权威揭秘:MapReduce Shuffle性能提升的7个实用技巧
发布时间: 2024-10-30 14:35:12 阅读量: 49 订阅数: 34 

大数据实验5实验报告:MapReduce 初级编程实践
# 1. MapReduce Shuffle概述
MapReduce框架的核心组件之一Shuffle,在大数据处理中起着至关重要的作用。它负责将Map阶段处理后的中间结果传递给Reduce阶段,这个过程涉及到数据的排序、合并、分区和传输。本章节将为读者梳理Shuffle的基本概念,帮助理解其在大数据处理中的基础作用。接下来我们将深入探讨Shuffle过程中数据的流动、排序和分区的细节,以及如何分析和优化Shuffle的性能,进而提升整体的数据处理效率。在进入更深层次的内容之前,让我们先从Shuffle的概述开始,为理解后续章节打下坚实的基础。
# 2. 理解Shuffle过程中的数据流动
Shuffle是MapReduce框架中至关重要的一个阶段,它负责将Map任务输出的数据分发到Reduce任务,确保相同键值的数据能够被发送到同一个Reduce任务中进行处理。Shuffle过程的效率直接影响整个MapReduce作业的性能。理解Shuffle过程中的数据流动是进行性能调优和优化的基础。
### 2.1 Shuffle的定义和作用
Shuffle本质上是一个数据的重新分发过程,它包括了从Map端到Reduce端的整个数据传输链路。在这个过程中,数据不仅被移动,还被重新组织,以保证每个Reduce任务能够得到它所需要处理的特定数据集。Shuffle的作用可以概括为以下几点:
- 数据划分:确保每个Reduce任务处理的是它应该处理的数据片段。
- 网络传输:将数据从Map任务的节点传输到Reduce任务的节点。
- 数据排序:在传输之前,Map输出的结果会按照key进行局部排序,以提高网络传输的效率。
- 系统优化:通过合理的调度,减少磁盘I/O操作和网络带宽的消耗。
### 2.2 Shuffle过程的关键组件分析
#### 2.2.1 Map端的Shuffle处理
Map端的Shuffle处理是整个Shuffle过程的起点,它涉及到数据的排序、分区和数据的溢写。首先,Map任务会处理输入数据,并将其输出到内存缓冲区。当缓冲区的大小达到一定的阈值后,数据会被写入到磁盘。这个过程包括以下几个步骤:
- 内存缓冲:Map任务将输出结果存储在内存中,便于快速处理。
- 溢写触发:当缓冲区的数据达到一定的大小,Map任务会启动溢写过程。
- 排序和分区:在写入磁盘之前,数据会根据key进行排序,并根据分区函数进行分区。
- 磁盘存储:经过排序和分区后的数据被写入到磁盘上,形成一个个分片(spill file)。
#### 2.2.2 Reduce端的Shuffle处理
Reduce端的Shuffle处理则是完成数据接收、合并和排序的工作。Reduce任务会从所有Map任务获取数据,并将这些数据准备就绪以供Reduce函数处理。具体步骤如下:
- 数据拉取:Reduce任务从Map任务拉取数据。
- 数据合并:将拉取来的数据进行合并,确保相同key的数据在一起。
- 最终排序:合并后的数据会进行最终的排序。
- 调用Reduce函数:对排序后的数据集进行处理,产生最终的输出结果。
### 2.3 Shuffle中的数据排序和分区
#### 2.3.1 排序机制详解
Shuffle过程中的排序机制涉及到几个关键的步骤:
- 初步排序:在Map输出到磁盘之前,会使用快速排序或归并排序等算法进行初步排序。
- 合并排序:在Reduce端,会根据key对从各个Map任务获取的数据进行合并和最终排序。
#### 2.3.2 分区策略的优化
分区是Shuffle过程中一个重要的步骤,它决定了数据最终将被发送到哪个Reduce任务。分区策略的优化主要包括:
- 分区函数的选择:比如使用哈希分区或者范围分区等。
- 分区数的确定:分区数通常与Reduce任务数相同,过少或过多都会影响性能。
Shuffle过程中的数据流动是复杂且关键的,理解每个组件如何协同工作,能够帮助开发者更有效地优化MapReduce作业的性能。在后续章节中,我们将深入探讨Shuffle性能分析与优化、实践技巧以及未来趋势。
# 3. Shuffle性能分析与优化基础
## 3.1 性能分析的关键指标
### 3.1.1 网络I/O的监控和优化
在大规模分布式计算环境中,网络I/O成为制约整体系统性能的一个关键因素。在MapReduce模型下,Shuffle过程中的网络I/O主要用于Map端输出数据传输到Reduce端。数据在网络中的传输时间会直接影响作业的完成时间。因此,对网络I/O的监控和优化是提升Shuffle性能的一个重要方面。
监控网络I/O的性能指标通常包括网络带宽利用率、网络吞吐量、数据传输延迟等。针对这些指标,我们可以采取如下优化措施:
- **减少数据传输量**:在Map端,可以适当增加Map任务的大小,以减少产生的中间数据量。同时,也可以通过数据压缩等方式减少网络传输数据的大小。
- **网络分区优化**:合理规划网络拓扑结构,避免网络拥堵,例如,使用高速交换机和合理的子网划分。
- **批量传输**:在网络数据传输时,采用批量传输的方式来减少对网络I/O的频繁调用,提高传输效率。
下面是一个简单的示例代码,展示了如何在Java中利用Socket进行网络数据传输,并计算传输所需的时间,以评估网络I/O性能:
```java
import java.io.*;
***.Socket;
public class NetworkIOBenchmark {
public static void main(String[] args) throws IOException {
String host = "***.*.*.*"; // 服务器地址
int port = 12345; // 服务器端口
int messageSize = 1024; // 消息大小,单位为字节
int numMessages = 100; // 消息数量
long startTime = System.currentTimeMillis();
try (Socket socket = new Socket(host, port)) {
OutputStream output = socket.getOutputStream();
for (int i = 0; i < numMessages; i++) {
byte[] message = new byte[messageSize];
output.write(message);
}
output.flush();
}
long endTime = System.currentTimeMillis();
System.out.println("Total time for data transfer: " + (endTime - startTime) + "ms");
}
}
```
在上述代码中,我们通过测量数据传输前后的时间差,来计算网络传输时间。通过这种方式,我们可以评估不同优化策略对网络I/O性能的影响。
### 3.1.2 磁盘I/O的监控和优化
磁盘I/O是影响Shuffle性能的另一关键因素,尤其是在Map端输出和Reduce端读取数据阶段。对于Map端而言,中间数据首先被写入本地磁盘;对于Reduce端,需要从各个Map节点拉取数据并写入磁盘。
要提高磁盘I/O性能,需要关注以下几个方面:
- **使用固态硬盘(SSD)**:SSD相对机械硬盘(HDD)有更低的延迟和更高的读写速度,对于I/O密集型操作,能显著提高性能。
- **RAID配置**:通过磁盘阵列技术(如RAID0),可以提高磁盘读写速度和数据冗余性,提升整体性能。
- **文件系统优化**:采用适合大数据处理的文件系统,如XFS或ext4,它们为连续大块数据读写优化。
下面是一个使用Linux命令`iotop`监控磁盘I/O活动的简单示例:
```bash
sudo iotop
```
执行上述命令后,可以观察到不同进程的磁盘I/O使用情况,通过这些信息,可以帮助我们定位磁盘瓶颈并进一步进行优化。
## 3.2 优化Shuffle的内存管理
### 3.2.1 内存溢写参数的调整
MapReduce Shuffle过程中,Map任务的输出首先被保存在内存中,一旦达到一定阈值,这些数据就会被溢写到磁盘。调整内存溢写相关的参数,如`mapreduce.job.maps.memory.mb`和`mapreduce.job.maps.java.opts`,可以显著影响到Shuffle的性能。
通过增加Map任务可用的内存量,可以减少内存溢写到磁盘的频率,从而提升性能。然而,这需要在保证集群其他任务正常运行的情况下进行调整,防止内存溢出。
### 3.2.2 堆外内存的利用与限制
除了JVM堆内存之外,Java还支持使用堆外内存(Direct Byte Buffer)。在Shuffle过程中,合理使用堆外内存可以减少内存碎片化问题,提高内存使用效率。
在Hadoop和Spark等分布式计算框架中,可以配置使用堆外内存的比例,以及分配给任务的最大堆外内存大小。例如,在Spark中可以通过参数`spark.executor.memoryOverhead`来控制。
## 3.3 优化Shuffle的磁盘存储
### 3.3.1 磁盘缓存机制的应用
磁盘缓存机制可以有效减少对磁盘的直接读写操作,提升数据访问速度。例如,Hadoop的HDFS提供了本地读缓存机制,通过缓存常用的HDFS数据块到本地磁盘,以减少网络传输的开销。
下面是一个关于HDFS本地读缓存机制的配置示例:
```xml
<property>
<name>dfs.datanode.data.dir</name>
<value>***${hadoop.tmp.dir}/dfs/data</value>
<description>本地读缓存数据目录</description>
</property>
<property>
<name>dfs.client.read.shortcircuit</name>
<value>true</value>
<description>启用本地读缓存机制</description>
</property>
```
### 3.3.2 数据压缩对性能的影响
数据压缩可以有效减少磁盘I/O操作,提升网络传输效率。然而,数据压缩和解压本身也需要消耗计算资源。因此,必须在压缩比和计算效率之间取得平衡。
在MapReduce中,可以对Map端输出以及最终输出结果进行压缩。比如,通过设置`***press`为`true`可以启用压缩功能。
```xml
<property>
<name>***press</name>
<value>true</value>
</property>
<property>
<name>***press.codec</name>
<value>***press.GzipCodec</value>
</property>
```
在上述配置中,我们启用了Gzip压缩,并指定了压缩编解码器为`GzipCodec`。选择合适的压缩算法和参数对于优化性能至关重要。
以上内容对Shuffle性能分析与优化的基础做了探讨,涉及了性能监控的关键指标和具体的优化措施。在下一章节中,我们将进一步深入讨论Shuffle性能提升的实践技巧,并提供一些实战演练的案例。
# 4. Shuffle性能提升的实践技巧
## 4.1 调整Map任务的并行度
### 4.1.1 确定最佳Map任务数
在MapReduce框架中,Map任务的并行度是影响Shuffle性能的一个关键因素。Map任务数设置过多或过少都会对性能造成影响。过多的Map任务会消耗过多的资源并可能导致任务调度的开销,而太少的Map任务可能无法充分利用集群的计算能力,导致资源浪费。
为了确定最佳的Map任务数,我们可以通过实验和监控集群的资源使用情况来进行分析。通常,Map任务数应该与集群的节点数量和每个节点的CPU核心数相匹配。对于大数据集,Map任务数可以设置为总核心数的1.5到3倍。通过逐步调整Map任务数,观察任务完成时间和资源利用率,可以找到一个较为理想的平衡点。
```bash
hadoop jar my-mapreduce-job.jar -D mapreduce.job.maps=100 my-input-path my-output-path
```
在上面的Hadoop命令中,`-D mapreduce.job.maps=100` 设置了Map任务的数量为100。我们可以通过多次运行作业,逐渐改变这个值,然后观察`mapreduce.job.endtimemillis`和`mapreduce.job投机次数`指标来优化Map任务数。
### 4.1.2 自适应任务调度的策略
自适应任务调度是指根据当前的集群负载和任务执行情况动态调整Map任务的并行度。这通常依赖于集群管理器的策略,例如Apache Hadoop的YARN和Apache Spark的集群管理器。
在YARN中,可以配置`yarn.scheduler.capacity.maximum-applications`和`yarn.scheduler.capacity.resource-calculator`等参数来控制任务调度。而在Spark中,可以通过动态资源分配功能来实现自适应调度。下面是一个Spark动态资源分配的配置示例:
```scala
val conf = new SparkConf().setMaster("yarn").setAppName("Adaptive Scheduling")
.set("spark.dynamicAllocation.enabled", "true")
.set("spark.shuffle.service.enabled", "true")
.set("spark.executor.memory", "4g")
.set("spark.executor.cores", "4")
```
在这个配置中,`spark.dynamicAllocation.enabled`设置为true来启用动态资源分配。`spark.shuffle.service.enabled`设置为true来允许Shuffle服务在独立的Executor上运行,这可以改善Shuffle过程中的稳定性。
## 4.2 自定义分区器和排序器
### 4.2.1 分区器的编写和应用
自定义分区器可以提高Shuffle过程中数据分布的效率。在Hadoop MapReduce中,默认使用的是`HashPartitioner`,它通过哈希值来决定键值对应该被送往哪个Reduce任务。然而,在特定的应用场景下,如键分布不均时,自定义分区器可以提供更好的性能。
自定义分区器需要继承`org.apache.hadoop.mapreduce.Partitioner`类,并重写`getPartition`方法。下面是一个自定义分区器的示例代码:
```java
public class CustomPartitioner extends Partitioner<Text, IntWritable> {
@Override
public int getPartition(Text key, IntWritable value, int numPartitions) {
// 基于键值的某种逻辑来计算分区
return (key.hashCode() & Integer.MAX_VALUE) % numPartitions;
}
}
```
在上面的代码中,我们通过自定义的哈希逻辑来决定键值对的分区。之后,需要在MapReduce作业中指定使用这个分区器:
```java
job.setPartitionerClass(CustomPartitioner.class);
```
### 4.2.2 排序器的选择和实现
排序器决定了键值对在写入到磁盘和发送给Reduce端之前是如何排序的。在MapReduce中,默认的排序器是`TotalOrderPartitioner`,它通过自然排序来组织键值对。然而,在某些情况下,可能需要特定的排序逻辑来优化性能。
自定义排序器需要实现`org.apache.hadoop.mapreduce.lib.partition.TotalOrderPartitioner`接口。下面是一个简单的自定义排序器实现示例:
```java
public class CustomSorter extends TotalOrderPartitioner<Text, IntWritable> {
@Override
public void generatePartitionFile(JobContext context) throws IOException, InterruptedException {
// 实现自定义的分区逻辑
}
}
```
实现自定义排序器后,需要在作业配置中指定使用这个排序器:
```java
job.setSortComparatorClass(CustomSorter.class);
```
## 4.3 高级Shuffle配置技巧
### 4.3.1 配置JVM调优参数
JVM的调优对于Shuffle性能优化也有着显著的作用。通过合理配置JVM内存和垃圾回收(GC)策略,可以提高内存的利用率和数据处理的吞吐量。
例如,可以使用`-XX:+UseG1GC`来启用G1垃圾回收器,并且通过`-Xmx`和`-Xms`参数来设置堆内存的最大和初始大小。下面是一个JVM参数配置示例:
```bash
export HADOOP_MAPRED_OPTS="-Xmx4g -XX:+UseG1GC"
```
在上面的配置中,我们为MapReduce任务设置了最大堆内存为4GB,并启用了G1垃圾回收器,以提高内存管理和回收的效率。
### 4.3.2 设置连接器和网络缓冲区大小
连接器(Connector)和网络缓冲区大小的调整,可以影响到数据在网络中的传输效率。在Hadoop中,可以通过调整`io.file.buffer.size`参数来设置网络缓冲区的大小。更大的缓冲区可以提高传输速度,但是也会占用更多的内存。
```java
jobConf.set("io.file.buffer.size", "65536");
```
在上面的代码中,我们将网络缓冲区的大小设置为64KB。根据数据量和网络条件的不同,可以适当调整这个参数,以获得最佳的性能。
总的来说,通过调整Shuffle配置,开发者可以更精准地控制数据处理过程,从而提升整体的MapReduce作业性能。这些调整需要在测试和分析的基础上进行,以确保更改对性能确实有所提升。
# 5. 案例研究:提升Shuffle性能的实战演练
## 5.1 实际应用场景分析
### 5.1.1 大数据集的Shuffle优化实例
大数据场景下的Shuffle优化对于提高整体MapReduce作业的性能至关重要。在本小节中,我们将通过一个大数据集优化实例来深入理解Shuffle性能优化的具体操作。
假设我们面对一个包含数十亿条记录的大数据集,这个数据集被存储在Hadoop分布式文件系统(HDFS)上。原始的作业配置导致了Map阶段的输出过多,数据在Shuffle过程中产生了大量的网络传输和磁盘I/O消耗,从而影响了作业的整体性能。
**优化步骤:**
1. **调整Map和Reduce任务的并行度**:通过调整`mapreduce.job.maps`和`mapreduce.job.reduces`的参数值,减少并行度,以减少Map任务产生的中间文件数量,从而降低网络和磁盘压力。
2. **优化内存管理**:调整`mapreduce.job.heap.memory百分比`和`mapreduce.job.heap.memory百分比`参数,合理分配内存资源,防止溢写到磁盘导致的性能瓶颈。
3. **自定义分区器**:实现一个自定义分区器来控制数据的分区策略,保证数据均匀分布,避免数据倾斜问题。代码示例如下:
```java
public class CustomPartitioner extends Partitioner<Text, IntWritable> {
@Override
public int getPartition(Text key, IntWritable value, int numPartitions) {
// 自定义分区逻辑
return Math.abs(key.hashCode() % numPartitions);
}
}
```
4. **数据压缩**:在Shuffle输出阶段启用数据压缩,减少磁盘I/O和网络传输的负载。例如,在Hadoop中可以设置`***press=true`。
通过这些操作,可以大幅减少中间数据的处理时间,提升Shuffle阶段的性能。根据实际的集群环境和数据集特征,以上参数和策略需要进行相应的调整。
### 5.1.2 复杂计算任务的Shuffle优化实例
在复杂计算任务中,Shuffle优化同样重要。考虑一个场景,其中一个MapReduce作业涉及大量的数据关联和聚合操作。
**优化策略:**
1. **使用Combiner**:在Map任务完成后,使用Combiner进行局部聚合,减少Reduce端处理的数据量。
2. **自定义排序器**:对于需要在Shuffle过程中进行复杂排序的任务,可以通过自定义排序器来优化排序策略。代码示例如下:
```java
public class CustomSorter extends WritableComparator {
protected CustomSorter() {
super(Text.class, true);
}
@Override
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
// 自定义比较逻辑
***pareBytes(b1, s1, l1, b2, s2, l2);
}
}
```
3. **合理使用Secondary Sort**:通过Secondary Sort模式,可以在Reduce阶段得到更有序的数据,从而提高处理效率。
4. **监控和调优**:利用YARN的资源管理器和Hadoop自带的监控工具对作业性能进行实时监控,并对Shuffle阶段的关键参数进行微调。
以上策略经过实际应用,可以有效降低复杂计算任务中的Shuffle开销,提升整个MapReduce作业的运行效率。
## 5.2 工具和框架的选择
### 5.2.1 分析工具的使用和解读
为了更深入地理解和优化Shuffle性能,使用适当的分析工具是不可或缺的。在本小节,我们将探讨如何选择和应用这些分析工具。
**常用的Shuffle性能分析工具包括:**
- **Hadoop MapReduce自带的计数器**:可以提供Shuffle过程中发生的数据倾斜、错误等信息。
- **Ganglia**:提供集群层面的性能监控和分析。
- **Ambari**:Hadoop集群的管理工具,可以对集群进行配置、监控和管理。
使用这些工具,我们能够对Shuffle过程中的关键性能指标进行追踪和分析。例如,通过Ganglia,我们可以观察到节点的CPU使用率、内存占用、磁盘I/O和网络I/O的实时数据。这些信息可以帮助我们发现性能瓶颈,并针对性地进行调优。
### 5.2.2 框架对比与选择建议
针对不同的业务需求和数据处理场景,选择最合适的处理框架至关重要。在本小节中,我们将探讨如何根据实际情况选择合适的框架。
**框架对比:**
- **Hadoop MapReduce**:适用于批处理场景,稳定性和可扩展性强,但在实时处理和低延迟查询方面有局限。
- **Apache Spark**:在内存计算方面表现出色,提供了高性能的处理能力,特别适合复杂的数据处理任务。
- **Apache Flink**:在流处理方面表现卓越,同时也支持批处理,适合需要实时数据处理的场景。
**选择建议:**
- 当需要处理大规模、复杂的数据转换和分析时,Spark可能是更佳的选择,因为它提供了更多的高级操作,易于实现复杂的数据处理逻辑。
- 对于实时数据处理需求,Flink提供了出色的流处理性能,能够更快速地提供实时数据洞察。
- 在需要高度稳定性和可扩展性的生产环境中,MapReduce仍然是一个可靠的选择。
选择合适的框架不仅能够提升Shuffle的性能,而且还可以提高整个数据处理流程的效率和质量。在实际应用中,可能需要综合考虑成本、技术栈、团队技能和业务需求来做出最终决定。
# 6. 未来趋势:Shuffle性能的前沿技术
## 6.1 新兴技术对Shuffle性能的影响
随着大数据处理框架的不断创新和优化,Shuffle性能在数据处理中变得越来越重要。尤其是新兴技术的引入,正在对 Shuffle 性能产生深远的影响。
### 6.1.1 Spark等框架的Shuffle机制
Apache Spark作为大数据处理领域的新宠,其Shuffle机制与传统的MapReduce有所不同,具有更多的优化和改进。不同于MapReduce将中间数据持久化到磁盘,Spark采用了内存计算模型,中间结果优先保存在内存中,这大大加快了数据处理速度,但也带来了内存溢出的风险。
例如,在Spark中,Shuffle过程可以被优化来减少内存的使用:
```scala
// 示例代码:Spark Shuffle操作示例
val rdd = sc.parallelize(Seq((1, "a"), (2, "b"), (3, "c")))
val shuffled = rdd.keyBy(_._1).mapValues(_._2).reduceByKey(_ + _)
```
这里,`keyBy(_._1)`是对数据进行分区,而`reduceByKey(_ + _)`是对每个分区的数据执行Shuffle操作。通过自定义的分区函数和聚合逻辑,可以有效地控制Shuffle的性能。
### 6.1.2 云计算环境下的Shuffle优化
云计算为大数据处理提供了弹性和可扩展的资源,这为 Shuffle 性能优化提供了新的可能性。通过动态分配资源,可以有效地平衡负载,优化网络和存储I/O,从而提升Shuffle性能。
例如,在AWS等云平台中,可以使用Elastic MapReduce服务来自动化处理集群资源的配置和管理,进而提高Shuffle效率:
```json
// 示例代码:AWS EMR配置片段
[
{
"Classification": "emrfs-site",
"Properties": {
"fs.s3.enableV4": "true",
"fs.s3.maxRetries": "50"
}
}
]
```
在这里,通过配置EMR的fs.s3相关参数,可以提高与Amazon S3存储服务交互时的性能,这对于跨地域的大数据Shuffle操作尤其重要。
## 6.2 Shuffle的开源贡献和发展方向
开源社区是技术创新和传播的重要平台,对于Shuffle技术的发展同样起到了至关重要的作用。
### 6.2.1 开源社区的Shuffle改进案例
开源社区中不断有开发者和组织分享他们的优化经验和改进案例,这些内容对于整个大数据处理社区来说是宝贵的财富。
例如,Hadoop社区中就有针对Shuffle优化的多种方案,比如调整Shuffle buffer大小,优化磁盘I/O操作,甚至更改数据序列化方式以减少网络传输的数据量。
### 6.2.2 对未来Shuffle技术的预测与展望
随着计算需求的日益增长,Shuffle技术的未来发展方向将会是更快、更高效、更智能。机器学习和人工智能的应用可能会帮助预测数据处理需求,从而优化Shuffle过程。
对于开发者而言,利用机器学习技术来预测Shuffle负载,动态调整资源分配,将是一个值得探索的领域。
```python
# 示例代码:使用机器学习预测Shuffle负载
from sklearn.linear_model import LinearRegression
import numpy as np
# 模拟数据集
X = np.array([[1], [2], [3], [4], [5]]) # 资源使用情况
y = np.array([100, 200, 300, 400, 500]) # Shuffle负载数据
# 创建并训练模型
model = LinearRegression().fit(X, y)
```
通过这样的方法,我们可以预测出Shuffle操作对资源的需求,并据此合理分配计算资源,以达到性能优化的目的。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 MapReduce 中的 Shuffle 和排序过程,揭示了它们在提升大数据处理速度中的关键作用。通过一系列文章,作者提供了权威的见解和实用的技巧,指导读者优化 Shuffle 和排序,从而提高数据处理效率。从原理分析到性能提升策略,再到实战解决方案和案例研究,本专栏涵盖了 MapReduce Shuffle 和排序的各个方面,帮助读者掌握大数据处理的秘密,实现数据处理速度的飞跃提升。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Vue Select选择框数据监听秘籍:掌握数据流与$emit通信机制

# 摘要
本文深入探讨了Vue框架中Select组件的数据绑定和通信机制。从Vue Select组件与数据绑定的基础开始,文章逐步深入到Vue的数据响应机制,详细解析了响应式数据的初始化、依赖追踪,以及父子组件间的数据传递。第三章着重于Vue Select选择框的动态数据绑定,涵盖了高级用法、计算属性的优化,以及数据变化监听策略。第四章则专注于实现Vue Se
【操作秘籍】:施耐德APC GALAXY5000 UPS开关机与故障处理手册
# 摘要
本文对施耐德APC GALAXY5000 UPS进行全面介绍,涵盖了设备的概述、基本操作、故障诊断与处理、深入应用与高级管理,以及案例分析与用户经验分享。文章详细说明了UPS的开机、关机、常规检查、维护步骤及监控报警处理流程,同时提供了故障诊断基础、常见故障排除技巧和预防措施。此外,探讨了高级开关机功能、与其他系统的集成以及高级故障处理技术。最后,通过实际案例和用户经验交流,强调了该UPS在不同应用环境中的实用性和性能优化。
# 关键字
UPS;施耐德APC;基本操作;故障诊断;系统集成;案例分析
参考资源链接:[施耐德APC GALAXY5000 / 5500 UPS开关机步骤
wget自动化管理:编写脚本实现Linux软件包的批量下载与安装
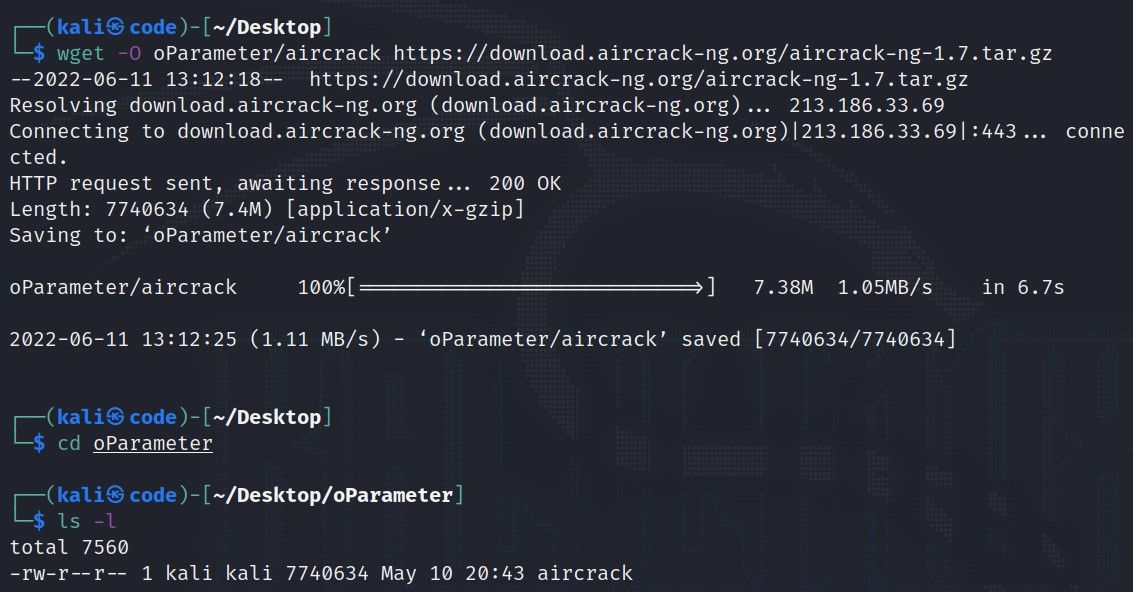
# 摘要
本文对wget工具的自动化管理进行了系统性论述,涵盖了wget的基本使用、工作原理、高级功能以及自动化脚本的编写、安装、优化和安全策略。首先介绍了wget的命令结构、选项参数和工作原理,包括支持的协议及重试机制。接着深入探讨了如何编写高效的自动化下载脚本,包括脚本结构设计、软件包信息解析、批量下载管理和错误
Java中数据结构的应用实例:深度解析与性能优化
# 摘要
本文全面探讨了Java数据结构的理论与实践应用,分析了线性数据结构、集合框架、以及数据结构与算法之间的关系。从基础的数组、链表到复杂的树、图结构,从基本的集合类到自定义集合的性能考量,文章详细介绍了各个数据结构在Java中的实现及其应用。同时,本文深入研究了数据结构在企业级应用中的实践,包括缓存机制、数据库索引和分布式系统中的挑战。文章还提出了Java性能优化的最佳实践,并展望了数据结构在大数据和人
SPiiPlus ACSPL+变量管理实战:提升效率的最佳实践案例分析

# 摘要
SPiiPlus ACSPL+是一种先进的控制系统编程语言,广泛应用于自动化和运动控制领域。本文首先概述了SPiiPlus ACSPL+的基本概念与变量管理基础,随后深入分析了变量类型与数据结构,并探讨了实现高效变量管理的策略。文章还通过实战技巧,讲解了变量监控、调试、性能优化和案例分析,同时涉及了高级应用,如动态内存管理、多线程变量同步以及面向对象的变
DVE基础入门:中文版用户手册的全面概览与实战技巧

# 摘要
本文旨在为初学者提供DVE(文档可视化编辑器)的入门指导和深入了解其高级功能。首先,概述了DVE的基础知识,包括用户界面布局和基本编辑操作,如文档的创建、保存、文本处理和格式排版。接着,本文探讨了DVE的高级功能,如图像处理、高级文本编辑技巧和特殊功能的使用。此外,还介绍了DVE的跨平台使用和协作功能,包括多用户协作编辑、跨平台兼容性以及与其他工具的整合。最后,通过
【Origin图表专业解析】:权威指南,坐标轴与图例隐藏_显示的实战技巧

# 摘要
本文系统地介绍了Origin软件中图表的创建、定制、交互功能以及性能优化,并通过多个案例分析展示了其在不同领域中的应用。首先,文章对Origin图表的基本概念、坐标轴和图例的显示与隐藏技巧进行了详细介绍,接着探讨了图表高级定制与性能优化的方法。文章第四章结合实战案例,深入分析了O
EPLAN Fluid团队协作利器:使用EPLAN Fluid提高设计与协作效率
# 摘要
EPLAN Fluid是一款专门针对流体工程设计的软件,它能够提供全面的设计解决方案,涵盖从基础概念到复杂项目的整个设计工作流程。本文从EPLAN Fluid的概述与基础讲起,详细阐述了设计工作流程中的配置优化、绘图工具使用、实时协作以及高级应用技巧,如自定义元件管理和自动化设计。第三章探讨了项目协作机制,包括数据管理、权限控制、跨部门沟通和工作流自定义。通过案例分析,文章深入讨论
【数据迁移无压力】:SGP.22_v2.0(RSP)中文版的平滑过渡策略

# 摘要
本文深入探讨了数据迁移的基础知识及其在实施SGP.22_v2.0(RSP)迁移时的关键实践。首先,
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )