Building Efficient Data Tables: Table Design and Optimization in Doris Database
发布时间: 2024-09-14 22:38:42 阅读量: 28 订阅数: 36 

Docker for Data Science: Building Scalable and Extensible Data Infrastructure
# 1. Overview of Doris Database
Doris is a distributed OLAP (Online Analytical Processing) database based on the MPP (Massively Parallel Processing) architecture. It is characterized by high performance, high availability, and high scalability, and is widely used in the field of big data analysis.
Doris adopts columnar storage and pre-aggregation technology, capable of efficiently processing massive amounts of data. Its MPP architecture distributes data across multiple nodes and processes queries in parallel, significantly enhancing query performance. Moreover, Doris supports various data types and encoding methods, allowing for flexible storage optimization based on data characteristics.
# 2. Doris Table Design Principles
### 2.1 Fundamentals of Data Modeling
#### 2.1.1 Normalization and Denormalization
**Normalization** is a data modeling method that follows certain rules to reduce data redundancy and anomalies. Normalized database design can improve data integrity and consistency.
**Denormalization** is a data modeling method that violates normalization rules, aimed at improving query performance. Denormalized design can reduce table joins, thereby increasing query speed.
#### 2.1.2 Dimensional Modeling and Fact Tables
**Dimensional modeling** is a data warehouse modeling method that organizes data into dimension tables and fact tables. Dimension tables contain attributes that describe the data, while fact tables contain the metrics.
**Fact tables** are the core tables in dimensional modeling, storing data from business transactions or events. Fact tables are typically very large and contain a significant amount of duplicate data.
### 2.2 Doris Table Structure Design
#### 2.2.1 Table Partitioning and Replication Strategy
**Table partitioning** divides the data in a table horizontally into multiple subsets, known as partitions. Partitioning can improve query performance as it allows Doris to scan only the necessary data.
**Replication strategy** specifies the number of replicas for each partition. Replicas can enhance data availability and fault tolerance.
#### 2.2.2 Data Type Selection and Encoding Methods
**Data types** specify the type of data in a column, such as integers, floats, or strings. Selecting the appropriate data type can save storage space and improve query performance.
**Encoding methods** specify how data is stored on disk. Different encoding methods have different trade-offs between space and performance.
**Code block:**
```
CREATE TABLE t1 (
id INT NOT NULL,
name VARCHAR(255) NOT NULL,
age INT NOT NULL,
PRIMARY KEY (id)
)
PARTITION BY RANGE (id) (
PARTITION p0 VALUES LESS THAN (10),
PARTITION p1 VALUES LESS THAN (20),
PARTITION p2 VALUES LESS THAN (30)
)
DISTRIBUTED BY HASH (id) BUCKETS 3;
```
**Logical Analysis:**
This code block creates a table named `t1`, which includes:
* An `id` column that is an integer primary key.
* A `name` column that is a string with a maximum length of 255 characters.
* An `age` column that is an integer.
The table is partitioned into three partitions:
* Partition `p0` contains rows where `id` is less than 10.
* Partition `p1` contains rows where `id` is less than 20.
* Partition `p2` contains rows where `id` is less than 30.
The table is also distributed across 3 storage buckets using a hash partitioning strategy.
# 3.1 Index Optimization
#### 3.1.1 Index Types and Selection
Doris supports various index types, including:
- **Bitmap Index:** Suitable for columns with a low cardinality, capable of quickly filtering rows that meet the conditions.
- **BloomFilter Index:** Suitable for columns with a high cardinality, capable of quickly determining if rows that meet the conditions exist.
- **Composite Index:** Combines multiple columns into a single index, improving the efficiency of multi-column queries.
- **ZoneMap Index:** Suitable for columns with uneven data distribution, capable of quickly locating the zones where rows that meet the conditions are located.
The choice of index depends on the cardinality, data distribution, and query patterns of the columns.
#### 3.1.2 Index Design Principles
When designing indexes, the following principles should

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
MTBF计算基础:从零开始,一文读懂MIL-HDBK-217F标准(附实战教程)

# 摘要
本文详细探讨了MTBF(平均无故障时间)与可靠性的基本概念,并深入解读了MIL-HDBK-217F标准,该标准广泛应用于评估电子和机械设备的可靠性。通过对MIL-HDBK-217F标准的历史背景、应用、基本假设和计算模型的解析,本文阐述了MTBF的计算方法,并提供了一个实战计算教程。此外,文章还探讨了如何通过优化策略和常见技术来提高MTBF,并通过案例研究展示这些策略的实际应用。最后,本文介绍了MTBF的测试方法、验证流
【通达信公式实战演练】:掌握高级调试技巧,最佳实践大公开

# 摘要
通达信公式是为金融市场分析设计的一套强大的工具语言,广泛应用于交易策略构建、市场指标分析以及图表分析等领域。本文首先介绍了通达信公式的概念和基础,然后深入解析了其语言的基本语法、数据类型和结构、高级特性。随后,文章通过实战应用,探讨了市场指标分析、交易策略构建与回测、高级图表应用等关键主题。进一步,本文对通达信公式的调试、性能优化以及安全性问题进行了详细讨论,并探讨
ODB++兼容性挑战:掌握不同软件间无缝转换的秘诀

# 摘要
本文综合探讨了ODB++格式在印刷电路板(PCB)设计中的应用及其与其他格式的兼容性问题。首先概述了ODB++格式及其在PCB设计中的作用,接着分析了ODB++与其他PCB设计格式如Gerber和Excellon之间的差异及兼容性挑战的原因。文章还介绍了ODB++兼容性转换的理论基础,包括数据转换模型和关键技术,并提供了实践应用中的转换工具介绍、设置与配置,以及转换过程中问题的解决方案。通过案例研究
激光对刀仪精度优化秘籍:波龙型号的精准校准
# 摘要
激光对刀仪作为制造业中重要的精密测量工具,对于提高机械加工的精确度和效率具有重要作用。本文首先介绍了激光对刀仪的技术背景及其在制造业中的应用,进而探讨了波龙型号激光对刀仪的理论基础,包括其工作原理、关键技术和精度参数。接着,本文详细阐述了精度校准的实践步骤、关键操作以及校准后的精度验证方法。进一步地,本文探讨了精度提升的技巧、设备维护策略,并通过案例分析提炼了成功经验。最后,本文展望了激光对刀仪精度优化的未来发展方向,包括人工智能、机器学习以及高精度传感器技术的应用前景,并讨论了行业发展趋势与挑战。通过对这些方面的深入分析,本文旨在为激光对刀仪的研究和应用提供有价值的参考。
# 关
【Fluent UDF高级应用技巧】:解锁复杂流体模拟的新世界

# 摘要
Fluent UDF(User-Defined Functions)为ANSYS Fluent提供了一种强大的自定义功能,使得用户能够通过编写代码来扩展Fluent内置的功能。本文首先介绍了Fluent UDF的基础知识,包括函数类型、声明、宏定义及使用,以及数据存储和管理。接着,文中探讨了流体模拟中的高级特性应用,如边界条件处理、复杂流体模型自定义和多相流、反应流模拟的U
ISO 16845-1标准物理信号传输机制:专家技术细节与实现指南

# 摘要
ISO 16845-1标准是针对物理信号传输的一套详细指南,涵盖了从理论基础到实际应用的全面内容。本文首先概述了ISO 16845-1标准,接着深入探讨了物理信号的定义、特性、传输原理以及标准中所规定的传输机制
确保Verilog除法器正确性的关键:验证与测试的最佳实践
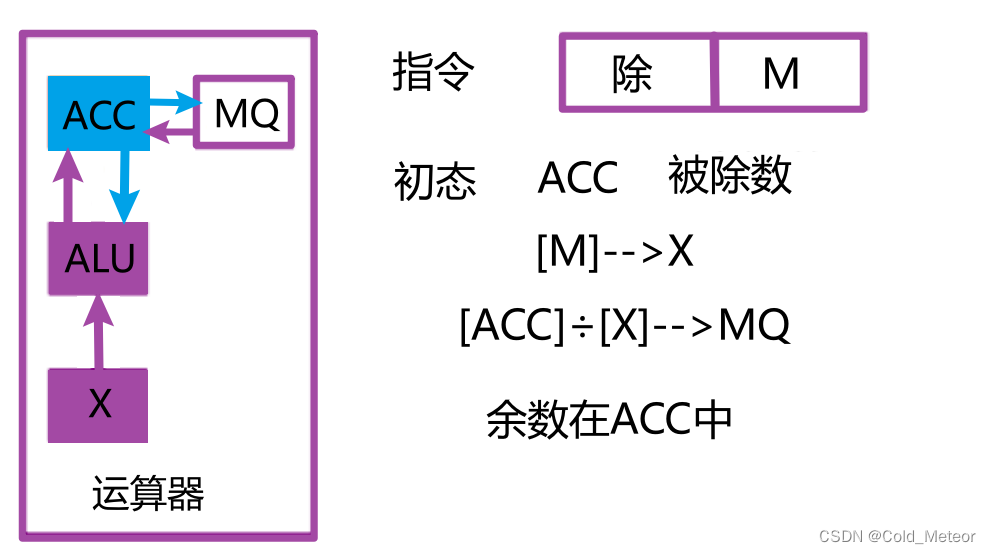
# 摘要
本文详细介绍了Verilog除法器的设计基础、理论基础、验证方法、测试策略以及高级验证技巧。首先,探讨了除法器设计的基础知识和数学原理,随后深入讨论了除法器的硬件实现,包括不同类型的除法器和硬件优化技术。接着,文章详述了除法器的验证方法,涵盖功能仿真验证和形式化验证,并解释了自动化测试框架和覆盖率分析在测试策略中的应用。文章最后介绍了断言驱动开发、跨时钟域验证以及验证计划和管理的高级技巧,为硬件设计者提供了一
【文档转换专家】:掌握Word到PDF无缝转换的终极技巧
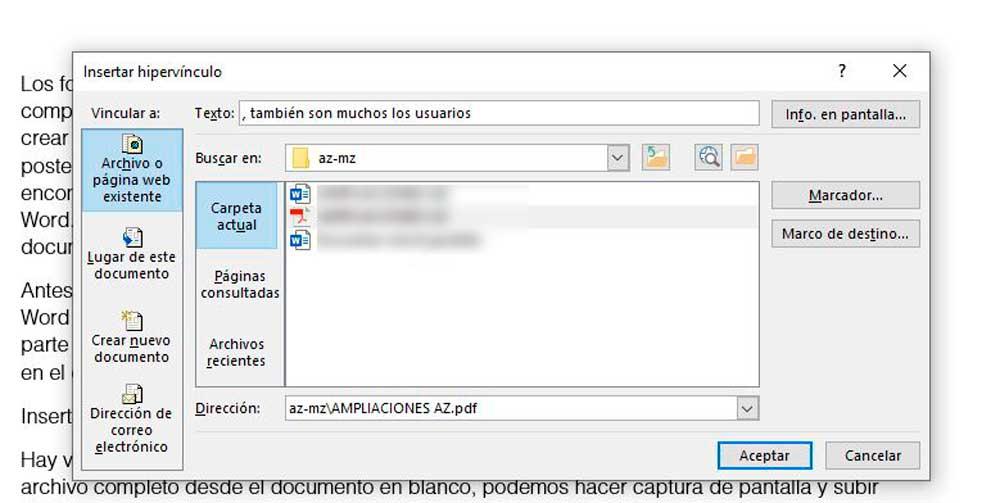
# 摘要
文档转换是电子文档处理中的一个重要环节,尤其是从Word到PDF的转换,因其实用性广泛受到关注。本文首先概述了文档转换的基础知识及Word到PDF转换的必要性。随后,深入探讨了转换的理论基础,包括格式转换原理、Word与PDF格式的差异,以及转换过程中遇到的布局、图像、表格、特殊字符处理和安全可访问性挑战。接着,文章通过介绍常用转换工具,实践操作步骤及解决
计算机二级Python实战:文件操作与数据持久化的巧妙应用

# 摘要
本文深入探讨了Python中文件操作的基础知识、数据持久化的机制以及它们在实际应用中的结合。首先,本文介绍了Python进行文件操作的基础,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )