MapReduce:海量数据处理的分区与负载均衡策略

1. MapReduce的基本原理与架构
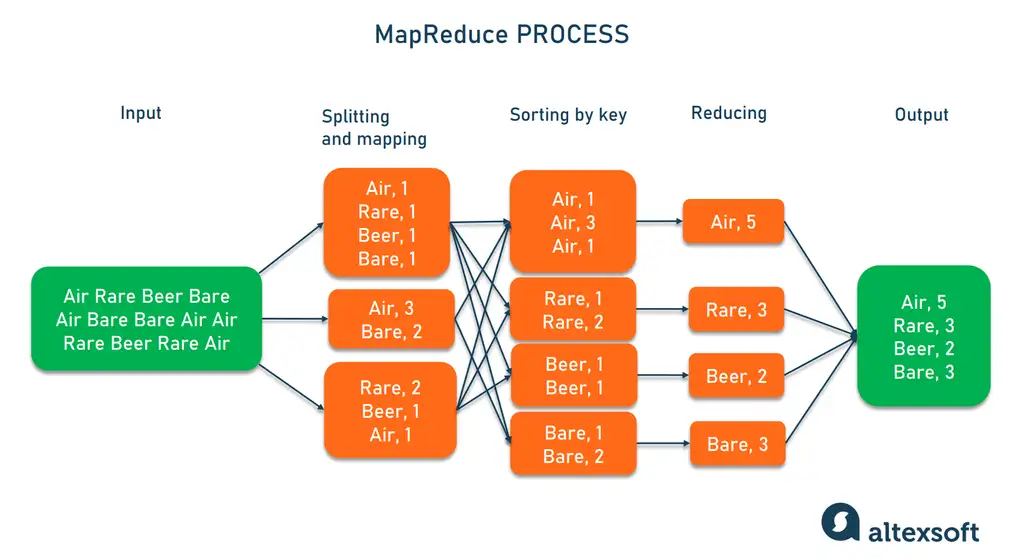
MapReduce是一种编程模型,用于处理大规模数据集。其核心是将计算任务分解为两个阶段:Map阶段和Reduce阶段。Map阶段处理输入数据,生成中间键值对;Reduce阶段则对这些中间键值对进行汇总,生成最终结果。这种模式极大地简化了并行编程模型,使其易于理解和实现。
1.1 MapReduce计算模型
计算模型是MapReduce的核心,由以下几个关键部分组成:
- 输入数据:数据被切分为固定大小的数据块,这些数据块可以并行处理。
- Map任务:Map函数处理输入数据块,执行用户定义的逻辑,产生键值对。
- Shuffle操作:Map任务产生的键值对经过排序和分配,确保相同键值的数据对被发送到同一个Reduce任务。
- Reduce任务:Reduce函数对所有具有相同键的值进行汇总处理。
1.2 MapReduce架构组件
MapReduce架构包含以下关键组件:
- Master节点:负责资源管理和任务调度,决定哪些任务由哪些从属节点执行。
- 从属节点(Slave或Worker节点):执行实际的Map和Reduce计算任务。
- 任务:每个Map或Reduce操作被视为一个任务。
- 任务槽(Task Slots):从属节点上用于执行任务的资源。
理解MapReduce的基本原理和架构是应用其进行大数据处理的第一步。接下来的章节将深入探讨数据分区策略、负载均衡机制和高级技术,以及这些技术的未来趋势。
2. 数据分区策略的理论与应用
2.1 数据分区的理论基础
2.1.1 分区的重要性与核心目标
数据分区是分布式计算中的核心概念,它主要负责将数据集拆分成更小的逻辑块,以便于并行处理。正确地实施数据分区策略对于提高数据处理的效率和系统的性能至关重要。
在MapReduce框架中,数据分区的核心目标通常包括:
- 提高数据处理的并行度:通过分区,可以确保多个Map任务同时处理数据,从而提高整个作业的处理速度。
- 实现负载均衡:合理的分区策略能够减少节点间数据处理量的差异,避免数据倾斜现象的发生,即某些节点承担过多的任务。
- 提升数据访问效率:良好的数据分区能够使数据尽量靠近计算节点,减少网络传输的时间开销。
2.1.2 常见的分区算法与适用场景
在MapReduce中,常见的数据分区算法有:
- 哈希分区:通过对关键字进行哈希运算,将记录分配到不同的分区。适用于随机分布的数据集,可以较好地避免数据倾斜问题。
- 范围分区:将关键字的范围预先设定好,将记录映射到对应范围的分区。适用于有序数据集,便于连续查询操作。
- 自定义分区:用户可以基于特定的业务逻辑实现分区函数,用于特殊的数据分布或特殊的处理需求。
每个算法都有其特点和适用场景。例如,哈希分区在数据随机性较好的情况下效果最好,而范围分区则适合那些自然有序的数据。
2.2 实践中的数据分区应用
2.2.1 Hadoop默认分区器的实现与分析
Hadoop提供了默认的分区器实现,通常是基于哈希的分区算法,但用户也可以选择其他分区策略。让我们深入分析一下默认分区器的代码逻辑。
- public class HashPartitioner<K, V> extends Partitioner<K, V> {
- public int getPartition(K key, V value, int numPartitions) {
- return (key.hashCode() & Integer.MAX_VALUE) % numPartitions;
- }
- }
上述代码块是Hadoop默认分区器的简单实现,通过key的哈希值与最大整数值进行位运算,然后对分区数取余,确定记录所在的分区。这种实现方式保证了分区的随机性,但仍然存在潜在的数据倾斜问题。
2.2.2 自定义分区器的设计与优化
为了应对特定的业务场景或优化性能,开发者经常需要设计自己的自定义分区器。下面是一个简单的自定义分区器的实现:
- public class CustomPartitioner extends Partitioner<Text, IntWritable> {
- public int getPartition(Text key, IntWritable value, int numPartitions) {
- // 自定义分区逻辑,例如基于关键字的首字母
- return (key.toString().charAt(0) % numPartitions);
- }
- }
这段代码演示了如何根据关键字首字母的哈希值来进行分区。在设计时,需要考虑分区逻辑与数据处理的负载均衡,并通过实验或分析来不断优化分区器的表现。
2.3 分区策略对负载均衡的影响
2.3.1 负载不均的识别与问题分析
负载不均会导致部分节点处理的数据量远远超过其他节点,这在分布式计算中会导致效率低下和资源浪费。识别负载不均可以通过监控任务执行时间和资源使用情况来实现。问题分析包括检查分区策略是否合理,数据分布是否均匀等。
2.3.2 分区策略优化与负载均衡的实现
优化分区策略需要对数据分布进行分析,并采取合适的算法和策略。例如,可以通过重写分区器,引入更复杂的哈希函数来减少数据倾斜。同时,可以使用动态分区策略来适应数据的变化。
通过以下表格,我们可以比较不同分区策略在负载均衡上的表现:
| 分区策略 | 负载均衡度 | 数据倾斜风险 | 实现复杂度 |
|---|---|---|---|
| 哈希分区 | 中等 | 低 | 低 |
| 范围分区 | 高 | 高 | 高 |
| 自定义分区 | 可变 | 可变 | 可变 |
通过表格,我们可以清晰地看到不同分区策略在负载均衡和实现上的差异,为优化分区策略提供参考依据。
3. ```
第三章:负载均衡的机制与优化方法
3.1 负载均衡的基本原理
3.1.1 负载均衡的目标与挑战
负载均衡是分布式计算中的核心问题之一,目的是为了确保所有计算资源均被高效、均匀地利用,避免出现部分节点过载而其他节点空闲的情况。负载均衡在MapReduce框架中尤为重要,因为Map和Reduce任务的处理时间往往差别较大,加之数据的不均匀分布,很容易造成负载不均。
实现负载均衡的目标需要克服多方面的挑战,例如数据倾斜、网络带宽限

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
相关推荐

专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Halcon图像识别】:一步到位学会1D_2D码识别
Oracle RAC集群维护:专家级不停机调整最佳实践
三菱CNC m70PLC接口安全攻略:保障系统稳定的五大措施
CCS3.3实战手册:掌握嵌入式系统开发的终极技巧
Ubuntu RTMP服务器性能调优秘籍:深入分析与实时监控技巧
【锅炉系统升级必备】:掌握600MW锅炉DCS系统的10大关键性能优化步骤
面向接口编程技术:Fortran OOP进阶指南
IntelliJ IDEA中的代码注释最佳实践:参数和返回值的智能处理
逆变器控制深度解析:DQ坐标变换的核心作用


专栏目录
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )