惰性求值,意味着它们在需要时才生成值,而不是一次性生成所有值。
#### 2.1.2 高级迭代器构建块
itertools还提供了一系列用于构建复杂迭代器的构建块,比如`chain`, `compress`, `dropwhile`, `filterfalse`, `islice`等。
```python
from itertools import chain, compress, dropwhile, filterfalse, islice
# 将多个列表合并成一个迭代器
combined = chain([1, 2, 3], [4, 5, 6])
for item in combined:
print(item)
# 根据掩码过滤数据
data = [1, 2, 3, 4, 5, 6]
mask = [True, False, True, False, True, False]
filtered = compress(data, mask)
for item in filtered:
print(item)
# 丢弃前几个元素直到某个条件成立
dropped = dropwhile(lambda x: x < 5, [1, 3, 5, 7, 9])
for item in dropped:
print(item)
# 过滤掉不符合条件的元素
false_filtered = filterfalse(lambda x: x % 2 == 0, [1, 2, 3, 4, 5, 6])
for item in false_filtered:
print(item)
# 切片迭代器,可以指定起始位置和结束位置
sliced = islice([1, 2, 3, 4, 5, 6, 7, 8, 9], 2, 7)
for item in sliced:
print(item)
```
这些构建块提供了高效且灵活的方式来操作数据流,它们让数据处理变得更加简单和直观。
### 2.2 itertools的内部机制
#### 2.2.1 迭代器与生成器的协作
itertools模块利用Python的生成器来实现迭代器。生成器是一种特殊的迭代器,它可以暂停和恢复,而不需要保存整个数据集的副本。因此,它们非常节省内存。理解生成器的工作原理是理解itertools模块的关键。
生成器通过`yield`关键字来产出值,而itertools中的工具和构建块函数使用`yield from`语句来生成值,这允许函数将生成值的任务委托给另一个生成器。
#### 2.2.2 惰性求值和内存效率
惰性求值是itertools工作中的另一个核心概念,意味着只在需要时才计算值。这使得处理大量数据成为可能,因为不需要一次性将数据全部加载到内存中。与传统的列表操作不同,迭代器只在迭代过程中产生下一个元素,从而大大节省内存资源。
例如,`count`函数创建一个无限的迭代器,但实际上并没有创建一个无限的列表。只有当我们迭代时,它才会从指定的开始值逐个产生数字。
itertools模块的这种设计哲学,即利用生成器的惰性求值机制,使得其在处理大规模数据集时具有得天独厚的优势。
# 3. itertools在数据处理中的实战应用
## 3.1 数据排序与分组
### 3.1.1 使用itertools进行排序操作
在处理数据时,排序操作是不可或缺的一个步骤。Python中的`itertools`模块提供了`sorted()`函数,它不仅仅返回一个列表,还可以在内存中创建一个迭代器,这在处理大型数据集时非常有用,因为它可以避免一次性加载大量数据到内存中。`itertools`中的`chain`函数可以帮助我们将多个排序后的序列连接成一个。
在排序操作中,`itertools`的`groupby`函数特别值得提及,它可以让我们按照指定的键值函数对数据进行分组。以下是使用`groupby`进行分组排序的一个例子:
```python
import itertools
# 创建一个示例数据列表
data = [('apple', 2), ('banana', 3), ('apple', 1), ('banana', 4)]
# 使用sorted函数首先按名称排序,然后按数量排序
sorted_data = sorted(data, key=lambda x: (x[0], x[1]))
# 使用groupby进行分组,并打印结果
for key, group in itertools.groupby(sorted_data, key=lambda x: x[0]):
for item in group:
print(key, item[1])
```
这段代码首先对数据按照名称和数量进行排序,然后按照名称对数据进行分组,并打印出每个组的内容。`groupby`返回的是一个迭代器,它提供了一种惰性的方式来处理数据,这在处理大量数据时非常高效。
### 3.1.2 迭代器分组技术
除了使用`groupby`之外,`itertools`还提供了`tee`和`zip_longest`等函数,它们在分组技术中也经常被使用。`tee`函数可以复制一个迭代器,这样可以在不同的地方同时迭代同一个数据序列。`zip_longest`函数用于将多个迭代器组合成一个,当迭代器长度不一致时,它可以用指定的填充值填充较短的迭代器,直到最长的迭代器结束。
以`tee`函数为例,下面是将一个数据序列分组的代码示例:
```python
import itertools
# 假设有一个迭代器it
it = iter([1, 2, 3, 4, 5])
# 使用tee函数复制迭代器
group1, group2 = itertools.tee(it, 2)
# 在group1上进行迭代操作
for i in group1:
print(f"Group 1: {i}")
# 在group2上进行迭代操作
for i in group2:
print(f"Group 2: {i}")
```
这个例子演示了如何使用`tee`复制迭代器,并在两个不同的组上执行迭代操作。需要注意的是,在使用`tee`时必须小心,因为它会产生额外的内存开销,尤其是当复制的迭代器非常大时。
## 3.2 数据聚合与处理
### 3.2.1 利用itertools进行数据聚合
数据聚合是一个将多个数据项组合成单个数据项的过程。在Python中,可以利用`itertools`模块中的`chain`、`combinations`、`combinations_with_replacement`和`permutations`等工具函数来进行数据聚合操作。
举个例子,如果我们想从一组给定的数字中找到所有可能的两两组合,可以这样做:
```python
import itertools
# 创建一个数字列表
numbers = [1, 2, 3, 4]
# 使用combinations获取所有可能的两两组合
combinations = list(***binations(numbers, 2))
# 打印结果
print(combinations)
```
这段代码会输出一个包含所有两两组合的列表,如[(1, 2), (1, 3), (1, 4), (2, 3), (2, 4), (3, 4)]。这种聚合操作在数据分析和处理时非常有用,特别是在处理组合统计问题时。
### 3.2.2 管道处理数据流
在数据处理中,我们经常需要对数据流执行一系列的转换操作。`itertools`模块中的`starmap`、`filterfalse`、`takewhile`、`dropwhile`等函数可以帮助我们构建一个处理数据流的管道。这些函数可以链式地应用在数据上,从而实现复杂的数据处理逻辑。
下面是一个使用`starmap`结合`filterfalse`来处理数据流的示例:
```python
import itertools
# 定义一个处理函数
def mult_and_filter(a, b):
return a * b if a > 2 else a + b
# 创建一个数据流
data = itertools.starmap(mult_and_filter, [(1, 2), (3, 4), (5, 6), (0, 1)])
# 使用filterfalse移除不符合条件的数据
filtered_data = itertools.filterfalse(lambda x: x < 10, data)
# 迭代并打印结果
for item in filtered_data:
print(item)
```
这段代码首先定义了一个乘法和加法的混合函数`mult_and_filter`,然后创建了一个数据流,其中包含对每个元组应用此函数的结果。接着使用`filterfalse`来过滤掉所有结果小于10的数据项。通过这种方式,我们可以灵活地构建一个处理数据流的管道,依次对数据执行多个操作。
以上就是`itertools`在数据处理中的实战应用,包括排序分组和聚合管道处理等高级技巧。在下一节中,我们将探讨`itertools`与其他模块的整合使用,进一步提升数据处理的效率和灵活性。
# 4. itertools与其他模块的整合使用
## 4.1 结合collections模块提高效率
itertools模块虽然功能强大,但在处理数据时有时需要与其他模块相结合以提高效率。collections模块中的Counter和defaultdict对于处理复杂数据非常有效,而deque则可以用来优化数据结构,尤其是在需要频繁地在数据结构两端添加或删除元素的场景。
### 4.1.1 使用Counter和defaultdict处理复杂数据
Counter是collections模块中的一个子类,它可以快速帮助我们计算可哈希对象的频率。defaultdict则是一个字典子类,它为字典提供了默认值,这样我们就不需要在使用字典之前检查键是否存在。
#### 利用Counter进行数据频率统计
考虑以下代码块,它演示了如何使用itertools和Counter来统计文本中各个单词的出现频率:
```python
import itertools
from collections import Counter
# 假设有一个文本字符串
text = 'itertools combines the advantages of lists and generators ' \
'to efficiently loop through sequential data'
# 分割字符串为单词列表
words = text.split()
# 使用itertools的chain.from_iterable来扁平化单词列表
words = itertools.chain.from_iterable(words)
# 使用Counter统计每个单词出现的次数
word_counts = Counter(words)
print(word_counts)
```
在执行上述代码后,我们可以得到一个字典,其中包含文本中每个单词及其出现的次数。例如:
```plaintext
Counter({'itertools': 1, 'the': 2, 'of': 2, 'and': 1, 'to': 1, ...})
```
#### 利用defaultdict处理缺失键
defaultdict允许我们为字典提供一个默认的工厂函数,当访问一个不存在的键时,它会自动为该键生成一个默认值。例如,处理缺失数据时,我们可以为缺失的键提供一个默认的计数器,代码如下:
```python
from collections import defaultdict
# 创建一个defaultdict,指定工厂函数为int,为缺失的键提供默认值0
data = [('apple', 3), ('banana', 2), ('apple', 1), ('orange', 2)]
# 使用defaultdict统计每种水果的数量
fruit_counts = defaultdict(int)
for fruit, count in data:
fruit_counts[fruit] += count
print(dict(fruit_counts))
```
结果会是每个水果及其对应的总数量:
```plaintext
{'apple': 4, 'banana': 2, 'orange': 2}
```
### 4.1.2 利用deque优化数据结构
deque(双端队列)是一个双端可添加或删除元素的序列。它支持在两端的O(1)时间复杂度的添加和删除操作,这在性能上优于列表。
#### 利用deque实现队列
下面的代码展示了如何使用deque来实现一个简单的队列,这对于需要先进先出操作的数据结构非常有用。
```python
from collections import deque
# 创建一个空的deque
queue = deque()
# 入队操作
queue.append(1)
queue.append(2)
queue.append(3)
print(queue) # 输出: deque([1, 2, 3])
# 出队操作
queue.popleft()
print(queue) # 输出: deque([2, 3])
```
#### 利用deque实现栈
deque也可以方便地被用作栈,支持后进先出的操作,以下是一个示例代码:
```python
# 继续使用上面创建的deque实例
queue = deque([1, 2, 3])
# 入栈操作
queue.appendleft(0)
print(queue) # 输出: deque([0, 1, 2, 3])
# 出栈操作
queue.pop()
print(queue) # 输出: deque([0, 1, 2])
```
通过利用collections模块中的Counter、defaultdict和deque,可以显著提高数据处理的效率和灵活性。这些工具的整合使用,结合itertools的强大功能,可以解决更复杂的数据处理任务。
# 5. itertools模块的高级应用案例
## 5.1 处理大规模数据集
在处理大规模数据集时,迭代器提供的流式处理能力显得尤为重要。itertools模块在这方面提供了强大的支持,尤其是在内存使用方面进行了优化。
### 5.1.1 利用itertools进行流式数据处理
流式数据处理意味着一次只处理数据流中的一小部分,这样可以避免一次性将整个数据集加载到内存中,这对于有限的内存资源是一个很大的优势。itertools中的`count`, `cycle`, `repeat`等函数可以用来创建无限的迭代器,这对生成流式数据非常有用。
```python
import itertools
# 创建一个无限迭代器,从1开始
counter = itertools.count(1)
next(counter), next(counter), next(counter) # 输出: (1, 2, 3)
# 创建一个重复指定元素的无限迭代器
repeat = itertools.repeat('foo')
next(repeat), next(repeat), next(repeat) # 输出: ('foo', 'foo', 'foo')
# 创建一个循环迭代器
cycle = itertools.cycle('ABCD')
next(cycle), next(cycle), next(cycle) # 输出: ('A', 'B', 'C')
```
### 5.1.2 缓存机制与数据管道优化
缓存机制是处理大规模数据时减少重复计算的关键。在itertools中,`tee`函数可以用来复制迭代器,这对于构建数据处理管道非常有用。但是要注意,复制迭代器会消耗更多内存。
```python
import itertools
numbers = range(10)
# 创建两个独立的迭代器,但它们会共享数据
iterator1, iterator2 = itertools.tee(numbers)
next(iterator1), next(iterator1), next(iterator2) # 输出: (0, 1, 0)
```
## 5.2 实现复杂的算法逻辑
itertools不仅在处理数据流方面表现出色,而且在实现复杂算法逻辑时也是一个很好的工具。它可以帮助我们以迭代器的方式思考问题,这通常会导致更加清晰和高效的代码。
### 5.2.1 itertool在算法设计中的应用
在算法设计中,itertools可以帮助我们以一种高效且模块化的方式来构建算法。例如,组合、排列等概念可以直接利用itertools中的函数实现。
```python
import itertools
# 获取从1到3的列表所有可能的组合
combinations = ***binations([1, 2, 3], 2)
list(combinations) # 输出: [(1, 2), (1, 3), (2, 3)]
# 获取从1到3的列表所有可能的排列
permutations = itertools.permutations([1, 2, 3], 2)
list(permutations) # 输出: [(1, 2), (1, 3), (2, 1), (2, 3), (3, 1), (3, 2)]
```
### 5.2.2 解决实际问题的itertools模式
在解决实际问题时,我们经常需要对数据集进行复杂的处理。itertools可以用来构建数据处理的流程,通过链式调用不同的迭代器来形成一个高效的数据处理管道。
```python
import itertools
# 假设我们有一个数字列表,并需要生成其所有可能的排列,并取其前三个
numbers = range(1, 4)
# 创建排列迭代器,并取前三个排列
first_three_permutations = itertools.islice(itertools.permutations(numbers), 3)
list(first_three_permutations) # 输出: [(1, 2, 3), (1, 3, 2), (2, 1, 3)]
```
在上述例子中,我们首先使用`itertools.permutations`创建了一个排列的迭代器,然后用`itertools.islice`从排列迭代器中取出前三个排列。这种方法在处理复杂数据流时既高效又节省资源。
在下一章节,我们将继续深入探讨如何利用itertools解决更多实际问题,并展示一些高级技巧来进一步优化我们的数据处理流程。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入浅出Java天气预报应用开发:零基础到项目框架搭建全攻略

# 摘要
Java作为一种流行的编程语言,在开发天气预报应用方面显示出强大的功能和灵活性。本文首先介绍了Java天气预报应用开发的基本概念和技术背景,随后深入探讨了Java基础语法和面向对象编程的核心理念,这些为实现天气预报应用提供了坚实的基础。接着,文章转向Java Web技术的应用,包括Servlet与JSP技术基础、前端技术集成和数据库交互技术。在
【GPO高级管理技巧】:提升域控制器策略的灵活性与效率
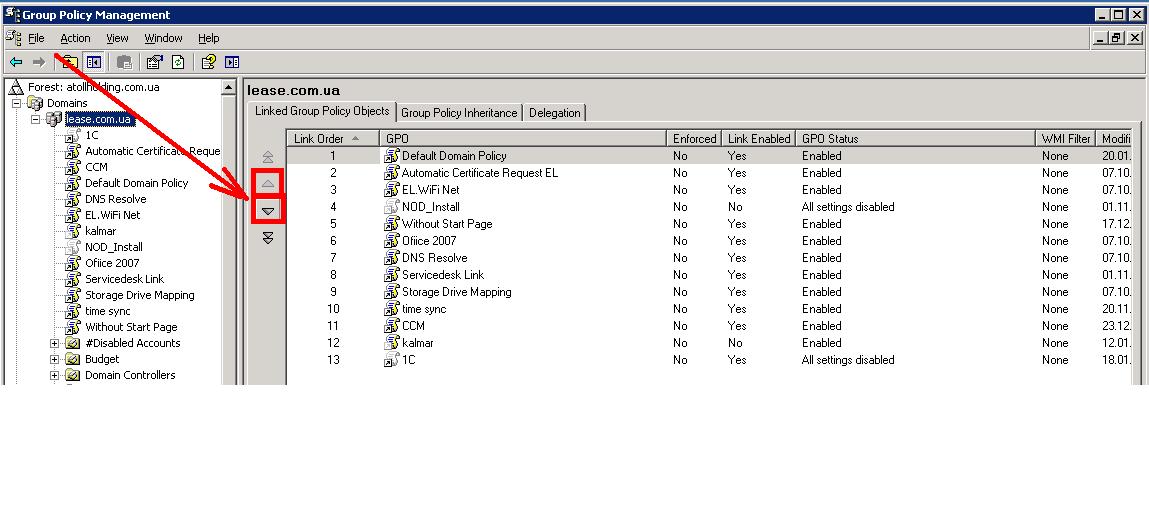
# 摘要
本论文全面介绍了组策略对象(GPO)的基本概念、策略设置、高级管理技巧、案例分析以及安全策略和自动化管理。GPO作为一种在Windows域环境中管理和应用策略的强大工具,广泛应用于用户配置、计算机配置、安全策略细化与管理、软件安装与维护。本文详细讲解了策略对象的链接与继承、WMI过滤器的使用以及GPO的版本控制与回滚策略,同时探讨了跨域策略同步、脚本增强策略灵活性以及故障排除与
高级CMOS电路设计:传输门创新应用的10个案例分析

# 摘要
本文全面介绍了CMOS电路设计基础,特别强调了传输门的结构、特性和在CMOS电路中的工作原理。文章深入探讨了传输门在高速数据传输、模拟开关应用、低功耗设计及特殊功能电路中的创新应用案例,以及设计优化面临的挑战,包括噪声抑制、热效应管理,以及传输门的可靠性分析。此外,本文展望了未来CMOS技术与传输门相结合的趋势,讨论了新型
计算机组成原理:指令集架构的演变与影响

# 摘要
本文综合论述了计算机组成原理及其与指令集架构的紧密关联。首先,介绍了指令集架构的基本概念、设计原则与分类,详细探讨了CISC、RISC架构特点及其在微架构和流水线技术方面的应用。接着,回顾了指令集架构的演变历程,比较了X86到X64的演进、RISC架构(如ARM、MIPS和PowerPC)的发展,以及SIMD指令集(例如AVX和NEON)的应用实例。文章进一步分析了指令集
KEPServerEX秘籍全集:掌握服务器配置与高级设置(最新版2018特性深度解析)
# 摘要
KEPServerEX作为一种广泛使用的工业通信服务器软件,为不同工业设备和应用程序之间的数据交换提供了强大的支持。本文从基础概述入手,详细介绍了KEPServerEX的安装流程和核心特性,包括实时数据采集与同步,以及对通讯协议和设备驱动的支持。接着,文章深入探讨了服务器的基本配置,安全性和性能优化的高级设
TSPL2批量打印与序列化大师课:自动化与效率的完美结合

# 摘要
TSPL2是一种广泛应用于打印和序列化领域的技术。本文从基础入门开始,详细探讨了TSPL2的批量打印技术、序列化技术以及自动化与效率提升技巧。通过分析TSPL2批量打印的原理与优势、打印命令与参数设置、脚本构建与调试等关键环节,本文旨在为读者提供深入理解和应用TSPL2技术的指
【3-8译码器构建秘籍】:零基础打造高效译码器

# 摘要
3-8译码器是一种广泛应用于数字逻辑电路中的电子组件,其功能是从三位二进制输入中解码出八种可能的输出状态。本文首先概述了3-8译码器的基本概念及其工作原理,并
EVCC协议源代码深度解析:Gridwiz代码优化与技巧

# 摘要
本文全面介绍了EVCC协议和Gridwiz代码的基础结构、设计模式、源代码优化技巧、实践应用分析以及进阶开发技巧。首先概述了EVCC协议和Gridwiz代码的基础知识,随后深入探讨了Gridwiz的架构设计、设计模式的应用、代码规范以及性能优化措施。在实践应用部分,文章分析了Gridwiz在不同场景下的应用和功能模块,提供了实际案例和故障诊断的详细讨论。此外,本文还探讨了
JFFS2源代码深度探究:数据结构与算法解析

# 摘要
JFFS2是一种广泛使用的闪存文件系统,设计用于嵌入式设备和固态存储。本文首先概述了JFFS2文件系统的基本概念和特点,然后深入分析其数据结构、关键算法、性能优化技术,并结合实际应用案例进行探讨。文中详细解读了JFFS2的节点类型、物理空间管理以及虚拟文件系统接口,阐述了其压
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )