Ensuring Data Consistency: Transaction Processing Mechanism of Doris Database
发布时间: 2024-09-14 22:41:05 阅读量: 38 订阅数: 35 

java全大撒大撒大苏打
# 1. The Importance of Data Consistency: Doris Database's Transaction Processing Mechanism
Data consistency is a crucial concept in database systems, ensuring the accuracy and integrity of data within a database. Data consistency demands that the data within a database is always in a valid state and adheres to expected business rules. Without data consistency, there may be data corruption, loss, or inaccuracies, which can severely impact business operations.
Data consistency is essential for the following aspects:
- **Data Integrity:** Ensures that data within the database is accurate and adheres to business rules and constraints.
- **Data Reliability:** Guarantees that data will not be lost or corrupted due to accidental events (such as hardware failures or software errors).
- **Data Availability:** Ensures users can access accurate and up-to-date data at any time.
# 2. Fundamental Principles of Transaction Processing
### 2.1 ACID Properties of Transactions
The ACID properties of transaction processing are the fundamental principles of transaction management in database management systems (DBMS), ensuring the reliability and consistency of database operations. ACID properties include:
- **Atomicity:** A transaction is an indivisible unit that either completely succeeds or fails entirely.
- **Consistency:** The database must be in a consistent state before and after the transaction, meaning it satisfies all business rules and constraints.
- **Isolation:** Concurrent transactions are independent of each other and do not affect one another.
- **Durability:** Once a transaction is committed successfully, its changes to the database are permanently saved, even if a system failure occurs.
### 2.2 Isolation Levels of Transactions
Isolation levels define the degree of visibility between concurrent transactions, ***mon isolation levels include:
- **Read Uncommitted:** Transactions can read data from other transactions that have not yet been committed, potentially leading to dirty reads.
- **Read Committed:** Transactions can only read data from other transactions that have been committed, avoiding dirty reads.
- **Repeatable Read:** Transactions can read the same data multiple times during execution, and the result will be consistent each time, avoiding phantom reads.
- **Serializable:** The order of transaction execution is the same as if they were executed serially, completely avoiding concurrency issues.
**Code Block:**
```python
# Set transaction isolation level to Repeatable Read
session.set_isolation_level(IsolationLevel.REPEATABLE_READ)
```
**Logical Analysis:**
The `set_isolation_level()` method is used to set the isolation level of a transaction. `REPEATABLE_READ` indicates that a transaction can read the same data multiple times during execution, and the result will be consistent each time.
**Parameter Description:**
- `IsolationLevel.REPEATABLE_READ`: Repeatable Read isolation level.
### 2.3 Concurrency Control Mechanisms of Transactions
Concurrency control mechanisms are used to manage the interaction between concurrent transactions, ***mon concurrency control mechanisms include:
- **Locking Mechanism:** Prevents other transactions from modifying a data object by locking it.
- **Optimistic Concurrency Control (OCC):** Does not use locks but solves concurrency issues through version control and conflict detection.
- **Multiversion Concurrency Control (MVCC):** Maintains multiple versions of a data object, allowing concurrent transactions to read different versions of the data.
**Table:**
| Concurrency Control Mechanism | Advantages | Disadvantages |
|---|---|---|
| Locking Mechanism | Ensures data consistency | May lead to deadlocks |
| OCC | High performance | May lead to dirty writes |
| MVCC | High performance, avoids deadlocks | Implementation complexity, high space overhead |
**Flowchart:**
```mermaid
graph LR
subgraph Locking Mechanism
A[Acquire Lock] --> B[Modify Data]
B[Release Lock] --> C[Commit Transaction]
end
subgraph OCC
A[Read Data] --> B[Modify Data]
B[Commit Transaction] --> C[Detect Conflicts]
C[Conflict] --> D[Rollback Transaction]
C[No Con
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
电力电子初学者必看:Simplorer带你从零开始精通IGBT应用
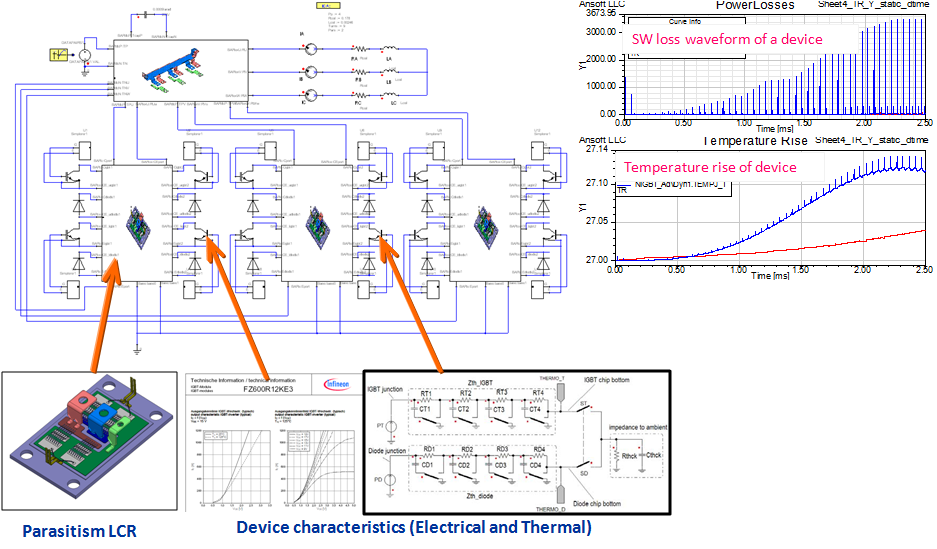
# 摘要
本文介绍了Simplorer软件在IGBT仿真应用中的重要性及其在电力电子领域中的应用。首先,文章概括了IGBT的基本理论和工作原理,涵盖其定义、组成、工作模式以及在电力电子设备中的作用。然后,详细探讨了Simplorer软件中IGBT模型的特点和功能,并通过仿真案例分析了IGBT的驱动电路和热特性。文章接着通过实际应用实例,如太阳能逆变器、电动汽车充放电系统和工业变频器,来
KUKA机器人的PROFINET集成:从新手到专家的配置秘籍
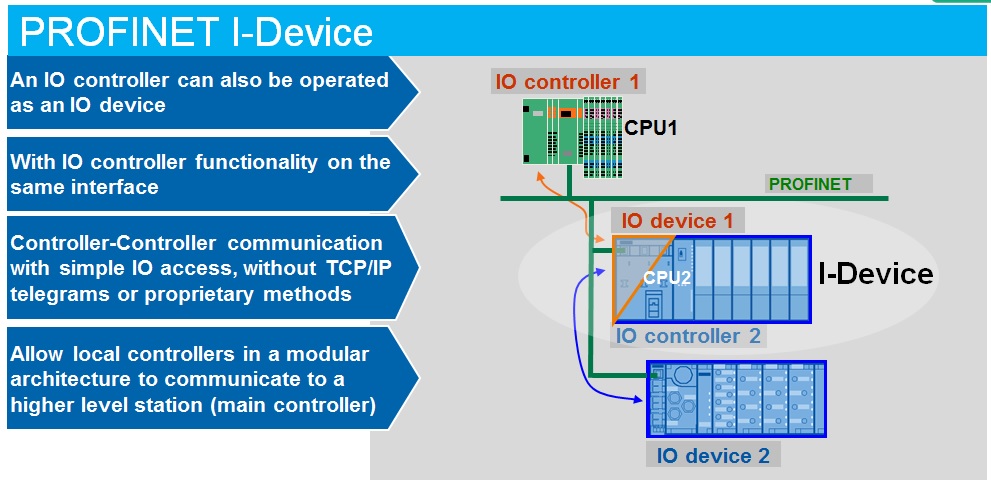
# 摘要
随着工业自动化技术的发展,KUKA机器人与PROFINET技术的集成已成为提高生产效率和自动化水平的关键。本文首先介绍KUKA机器人与PROFINET集成的基础知识,然后深入探讨PROFINET技术标准,包括通信协议、架构和安全性分析。在此基础上,文章详细描述了KUKA机器人的PROFINET配置方法,涵盖硬件准备、软件配置及故障诊断。进一步地,文章探讨了
STM32F030C8T6时钟系统设计:时序精确配置与性能调优
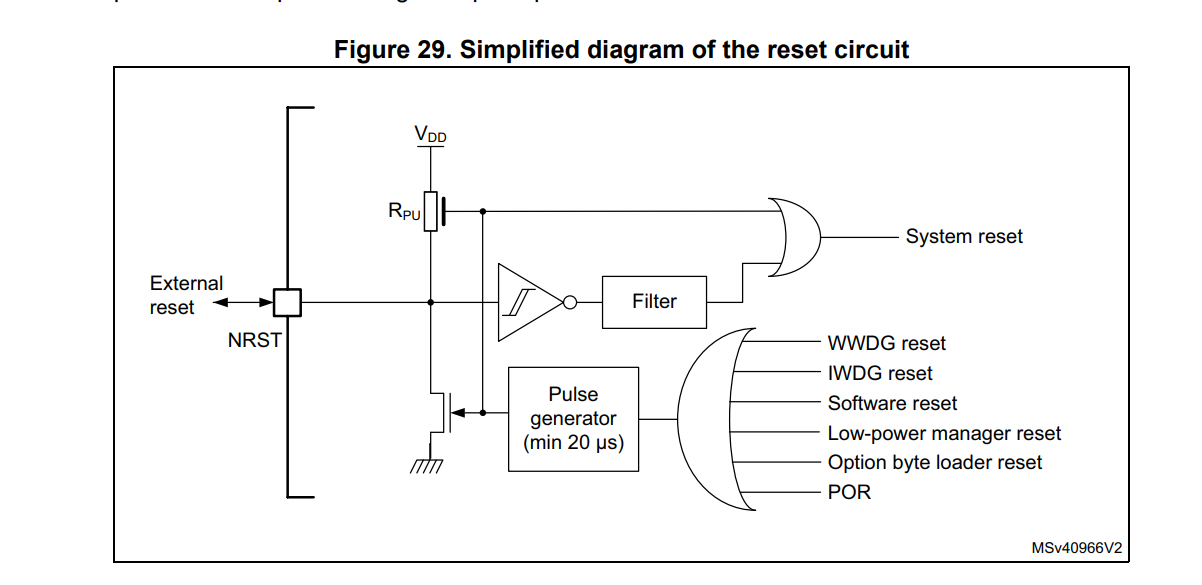
# 摘要
本文全面介绍了STM32F030C8T6微控制器的时钟系统,从基础配置到精确调优和故障诊断,详细阐述了时钟源选择、分频器、PLL生成器、时钟同步、动态时钟管理以及电源管理等关键组件的配置与应用。通过分析时钟系统的理论基础和实践操作,探讨了系统时钟配置的最优策略,并结合案例研究,揭示了时钟系统在实际应用中性能调优的效果与经验教训。此外,本文还探讨了提升系统稳定性的技术与策略
数字逻辑知识体系构建:第五版关键练习题精讲
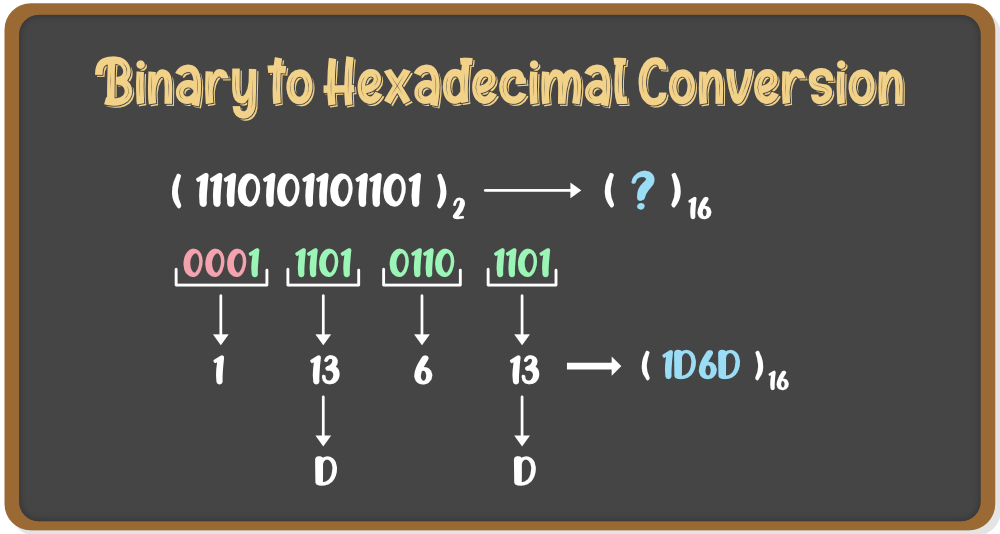
# 摘要
本文对数字逻辑的基本概念、设计技巧以及系统测试与验证进行了全面的探讨。首先解析了数字逻辑的基础原理,包括数字信号、系统以及逻辑运算的基本概念。接着,分析了逻辑门电路的设计与技巧,阐述了组合逻辑与时序逻辑电路的分析方法。在实践应用方面,本文详细介绍了数字逻辑设计的步骤和方法,以及现代技术中的数字逻辑应用案例。最后,探讨了
Element Card 常见问题汇总:24小时内解决你的所有疑惑

# 摘要
Element Card作为一种流行的前端组件库,为开发者提供了一系列构建用户界面和交互功能的工具。本文旨在全面介绍Element Card的基本概念、安装配置、功能使用、前后端集成以及高级应用等多方面内容。文章首先从基础知识出发,详述了Element Card的安装过程和配置步骤,强调了解决安装配置问题的重要性。随后,
【PyCharm从入门到精通】:掌握Excel操纵的必备技巧
# 摘要
本文详细介绍了PyCharm集成开发环境的安装、配置以及与Python编程语言的紧密结合。文章涵盖从基础语法回顾到高级特性应用,包括控制流语句、函数、类、模块、异常处理和文件操作。同时,强调了PyCharm调试工具的使用技巧,以及如何操纵Excel进行数据分析、处理、自动化脚本编写和高级集成。为了提升性能,文章还提供了PyCharm性能优化和
【提升VMware性能】:虚拟机高级技巧全解析
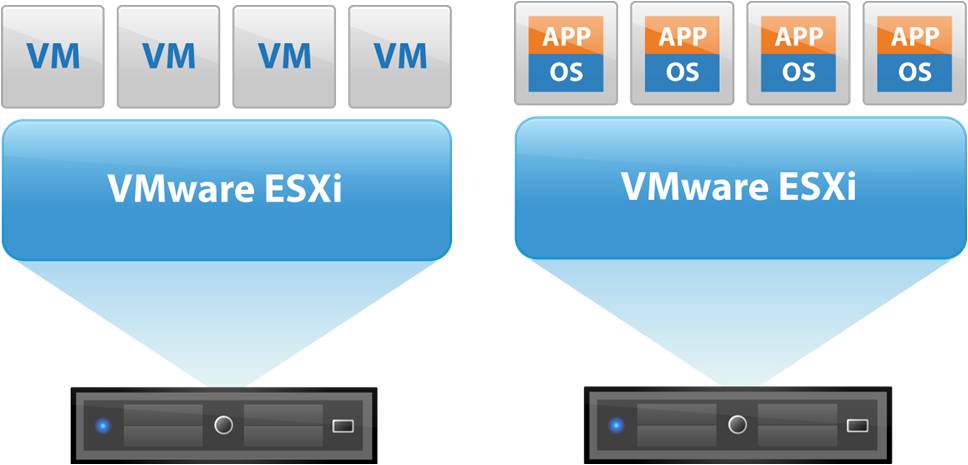
# 摘要
随着虚拟化技术的广泛应用,VMware作为市场主流的虚拟化平台,其性能优化问题备受关注。本文综合探讨了VMware在虚拟硬件配置、网络性能、系统和应用层面以及高可用性和故障转移等方面的优化策略。通过分析CPU资源分配、内存管理、磁盘I/O调整、网络配置和操作系统调优等关键技术点,本文旨在提供一套全面的性能提升方案。此外,文章还介绍了性能监控和分析工具的运用,帮助用户及时发
性能优化杀手锏:提升移动应用响应速度的终极技巧

# 摘要
移动应用性能优化是确保用户良好体验的关键因素之一。本文概述了移动应用性能优化的重要性,并分别从前端和后端两个角度详述了优化技巧。前端优化技巧涉及用户界面渲染、资源加载、代码执行效率的提升,而后端优化策略包括数据库操作、服务器资源管理及API性能调优。此外,文章还探讨了移动应用架构的设计原则、网络优化与安全性、性能监控与反馈系统的重要性。最后,通过案例分析来总结当前优化实践,并展望未来优
【CEQW2数据分析艺术】:生成报告与深入挖掘数据洞察
# 摘要
本文全面探讨了数据分析的艺术和技术,从报告生成的基础知识到深入的数据挖掘方法,再到数据分析工具的实际应用和未来趋势。第一章概述了数据分析的重要性,第二章详细介绍了数据报告的设计和高级技术,包括报告类型选择、数据可视化和自动化报告生成。第三章深入探讨了数据分析的方法论,涵盖数据清洗、统计分析和数据挖掘技术。第四章探讨了关联规则、聚类分析和时间序列分析等更高级的数据洞察技术。第五章将
ARM处理器安全模式解析:探索与应用之道

# 摘要
本文对ARM处理器的安全模式进行了全面概述,从基础理论讲起,详细阐述了安全状态与非安全状态、安全扩展与TrustZone技术、内存管理、安全启动和引导过程等关键概念。接着,文章深入探讨了ARM安全模式的实战应用,包括安全存储、密钥管理、安全通信协议以及安全操作系统的部署与管理。在高级应用技巧章节,本
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )