趋势分析:识别时间序列中的长期趋势,预测未来
发布时间: 2024-08-21 23:48:37 阅读量: 73 订阅数: 31 

# 1. 时间序列分析基础
时间序列分析是一种处理和分析按时间顺序排列的数据的技术。它广泛应用于金融、经济、环境科学和医疗保健等领域。
时间序列数据通常具有时间依赖性,即一个时间点的数据值与之前的时间点相关。时间序列分析旨在识别和理解这种依赖性,以便预测未来趋势和做出明智的决策。
时间序列分析涉及以下关键步骤:
- 数据收集和预处理:收集相关数据并处理缺失值、异常值和时间对齐等问题。
- 趋势识别:使用移动平均、指数平滑和霍尔特-温特斯法等技术识别时间序列中的趋势和季节性模式。
- 预测:应用线性回归、ARMA 和 ARIMA 等方法对未来趋势进行预测。
# 2. 时间序列趋势识别技术
### 2.1 移动平均法
移动平均法是一种常用的时间序列趋势识别技术,它通过对时间序列中的数据点进行加权平均来平滑数据,从而消除噪声和随机波动,凸显出潜在的趋势。
#### 2.1.1 简单移动平均
简单移动平均(SMA)是最简单的移动平均方法,它对给定时间窗口内的所有数据点进行等权平均。
```python
def simple_moving_average(data, window_size):
"""
计算简单移动平均。
参数:
data:时间序列数据。
window_size:移动平均窗口的大小。
返回:
移动平均后的数据。
"""
return np.convolve(data, np.ones(window_size) / window_size, mode='valid')
```
**参数说明:**
* `data`:时间序列数据,通常为一维数组。
* `window_size`:移动平均窗口的大小,即要平均的连续数据点的数量。
**代码逻辑分析:**
该代码使用 `np.convolve` 函数执行卷积运算,将时间序列数据与一个单位权重窗口进行卷积。卷积操作的结果是移动平均后的数据,它将窗口内的所有数据点等权平均。
#### 2.1.2 指数移动平均
指数移动平均(EMA)是一种加权移动平均方法,它赋予最近的数据点更高的权重。这使得 EMA 对趋势变化更加敏感,并且能够更快速地适应数据中的变化。
```python
def exponential_moving_average(data, alpha):
"""
计算指数移动平均。
参数:
data:时间序列数据。
alpha:平滑系数,介于 0 和 1 之间。
返回:
指数移动平均后的数据。
"""
ema = [data[0]]
for i in range(1, len(data)):
ema.append(alpha * data[i] + (1 - alpha) * ema[i - 1])
return ema
```
**参数说明:**
* `data`:时间序列数据,通常为一维数组。
* `alpha`:平滑系数,介于 0 和 1 之间。它决定了最近数据点的权重。
**代码逻辑分析:**
该代码使用递归方法计算 EMA。它从第一个数据点开始,然后依次计算后续数据点的 EMA。每个 EMA 值都是当前数据点与前一个 EMA 值的加权平均,其中权重由 `alpha` 参数控制。
# 3.1 线性回归法
#### 3.1.1 一元线性回归
一元线性回归是一种用于预测一个因变量(目标变量)与一个自变量(预测变量)之间线性关系的统计方

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
时间序列分解方法专栏深入探讨了时间序列数据的分解技术,揭示了其作为预测模型秘密武器的强大力量。通过一系列标题,专栏全面介绍了时间序列分解的各个方面,从入门到精通预测模型构建。它揭示了数据背后的结构,包括季节性变化、残差波动和长期趋势。专栏强调了时间序列分解在提升预测准确性、识别异常值、数据可视化和机器学习特征工程中的关键作用。它还提供了从理论基础到实际应用的完整指南,涵盖了从业者的必备技能和最佳实践。通过深入了解时间序列分解,数据科学家和分析师可以掌握应对数据复杂性的有效策略,并提升其数据分析能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【笔记本性能飙升】:DDR4 SODIMM vs DDR4 DIMM,内存选择不再迷茫
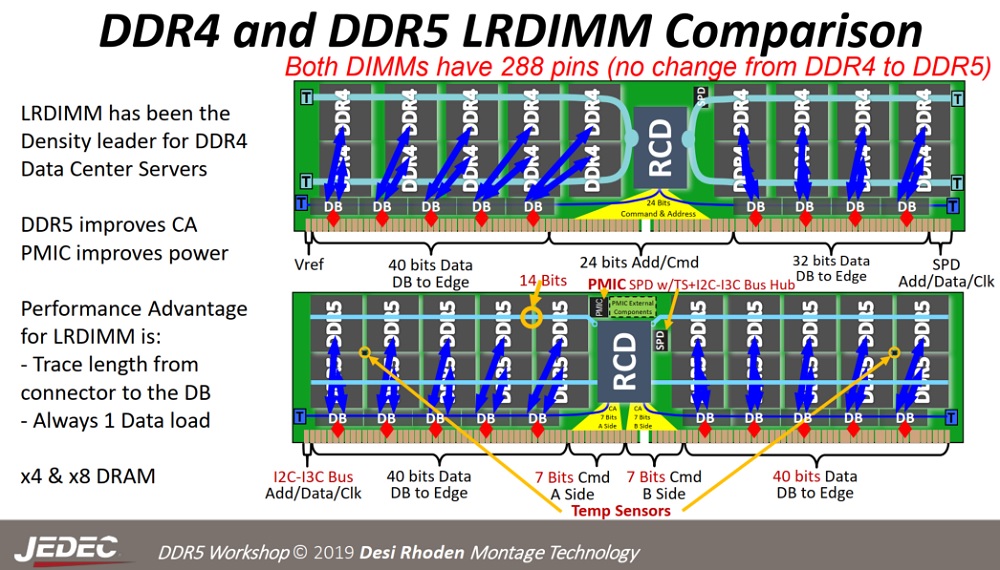
参考资源链接:[DDR4_SODIMM_SPEC.pdf](https://wenku.csdn.net/doc/6412b732be7fbd1778d496f2?spm=1055.2635.3001.10343)
# 1. 内存技术的演进与DDR4标准
## 1.1 内存技术的历史回顾
内存技术经历了从最
【防止过拟合】机器学习中的正则化技术:专家级策略揭露

参考资源链接:[《机器学习(周志华)》学习笔记.pdf](https://wenku.csdn.net/doc/6412b753be7fbd1778d49
【高级电路故障排除】:PIN_delay设置错误的诊断与修复,恢复系统稳定性
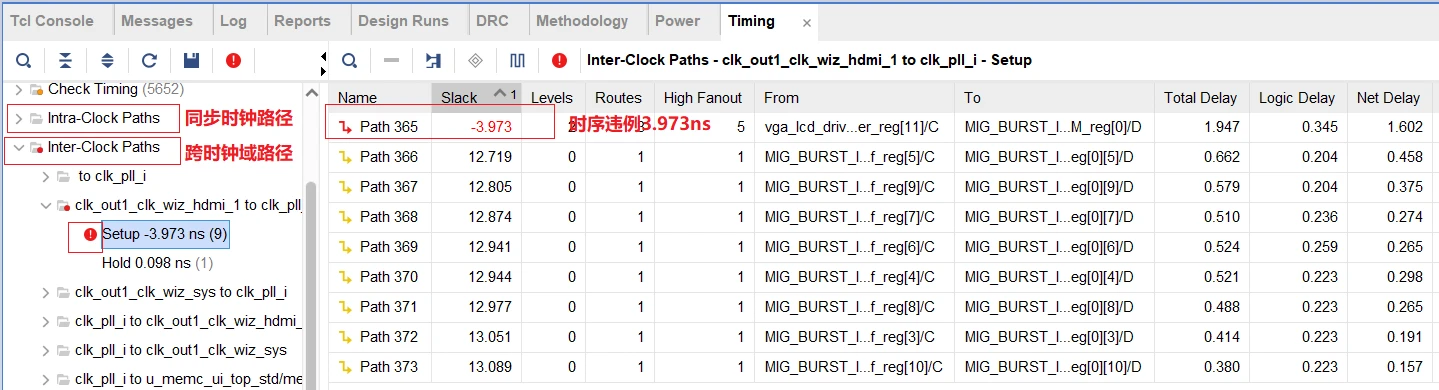
参考资源链接:[Allegro添加PIN_delay至高速信号的详细教程](https://wenku.csdn.net/doc/6412b6c8be7fbd1778d47f6b?spm=1055.2635.3001.10343)
# 1. PIN_delay设置的重要性与影响
在当今的IT和电子工程领域,PIN_delay参数的设置对于确保系统稳定性和
【GX Works3版本控制】:如何管理PLC程序的版本更新,避免混乱

参考资源链接:[三菱GX Works3编程手册:安全操作与应用指南](https://wenku.csdn.net/doc/645da0e195996c03ac442695?spm=1055.2635.3001.10343)
# 1. GX Works3版本控制概论
在PLC(可编程逻辑控制器)编程中,随着项目规模的增长和团队协作的复杂化,版本控制已经成为了一个不可或缺的工具。GX Wo
【GNSS高程数据处理坐标系统宝典】:选择与转换的专家指南

参考资源链接:[GnssLevelHight:高精度高程拟合工具](https://wenku.csdn.net/doc/6412b6bdbe7fbd1778d47cee?spm=1055.2635.3001.10343)
# 1. GNSS高程数据处理基础
在本章中,我们将探讨全球导航卫星系统(GNSS)高程数据处理的
【跨平台GBFF文件解析】:兼容性问题的终极解决方案

参考资源链接:[解读GBFF:GenBank数据的核心指南](https://wenku.csdn.net/doc/3cym1yyhqv?spm=1055.2635.3001.10343)
# 1. 跨平台文件解析的挑战与GBFF格式
跨平台应用在现代社会已经成为一种常态,这不仅仅表现在不同操作系统之间的兼容,还包括不同硬件平台以及网络环境。在文件解析这一层面,
STEP7 GSD文件安装:兼容性分析,确保不同操作系统下的正确安装
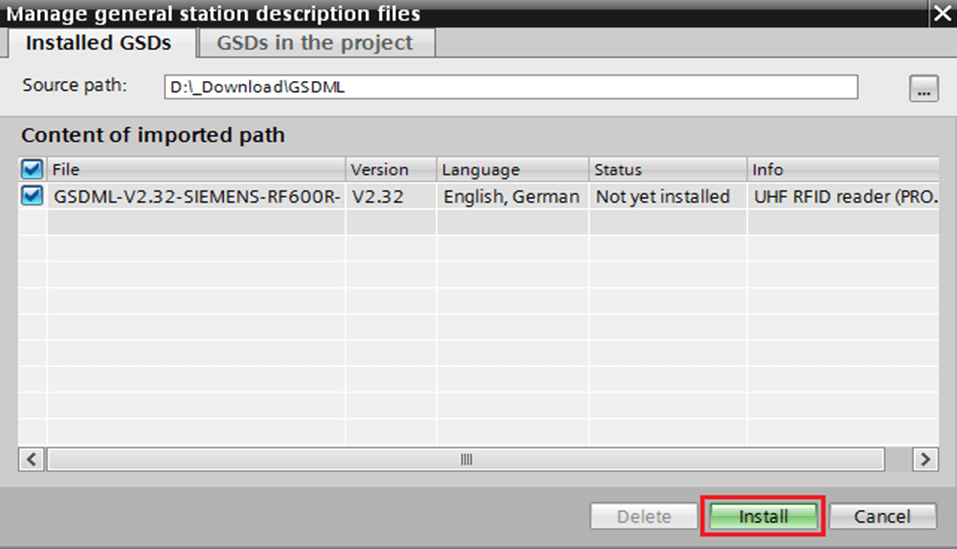
参考资源链接:[解决STEP7中GSD安装失败问题:解除引用后重装](https://wenku.csdn.net/doc/6412b5fdbe7fbd1778d451c0?spm=1055.2635.3001.10343)
# 1. STEP7 GSD文件简介
在自动化和工业控制系统领域,STEP7(也称为TIA Portal)是西门子广泛
【自定义宏故障处理】:发那科机器人灵活性与稳定性并存之道
参考资源链接:[发那科机器人SRVO-037(IMSTP)与PROF-017(从机断开)故障处理办法.docx](https://wenku.csdn.net/doc/6412b7a1be7fbd1778d4afd1?spm=1055.2635.3001.10343)
# 1. 发那科机器人自定义宏概述
自定义宏是发那科机器人编程中的一个强大工具,它允许用户通过参数化编程来简化重复性任务和复杂逻辑
台达PLC编程常见错误剖析:新手到专家的防错指南
参考资源链接:[台达PLC ST编程语言详解:从入门到精通](https://wenku.csdn.net/doc/6401ad1acce7214c316ee4d4?spm=1055.2635.3001.10343)
# 1. 台达PLC编程简介
台达PLC(Programmable Logic Controller)
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )