时间序列分解:提升预测模型准确性的关键步骤
发布时间: 2024-08-21 23:15:08 阅读量: 29 订阅数: 37 

白色简洁的艺术展示网页模板下载.zip

# 1. 时间序列分解概述**
时间序列分解是一种将时间序列数据分解为趋势、季节性和残差分量的技术。它有助于揭示数据中的模式和规律,为预测、优化和决策提供基础。时间序列分解在许多领域都有广泛的应用,包括金融、经济、气象和医疗保健。
分解过程涉及将原始时间序列拆分为三个主要分量:
* **趋势:**反映数据中长期变化的平滑趋势。
* **季节性:**代表数据中可预测的周期性模式,例如每周或每年。
* **残差:**包含数据中无法解释的随机波动和异常值。
# 2. 时间序列分解理论
时间序列分解是一种将时间序列分解为趋势、季节性和残差分量的技术。它有助于理解数据中的模式并为预测和建模提供基础。
### 2.1 分解方法:加性模型与乘性模型
时间序列分解可以使用加性模型或乘性模型。
**加性模型**假设时间序列分量之间是加性的,即:
```
Y = T + S + R
```
其中:
* Y:原始时间序列
* T:趋势分量
* S:季节性分量
* R:残差分量
**乘性模型**假设时间序列分量之间是乘性的,即:
```
Y = T * S * R
```
选择加性模型还是乘性模型取决于数据中分量的特性。一般来说,如果分量之间的变化幅度相似,则使用加性模型;如果分量之间的变化幅度不同,则使用乘性模型。
### 2.2 分解步骤:趋势、季节性、残差
时间序列分解通常遵循以下步骤:
1. **趋势分解:**提取数据中的长期趋势,它表示数据随着时间的总体变化。
2. **季节性分解:**识别和去除数据中的季节性模式,它表示数据在一年或其他周期内重复出现的波动。
3. **残差分析:**检查分解后的残差分量,以评估模型的拟合度和数据的平稳性。
通过这些步骤,时间序列分解可以揭示数据中的隐藏模式,为进一步的分析和预测提供基础。
# 3. 移动平均、指数平滑
**移动平均**
移动平均是一种用于平滑时间序列数据的简单方法。它通过计算特定时间窗口内数据的平均值来消除随机波动。
**步骤:**
1. 选择一个窗口大小 `w`。
2. 对于每个时间点 `t`,计算窗口内数据的平均值:
```python
MA_t = (x_t + x_{t-1} + ... + x_{t-w+1}) / w
```
**指数平滑**
指数平滑是一种更复杂的趋势分解方法,它考虑了最近数据的权重高于过去数据的权重。
**步骤:**
1. 初始化一个平滑系数 `α`,通常在 0 到 1 之间。
2. 对于每个时间点 `t`,计算平滑值:
```python
ES_t = α * x_t + (1 - α) * ES_{t-1}
```
**代码示例:**
```python
import pandas as pd
import numpy as np
# 数据
data = pd.read_csv('time_series.csv')
# 移动平均
window_size = 5
data['MA'] = data['value'].rolling(window_size
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
时间序列分解方法专栏深入探讨了时间序列数据的分解技术,揭示了其作为预测模型秘密武器的强大力量。通过一系列标题,专栏全面介绍了时间序列分解的各个方面,从入门到精通预测模型构建。它揭示了数据背后的结构,包括季节性变化、残差波动和长期趋势。专栏强调了时间序列分解在提升预测准确性、识别异常值、数据可视化和机器学习特征工程中的关键作用。它还提供了从理论基础到实际应用的完整指南,涵盖了从业者的必备技能和最佳实践。通过深入了解时间序列分解,数据科学家和分析师可以掌握应对数据复杂性的有效策略,并提升其数据分析能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
JLINK_V8固件烧录故障全解析:常见问题与快速解决

# 摘要
JLINK_V8作为一种常用的调试工具,其固件烧录过程对于嵌入式系统开发和维护至关重要。本文首先概述了JLINK_V8固件烧录的基础知识,包括工具的功能特点和安装配置流程。随后,文中详细阐述了烧录前的准备、具体步骤和烧录后的验证工作,以及在硬件连接、软件配置及烧录失败中可能遇到的常见问题和解决方案
【Jetson Nano 初识】:掌握边缘计算入门钥匙,开启新世界

# 摘要
本论文介绍了边缘计算的兴起与Jetson Nano这一设备的概况。通过对Jetson Nano的硬件架构进行深入分析,探讨了其核心组件、性能评估以及软硬件支持。同时,本文指导了如何搭建Jetson Nano的开发环境,并集成相关开发库与API。此外,还通过实际案例展示了Jetson Nano在边缘计算中的应用,包括实时图像和音频数
MyBatis-Plus QueryWrapper故障排除手册:解决常见查询问题的快速解决方案
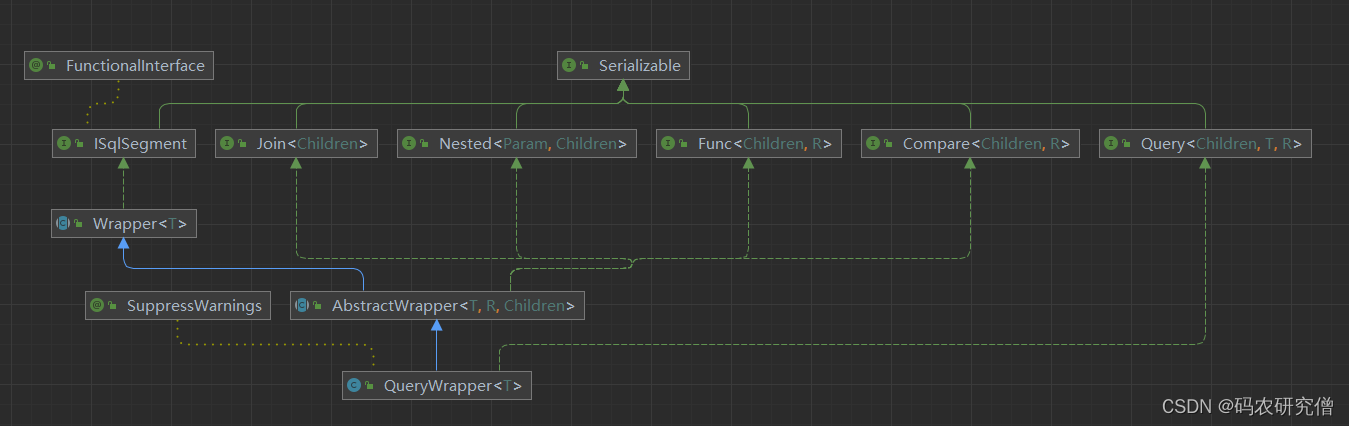
# 摘要
MyBatis-Plus作为一款流行的持久层框架,其提供的QueryWrapper工具极大地简化了数据库查询操作的复杂性。本文首先介绍了MyBatis-Plus和QueryWrapper的基本概念,然后深入解析了QueryWrapper的构建过程、关键方法以及高级特性。接着,文章探讨了在实际应用中查询常见问题的诊断与解决策略,以及在复杂场
【深入分析】SAP BW4HANA数据整合:ETL过程优化策略

# 摘要
SAP BW4HANA作为企业数据仓库的更新迭代版本,提供了改进的数据整合能力,特别是在ETL(抽取、转换、加载)流程方面。本文首先概述了SAP BW4HANA数据整合的基础知识,接着深入探讨了其ETL架构的特点以及集成方法论。在实践技巧方面,本文讨论了数据抽取、转换和加载过程中的优化技术和高级处理方法,以及性能调优策略。文章还着重讲述了ETL过
电子时钟硬件选型精要:嵌入式系统设计要点(硬件配置秘诀)

# 摘要
本文对嵌入式系统与电子时钟的设计和开发进行了综合分析,重点关注核心处理器的选择与评估、时钟显示技术的比较与组件选择、以及输入输出接口与外围设备的集成。首先,概述了嵌入式系统的基本概念和电子时钟的结构特点。接着,对处理器性能指标进行了评估,讨论了功耗管理和扩展性对系统效能和稳定性的重要性。在时钟显示方面,对比了不同显示技术的优劣,并探讨了显示模块设计和电源管理的优化策略。最后,本
【STM8L151电源设计揭秘】:稳定供电的不传之秘

# 摘要
本文对STM8L151微控制器的电源设计进行了全面的探讨,从理论基础到实践应用,再到高级技巧和案例分析,逐步深入。首先概述了STM8L151微控制器的特点和电源需求,随后介绍了电源设计的基础理论,包括电源转换效率和噪声滤波,以及STM8L151的具体电源需求。实践部分详细探讨了适合STM8L151的低压供电解决方案、电源管理策略和外围电源设计。最后,提供了电源设计的高级技巧,包括
NI_Vision视觉软件安装与配置:新手也能一步步轻松入门

# 摘要
本文系统介绍NI_Vision视觉软件的安装、基础操作、高级功能应用、项目案例分析以及未来展望。第一章提供了软件的概述,第二章详细描述了软件的安装流程及其后的配置与验证方法。第三章则深入探讨了NI_Vision的基础操作指南,包括界面布局、图像采集与处理,以及实际应用的演练。第四章着重于高级功能实
【VMware Workstation克隆与快照高效指南】:备份恢复一步到位

# 摘要
VMware Workstation的克隆和快照功能是虚拟化技术中的关键组成部分,对于提高IT环境的备份、恢复和维护效率起着至关重要的作用。本文全面介绍了虚拟机克隆和快照的原理、操作步骤、管理和高级应用,同时探讨了克隆与快照技术在企业备份与恢复中的应用,并对如何
【Cortex R52 TRM文档解读】:探索技术参考手册的奥秘
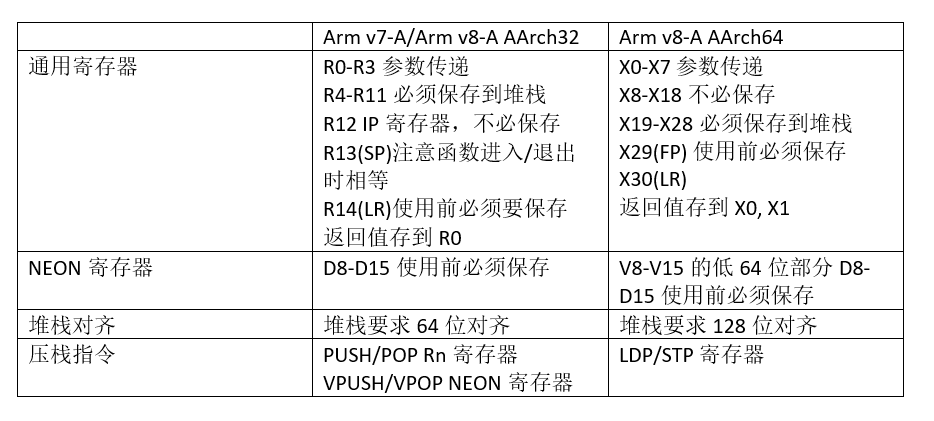
# 摘要
本文深入探讨了Cortex R52处理器的各个方面,包括其硬件架构、指令集、调试机制、性能分析以及系统集成与优化。文章首先概述了Cortex R52处理器的特点,并解析了其硬件架构的核心设计理念与组件。接着,本文详细解释了处理器的执行模式,内存管理机制,以及指令集的基础和高级特性。在调试与性能分析方面,文章介绍了Cortex R52的调试机制、性能监控技术和测试策略。最后,本文探讨了Cortex R52与外部组件的集成,实时操作系统支持,以及在特定应
西门子G120变频器安装与调试:权威工程师教你如何快速上手

# 摘要
西门子G120变频器在工业自动化领域广泛应用,其性能的稳定性与可靠性对于提高工业生产效率至关重要。本文首先概述了西门子G120变频器的基本原理和主要组件,然后详细介绍了安装前的准备工作,包括环境评估、所需工具和物料的准备。接下来,本文指导了硬件的安装步骤,强调了安装过程中的安全措施,并提供硬件诊断与故障排除的方法。此外,本文阐述了软件配置与调试的流程,包括控制面板操作、参数设置、调试技巧以及性能
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )