Building Efficient Data Models: A Guide to Doris Database Data Modeling Design
发布时间: 2024-09-14 22:28:26 阅读量: 31 订阅数: 35 

data-lineage-doris-master.zip
# 1. Fundamentals of Data Modeling**
Data models are abstract representations of data organization and storage, defining data structures, the relationships between data elements, and rules for data operations. A good data model can enhance the efficiency of data queries and analyses and provide a reliable foundation for business decision-making.
Data modeling should adhere to certain principles, including performance priority, scalability, and ease of maintenance. The data modeling process generally consists of three phases: requirement analysis, data modeling, and data validation. During requirement analysis, the needs and goals of the data model are determined; data modeling creates the structure and relationships of the data model based on these requirements; and data validation ensures the data model meets requirements through testing and analysis.
# 2. Doris Database Data Modeling Design Principles
### 2.1 Overview of Data Modeling Design Principles
Data modeling design principles guide the data modeling process in the Doris database, ensuring that the data model meets the requirements of performance, scalability, and ease of maintenance.
#### 2.1.1 Performance Priority
Performance is the primary principle in data model design. The data model should be designed to maximize query performance while maintaining data consistency and integrity. This includes:
- Choosing appropriate storage formats and compression algorithms
- Using partitioning and indexing to optimize data access
- Avoiding unnecessary redundancy and complex data structures
#### 2.1.2 Scalability
Data models should be scalable to support growing data volumes and user needs. This includes:
- Using partitioning and sharding to horizontally scale data
- Using replication and backups to ensure data redundancy and availability
- Designing scalable data structures to support future expansion
#### 2.1.3 Ease of Maintenance
Data models should be easy to maintain, allowing for updates and expansions as business needs change. This includes:
- Employing clear and consistent data naming conventions
- Adopting modular design for easy modification and expansion of data models
- Providing tools and documentation to support the management and maintenance of data models
### 2.2 Data Modeling Design Process
The data modeling design process is an iterative process involving the following steps:
#### 2.2.1 Requirement Analysis
The first step in data modeling design is analyzing business requirements. This includes determining the queries, reports, and analyses that the data model should support. Requirement analysis should consider the following factors:
- Data sources and data formats
- Data usage scenarios and query patterns
- Performance and scalability requirements
#### 2.2.2 Data Modeling
After requirement analysis, the next step is to construct the data model. The data model should reflect business entities and relationships and meet the principles of performance, scalability, and ease of maintenance. Data modeling techniques include:
- **Entity-Relationship Diagram (ERD):** Used to visualize data entities and their relationships.
- **Star Schema and Snowflake Schema:** Used to organize multidimensional data.
- **Dimensional Modeling:** Used to organize hierarchical data.
#### 2.2.3 Data Validation
Once the data model is completed, it needs to be validated to ensure it meets the requirements. The validation process includes:
- **Syntax Validation:** Checking if the data model conforms to the Doris database's syntax rules.
- **Logical Validation:** Checking if the data model is logically correct and capable of supporting the expected queries and analyses.
- **Performance Validation:** Running query and analysis benchmarks to evaluate the performance of the data model.
# 3. Doris Database Data Model Types
The Doris database supports various types of data models

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
ARM处理器:揭秘模式转换与中断处理优化实战
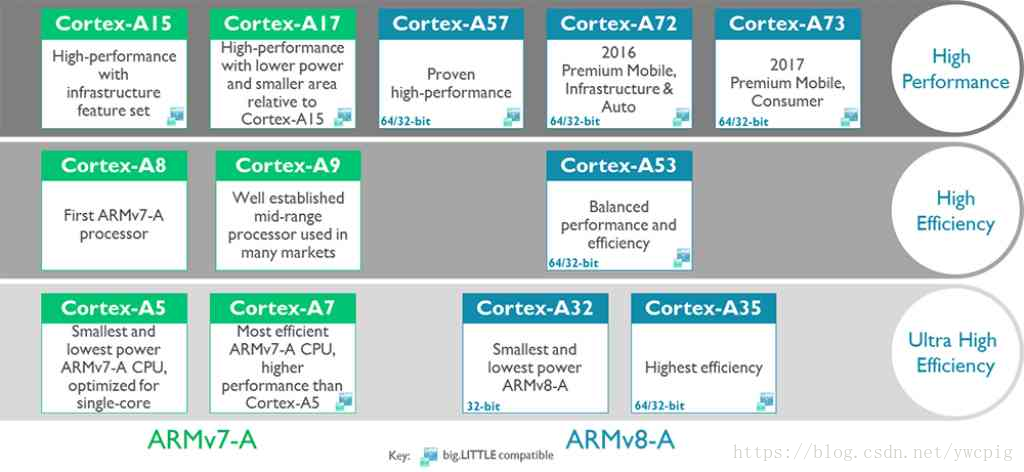
# 摘要
本文详细探讨了ARM处理器模式转换和中断处理机制的基础知识、理论分析以及优化实践。首先介绍ARM处理器的运行模式和中断处理的基本流程,随后分析模式转换的触发机制及其对中断处理的影响。文章还提出了一系列针对模式转换与中断
高可靠性系统的秘密武器:IEC 61709在系统设计中的权威应用

# 摘要
IEC 61709标准作为高可靠性系统设计的重要指导,详细阐述了系统可靠性预测、元器件选择以及系统安全与维护的关键要素。本文从标准概述出发,深入解析其对系统可靠性基础理论的贡献以及在高可靠性概念中的应用。同时,本文讨论了IEC 61709在元器件选择中的指导作用,包括故障模式分析和选型要求。此外,本文还探讨了该标准在系统安全评估和维护策略中的实际应用,并分析了现代系统设计新趋势下
【CEQW2高级用户速成】:掌握性能优化与故障排除的关键技巧
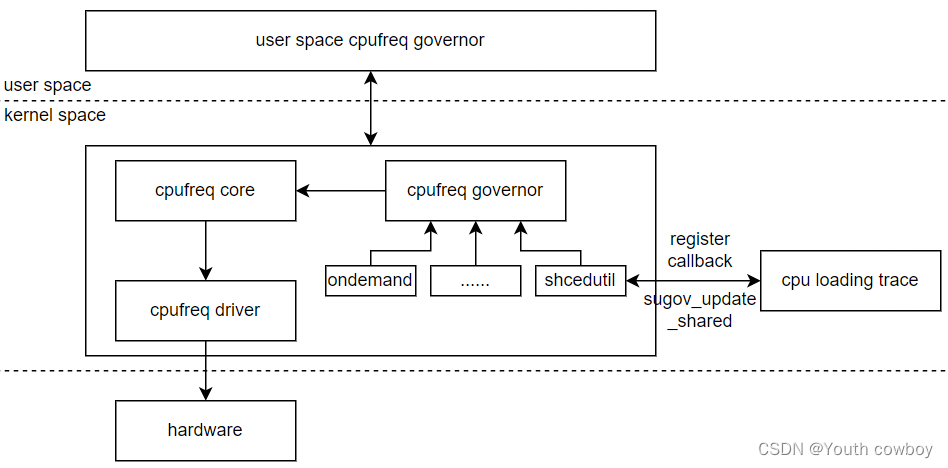
# 摘要
本文旨在全面探讨系统性能优化与故障排除的有效方法与实践。从基础的系统性能分析出发,涉及性能监控指标、数据采集与分析、性能瓶颈诊断等关键方面。进一步,文章提供了硬件升级、软件调优以及网络性能优化的具体策略和实践案例,强调了故障排除的重要性,并介绍了故障排查的步骤、方法和高级技术。最后,强调最佳实践的重要性,包括性能优化计划的制定、故障预防与应急响应机制,以及持续改进与优化的
Zkteco智慧考勤数据ZKTime5.0:5大技巧高效导入导出

# 摘要
Zkteco智慧考勤系统作为企业级时间管理和考勤解决方案,其数据导入导出功能是日常管理中的关键环节。本文旨在提供对ZKTime5.0版本数据导入导出操作的全面解析,涵盖数据结构解析、操作界面指导,以及高效数据导入导出的实践技巧。同时,本文还探讨了高级数据处理功能,包括数据映射转换、脚本自动化以及第三方工具的集成应用。通过案例分析,本文分享了实际应用经验,并对考勤系统
揭秘ABAP事件处理:XD01增强中事件使用与调试的终极攻略

# 摘要
本文全面介绍了ABAP事件处理的相关知识,包括事件的基本概念、类型、声明与触发机制,以及如何进行事件的增强与实现。深入分析了XD01事件的具体应用场景和处理逻辑,并通过实践案例探讨了事件增强的挑战和解决方案。文中还讨论了ABAP事件调试技术,如调试环境的搭建、事件流程的跟踪分析,以及调试过程中的性能优化技巧。最后,本文探讨了高级事件处理技术,包含事件链、事件分发、异常处理和事件日志记录,并着眼
数值分析经典题型详解:哈工大历年真题集锦与策略分析

# 摘要
本论文首先概述了数值分析的基本概念及其在哈工大历年真题中的应用。随后详细探讨了数值误差、插值法、逼近问题、数值积分与微分等核心理论,并结合历年真题提供了解题思路和实践应用。论文还涉及数值分析算法的编程实现、效率优化方法以及算法在工程问题中的实际应用。在前沿发展部分,分析了高性能计算、复杂系统中的数值分析以及人工智能
Java企业级应用安全构建:local_policy.jar与US_export_policy.jar的实战运用

# 摘要
随着企业级Java应用的普及,Java安全架构的安全性问题愈发受到重视。本文系统地介绍了Java安全策略文件的解析、创建、修改、实施以及管理维护。通过深入分析local_policy.jar和US_export_policy.jar的安全策略文件结构和权限配置示例,本文探讨了企业级应用中安全策略的具体实施方法,包括权限
【海康产品定制化之路】:二次开发案例精选

# 摘要
本文综合概述了海康产品定制化的基础理论与实践技巧。首先,对海康产品的架构进行了详细解析,包括硬件平台和软件架构组件。接着,系统地介绍了定制化开发流程,涵盖需求分析、项目规划、开发测试、部署维护等
提高效率:proUSB注册机文件优化技巧与稳定性提升

# 摘要
本文详细介绍了proUSB注册机的功能和优化策略。首先,对proUSB注册机的工作原理进行了阐述,并对其核心算法和注册码生成机制进行了深入分析。接着,从代码、系统和硬件三个层面探讨了提升性能的策略。进一步地,本文分析了提升稳定性所需采取的故障排除、容错机制以及负载均衡措施,并通过实战案例展示了优化实施和效果评估。最后,本文对proUSB注册机的未来发展趋
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )