numpy数组索引与切片技巧
发布时间: 2024-05-03 04:28:39 阅读量: 158 订阅数: 41 
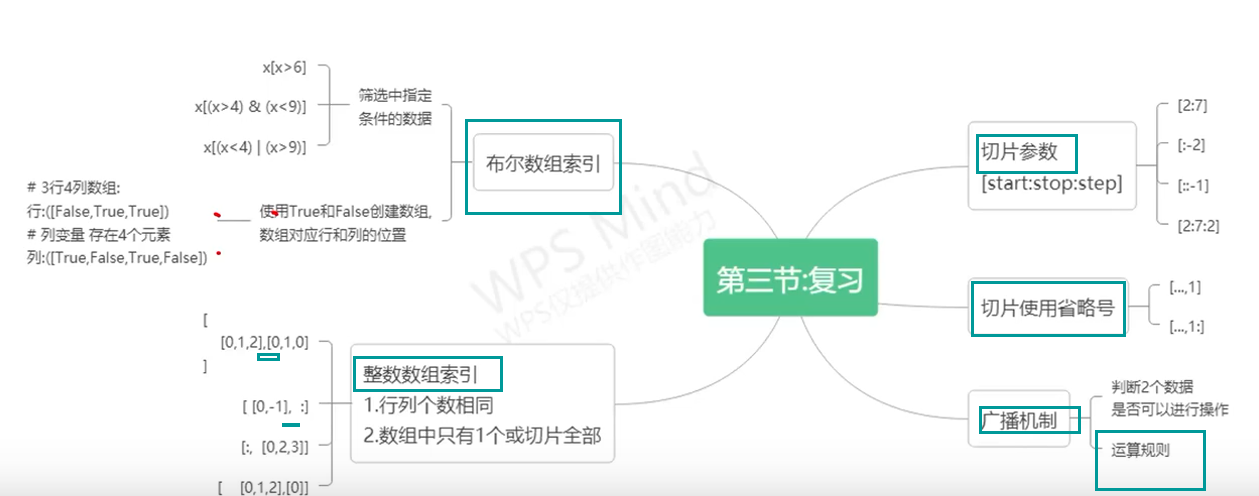
# 2.1 整数索引
整数索引是 NumPy 数组中索引元素的最简单方法。它允许您使用整数来访问数组中的特定元素或子数组。
### 2.1.1 单个元素索引
单个元素索引使用一个整数来访问数组中的单个元素。语法为:
```python
array[index]
```
其中:
* `array` 是要索引的 NumPy 数组。
* `index` 是要访问的元素的索引。
例如:
```python
import numpy as np
arr = np.array([1, 2, 3, 4, 5])
print(arr[2]) # 输出:3
```
# 2. NumPy数组索引技巧
### 2.1 整数索引
整数索引是NumPy数组中最基本的索引方式,它允许使用整数来访问数组中的单个元素或一组元素。
#### 2.1.1 单个元素索引
要访问数组中的单个元素,可以使用方括号索引,其中索引是元素在数组中的位置。例如:
```python
import numpy as np
# 创建一个一维数组
arr = np.array([1, 2, 3, 4, 5])
# 访问数组中的第三个元素
element = arr[2]
# 打印元素
print(element) # 输出:3
```
#### 2.1.2 范围索引
范围索引允许使用冒号(`:`)来访问数组中的一组连续元素。语法为:
```
arr[start:stop:step]
```
其中:
* `start`:起始索引(包含)
* `stop`:结束索引(不包含)
* `step`:步长(可选,默认为1)
例如:
```python
# 访问数组中从索引2到4的元素
elements = arr[2:5]
# 打印元素
print(elements) # 输出:[3 4 5]
```
#### 2.1.3 布尔索引
布尔索引允许使用布尔数组作为索引,仅选择满足特定条件的元素。语法为:
```
arr[condition]
```
其中:
* `condition`:一个与数组形状相同的布尔数组
例如:
```python
# 创建一个布尔数组
condition = arr > 2
# 使用布尔索引访问满足条件的元素
filtered_elements = arr[condition]
# 打印元素
print(filtered_elements) # 输出:[3 4 5]
```
### 2.2 布尔索引
布尔索引是一种高级索引技术,它允许使用布尔数组作为索引,选择满足特定条件的元素。
#### 2.2.1 布尔索引的基本原理
布尔索引的基本原理是,它将布尔数组与原始数组进行逐元素比较,并返回满足条件的元素。例如:
```python
import numpy as np
# 创建一个一维数组
arr = np.array([1, 2, 3, 4, 5])
# 创建一个布尔数组
condition = arr > 2
# 使用布尔索引访问满足条件的元素
filtered_elements = arr[condition]
# 打印元素
print(filtered_elements) # 输出:[3 4 5]
```
#### 2.2.2 高级布尔索引
布尔索引还可以用于更复杂的条件,例如:
* **多个条件:**可以使用逻辑运算符(`&`、`|`、`~`)组合多个条件。
* **嵌套布尔索引:**可以使用嵌套布尔索引来选择满足多个条件的元素。
* **布尔掩码:**可以使用布尔掩码来创建复杂的布尔数组。
例如:
```python
# 创建一个一维数组
arr = np.array([1, 2, 3, 4, 5])
# 创建一个布尔掩码
mask = (arr > 2) & (arr < 4)
# 使用布尔掩码进行布尔索引
filtered_elements = arr[mask]
# 打印元素
print(filtered_elements) # 输出:[3]
```
### 2.3 高级索引
高级索引允许使用更复杂的索引方式,例如多维数组索引和索引组合。
#### 2.3.1 多维数组索引
多维数组索引允许使用多个索引来访问多维数组中的元素。语法为:
```
arr[index1, index2, ..., indexN]
```
其中:
* `index1`, `index2`, ..., `indexN`:每个维度上的索引
例如:
```python
import numpy as np
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 访问二维数组中的元素
element = arr[1, 2]
# 打印元素
print(element) # 输出:6
```
#### 2.3.2 索引组合
索引组合允许将不同类型的索引组合起来,例如整数索引和布尔索引。语法为:
```
arr[index1, index2, ..., indexN, condition]
```
其中:
* `index1`, `index2`, ..., `indexN`:每个维度上的索引
* `condition`:一个与数组形状相同的布尔数组
例如:
```python
import numpy as np
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 创建一个布尔数组
condition = arr > 5
# 使用索引组合访问满足条件的元素
filtered_elements = arr[condition]
# 打印元素
print(filtered_elements) # 输出:[6 7 8 9]
```
# 3. NumPy数组切片技巧
### 3.1 基本切片
#### 3.1.1 单个维度切片
NumPy数组的切片操作与Python列表的切片操作类似。它使用方括号(`[]`)和冒号(`:`)来指定要切片的范围。
对于一维数组,切片操作如下所示:
```python
import numpy as np
# 创建一个一维数组
arr = np.array([1, 2, 3, 4, 5])
# 切片从索引0到索引2(不包括索引2)
arr_sliced = arr[0:2]
print(arr_sliced)
```
输出:
```
[1 2]
```
#### 3.1.2 多维数组切片
对于多维数组,切片操作使用逗号(`,`)分隔每个维度的切片范围。
例如,对于一个二维数组,切片操作如下所示:
```python
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 切片第一行,第二列到第三列
arr_sliced = arr[0, 1:3]
print(arr_sliced)
```
输出:
```
[2 3]
```
### 3.2 高级切片
#### 3.2.1 步长切片
步长切片允许以指定的步长从数组中提取元素。语法如下:
```python
arr[start:stop:step]
```
例如,以下代码以步长2从数组中提取元素:
```python
# 创建一个一维数组
arr = np.array([1, 2, 3, 4, 5])
# 以步长2切片
arr_sliced = arr[::2]
print(arr_sliced)
```
输出:
```
[1 3 5]
```
#### 3.2.2 负向切片
负向切片允许从数组的末尾向开头提取元素。语法如下:
```python
arr[-start:]
```
例如,以下代码从数组的末尾提取最后两个元素:
```python
# 创建一个一维数组
arr = np.array([1, 2, 3, 4, 5])
# 从末尾提取最后两个元素
arr_sliced = arr[-2:]
print(arr_sliced)
```
输出:
```
[4 5]
```
#### 3.2.3 广播切片
广播切片允许将标量或一维数组应用于多维数组,从而对每个元素执行相同的操作。
例如,以下代码将标量5应用于二维数组,从而创建了一个新数组,其中每个元素都增加了5:
```python
# 创建一个二维数组
arr = np.array([[1, 2, 3], [4, 5, 6]])
# 将标量5应用于数组
arr_sliced = arr + 5
print(arr_sliced)
```
输出:
```
[[ 6 7 8]
[ 9 10 11]]
```
# 4. NumPy数组索引和切片应用
### 4.1 数据提取和处理
#### 4.1.1 数据过滤
NumPy索引和切片可以用于高效地过滤数组中的数据。布尔索引是一种强大的工具,它允许我们根据特定条件选择数组中的元素。例如,以下代码从一个NumPy数组中过滤出所有大于5的元素:
```python
import numpy as np
array = np.array([1, 3, 5, 7, 9, 11, 13, 15])
filtered_array = array[array > 5]
print(filtered_array)
# 输出:[ 7 9 11 13 15]
```
#### 4.1.2 数据聚合
索引和切片也可以用于聚合数组中的数据。例如,以下代码使用布尔索引计算数组中大于5的元素的总和:
```python
import numpy as np
array = np.array([1, 3, 5, 7, 9, 11, 13, 15])
sum_filtered = np.sum(array[array > 5])
print(sum_filtered)
# 输出:45
```
#### 4.1.3 数据转换
索引和切片还可以用于转换数组中的数据。例如,以下代码使用索引将数组中的所有奇数元素替换为0:
```python
import numpy as np
array = np.array([1, 3, 5, 7, 9, 11, 13, 15])
array[array % 2 == 1] = 0
print(array)
# 输出:[0 3 0 7 0 11 0 15]
```
### 4.2 图像处理
NumPy索引和切片在图像处理中也得到了广泛的应用。
#### 4.2.1 图像裁剪
索引和切片可以用于从图像中裁剪子区域。例如,以下代码从图像中裁剪出左上角的2x2子区域:
```python
import numpy as np
from PIL import Image
image = Image.open("image.jpg")
array = np.array(image)
cropped_array = array[:2, :2]
Image.fromarray(cropped_array).show()
```
#### 4.2.2 图像增强
索引和切片还可以用于增强图像。例如,以下代码使用索引将图像的亮度增加50:
```python
import numpy as np
from PIL import Image
image = Image.open("image.jpg")
array = np.array(image)
enhanced_array = array + 50
Image.fromarray(enhanced_array).show()
```
#### 4.2.3 图像分析
索引和切片还可以用于分析图像。例如,以下代码使用布尔索引查找图像中所有像素值大于100的区域:
```python
import numpy as np
from PIL import Image
image = Image.open("image.jpg")
array = np.array(image)
mask = array > 100
Image.fromarray(mask).show()
```
# 5. NumPy数组索引和切片性能优化
### 5.1 索引和切片的性能比较
**5.1.1 整数索引与布尔索引**
整数索引和布尔索引是NumPy数组中两种最常见的索引方式。整数索引直接访问数组中的特定元素,而布尔索引返回满足给定条件的元素的子数组。
在性能方面,整数索引通常比布尔索引更快,因为整数索引直接访问数组中的元素,而布尔索引需要创建子数组。下表总结了整数索引和布尔索引的性能比较:
| 操作 | 整数索引 | 布尔索引 |
|---|---|---|
| 单个元素索引 | O(1) | O(n) |
| 范围索引 | O(1) | O(n) |
| 布尔索引 | O(n) | O(n) |
其中,n是数组的长度。
**5.1.2 切片与索引**
切片和索引都是从数组中提取元素的两种方法。切片返回数组的子数组,而索引返回数组中的单个元素或元素子集。
在性能方面,切片通常比索引更快,因为切片创建数组的视图,而索引创建数组的副本。下表总结了切片和索引的性能比较:
| 操作 | 切片 | 索引 |
|---|---|---|
| 单个元素索引 | O(1) | O(1) |
| 范围索引 | O(1) | O(n) |
| 布尔索引 | O(n) | O(n) |
其中,n是数组的长度。
### 5.2 优化索引和切片操作
为了优化索引和切片操作,可以采取以下措施:
**5.2.1 避免不必要的复制**
当使用索引或切片时,NumPy会创建数组的副本。为了避免不必要的复制,可以使用`view`方法来创建数组的视图。视图与原始数组共享相同的底层数据,因此任何对视图的修改都会反映在原始数组中。
```python
import numpy as np
# 创建一个数组
arr = np.arange(10)
# 使用索引创建数组的副本
arr_copy = arr[::2]
# 使用视图创建数组的视图
arr_view = arr[::2].view()
# 修改视图
arr_view[0] = 10
# 修改视图会反映在原始数组中
print(arr) # 输出:[ 0 2 4 6 8 10]
```
**5.2.2 利用广播机制**
广播机制允许将标量或低维数组应用于高维数组。这可以避免创建不必要的临时数组,从而提高性能。
```python
import numpy as np
# 创建一个标量
scalar = 10
# 创建一个一维数组
arr = np.arange(10)
# 使用广播机制将标量应用于一维数组
arr += scalar
# 输出:[10 11 12 13 14 15 16 17 18 19]
```
**5.2.3 使用NumPy的内置函数**
NumPy提供了许多内置函数来优化索引和切片操作。这些函数包括:
* `np.where()`:返回满足给定条件的元素的索引。
* `np.take()`:从数组中提取元素,指定索引。
* `np.put()`:将元素插入数组中,指定索引。
这些函数可以比直接使用索引或切片更有效地执行特定操作。
```python
import numpy as np
# 创建一个数组
arr = np.arange(10)
# 使用np.where()返回满足条件的元素的索引
idx = np.where(arr > 5)
# 使用np.take()从数组中提取元素
arr_filtered = np.take(arr, idx)
# 输出:[6 7 8 9]
```
# 6. NumPy数组索引和切片高级技巧
### 6.1 自定义索引和切片
#### 6.1.1 索引函数
我们可以使用`numpy.where()`函数来创建自定义索引。该函数返回一个布尔掩码,其中`True`元素对应于满足给定条件的元素。我们可以使用此掩码来索引数组。
```python
import numpy as np
# 创建一个数组
arr = np.array([1, 2, 3, 4, 5])
# 创建一个自定义索引
idx = np.where(arr > 2)
# 使用索引获取元素
print(arr[idx])
```
输出:
```
[3 4 5]
```
#### 6.1.2 切片对象
我们可以使用`numpy.s_`函数来创建切片对象。该对象表示一个切片,我们可以将其用于索引数组。
```python
# 创建一个切片对象
slice_obj = np.s_[1:4]
# 使用切片对象获取元素
print(arr[slice_obj])
```
输出:
```
[2 3 4]
```
### 6.2 NumPy数组的Fancy Indexing
#### 6.2.1 Fancy Indexing的基本原理
Fancy Indexing允许我们使用整数数组或布尔数组作为索引。这可以用于选择数组中的特定元素或子数组。
#### 6.2.2 Fancy Indexing的应用
我们可以使用Fancy Indexing来执行以下操作:
* **选择特定元素:**使用整数数组作为索引。
* **选择特定行或列:**使用布尔数组作为索引。
* **选择子数组:**使用整数数组或布尔数组作为索引。
```python
# 创建一个数组
arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# 使用Fancy Indexing选择特定元素
idx = np.array([0, 2])
print(arr[idx, idx])
# 使用Fancy Indexing选择特定行或列
idx = np.array([True, False, True])
print(arr[idx, :])
# 使用Fancy Indexing选择子数组
idx = np.array([[True, False, True], [False, True, False]])
print(arr[idx, idx])
```
输出:
```
[[1 3]
[7 9]]
[[1 2 3]
[7 8 9]]
[[1 3]
[4 6]]
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏以 NumPy 为核心,深入探讨数据分析的各种技巧。它涵盖了从基本数组索引和切片到高级数据重塑和透视等广泛主题。通过深入剖析 NumPy 的运算和广播机制,专栏阐明了高效数据处理的原理。此外,还介绍了 NumPy 的常用数学函数、随机数生成方法和数据统计分析技巧。
专栏还探讨了数据缺失值处理、数据合并和拼接以及自定义函数和向量化实现等高级技术。它深入研究了窗口函数、多维数组操作和矩阵计算,以及线性代数运算和傅里叶变换在数据分析中的应用。
此外,专栏还提供了机器学习常见操作、模型评估指标计算、特征工程和数据预处理技巧等实际应用指导。它还涵盖了数据可视化、深度学习数据准备和数据安全与隐私等主题。通过这些全面的内容,本专栏旨在为数据分析师和数据科学家提供一套强大的工具和技巧,帮助他们从数据中提取有价值的见解。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MATLAB遗传算法与模拟退火策略:如何互补寻找全局最优解

# 1. 遗传算法与模拟退火策略的理论基础
遗传算法(Genetic Algorithms, GA)和模拟退火(Simulated Annealing, SA)是两种启发式搜索算法,它们在解决优化问题上具有强大的能力和独特的适用性。遗传算法通过模拟生物
拷贝构造函数的陷阱:防止错误的浅拷贝
# 1. 拷贝构造函数概念解析
在C++编程中,拷贝构造函数是一种特殊的构造函数,用于创建一个新对象作为现有对象的副本。它以相同类类型的单一引用参数为参数,通常用于函数参数传递和返回值场景。拷贝构造函数的基本定义形式如下:
```cpp
class ClassName {
public:
ClassName(const ClassName& other); // 拷贝构造函数
消息队列在SSM论坛的应用:深度实践与案例分析

# 1. 消息队列技术概述
消息队列技术是现代软件架构中广泛使用的组件,它允许应用程序的不同部分以异步方式通信,从而提高系统的可扩展性和弹性。本章节将对消息队列的基本概念进行介绍,并探讨其核心工作原理。此外,我们会概述消息队列的不同类型和它们的主要特性,以及它们在不同业务场景中的应用。最后,将简要提及消息队列
MATLAB时域分析:动态系统建模与分析,从基础到高级的完全指南
# 1. MATLAB时域分析概述
MATLAB作为一种强大的数值计算与仿真软件,在工程和科学领域得到了广泛的应用。特别是对于时域分析,MATLAB提供的丰富工具和函数库极大地简化了动态系统的建模、分析和优化过程。在开始深入探索MATLAB在时域分析中的应用之前,本章将为读者提供一个基础概述,包括时域分析的定义、重要性以及MATLAB在其中扮演的角色。
时域
【MATLAB在Pixhawk定位系统中的应用】:从GPS数据到精确定位的高级分析

# 1. Pixhawk定位系统概览
Pixhawk作为一款广泛应用于无人机及无人车辆的开源飞控系统,它在提供稳定飞行控制的同时,也支持一系列高精度的定位服务。本章节首先简要介绍Pixhawk的基本架构和功能,然后着重讲解其定位系统的组成,包括GPS模块、惯性测量单元(IMU)、磁力计、以及_barometer_等传感器如何协同工作,实现对飞行器位置的精确测量。
我们还将概述定位技术的发展历程,包括
故障恢复计划:机械运动的最佳实践制定与执行

# 1. 故障恢复计划概述
故障恢复计划是确保企业或组织在面临系统故障、灾难或其他意外事件时能够迅速恢复业务运作的重要组成部分。本章将介绍故障恢复计划的基本概念、目标以及其在现代IT管理中的重要性。我们将讨论如何通过合理的风险评估与管理,选择合适的恢复策略,并形成文档化的流程以达到标准化。
## 1.1 故障恢复计划的目的
故障恢复计划的主要目的是最小化突发事件对业务的
【JavaScript人脸识别的用户体验设计】:界面与交互的优化

# 1. JavaScript人脸识别技术概述
## 1.1 人脸识别技术简介
人脸识别技术是一种通过计算机图像处理和识别技术,让机器能够识别人类面部特征的技术。近年来,随着人工智能技术的发展和硬件计算能力的提升,JavaScript人脸识别技术得到了迅速的发展和应用。
## 1.2 JavaScript在人脸识别中的应用
JavaScript作为一种强
Python算法实现捷径:源代码中的经典算法实践

# 1. Python算法实现捷径概述
在信息技术飞速发展的今天,算法作为编程的核心之一,成为每一位软件开发者的必修课。Python以其简洁明了、可读性强的特点,被广泛应用于算法实现和教学中。本章将介绍如何利用Python的特性和丰富的库,为算法实现铺平道路,提供快速入门的捷径
【深度学习在卫星数据对比中的应用】:HY-2与Jason-2数据处理的未来展望

# 1. 深度学习与卫星数据对比概述
## 深度学习技术的兴起
随着人工智能领域的快速发展,深度学习技术以其强大的特征学习能力,在各个领域中展现出了革命性的应用前景。在卫星数据处理领域,深度学习不仅可以自动
【设计的艺术】:CBAM模块构建,平衡复杂度与性能提升
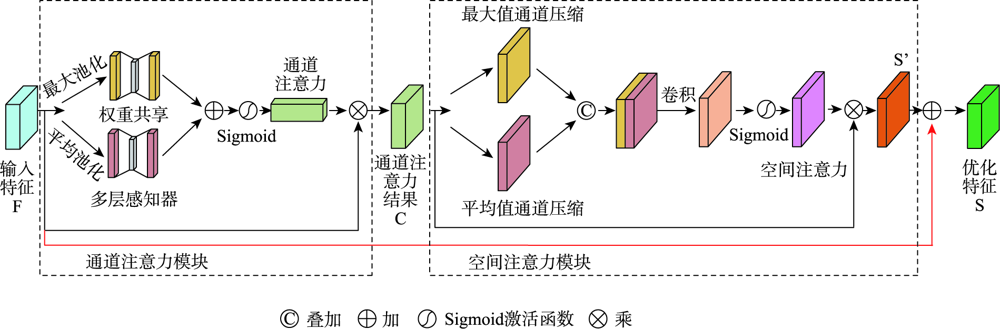
# 1. CBAM模块概述
在深度学习领域,CBAM(Convolutional Block Attention Module)模块已经成为一种重要的神经网络组件,主要用于提升网络对特征的注意力集中能力,进而改善模型的性能。本章将带您初步了解CBAM模块的含义、工作原理以及它在各种应用中的作用。通过对CBAM模块的概述,我们将建立对这一技术的基本认识,为后续章节深入探讨
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )