【Sqoop性能调优秘籍】:详解优化作业性能的不传之秘

1. Sqoop简介及性能影响因素
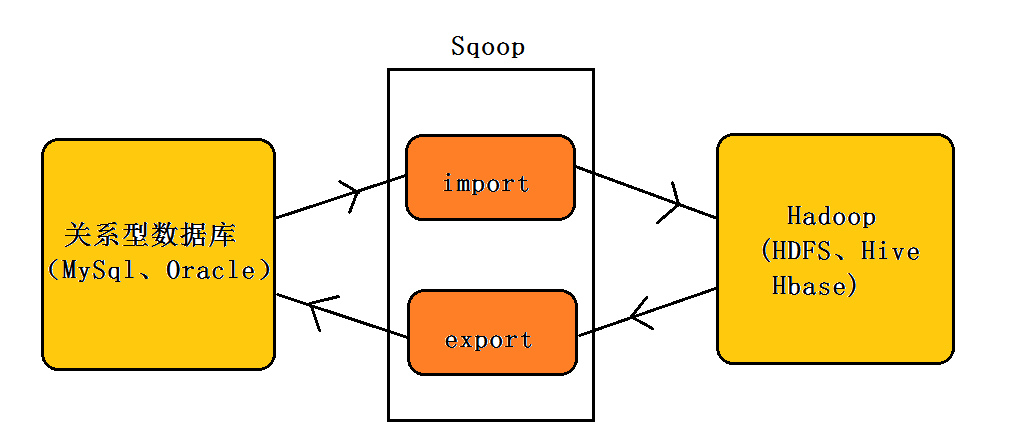
1.1 Sqoop的基本概念
Sqoop是一个开源工具,用于高效地在Hadoop和关系数据库管理系统(RDBMS)之间传输批量数据。通过使用MapReduce,Sqoop能够有效地将数据导入到Hadoop的HDFS中,或者从Hadoop中导出到外部数据库系统中。这种机制非常适合在数据仓库任务、数据分析、以及数据迁移操作中使用。Sqoop的出现,极大地简化了Hadoop与传统数据库之间的数据交互操作,提高了数据处理的效率。
1.2 Sqoop的工作原理
Sqoop工作时,通过JDBC(Java Database Connectivity)连接到关系数据库,并利用MapReduce框架将数据分散到多个节点上进行并行处理。在数据导入时,Sqoop会将数据库表分解成多个块,每个块由一个Map任务处理。相应地,在数据导出操作时,MapReduce任务将数据从HDFS读取,并转换为数据库能够理解的格式,然后通过JDBC批量写入数据库。
1.3 影响Sqoop性能的主要因素
性能是Sqoop使用过程中需要关注的核心问题之一。Sqoop的性能受多种因素的影响,包括硬件配置、网络带宽、磁盘I/O、JDBC连接池的配置、批处理大小以及MapReduce作业的并行度设置等。理解并合理配置这些因素对于提高Sqoop操作的效率至关重要。优化策略包括对数据库的连接进行池化管理、合理配置导入导出的数据块大小、以及调整MapReduce作业的资源使用等。
- 注意:上述内容中的代码块、表格、列表或流程图暂未提供,因为根据当前的内容要求,这些元素不是必须的。在后续章节需要时会按需添加。
2. Sqoop作业设计优化
2.1 数据导入导出策略
2.1.1 数据切分策略
数据切分是优化Sqoop作业性能的重要手段之一。数据切分策略可以根据数据量大小、数据分布特性以及系统资源状况来制定,以实现更高效的批量数据处理。
在数据量较大时,合适的切分策略可以有效降低单次作业的压力,提高数据导入导出的效率。对于数据量特别大的情况,可以考虑使用--split-by选项根据某一列的值进行切分,这种方式能够保证同一个split内部的数据连续性,从而提高导入导出的效率。例如,使用以下命令根据员工ID进行切分:
- sqoop import --connect jdbc:mysql://localhost/employees --username user --password pass --table employees --split-by id --target-dir /sqoop/employees
需要注意的是,切分后的数据分布要尽量均匀,以避免产生作业间执行时间的显著差异。此外,还可以通过增加切分的份数来提高并发度,但这也要考虑到集群的资源能否承载更高的并发作业。
2.1.2 数据类型转换优化
Sqoop在数据导入导出时会涉及到数据类型转换的问题。不恰当的数据类型转换可能会引入额外的计算开销,进而影响性能。例如,将数据库中的VARCHAR类型转换为Hadoop中的Text类型,相较于转换为String,可能并不会带来明显的性能提升,反而会因为Text类型对象创建和销毁开销导致性能下降。
对于数据类型转换的优化,建议遵循以下几点:
- 避免不必要的数据类型转换。例如,如果数据库中的整型数据在Hadoop中仍然可以作为整型处理,则无需转换。
- 尽量使用存储空间较小的数据类型,以减少数据传输和存储的开销。
- 确保数据类型在源和目标系统中的表示是一致的,避免因数据类型解释不一致而导致的数据转换错误。
例如,在导入过程中,如果decimal类型的数据可以接受为double类型,那么可以使用--map-column-java参数进行类型转换:
- sqoop import --connect jdbc:mysql://localhost/finance --username user --password pass --table transactions --fields-terminated-by ',' --map-column-java amount=double
2.2 Sqoop连接管理
2.2.1 连接池的使用
连接池技术可以帮助管理数据库连接,从而提高系统性能。在Sqoop中,使用连接池可以显著提高作业的启动速度,并减少数据库连接的频繁创建和销毁开销。
Sqoop支持多种数据库连接池配置,最常用的配置参数是--num-mappers,它会创建指定数量的数据库连接。此外,还可以利用--connection-paramters选项来设置数据库连接池的参数,比如最大连接数、连接超时时间等。
下面是一个配置连接池的示例,该配置指定了最多可以创建30个数据库连接,并且设置了数据库连接的默认事务隔离级别:
- sqoop import --connect "jdbc:mysql://localhost/employees?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&useSSL=false" --username user --password pass --table employees --num-mappers 30 --connection-paramters "defaultTransactionIsolation=TRANSACTION_READ_COMMITTED;allowMultiQueries=true"
合理配置连接池不仅能提高作业的执行效率,还可以通过减少数据库连接的压力来提高数据库的整体性能。
2.2.2 连接重用与并发控制
Sqoop作业的并发执行可以显著提高数据导入导出的效率,但过高的并发度可能会对源数据库造成过大压力,甚至可能影响源数据库的正常业务运行。因此,需要合理控制并发数,以保证作业的高效执行同时对源数据库的影响最小。
使用--num-mappers参数可以控制并发数。但需要注意的是,这个参数所控制的是 Sqoop 同时开启的 mapper 任务的数量,它直接影响着导入导出作业的并发度。例如,设置--num-mappers 20表示同时开启20个并发任务进行数据处理。
- sqoop export --connect "jdbc:mysql://localhost/employees" --username user --password pass --table employees --num-mappers 20 --export-dir /sqoop/employees
此外,合理配置每个mapper任务处理的数据量也非常关键。可以在数据切分时使用--split-limit参数来限制每个split的大小,这样可以更好地控制并发任务的负载均衡。
为了进一步控制并发,还可以使用--max-parallel-connections来设置并行连接的最大数量,这样可以在多个作业之间共享连接池资源,从而避免同时开启过多数据库连接。
2.3 数据批处理与压缩技术
2.3.1 批量数据处理的调整
在Sqoop作业中,使用批处理可以减少与数据库交互的次数,提高数据传输效率。通过调整批处理的参数,如批处理大小(batch size)、批处理提交间隔(batch flush interval)等,可以进一步优化数据的导入导出性能。
例如,通过--batch参数可以启用批处理模式,该模式下,Sqoop会将多个行插入到数据库作为一个批量操作,这样可以减少SQL执行的次数:
- sqoop import --connect jdbc:mysql://localhost/employees --username user --password pass --table employees --batch --batch-size 100
在这个例子中,每个批处理包含100条记录。批处理大小的调整需要根据实际的数据库性能和网络状况来进行,过大可能会导致内存溢出,过小则无法达到优化的效果。
2.3.2 数据压缩算法的选择和应用
使用数据压缩可以减少网络传输和存储所需的数据量,从而提高数据导入导出的速度。Sqoop支持多种数据压缩算法,常见的有Deflate、Gzip、Bzip2等。
选择合适的压缩算法依赖于多个因素,比如压缩率、压缩速度以及兼容性。例如,虽然Bzip2提供了较高的压缩率,但压缩和解压缩速度较慢;而Gzip在压缩率和速度之间提供了一个平衡。使用压缩时,需要在压缩率和性能之间做出权衡。
下面的例子演示了如何使用Gzip压缩算法进行数据导出:
- sqoop export --connect "jdbc:mysql://localhost/employees" ***press.GzipCodec
在使用压缩技术时,需要保证源和目标系统均支持所选的压缩算法,这样才能顺利进行数据的导入导出工作。
以上所述的策略和实践都是为了提高Sqoop作业的设计效率和执行效率。正确地使用这些策略可以显著提升数据处理的速度,降低系统资源的消耗,从而让大数据处理更加高效和稳定。
3. Sqoop与Hadoop集群的协同
3.1 资源管理器YARN与Sqoop的协同

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ISO_IEC 27000-2018标准实施准备:风险评估与策略规划的综合指南
戴尔笔记本BIOS语言设置:多语言界面和文档支持全面了解
【VCS高可用案例篇】:深入剖析VCS高可用案例,提炼核心实施要点
【T-Box能源管理】:智能化节电解决方案详解
Fluentd与日志驱动开发的协同效应:提升开发效率与系统监控的魔法配方
【内存分配调试术】:使用malloc钩子追踪与解决内存问题
【精准测试】:确保分层数据流图准确性的完整测试方法
【Arcmap空间参考系统】:掌握SHP文件坐标转换与地理纠正的完整策略
Cygwin系统监控指南:性能监控与资源管理的7大要点


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )