【数学推导:MSE背后】:概率论视角下的均方误差
发布时间: 2024-11-21 11:40:26 阅读量: 40 订阅数: 23 

image-mse-js:图像均方误差(MSE)
# 1. 均方误差(MSE)简介
在机器学习和统计学中,均方误差(Mean Squared Error, MSE)是衡量模型预测值与真实值之间差异的常用指标。它通过计算预测值与真实值差值的平方,再求平均值得到。这个指标对于优化回归问题有着重要应用,因为它反映了模型的精度,并且可以很容易地利用数学方法进行最小化处理。尽管MSE具有直观和易于实现的优点,但在处理异常值时需要特别注意,因为它的平方项会放大大的预测误差,这可能会导致模型对异常值过于敏感。在后续章节中,我们将深入探讨MSE与概率论的关系,以及如何在实践中有效地应用和优化MSE。
# 2. ```
# 第二章:概率论基础与MSE的联系
概率论是数学的一个分支,它研究随机事件及其发生的概率。在机器学习中,概率论被广泛应用于建模不确定性和进行预测。均方误差(MSE)作为一种常用的损失函数,在其计算过程中也涉及到概率论的多个概念。本章将探讨概率论与MSE之间的联系,从随机变量、概率分布,到条件概率,我们将逐步深入理解这些概念是如何与MSE紧密相连的。
## 2.1 随机变量和概率分布
### 2.1.1 随机变量的定义和分类
随机变量是指其取值具有不确定性的变量,通常用大写字母如 X、Y 表示。根据取值的性质,随机变量分为离散型和连续型两大类。
- **离散型随机变量**是指只能取有限个或可数无限多个值的随机变量,比如抛硬币的次数、掷骰子的点数等。例如,令 X 表示掷一次六面骰子的结果,则 X 是一个离散型随机变量,其可能的取值为 {1, 2, 3, 4, 5, 6}。
- **连续型随机变量**则可以取任意实数值,在一定的区间内取值是连续的,例如测量的温度、降雨量等。连续型随机变量通常通过概率密度函数(Probability Density Function, PDF)来描述。对于连续型随机变量,概率计算公式为 P(X=a) = 0,因为连续型随机变量取特定值的概率为零,但其取值落在某个区间内的概率不为零。
### 2.1.2 概率分布的基本概念
概率分布描述了一个随机变量所有可能取值的概率。对于离散型随机变量,我们使用概率质量函数(Probability Mass Function, PMF)来描述其概率分布;对于连续型随机变量,我们使用概率密度函数(PDF)来描述。此外,累积分布函数(Cumulative Distribution Function, CDF)是描述随机变量取值小于或等于某值的概率,是 PMF 或 PDF 的积分(连续型)或求和(离散型)。
概率分布的性质和形式对MSE有着直接的影响,MSE在计算期望损失时,依赖于随机变量的概率分布。在机器学习模型中,我们通过数据来估计这些分布,进而估计MSE。
## 2.2 常见的概率分布与MSE
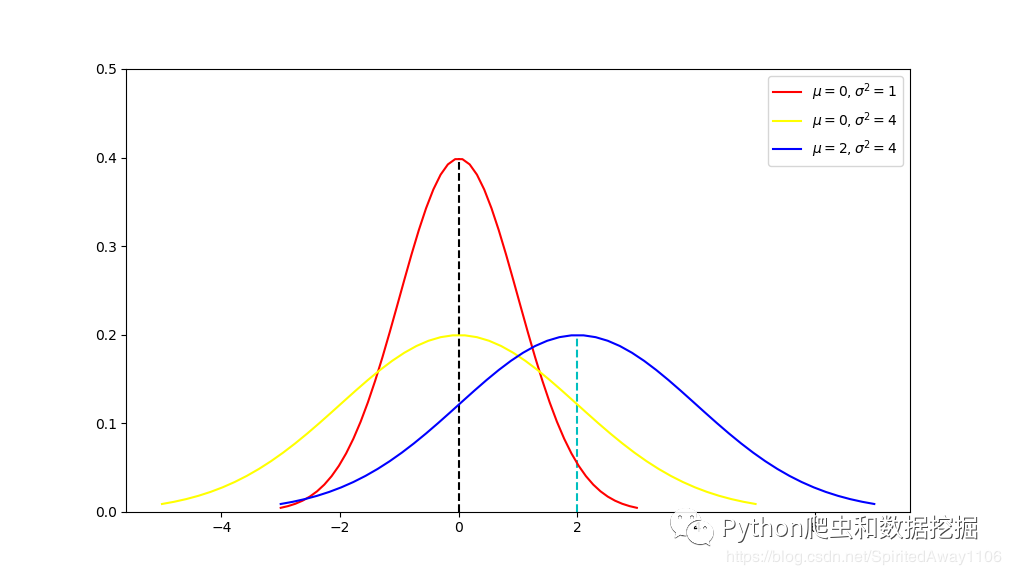
### 2.2.1 高斯分布与MSE的数学推导
高斯分布,也称正态分布,是最常见的连续型概率分布之一。其概率密度函数为:
```math
f(x|\mu,\sigma^2) = \frac{1}{\sqrt{2\pi\sigma^2}}e^{-\frac{(x-\mu)^2}{2\sigma^2}}
```
其中,μ 是均值,σ^2 是方差,分别决定分布的位置和宽度。在机器学习中,特别是在回归分析中,我们假设误差项呈高斯分布,并且基于最小化MSE来估计模型参数。
在高斯分布的假设下,MSE的数学推导表明,最小化MSE等价于最大似然估计(MLE):
```math
MSE(\theta) = E[(Y - f(X;\theta))^2] = \sigma^2 + (\mu - f(X;\theta))^2
```
当 f(X;θ) = μ 时,即模型预测值等于真实均值时,MSE达到最小值 σ^2。因此,最小化MSE与模型的均值拟合程度相关。
### 2.2.2 伯努利分布和二项分布对MSE的影响
**伯努利分布**描述了只有两种可能结果的随机实验,例如抛硬币(正面或反面)。其概率质量函数为:
```math
f(x|p) = p^x(1-p)^{1-x}
```
其中,p 是成功(正面)的概率。
**二项分布**是伯努利分布的推广,描述了在 n 次独立的伯努利实验中成功的次数。其概率质量函数为:
```math
f(k;n,p) = \binom{n}{k}p^k(1-p)^{n-k}
```
伯努利分布和二项分布在二元分类问题中非常常见,例如,在逻辑回归模型中,模型输出被解释为成功(正类)的概率,然后与一个阈值比较来分类。MSE 在这种情况下衡量的是模型预测概率与真实概率之间的差异。由于二项分布可以看作是多个独立的伯努利分布的和,因此其对MSE的影响更加显著。
## 2.3 条件概率与MSE的进一步探讨
### 2.3.1 条件概率的定义及其性质
条件概率是指在某一个事件已经发生的条件下,另一事件发生的概率。如果 A 和 B 是两个事件,那么条件概率 P(A|B) 定义为:
```math
P(A|B) = \frac{P(A \cap B)}{P(B)}
```
只有当 P(B) > 0 时,条件概率才有定义。条件概率满足以下性质:
```math
P(A_1 \cup A_2 | B) = P(A_1 | B) + P(A_2 | B) - P(A_1 \cap A_2 | B)
```
在机器学习中,条件概率是很多算法的基础,比如朴素贝叶斯分类器,以及在贝叶斯优化中MSE的更新也依赖于条件概率。
### 2.3.2 条件概率在MSE中的应用实例
条件概率在MSE计算中的一个应用实例是在线性回归模型中,当我们知道输入 X 的条件下,输出 Y 的分布是高斯分布时,最小化MSE可以得到模型参数的最佳线性无偏估计(BLUE)。这与高斯分布的条件概率密度函数紧密相关。
举一个简单例子,在一个二元回归模型中,我们的目标是最小化均方误差:
```math
MSE = E[(Y - (β_0 + β_1X))^2 | X=x]
```
我们假设 Y | X = x 是均值为 β_0 + β_1x,方差为 σ^2 的正态随机变量。此时,我们可以利用条件概率分布来求解参数 β_0 和 β_1 的估计值。通过求解最小化条件期望的参数值,我们得到参数的BLUE。
在机器学习模型中,尽管我们
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
专栏“均方误差(MSE)”深入探讨了机器学习和统计学中广泛使用的损失函数MSE。它涵盖了MSE的原理、应用、优化技巧以及与其他误差度量(如RMSE、R-Squared)的比较。专栏还探讨了MSE在回归分析、时间序列预测和深度学习中的作用。此外,它还提供了Python中MSE计算的实用技巧,并分析了MSE在分类问题中的局限性。通过一系列标题,专栏提供了对MSE的全面理解,使其成为机器学习从业者和统计学家的一份宝贵资源。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
WZl客户端补丁编辑器全流程剖析:如何从源码到成品
# 摘要
本文主要探讨了WZl客户端补丁编辑器的设计与实现,包括源码分析与理解、用户界面设计、功能模块开发、异常处理与优化以及测试与部署。首先,对编辑器的源码结构和核心技术原理进行了详细解析,阐述了补丁生成算法、压缩和解压缩机制。其次,本文详细介绍了编辑器的设计和实现过程,包括界面布局、功能模块划分以及文件读写和补丁逻辑处理的实现。同时,也对异常处理和性能优化提出了相应的策略和措施。此外,本文还对编辑器的
信息系统项目时间管理:制定与跟踪项目进度的黄金法则

# 摘要
项目时间管理是确保项目按时完成的关键环节,涉及工作分解结构(WBS)的构建、项目进度估算、关键路径法(CPM)的应用等核心技术。本文全面探讨了项目时间管理的概念、重要性、进度计划的制定和跟踪控制策略,并且分析了多项目环境中的时间管理挑战、风险评估以及时间管理的创新方法。通过案例研究,本文总结了时间管理的最佳实践与技巧,旨在为项目管理者提供实用的工具和策略,以提高项目执行效率
R420读写器GPIO脚本自动化:简化复杂操作的终极脚本编写手册

# 摘要
本文主要探讨了R420读写器与GPIO脚本的综合应用。第一章介绍了R420读写器的基本概念和GPIO脚本的应用概述。第二章详细阐述了GPIO脚本的基础知识、自动化原理以及读写器的工作机制和信号控制原理。第三章通过实践操作,说明了如何编写基本和复杂操作的GPIO脚本,并探讨了R420读写器与外部设备的交互。第四章则聚焦于自动化脚本的优化与高级应用开发,包括性能优化策略、远程控制和网络功能集成,以及整合R420
EIA-481-D实战案例:电路板设计中的新标准应用与效率提升

# 摘要
EIA-481-D标准作为电路板设计领域的一项新标准,对传统设计方法提出了挑战,同时也为行业发展带来了新机遇。本文首先概述了EIA-481-D标准的产生背景及其核心要素,揭示了新标准对优化设计流程和跨部门协作的重要性。随后,探讨了该标准在电路板设计中的实际应用,包括准备工作、标准化流程的执行以及后续的测试与评估。文章重点分析了EIA-481-D标准带来
利用Xilinx SDK进行Microblaze程序调试:3小时速成课
# 摘要
本文详细介绍了Microblaze处理器与Xilinx SDK的使用方法,涵盖了环境搭建、程序编写、编译、调试以及实战演练的全过程。首先,概述了Microblaze处理器的特点和Xilinx SDK环境的搭建,包括软件安装、系统要求、项目创建与配置。随后,深入探讨了在Microblaze平台上编写汇编和C语言程序的技巧,以及程序的编译流程和链接脚本的编写。接着,文章重点讲述了使用Xilinx
LIN 2.1与LIN 2.0全面对比:升级的最佳理由

# 摘要
随着车载网络技术的迅速发展,LIN(Local Interconnect Network)技术作为一项重要的低成本车辆通信标准,已经实现了从2.0到2.1的演进。本文旨在全面概述LIN 2.1技术的关键改进,包括性能优化、诊断能力提升及安全性增强等方面。文章深入探讨了LIN 2.1在汽车通信中的实际
【数据同步技术挑战攻略】:工厂管理系统中的应用与应对

# 摘要
数据同步技术是确保信息系统中数据准确性和一致性的重要手段。本文首先概述了数据同步技术及其理论基础,包括数据一致性的定义和同步机制类型。接着,本文探讨了数据同步技术的
【Adobe Illustrator高级技巧曝光】:20年经验设计专家分享的秘密武器库
# 摘要
本文全面探讨了Adobe Illustrator在图形设计领域的应用,涵盖了从基础操作到高效工作流程优化的各个方面。首先介绍了Illustrator的基本功能和高级图形设计技巧,包括路径、锚点、图层、蒙版以及颜色和渐变的处理。其次,强调了工作流程的优化,包括自定义工作区、智能对象与符号管理,以及输出和预览设置的高效化。接着深入讨
TRACE32高级中断调试:快速解决中断响应难题
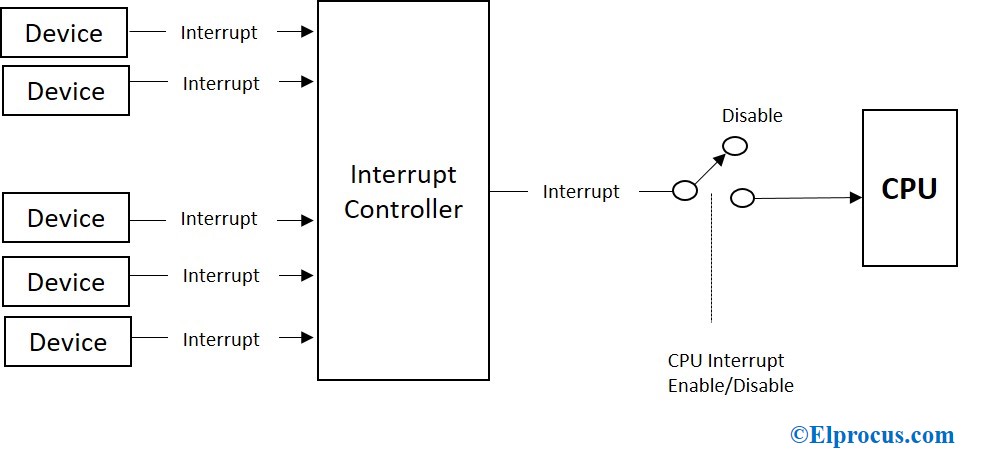
# 摘要
中断机制是现代嵌入式系统设计中的关键组成部分,直接影响到系统的响应时间和性能。本文从中断机制的基础知识出发,介绍了TRACE32工具在高级中断调试中的功能与优势,并探讨了其在实际应用中的实践技巧。通过对中断系统工作原理的理论分析,以及 TRACE32 在测量、分析和优化中断响应时间方面的技术应用,本文旨在提高开发者对中断调试的理解和操作能力。同时,通过分析常见中断问题案例,本文展示了 TRACE32 在实际项目
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )