【图数据结构揭秘】:Python中的图论与算法精要
发布时间: 2024-09-11 17:08:36 阅读量: 247 订阅数: 79 

数据结构与算法:Python实现单链表及其应用

# 1. 图数据结构的理论基础
图是计算机科学和数学中的一种基础数据结构,它由一组顶点(节点)和它们之间的边组成。在本章中,我们将探讨图的一些核心概念和理论基础,为后续章节中的实现和应用打下坚实的基础。
## 1.1 图的定义和分类
图(Graph)可以定义为一个二元组 \(G = (V, E)\),其中 \(V\) 是顶点集合,\(E\) 是边的集合。边可以是有向的(从一个顶点指向另一个顶点),也可以是无向的(连接两个顶点,不区分方向)。基于边的不同特性,图可以被分为有向图、无向图、加权图和非加权图等类别。
## 1.2 图的邻接矩阵表示
在图的表示方法中,邻接矩阵是一种非常直观的方式。它是一个二维数组,用于表示图中所有顶点之间的连接关系。如果顶点 \(i\) 和顶点 \(j\) 之间存在边,则矩阵中的 \(A[i][j]\) 被标记为1(或边的权重值),否则标记为0。邻接矩阵表示法在图的顶点数量较少时较为高效,因为它的查找操作是常数时间复杂度 \(O(1)\)。但当顶点数量增多时,空间复杂度会显著增加,因为需要存储 \(V^2\) 个元素,即使图是稀疏的。
在下一章中,我们将深入探讨图的不同表示方法,并介绍如何使用Python实现这些结构。我们会看到,选择合适的图表示方法对于解决特定问题至关重要,同时也会关注在实际编程实践中如何优化这些方法的性能。
# 2. 图的表示方法与Python实现
在第一章中,我们探索了图数据结构的理论基础,现在让我们深入了解如何在Python中表示和实现图。图的应用无处不在,从社交网络到网络流问题,再到复杂的推荐系统,图结构为这些领域提供了强大的数据表示能力。在本章中,我们将探讨图的不同表示方法,并展示如何在Python中高效实现它们。
## 2.1 图的基本概念和术语
### 2.1.1 图的定义和分类
图是由一系列顶点(也称为节点)和连接这些顶点的边组成的集合。图可以用来表示不同的实体和它们之间的关系,例如网页和超链接、人和他们的友谊关系等。在图论中,我们根据边是否有方向将图分类为有向图和无向图。
- 无向图的边表示顶点之间的无方向关系,例如,两个人是朋友。
- 有向图的边表示顶点之间的有方向关系,例如,网页A有一个链接指向网页B。
有向图中的边可以表示为有序对(u, v),其中u是起始顶点,v是终止顶点。无向图的边可以表示为无序对{u, v},因为在这里方向不重要。
### 2.1.2 图的邻接矩阵表示
邻接矩阵是表示图的一种方法,其中图的每个顶点都由矩阵的行和列表示。如果顶点u和顶点v之间有边,那么邻接矩阵中的相应条目M[u][v]就是1,否则为0。对于无向图,邻接矩阵是对称的,因为M[u][v] = M[v][u]。
邻接矩阵在空间复杂度上有优势,特别是对于稠密图,但在稀疏图中可能会造成空间浪费。邻接矩阵也便于检查顶点之间的连通性,但添加和删除顶点和边的操作效率较低。
下面是一个简单的Python代码示例,展示了如何创建无向图的邻接矩阵表示:
```python
# 定义无向图的邻接矩阵
def create_adjacency_matrix(graph):
# 图的顶点数
vertices = len(graph)
# 创建一个初始填充为0的矩阵
matrix = [[0 for _ in range(vertices)] for _ in range(vertices)]
# 遍历图中的所有边
for edge in graph:
# 无向图的边是无序的,因此需要对顶点进行排序
start, end = sorted(edge)
# 设置邻接矩阵中的对应条目为1
matrix[start][end] = 1
matrix[end][start] = 1
return matrix
# 示例图的边
graph_edges = [(0, 1), (0, 2), (1, 2), (2, 3)]
# 创建邻接矩阵
adj_matrix = create_adjacency_matrix(graph_edges)
print(adj_matrix)
```
执行上述代码将创建一个邻接矩阵,并打印出来,为理解如何表示图提供了直观的步骤。
## 2.2 图的邻接表和边列表
### 2.2.1 邻接表的结构和作用
邻接表是另一种图的表示方法,通常在稀疏图中使用时更为高效。邻接表是一个列表,其中每个顶点都有自己的列表,列表中包含与该顶点直接相连的所有顶点。
邻接表比邻接矩阵更节省空间,因为它只表示实际存在的边。这种表示法对于添加和删除边和顶点的操作来说也是高效的,但检查两个顶点是否连通则需要遍历相关顶点的列表。
在Python中,我们通常使用字典来实现邻接表,其中键是顶点,值是与该顶点相连的其他顶点的列表。以下是一个简单的实现示例:
```python
# 定义图的邻接表表示
def create_adjacency_list(graph_edges):
# 创建一个字典表示邻接表
adjacency_list = {i: [] for i in range(len(graph_edges))}
# 遍历所有边并更新邻接表
for start, end in graph_edges:
adjacency_list[start].append(end)
adjacency_list[end].append(start) # 对于无向图需要添加这条边
return adjacency_list
# 示例图的边
graph_edges = [(0, 1), (0, 2), (1, 2), (2, 3)]
# 创建邻接表
adj_list = create_adjacency_list(graph_edges)
print(adj_list)
```
这段代码演示了如何使用字典在Python中创建邻接表,并打印出结果。
### 2.2.2 边列表的优势和应用场景
边列表是图的另一种表示方法,它简单地列出所有边。边列表通常用作读取图数据的中间格式,或者当需要频繁添加和删除边时。
边列表特别适合表示有向图,因为它可以清晰地显示每个边的方向。在邻接矩阵中,有向图也是对称的,因此需要额外的逻辑来表示边的方向。
边列表可以高效地存储为两列数据,一列是起始顶点,另一列是终止顶点。这种方式有利于快速查看哪些边与特定顶点相连。
以下是一个使用Python列表表示边列表的简单示例:
```python
# 定义图的边列表表示
def create_edge_list(graph_edges):
return graph_edges
# 示例图的边
graph_edges = [(0, 1), (0, 2), (1, 2), (2, 3)]
# 创建边列表
edge_list = create_edge_list(graph_edges)
print(edge_list)
```
这段代码展示了如何创建一个边列表,并打印出来,为理解图的其他表示方式提供了基础。
## 2.3 图的实现技巧
### 2.3.1 在Python中使用字典实现图
在Python中,字典是一种非常灵活的数据结构,可以用来表示图。字典的键可以代表图中的顶点,而值是一个列表,包含与该顶点相连的所有顶点。这种表示方法结合了邻接表和边列表的优势,是一种既简洁又有效的实现方式。
当使用字典来实现图时,每个顶点都对应一个列表,该列表存储了所有与该顶点直接相连的顶点。这种方法对于稀疏图而言尤其节省空间,并且便于添加或删除边。
下面是一个如何使用Python字典来实现图的示例代码:
```python
# 定义图的字典表示
def create_graph_dict(graph_edges):
graph = {}
for edge in graph_edges:
u, v = edge
if u not in graph:
graph[u] = []
if v not in graph:
graph[v] = []
graph[u].append(v)
graph[v].append(u) # 对于无向图需要添加这条边
return graph
# 示例图的边
graph_edges = [(0, 1), (0, 2), (1, 2), (2, 3)]
# 创建图
graph = create_graph_dict(graph_edges)
print(graph)
```
这段代码演示了如何使用字典创建一个图的表示,并输出结果。
### 2.3.2 图的存储效率和性能考量
在图的实现中,存储效率和性能是两个需要特别关注的因素。选择合适的图表示方法取决于特定应用场景和图的特性。例如,对于稠密图,邻接矩阵可能是更好的选择,因为它可以提供O(1)时间复杂度的边访问速度。然而,对于稀疏图,邻接表或边列表会更加高效。
存储效率主要取决于图中边的数量。如果图是稀疏的,使用邻接表或边列表可以节省大量内存。性能方面,不同的操作(如查找所有与特定顶点相连的顶点、检查两个顶点是否相连等)的效率会根据所选择的表示方法而有所不同。
下面是创建一个简单的性能比较函数的代码示例,该函数将比较在无向图中,使用邻接矩阵和邻接表访问与顶点相邻的所有顶点的时间:
```python
import time
# 使用邻接矩阵访问所有相邻顶点
def time_adjacency_matrix(graph, start):
start_time = time.time()
for vertex, edges in graph.items():
if start in edges:
pass # 如果顶点在列表中,则忽略
return time.time() - start_time
# 使用邻接表访问所有相邻顶点
def time_adjacency_list(graph, start):
start_time = time.time()
for vertex in graph[start]:
pass # 如果顶点在列表中,则忽略
return time.time() - start_time
# 创建邻接矩阵和邻接表
graph_matrix = create_adjacency_matrix(graph_edges)
graph_dict = create_graph_dict(graph_edges)
# 测试性能
start_vertex = 0
print(f"Time to access adjacent vertices using adjacency matrix: {time_adjacency_matrix(graph_matrix, start_vertex)} seconds")
print(f"Time to access adjacent vertices using adjacency list: {time_adjacency_list(graph_dict, start_vertex)} seconds")
```
在上述代码中,我们定义了两个函数来测试邻接矩阵和邻接表的性能。我们首先创建了图的两种表示,然后测试了访问与特定顶点相连的所有顶点所需的时间。这有助于我们直观地了解在不同数据结构下图操作的性能。
通过实际的性能测试,我们可以更好地理解不同的图表示方法在实际应用中的优劣,从而为特定需求选择合适的图表示方法。在后续章节中,我们将进一步探讨图的算法实现,包括遍历、最短路径和其他高级主题。
# 3. 图算法的Python实现
## 3.1 图的遍历算法
### 3.1.1 深度优先搜索(DFS)
深度优先搜索是一种用于遍历或搜索树或图的算法。在遍历图的过程中,DFS会尽可能深地沿着分支进行搜索,直到分支的末端,然后回溯继续搜索其他分支。
#### Python实现DFS
下面是一个使用Python实现DFS的示例代码,这里以邻接表的形式表示图:
```python
def dfs(graph, start, visited=None):
if visited is None:
visited = set()
visited.add(start)
print(start)
for next in graph[start] - visited:
dfs(graph, next, visited)
return visited
# 示例图的邻接表表示
graph = {
'A': {'B', 'C'},
'B': {'A', 'D', 'E'},
'C': {'A', 'F'},
'D': {'B'},
'E': {'B', 'F'},
'F': {'C', 'E'}
}
# 执行DFS
dfs(graph, 'A')
```
在上述代码中,`graph`代表图的邻接表,`start`是开始遍历的顶点,`visited`是一个集合,记录已经访问过的顶点,避免重复访问。该函数首先将起始顶点`start`添加到已访问集合中,然后遍历与起始顶点相连的所有顶点,对每一个未访问过的顶点递归调用`dfs`函数。
### 3.1.2 广度优先搜索(BFS)
广度优先搜索是一种用于图的遍历或搜索树的算法。该算法从根节点开始,逐层向外扩展,直到找到目标节点或遍历完所有节点为止。
#### Python实现BFS
下面是一个使用Python实现BFS的示例代码,这里同样使用邻接表来表示图:
```python
from collections import deque
def bfs(graph, start):
visited = set()
queue = deque([start])
while queue:
vertex = queue.popleft()
if vertex not in visited:
visited.add(vertex)
print(vertex)
queue.extend(graph[vertex] - visited)
return visited
# 使用示例图的邻接表表示
bfs(graph, 'A')
```
在上述代码中,`graph`代表图的邻接表,`start`是开始遍历的顶点。`visited`用于记录已经访问过的顶点,`queue`是用双端队列实现的队列,用于存储待访问的顶点。首先将起始顶点`start`加入队列,然后进行循环。在循环中,依次从队列中取出顶点,检查并将其邻接顶点加入队列,这样可以确保按照与起始顶点的距离逐渐增大的顺序进行访问。
## 3.2 最短路径算法
### 3.2.1 迪杰斯特拉(Dijkstra)算法
迪杰斯特拉算法是一种用于在加权图中找到某顶点到其他所有顶点的最短路径的算法。该算法适用于没有负权边的图。
#### Python实现Dijkstra算法
下面是使用Python实现Dijkstra算法的示例代码:
```python
import heapq
def dijkstra(graph, start):
# 初始化距离字典,所有顶点的距离都设置为无穷大
distances = {vertex: float('infinity') for vertex in graph}
# 起始顶点到自己的距离是0
distances[start] = 0
# 优先队列(最小堆)用于存储(距离, 顶点)元组,按距离排序
priority_queue = [(0, start)]
while priority_queue:
current_distance, current_vertex = heapq.heappop(priority_queue)
# 如果该顶点的距离已经被处理过,则跳过
if current_distance > distances[current_vertex]:
continue
# 遍历当前顶点的邻接顶点
for neighbor, weight in graph[current_vertex].items():
distance = current_distance + weight
# 如果找到更短的路径,则更新距离并加入优先队列
if distance < distances[neighbor]:
distances[neighbor] = distance
heapq.heappush(priority_queue, (distance, neighbor))
return distances
# 示例图的邻接表表示,每条边有权重
graph = {
'A': {'B': 1, 'C': 4},
'B': {'A': 1, 'C': 2, 'D': 5},
'C': {'A': 4, 'B': 2, 'D': 1},
'D': {'B': 5, 'C': 1}
}
# 执行Dijkstra算法
print(dijkstra(graph, 'A'))
```
在上述代码中,`graph`代表图的邻接表,并用字典存储边的权重。`start`是算法开始的顶点。`distances`字典用于存储从起始顶点到其他所有顶点的最短路径长度。算法使用优先队列(最小堆)来保持按距离排序的顶点队列。对于每个顶点,算法会检查其所有邻居,并更新到这些邻居的最短路径长度,直到所有顶点都被访问。
### 3.2.2 贝尔曼-福特(Bellman-Ford)算法
贝尔曼-福特算法同样可以用来找到加权图中某个顶点到其他所有顶点的最短路径,且算法能够处理负权边。
#### Python实现Bellman-Ford算法
下面是使用Python实现Bellman-Ford算法的示例代码:
```python
def bellman_ford(graph, start):
# 初始化距离字典,所有顶点的距离都设置为无穷大
distances = {vertex: float('infinity') for vertex in graph}
# 起始顶点到自己的距离是0
distances[start] = 0
# 进行V-1次松弛操作(V为顶点数)
for _ in range(len(graph) - 1):
for vertex in graph:
for neighbor, weight in graph[vertex].items():
if distances[vertex] + weight < distances[neighbor]:
distances[neighbor] = distances[vertex] + weight
return distances
# 示例图的邻接表表示,每条边有权重
graph = {
'A': {'B': 1, 'C': 4},
'B': {'A': 1, 'C': 2, 'D': 5},
'C': {'A': 4, 'B': 2, 'D': 1},
'D': {'B': 5, 'C': 1}
}
# 执行Bellman-Ford算法
print(bellman_ford(graph, 'A'))
```
在上述代码中,`graph`代表图的邻接表,并用字典存储边的权重。`start`是算法开始的顶点。`distances`字典用于存储从起始顶点到其他所有顶点的最短路径长度。Bellman-Ford算法通过V-1次迭代,逐顶点检查并松弛所有边。算法可以检测负权环,如果在一次松弛操作后顶点的最短路径值还能被更新,则表示图中存在负权环。
## 3.3 拓扑排序和关键路径
### 3.3.1 拓扑排序的原理和实现
拓扑排序是针对有向无环图(DAG)的一种排序方式,它会返回一个顶点的线性序列,这个序列满足图中的每一条有向边的箭头方向都从序列的前面指向后面。
#### Python实现拓扑排序
下面是使用Python实现拓扑排序的示例代码:
```python
def topological_sort(graph):
# 计算每个顶点的入度
in_degree = {v: 0 for v in graph}
for v in graph:
for u in graph[v]:
in_degree[u] += 1
# 初始化入度为0的顶点队列
queue = [v for v in in_degree if in_degree[v] == 0]
# 存储拓扑排序的结果
order = []
while queue:
vertex = queue.pop(0)
order.append(vertex)
# 减少相邻顶点的入度,并检查是否入度为0
for neighbor in graph[vertex]:
in_degree[neighbor] -= 1
if in_degree[neighbor] == 0:
queue.append(neighbor)
# 如果结果数量不等于顶点数,说明存在环
if len(order) == len(graph):
return order
else:
return None
# 示例图的邻接表表示
graph = {
'A': ['B', 'C'],
'B': ['D'],
'C': ['D'],
'D': []
}
print(topological_sort(graph))
```
在上述代码中,`graph`代表图的邻接表。首先计算每个顶点的入度并存储在`in_degree`字典中。之后,将所有入度为0的顶点放入队列`queue`中,并通过循环从队列中取出顶点,将其加入拓扑排序的结果`order`中。每次取出一个顶点时,更新其相邻顶点的入度,并将入度减为0的相邻顶点加入队列。如果遍历结束后,排序结果的数量等于顶点总数,说明图是DAG,否则图中存在环,无法进行拓扑排序。
### 3.3.2 关键路径算法的应用
关键路径算法是用来在项目管理中确定项目完成时间的算法。它找出项目中的关键路径,即最长的路径,这条路径决定了项目的最短完成时间。
#### Python实现关键路径算法
下面是使用Python实现关键路径算法的示例代码:
```python
def critical_path(graph):
# 计算每个顶点的最早开始时间和最晚完成时间
earliest = {v: 0 for v in graph}
latest = {v: float('infinity') for v in graph}
# 更新最早开始时间
for v in graph:
for u, weight in graph[v]:
earliest[u] = max(earliest[u], earliest[v] + weight)
# 更新最晚完成时间
graph_reversed = {v: [] for v in graph}
for v in graph:
for u, weight in graph[v]:
graph_reversed[u].append((v, weight))
for v in latest:
for u, weight in graph_reversed[v]:
latest[u] = min(latest[u], latest[v] - weight)
# 找出所有关键路径
critical_paths = []
for v in graph:
if earliest[v] == latest[v]:
critical_paths.append(v)
return earliest, latest, critical_paths
# 示例图的邻接表表示,每条边有权重
graph = {
'A': [('B', 1), ('C', 2)],
'B': [('D', 3)],
'C': [('D', 1), ('E', 4)],
'D': [('F', 2)],
'E': [('F', 3)],
'F': []
}
earliest, latest, critical_paths = critical_path(graph)
print("Earliest start times:", earliest)
print("Latest finish times:", latest)
print("Critical path:", critical_paths)
```
在上述代码中,`graph`代表图的邻接表,并且边的权重代表活动持续时间。首先计算每个顶点的最早开始时间和最晚完成时间。然后反向构建图`graph_reversed`,以便更容易计算最晚完成时间。最后,确定所有顶点的最早和最晚时间,并找出那些最早和最晚时间相同的顶点,这些顶点组成的路径即为关键路径。
## 结构化展示数据
为了更有效地展示以上内容,本章节将使用表格和mermaid格式流程图来强化关键概念和算法的结构化信息。下面是一个表格展示图遍历算法的比较:
| 特性 | DFS | BFS |
|------------|-------------------------|-------------------------|
| 遍历方式 | 深度优先 | 广度优先 |
| 数据结构 | 递归栈(或显式栈) | 队列 |
| 时间复杂度 | O(V+E) | O(V+E) |
| 空间复杂度 | O(V) | O(V) |
| 适用场景 | 内存限制较大的情况 | 目标距离近的情况 |
| 实现复杂度 | 简单 | 简单 |
接下来是一个展示关键路径算法步骤的mermaid流程图:
```mermaid
graph TD
A[开始] --> B[初始化最早和最晚时间]
B --> C[计算最早开始时间]
C --> D[计算最晚完成时间]
D --> E[找出所有关键路径]
E --> F[结束]
```
以上章节内容涵盖了图算法的Python实现,包括图的遍历算法(深度优先搜索和广度优先搜索)和最短路径算法(迪杰斯特拉算法和贝尔曼-福特算法),以及拓扑排序和关键路径算法的原理和应用。通过代码块、表格和mermaid流程图的结合使用,加深了对算法实现和应用场景的理解。
# 4. 图论在实际问题中的应用
图论作为计算机科学的一个分支,在实际问题中有着广泛的应用。我们不仅可以用图论模型来描述社交网络和交通网络等复杂系统,还可以解决最短路径问题、网络流问题等经典问题。本章节深入探讨图论在实际问题中的应用,以及如何通过Python等编程工具实现相关算法。
## 4.1 网络流问题
网络流问题在计算机网络、运输规划、生产调度等多个领域有着重要的应用。其核心是研究如何在网络中运输最大量的数据或物质。例如,在计算机网络中,网络流可以用来模拟数据包的传输过程。
### 4.1.1 最大流问题和最小割问题
在图论中,最大流问题是指在一个网络中从源点到汇点最大可以运输多少流量。最小割问题则是找到这样的边集,移除它们后网络的总流量为零,即从源点到汇点不存在路径。
为了理解最大流问题,考虑一个场景,比如水资源分配。假设有一个水流网络,节点代表水库或者城市,边代表河流或者管道,边上的权重代表流量的容量。我们需要找出最大的流量,使得从源点(水源)到汇点(消耗点)的流量最大。
#### 理解最大流问题
最大流问题可以通过Ford-Fulkerson方法来解决。这个算法利用了“增广路径”的概念来不断寻找从源点到汇点的路径,并增加流量,直到无法找到增广路径为止。Ford-Fulkerson方法的Python实现如下:
```python
def ford_fulkerson(graph, source, sink):
path = find_path(graph, source, sink) # 使用深度优先搜索或广度优先搜索寻找增广路径
while path is not None:
bottleneck = min([graph[u][v]['cap'] for u, v in zip(path, path[1:])])
for u, v in zip(path, path[1:]):
graph[u][v]['cap'] -= bottleneck
graph[v][u]['cap'] += bottleneck
path = find_path(graph, source, sink)
return value_of_flow(graph, sink) # 计算汇点的流入量,即最大流值
def find_path(graph, source, sink):
# 使用DFS或BFS寻找路径的实现
pass
def value_of_flow(graph, sink):
# 计算最大流值的实现
pass
```
### 4.1.2 Ford-Fulkerson方法和Edmonds-Karp算法
Ford-Fulkerson方法的效率取决于增广路径的寻找过程。Edmonds-Karp算法是Ford-Fulkerson方法的一个实现,它使用广度优先搜索来寻找增广路径,从而保证了算法的时间复杂度为O(VE^2)。在最坏的情况下,算法的迭代次数为O(E),其中E是边的数量。
Edmonds-Karp算法是求解最大流问题的经典算法,通过应用广度优先搜索,它有效地减少了不必要的搜索路径,使得算法的运行更加高效。这一点可以通过观察网络流图的拓扑结构来进一步优化。
## 4.2 社交网络分析
社交网络分析涉及对社交网络中的信息流动和结构特征的分析。中心性度量和社团发现是社交网络分析中的两个主要课题。
### 4.2.1 中心性度量和社团发现
中心性度量可以帮助我们找到网络中的关键节点,比如社交网络中的“意见领袖”。常见的中心性度量指标包括度中心性、接近中心性和中介中心性等。
社团发现是识别社交网络中密集连接的节点群体的过程,这些节点群体被称作“社团”或“模块”。在社交网络中,社团的发现可以帮助理解群体内部和群体之间的关系。
Python中有很多库可以用来进行社交网络分析,例如`networkx`,它提供了丰富的接口来计算中心性度量和进行社团发现。下面是一个使用`networkx`来进行社团发现的简单例子:
```python
import networkx as nx
def community_detection(graph):
# 使用Girvan-Newman算法进行社团发现
partition = ***munity.girvan_newman(graph)
communities = next(partition)
return communities
# 构建社交网络图
G = nx.Graph()
# 添加节点和边
# ...
# 进行社团发现
communities = community_detection(G)
print("社团划分结果:", communities)
```
### 4.2.2 Python在社交网络分析中的应用实例
利用Python进行社交网络分析的一个实例是,分析在线教育平台上的学生互动网络。我们可以将学生之间的讨论和交流关系建模为一个网络,然后分析网络中的关键学生节点和学生群体。这有助于教育者了解课程社区的互动模式,并采取措施来增强学习效果。
## 4.3 旅行商问题(TSP)和路径规划
旅行商问题(TSP)是一个经典的组合优化问题,即寻找一条最短的路径,使得旅行商从一个城市出发,经过所有城市一次,并最终回到起始城市。
### 4.3.1 TSP问题的数学模型和解决方法
TSP问题的数学模型是一个带权完全图,顶点代表城市,边的权重代表两个城市之间的距离。目标是找到一条哈密顿回路(经过每个顶点一次的环路),使得总距离最小。
解决TSP问题的方法多种多样,包括精确算法和启发式算法。精确算法如分支限界和动态规划,在小规模问题中可以获得最优解,但在大规模问题中不切实际。启发式算法如遗传算法和蚁群算法可以在可接受的时间内得到较好的近似解。
下面是一个使用Python解决TSP问题的示例代码,采用贪心算法进行求解:
```python
import itertools
import numpy as np
def greedy_tsp(distances):
shortest_path = None
shortest_length = float('inf')
for path in itertools.permutations(range(len(distances))):
current_length = sum([distances[path[i]][path[i + 1]] for i in range(len(path) - 1)])
current_length += distances[path[-1]][path[0]] # return to the start
if current_length < shortest_length:
shortest_length = current_length
shortest_path = path
return shortest_path, shortest_length
# 假设的距离矩阵
distances_matrix = [
[0, 10, 15, 20],
[10, 0, 35, 25],
[15, 35, 0, 30],
[20, 25, 30, 0]
]
# 计算TSP
path, length = greedy_tsp(distances_matrix)
print("路径:", path)
print("总距离:", length)
```
### 4.3.2 Python在路径规划问题中的应用
在实际应用中,路径规划问题除了TSP之外,还可能涉及到多个约束条件,如时间窗口限制、车辆容量限制等。Python在路径规划中的应用可以扩展到智能交通系统、物流配送系统等。
例如,在智能交通系统中,我们可以使用图论和Python来优化公共交通网络,减少乘客的等待时间和换乘次数。这通常涉及到图的优化,以及利用启发式算法找到近似最优解。
在物流配送系统中,路径规划可以帮助公司安排最有效的配送路线,减少燃料消耗和配送时间。结合现实世界的地理信息系统(GIS),路径规划可以进一步优化,提供精确的地理数据支持。
本章节详细介绍了图论在实际问题中的几个关键应用领域,以及如何利用Python实现相关的图算法来解决这些问题。通过本章的讨论,读者应能更好地理解图论在处理复杂问题时的实用性和强大功能。
# 5. 图数据结构的高级主题
## 5.1 加权图和最短路径算法的扩展
### 加权图的定义与特性
加权图是图的一种特殊形式,在其中的每条边都关联了一个权重。权重通常代表了成本、距离、容量等属性。在最短路径问题中,加权图提供了比无权图更复杂的解决方案,因为它需要考虑边的权重。加权图的种类有:有向加权图、无向加权图,以及混合加权图。
### A*搜索算法的优化原理
A*算法是一种启发式搜索算法,用于在图中找到从起始节点到目标节点的最短路径。它结合了最好优先搜索和迪杰斯特拉算法的特点。A*算法的核心是使用启发函数来估计从当前节点到目标节点的最佳路径成本。
以下是A*算法的Python实现:
```python
import heapq
class Node:
def __init__(self, parent=None, position=None):
self.parent = parent
self.position = position
self.g = 0 # Cost from start to current node
self.h = 0 # Heuristic cost from current node to goal
self.f = 0 # Total cost
def __eq__(self, other):
return self.position == other.position
def __lt__(self, other):
return self.f < other.f
def astar(maze, start, end):
# 创建起始和结束节点
start_node = Node(None, tuple(start))
end_node = Node(None, tuple(end))
start_node.g = start_node.h = start_node.f = 0
end_node.g = end_node.h = end_node.f = 0
# 初始化open和closed列表
open_list = []
closed_list = []
# 将起始节点加入open列表
heapq.heappush(open_list, start_node)
# 循环直到找到终点
while len(open_list) > 0:
current_node = heapq.heappop(open_list)
closed_list.append(current_node)
# 如果找到目标,返回路径
if current_node == end_node:
path = []
while current_node is not None:
path.append(current_node.position)
current_node = current_node.parent
return path[::-1] # 返回反转的路径
# 生成子节点
children = []
for new_position in [(0, -1), (0, 1), (-1, 0), (1, 0)]: # Adjacent squares
# 获取节点位置
node_position = (current_node.position[0] + new_position[0], current_node.position[1] + new_position[1])
# 确保在范围内
if node_position[0] > (len(maze) - 1) or node_position[0] < 0 or node_position[1] > (len(maze[len(maze)-1]) -1) or node_position[1] < 0:
continue
# 确保可行性
if maze[node_position[0]][node_position[1]] != 0:
continue
# 创建新节点
new_node = Node(current_node, node_position)
# 添加到子节点列表
children.append(new_node)
# 循环子节点
for child in children:
# 子节点在closed列表中
if child in closed_list:
continue
# 创建子节点的f, g, 和 h 值
child.g = current_node.g + 1
child.h = ((child.position[0] - end_node.position[0]) ** 2) + ((child.position[1] - end_node.position[1]) ** 2)
child.f = child.g + child.h
# 子节点已在open列表中
for open_node in open_list:
if child == open_node and child.g > open_node.g:
continue
# 添加子节点到open列表
heapq.heappush(open_list, child)
return None
# 示例使用
maze = [
[0, 0, 0, 0, 1],
[1, 1, 0, 1, 0],
[0, 0, 0, 0, 0],
[0, 1, 1, 1, 0],
[0, 0, 0, 0, 0]
]
start = [0, 0] # 起点位置
end = [4, 4] # 终点位置
path = astar(maze, start, end)
print(path)
```
A*算法的优化原理在于对启发式函数的使用,通常这个函数表示为h(x),它估计从当前节点到达目标节点的最佳路径。一个好的启发式函数可以减少搜索范围,提高算法效率。
### 弗洛伊德(Floyd-Warshall)算法详解
弗洛伊德算法是一种计算图中所有节点对之间最短路径的动态规划算法。它可以在一个图的所有顶点对之间找到最短路径,包括带负权边的图(但不能包含负权环)。
以下是Floyd-Warshall算法的Python实现:
```python
def floyd_warshall(graph):
distance = {}
for node in graph:
for child in graph[node]:
distance[(node, child)] = graph[node][child]
# 添加所有节点到节点列表
nodes = list(graph.keys())
# 对所有节点进行松弛
for k in nodes:
for i in nodes:
for j in nodes:
if (i, k) in distance and (k, j) in distance:
if (i, j) not in distance or distance[(i, k)] + distance[(k, j)] < distance[(i, j)]:
distance[(i, j)] = distance[(i, k)] + distance[(k, j)]
return distance
# 示例使用
graph = {
'A': {'B': 3, 'C': 1},
'B': {'A': 3, 'C': 2, 'D': 4},
'C': {'A': 1, 'B': 2, 'D': 5},
'D': {'B': 4, 'C': 5}
}
distances = floyd_warshall(graph)
print(distances)
```
Floyd-Warshall算法的工作原理是通过迭代地改进节点对之间的最短路径估计。对于每一对节点(i, j),算法考虑所有中间节点k,并尝试通过k来优化i和j之间的最短路径。如果通过k的路径更短,则更新i和j之间的最短路径。这个过程对所有节点对迭代进行,直到所有的最短路径都得到优化。
# 6. 图论项目的实战演练
## 6.1 实战项目一:网络爬虫中的图结构应用
网络爬虫是互联网上数据收集的一种重要工具。在这种场景下,网页可以被视为图中的节点,而超链接则可以视作连接这些节点的边。因此,图结构在设计爬虫时起到了至关重要的作用。
### 6.1.1 爬虫的图结构设计
当设计一个网络爬虫时,我们需要考虑如何存储和管理网页的URLs以及它们之间的链接关系。图结构为我们提供了一个直观的模型来表示这种关系。
在Python中,我们可以使用字典来构建一个图结构。下面是一个简单的例子:
```python
# 使用字典构建图结构
graph = {}
# 假设我们有三个网页URL
urls = ['***', '***', '***']
# 将每个URL添加到图中作为节点
for url in urls:
graph[url] = []
# 添加边,表示网页间的链接关系
graph['***'].append('***')
graph['***'].append('***')
graph['***'].append('***')
```
### 6.1.2 网页链接关系的图算法分析
在构建了图结构之后,我们可以运用图算法来分析网页之间的链接关系。例如,我们可以使用DFS算法来发现所有可访问的页面。
```python
def dfs(graph, start, visited=None):
if visited is None:
visited = set()
visited.add(start)
print(start) # 输出当前访问的URL
for node in graph[start]:
if node not in visited:
dfs(graph, node, visited)
return visited
# 从特定URL开始深度优先遍历
dfs(graph, '***')
```
## 6.2 实战项目二:交通网络的优化
交通网络优化是另一个图论应用的典型例子,它可以帮助减少拥堵、降低旅行时间,并提高整个网络的效率。
### 6.2.1 交通流模型的图结构构建
构建交通网络的图模型时,交叉口可以是节点,而道路则是边。边的权重可以表示道路的长度、通行时间或交通流量。
```python
# 构建交通网络的图结构
traffic_graph = {}
# 假设交通网络包含三个交叉口
intersections = ['IntersectionA', 'IntersectionB', 'IntersectionC']
# 添加节点和边,以及边的权重(时间)
traffic_graph['IntersectionA'] = {'IntersectionB': 10, 'IntersectionC': 15}
traffic_graph['IntersectionB'] = {'IntersectionA': 10, 'IntersectionC': 20}
traffic_graph['IntersectionC'] = {'IntersectionA': 15, 'IntersectionB': 20}
```
### 6.2.2 最短路径算法在交通规划中的应用
最短路径算法可以用来为驾驶员规划旅行路线。例如,Dijkstra算法就可以用来计算两个交叉口之间的最短时间路径。
```python
# 实现Dijkstra算法以找到最短路径
def dijkstra(graph, start):
distances = {vertex: float('infinity') for vertex in graph}
distances[start] = 0
priority_queue = [(0, start)]
while priority_queue:
current_distance, current_vertex = heapq.heappop(priority_queue)
if current_distance > distances[current_vertex]:
continue
for neighbor, weight in graph[current_vertex].items():
distance = current_distance + weight
if distance < distances[neighbor]:
distances[neighbor] = distance
heapq.heappush(priority_queue, (distance, neighbor))
return distances
# 计算从IntersectionA到其他交叉口的最短时间
dijkstra(traffic_graph, 'IntersectionA')
```
## 6.3 实战项目三:推荐系统中的图分析
推荐系统是电子商务、社交媒体和其他在线服务中不可或缺的一部分。基于图的协同过滤是构建推荐系统的一种有效方式。
### 6.3.1 基于图的协同过滤方法
协同过滤通过分析用户之间的相似性来进行推荐。在这种方法中,用户和项目可以形成一个二部图,通过计算图中的距离来找出相似用户或项目。
```python
# 使用图结构构建用户与项目的关系
user_item_graph = {}
# 假设我们有用户、项目和它们之间的交互关系
users = ['User1', 'User2', 'User3']
items = ['ItemA', 'ItemB', 'ItemC', 'ItemD']
# 添加边,表示用户与项目之间的交互
user_item_graph['User1'] = {'ItemA', 'ItemB', 'ItemC'}
user_item_graph['User2'] = {'ItemA', 'ItemB', 'ItemD'}
user_item_graph['User3'] = {'ItemB', 'ItemC', 'ItemD'}
# 计算用户或项目之间的相似度
# 这里只是一个示例,实际中可以通过共现频率或其他方式计算相似度
```
### 6.3.2 推荐系统中图结构的优化策略
为了提高推荐系统的性能和准确性,我们可以优化图结构,比如引入权重来表示用户与项目之间交互的强度,或者使用复杂的图算法来提取更深层次的用户偏好。
```python
# 通过权重改进用户与项目之间的关系
weighted_user_item_graph = {}
# 假设权重表示用户对项目的评分或评分的倒数
weighted_user_item_graph['User1'] = {'ItemA': 5, 'ItemB': 3, 'ItemC': 2}
weighted_user_item_graph['User2'] = {'ItemA': 4, 'ItemB': 2, 'ItemD': 5}
weighted_user_item_graph['User3'] = {'ItemB': 3, 'ItemC': 1, 'ItemD': 4}
# 使用图算法提取用户偏好或寻找相似用户
# 例如,我们可以使用基于图的聚类算法
```
通过图结构的优化,我们可以构建更加智能和个性化的推荐系统,为用户推荐他们可能感兴趣的新项目。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 图数据结构模块专栏!本专栏深入探讨了图论在 Python 中的应用,涵盖了从基础概念到高级算法的方方面面。
专栏文章涵盖了广泛的主题,包括:
* 图数据结构的深入解析
* 高效图算法的实战指南
* 优化图数据结构性能的技巧
* 网络流算法的实现
* 最短路径问题的多种解决方案
* 拓扑排序的细节和优化
* 深度优先搜索和广度优先搜索的应用和分析
* 最小生成树算法的应用
* PageRank 算法的实现
* 图社区检测和同构性检测
* 路径查找策略和图匹配算法
* 旅行商问题的近似解
* 项目调度图算法
本专栏旨在为 Python 开发人员提供全面的资源,帮助他们理解和应用图论概念,以解决现实世界中的问题。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
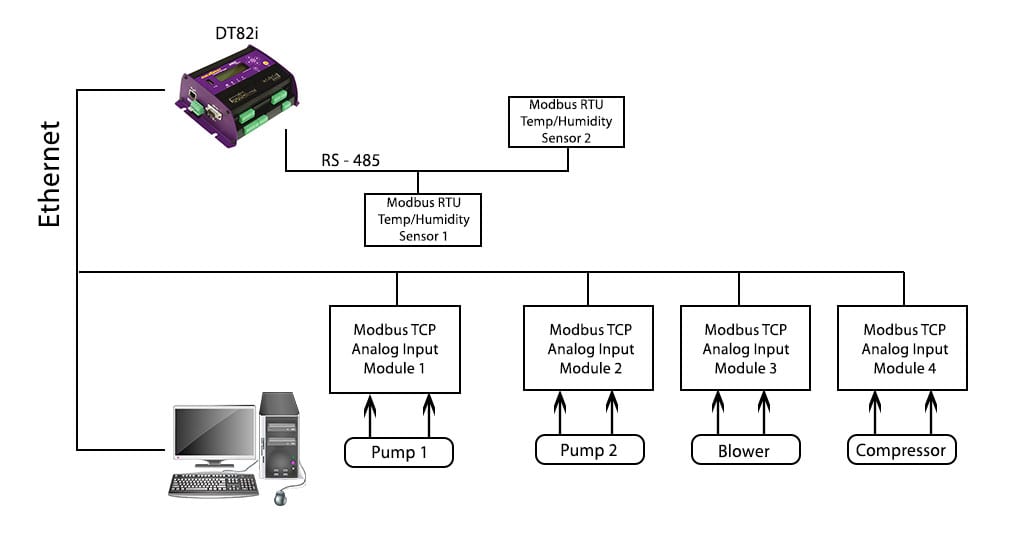
NModbus性能优化:提升Modbus通信效率的5大技巧
# 摘要
本文综述了NModbus性能优化的各个方面,包括理解Modbus通信协议的历史、发展和工作模式,以及NModbus基础应用与性能瓶颈的分析。文中探讨了性能瓶颈常见原因,如网络延迟、数据处理效率和并发连接管理,并提出了多种优化技巧,如缓存策略、批处理技术和代码层面的性能改进。文章还通过工业自动化系统的案例分析了优化实施过程和结果,包括性能对比和稳定性改进。最后,本文总结了优化经验,展望了NModbus性能优化技术的发展方向。
【Java开发者效率利器】:Eclipse插件安装与配置秘籍

# 摘要
Eclipse插件开发是扩展IDE功能的重要途径,本文对Eclipse插件开发进行了全面概述。首先介绍了插件的基本类型、架构及安装过程,随后详述了提升Java开发效率的实用插件,并探讨了高级配置技巧,如界面自定义、性能优化和安全配置。第五章讲述了开发环境搭建、最佳实践和市场推广策略。最后,文章通过案例研究,分析了成功插件的关键因素,并展望了未来发展趋势和面临的技
【性能测试:基础到实战】:上机练习题,全面提升测试技能

# 摘要
随着软件系统复杂度的增加,性能测试已成为确保软件质量不可或缺的一环。本文从理论基础出发,深入探讨了性能测试工具的使用、定制和调优,强调了实践中的测试环境构建、脚本编写、执行监控以及结果分析的重要性。文章还重点介绍了性能瓶颈分析、性能优化策略以及自动化测试集成的方法,并展望了
SECS-II调试实战:高效问题定位与日志分析技巧

# 摘要
SECS-II协议作为半导体设备通信的关键技术,其基础与应用环境对提升制造自动化与数据交换效率至关重要。本文详细解析了SECS-II消息的类型、格式及交换过程,包括标准与非标准消息的处理、通信流程、流控制和异常消息的识别。接着,文章探讨了SECS-II调试技巧与工具,从调试准备、实时监控、问题定位到日志分析
Redmine数据库升级深度解析:如何安全、高效完成数据迁移

# 摘要
随着信息技术的发展,项目管理工具如Redmine的需求日益增长,其数据库升级成为确保系统性能和安全的关键环节。本文系统地概述了Redmine数据库升级的全过程,包括升级前的准备工作,如数据库评估、选择、数据备份以及风险评估。详细介绍了安全迁移步骤,包括
YOLO8在实时视频监控中的革命性应用:案例研究与实战分析

# 摘要
YOLO8作为一种先进的实时目标检测模型,在视频监控应用中表现出色。本文概述了YOLO8的发展历程和理论基础,重点分析了其算法原理、性能评估,以及如何在实战中部署和优化。通过探讨YOLO8在实时视频监控中的应用案例,本文揭示了它在不同场景下的性能表现和实际应用,同时提出了系统集成方法和优化策略。文章最后展望了YOLO8的未来发展方向,并讨论了其面临的挑战,包括数据隐私和模型泛化能力等问题。本文旨在为研究人员和工程技术人员提供YOLO8
UL1310中文版深入解析:掌握电源设计的黄金法则

# 摘要
电源设计在确保电气设备稳定性和安全性方面发挥着关键作用,而UL1310标准作为重要的行业准则,对于电源设计的质量和安全性提出了具体要求。本文首先介绍了电源设计的基本概念和重要性,然后深入探讨了UL1310标准的理论基础、主要内容以及在电源设计中的应用。通过案例分析,本文展示了UL1310标准在实际电源设计中的实践应用,以及在设计、生产、测试和认证各阶段所面
Lego异常处理与问题解决:自动化测试中的常见问题攻略

# 摘要
本文围绕Lego异常处理与自动化测试进行深入探讨。首先概述了Lego异常处理与问题解决的基本理论和实践,随后详细介绍了自动化测试的基本概念、工具选择、环境搭建、生命周期管理。第三章深入探讨了异常处理的理论基础、捕获与记录方法以及恢复与预防策略。第四章则聚焦于Lego自动化测试中的问题诊断与解决方案,包括测试脚本错误、数据与配置管理,以及性
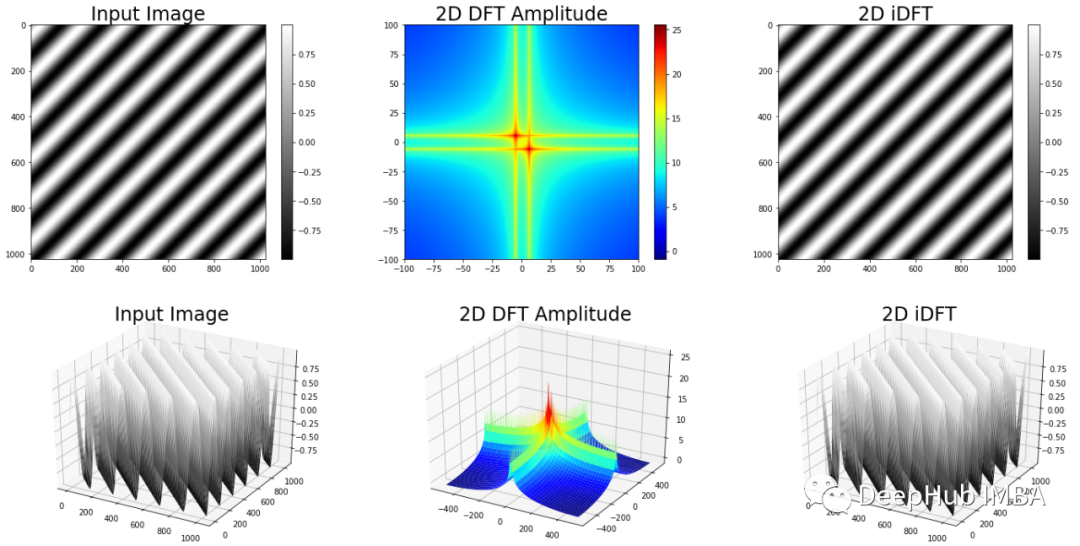
【Simulink频谱分析:立即入门】
# 摘要
本文系统地介绍了Simulink在频谱分析中的应用,涵盖了从基础原理到高级技术的全面知识体系。首先,介绍了Simulink的基本组件、建模环境以及频谱分析器模块的使用。随后,通过多个实践案例,如声音信号、通信信号和RF信号的频谱分析,展示了Simulink在不同领域的实际应用。此外,文章还深入探讨了频谱分析参数的优化,信号处理工具箱的使用,以及实时频谱分析与数据采
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )