PyTorch CNN文本分类全程攻略:从数据到模型的转变
发布时间: 2024-12-11 14:47:43 阅读量: 10 订阅数: 11 

pytorch实现用CNN和LSTM对文本进行分类方式

# 1. PyTorch CNN文本分类概述
在当今数字化时代,自然语言处理(NLP)技术正变得日益重要。文本分类,作为NLP的一个核心应用领域,能够将文本数据自动分类到预定义的标签或类别中。随着深度学习的崛起,卷积神经网络(CNN)已经成为文本分类任务中的一种高效模型,尤其是PyTorch,这个具有动态计算图的深度学习框架,为开发者提供了强大的工具来构建和训练复杂的模型。在本章中,我们将概览PyTorch如何用于构建CNN进行文本分类,并简要介绍其背后的基本原理和优势。我们将为读者揭示通过PyTorch实现CNN文本分类的可能性,以及这一技术如何简化模型搭建和训练过程。随着章节的深入,我们将逐步揭开PyTorch在文本分类中的强大功能和实践技巧的神秘面纱。
# 2. PyTorch CNN文本分类理论基础
## 2.1 卷积神经网络(CNN)概念解析
### 2.1.1 CNN在文本分类中的作用
卷积神经网络(CNN)最初是为图像处理任务而设计的,它通过局部感知和权值共享的机制有效捕捉局部特征,随后通过层级结构组合局部特征形成全局信息。然而,CNN的应用不限于图像处理。在文本分类中,CNN也表现出了强大的特征提取能力,尽管文本数据和图像数据在形式上有所不同。
在处理文本数据时,每个单词或短语可视为一个“像素”。通过使用一维卷积核,CNN可以在文本序列上滑动,从而捕捉到局部的n-gram特征。举例来说,对于句子“我喜欢使用PyTorch进行文本分类”,一维卷积核可能捕捉到“使用PyTorch”这样的三词组合,这些组合对于分类任务来说可能具有重要意义。
### 2.1.2 CNN关键组件的理论基础
卷积层(Convolutional Layer)是CNN的基础,它负责在输入数据上执行卷积操作。卷积操作的核心是卷积核(或滤波器),它在输入数据上滑动,执行元素乘法后求和,从而得到新的特征图(Feature Map)。通过不同大小和形状的卷积核,CNN能够提取不同层次和抽象度的特征。
池化层(Pooling Layer)通常跟在卷积层之后,用来减少特征图的空间尺寸,降低计算复杂度,并且能够提取出更为重要的特征。常见的池化操作包括最大池化(Max Pooling)和平均池化(Average Pooling)。例如,最大池化操作会选择特征图中的最大值,这有助于提取出最显著的特征。
在PyTorch中,`nn.Conv2d`和`nn.MaxPool2d`是构建卷积层和池化层的常用类。这些层在文本分类的CNN模型中也以一维的形式使用,即`nn.Conv1d`和`nn.MaxPool1d`。
## 2.2 文本处理与向量化技术
### 2.2.1 文本向量化的方法论
文本向量化是自然语言处理中的关键步骤之一,它将文本数据转换为机器学习模型可以理解的数值形式。在文本分类任务中,向量化的主要目标是捕获文本中的语义信息,并将这些信息转换为数值向量。最常用的文本向量化方法包括:
- 词袋模型(Bag-of-Words, BoW):将文本表示为单词出现的频率向量,忽略了单词的顺序信息。
- TF-IDF(Term Frequency-Inverse Document Frequency):在BoW的基础上进一步赋予单词权重,降低常见词的影响,突出重要词的作用。
- Word Embeddings(词嵌入):通过训练学习,将单词映射到一个连续的向量空间中,每个单词由一个固定长度的向量表示,向量间可以捕获语义和句法关系。
### 2.2.2 常见的词嵌入技术
Word Embeddings是处理文本数据时常用的词嵌入技术,它将单词映射到高维空间中,保持了单词间的语义和句法关系。以下是几种常见的词嵌入模型:
- Word2Vec:由Google开发,通过神经网络模型学习单词的嵌入表示,主要有CBOW和Skip-gram两种架构。
- GloVe:全称Global Vectors for Word Representation,是一种基于全局词频统计的词嵌入方法。
- FastText:由Facebook开发,能够处理词的形态变化,并通过子词(subword)信息增强嵌入的表达能力。
PyTorch提供了`torch.nn.Embedding`层来实现这些词嵌入模型。在实践中,可以使用预训练好的嵌入向量或在特定数据集上训练自己的嵌入层。
## 2.3 文本分类任务的数据预处理
### 2.3.1 数据清洗和标注过程
数据预处理是构建高效文本分类模型的第一步。数据清洗包括去除噪声、去除停用词、词干提取和词形还原等。文本标注则是将文本数据转化为机器学习模型可以学习的格式,例如将文本标签转化为数字。
在实际操作中,数据清洗和标注过程可能会涉及到以下几个步骤:
- 分词(Tokenization):将句子分割成单独的单词或短语。
- 去除停用词:删除常见的无意义词汇,如“的”、“和”、“是”等。
- 标准化(Normalization):将所有词汇转换为统一的小写形式,并统一可能的变形。
- 词干提取(Stemming)或词形还原(Lemmatization):将词汇转换为其词根或基本形式。
### 2.3.2 文本预处理技术详解
文本预处理技术的深入理解对于提升模型性能至关重要。在文本分类任务中,预处理技术不仅包括了上述的基础步骤,还可能涉及到高级技术:
- 词嵌入预训练:使用Word2Vec、GloVe等预训练模型加载预训练词向量。
- 文本增强(Data Augmentation):通过技术手段增加数据的多样性和数量,以防止模型过拟合。
- 词频-逆文档频率(TF-IDF):对词袋模型进行权重调整,赋予高频词汇较小权重,赋予罕见词汇较大权重。
文本预处理通常在PyTorch中使用`torchtext`库来完成。该库提供了简洁的API,用于进行分词、构建词汇表、数据加载和预处理等操作。
例如,使用`torchtext`的`data`模块创建字段和迭代器的过程如下:
```python
import torch
from torchtext import data
from torchtext import datasets
TEXT = data.Field(lower=True, include_lengths=True)
LABEL = data.LabelField(dtype=torch.float)
train_data, test_data = datasets.IMDB.splits(TEXT, LABEL)
TEXT.build_vocab(train_data, max_size=25000, vectors="glove.6B.100d")
LABEL.build_vocab(train_data)
train_iter, test_iter = data.BucketIterator.splits(
(train_data, test_data),
batch_size=32,
device=device
)
```
在上述代码中,我们首先创建了`TEXT`和`LABEL`两个字段,分别用于处理文本和标签。随后,我们使用`torchtext`的内置方法加载IMDB电影评论数据集,并构建词汇表。我们还使用预训练的GloVe向量对词汇表进行初始化,这样模型就能够利用预训练的语义信息。最后,我们创建了数据迭代器来批量加载数据,供模型训练使用。
在实际项目中,文本预处理的细节可能更加复杂,但总体思路是确保输入数据的质量和一致性,以便模型能够学习到最有效的特征。
# 3. PyTorch CNN模型搭建实践
## 3.1 PyTorch框架的基本使用
### 3.1.1 PyTorch环境搭建和配置
PyTorch是由Facebook的AI研究团队开发的一个开源机器学习库,基于Python编程语言,并提供了一个强大的GPU加速的张量计算库。其设计理念是能够快速地实现研究原型到产品部署的过程。
首先,为了使用PyTorch进行深度学习项目的开发,我们需要在系统上进行环境配置。安装PyTorch可以按照以下步骤操作:
1. 访问PyTorch官方网站获取安装命令:https://pytorch.org/get-started/locally/
2. 根据自己的系统配置选择合适的命令。例如,如果你使用的是Linux系统,Python版本为3.8,CUDA为11.1,那么你可以选择相应的命令。
3. 使用以下命令进行安装:
```bash
pip3 install torch torchvision torchaudio
```
如果你使用的是CPU版本的PyTorch,则命令会稍有不同。
4. 安装完成后,我们可以使用Python进行验证:
```python
import torch
print(torch.__version__)
```
如果安装成功,上述代码会打印出PyTorch的版本号。
### 3.1.2 PyTorch中的数据处理管道
PyTorch提供了简洁而高效的数据处理管道,使得数据加载、转换和批处理变得异常方便。`torch.utils.data`模块中的`DataLoader`和`Dataset`类是两个核心组件。
- `Dataset`类代表了数据集,它负责存储数据样本及其相关信息,并实现`__len__`方法和`__getitem__`方法。
```python
class MyDataset(torch.utils.data.Dataset):
def __init__(self):
# 初始化数据集
pass
def __len__(self):
# 返回数据集的大小
pass
def __getitem__(self, idx):
# 根据索引返回数据集中的一个样本
pass
```
- `DataLoader`类用于将数据集包装成批处理、打乱数据以及加载数据到内存等功能。
```python
from torch.utils.data import DataLoader
my_dataset = MyDataset()
my_loader = DataLoader(dataset=my_dataset, batch_size=32, shuffle=True)
```
通过上述代码,我们创建了一个`DataLoader`对象,它会以32个样本为一个批次从`my_dataset`中加载数据,并在每个epoch开始时随机打乱数据。
## 3.2 构建CNN模型的步骤和技巧
### 3.2.1 CNN模型结构设计
构建一个有效的CNN模型需要对网络结构有深刻的理解。以下是一个简单的CNN模型构建示例:
```python
import torch.nn as nn
import torch.nn.functional as F
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏通过一系列深入浅出的文章,全面介绍了使用 PyTorch 实现卷积神经网络 (CNN) 的各个方面。从构建 CNN 模型的基础步骤到高级技巧和优化策略,该专栏提供了全面的指南。它涵盖了 CNN 的前向传播和反向传播、图像识别案例分析、性能优化、批量归一化、超参数调优、迁移学习、故障排除、激活函数选择、多 GPU 训练和损失函数优化。无论你是 CNN 初学者还是经验丰富的从业者,本专栏都能为你提供宝贵的见解和实用的技巧,帮助你构建和优化高效的 CNN 模型。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Windows CE 6.0新手速成】:一步到位的开发环境搭建攻略
# 摘要
本文全面介绍了Windows CE 6.0的操作系统,涵盖了从开发环境的搭建到基础操作与开发实践,再到设备驱动开发的入门知识以及系统部署与维护的详细步骤。首先,本文概述了Windows CE 6.0的基本概念,然后详细阐述了在不同硬件平台和软件工具上搭建开发环境的方法。接着,文章深入讲解了系统架构和核心组件的交互,基本编程实践,以及高级开发技
打造工业通信效率:FANUC机器人MODBUS TCP性能优化秘诀
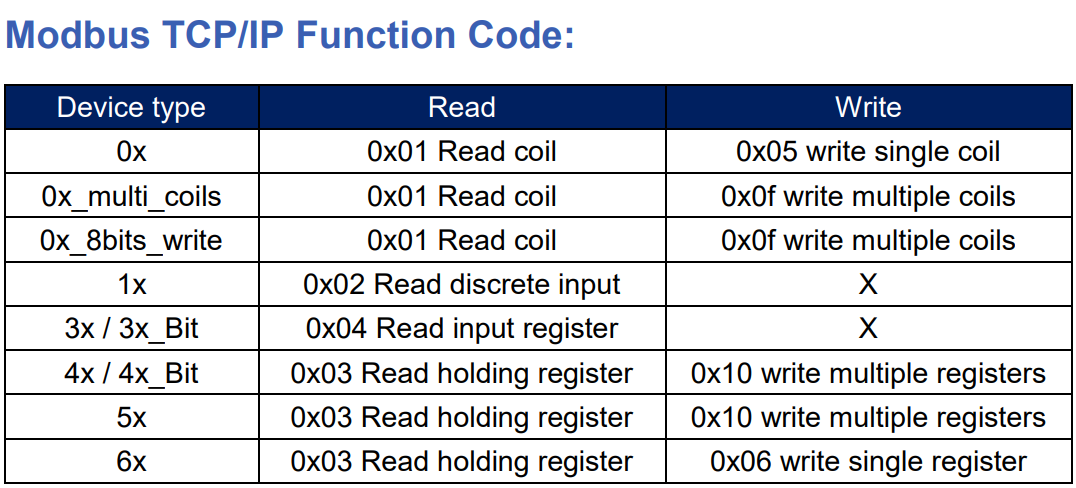
# 摘要
本论文综述了MODBUS TCP协议在FANUC机器人通信中的应用及其优化。首先概述了MODBUS TCP协议的基本原理和在工业通信中的重要性,特别是FANUC机器人在通信效率方面的作用。随后,详细分析了MODBUS TCP性能,包括理论基础、性能瓶颈识别以及评估方法。论文还探讨了优化策略,从硬件选择、配
深入解析:【Android SQLite数据库高效实践】,从创建到优化

# 摘要
随着Android应用开发的普及,SQLite作为一种轻量级的数据库系统,因其简洁高效而被广泛集成在移动设备中。本文从基础概念出发,详细介绍SQLite数据库的设计原理、数据操作、查询优化、安全机制以及高级应用编程。本文重点讨论了数据库的设计理论和创建实践,包括关系型数据库范式理论和SQL
数据库性能监控:5个关键指标让你快速定位性能瓶颈
# 摘要
数据库性能监控是确保数据管理高效和稳定的关键。本文首先概述了数据库性能监控的重要性和核心理论,重点分析了关键性能指标,例如响应时间、吞吐量和并发用户数,并讨论了它们的理论基础和提升方法。随后,文章深入探讨了事务处理性能、锁等待时间、死锁、缓存命中率等因素,并提出了相应的优化策略。第四章深入
【Sigrity SPB设计流程实战】:零基础到精通的转变
# 摘要
Sigrity SPB(Signal and Power Integrity Solution for PCB)是一款针对高速电路板设计的仿真分析工具。本文对Sigrity SPB的设计流程进行了概述,并深入探讨了其软件基础与界面布局、仿真与分析实践以及在PCB设计中的应用。文章详细阐述了软件环境搭建、信号和电源完整性的基本原理、项目设置与管理、仿真分析的关键技术,以及如何高效集成到PCB设计流程中并应用于
DIP2.0与健康数据标准化:升级医疗信息系统,实现从Excel到智能处理的飞跃

# 摘要
随着医疗信息技术的迅速发展,数据标准化成为提升医疗质量和效率的关键。DIP2.0作为最新的数据集成协议,旨在为医疗信息交换和共享提供统一标准,通过清晰的理论框架和实践应用,促进健康数据的规范化与安全保护。本文从DIP2.0概述开始,深入探讨了其在医疗领域的应用、标准化技术以及从传统Excel到智能处理技术的演进。文章详细分析了数据采集、预处理、分类
自动驾驶系统的u-blox M8030集成攻略:一步到位

# 摘要
本文介绍了自动驾驶技术中u-blox M8030模块的应用与集成过程。首先,概述了u-blox M8030的基本特性和硬件集成基础,包括其硬件组件、电源管理、信号处理、配置和系统集成。接着,阐述了软件集成与开发的关键环节,涵盖开发环境搭建、GPS信号处理、系统软件集成以及高级应用开发。文章重点探讨了自动驾驶系统中融合
【Arduino IDE主题自定义】:终极指南教你轻松打造个性化黑色主题

# 摘要
本文全面介绍了Arduino IDE主题自定义的入门知识、理论基础、实践步骤以及高级应用。从基础的IDE界面元素和主题机制,到主题定制的开发工具链和色彩理论,逐步深入探讨了自定义黑色主题的设计和实施过程。重点阐述了如何创建主题框架、编辑主题元素、添加图标与颜色,并进行了详细的测试与优化。文章还讨论了黑色主题的功能拓展,包括添
【工作效率倍增】:泛微OA流程优化的7大技巧
# 摘要
本文全面探讨了泛微OA系统的流程优化实践,从基础理论分析到具体应用技巧,深入阐述了提升办公自动化系统效率的途径。文章首先概述了流程优化的目标与原则,接着介绍了流程分析与标准化实施步骤。深入探讨了泛微OA系统功能的深度应用,包括自动化工具的使用、数据整合与用户体验的提升。实战技巧章节分享了流程模板设计、异常处理及团队协作的策略。案例分析章节通过成功案例和问题对策,评估流程优化的成效,并对
车载网络通信升级指南:TC8-WMShare与OPEN Alliance的完美协同
# 摘要
车载网络通信在现代汽车技术中扮演着关键角色,它保证了车辆各组件间高效、安全的信息交流。本文从车载网络通信的基础和重要性开始,详细解读了TC8-WMShare协议的原理、优势及与车辆网络的整合,并分析了OPEN Alliance标准的核心技术及其在车载网络中的应用。文中进一步探讨了TC8-WMShare与OPEN Alliance如何协同工作,以及如何实施有效的协同升级策略。最后,本文展望了车载网络通
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )