LSTM 模型在金融领域的实践应用
发布时间: 2024-05-01 23:11:15 阅读量: 12 订阅数: 42 

# 1. LSTM模型基础**
LSTM(长短期记忆网络)是一种循环神经网络(RNN),专门设计用于处理顺序数据。它通过引入记忆单元来克服传统RNN的梯度消失和梯度爆炸问题,使其能够学习长期依赖关系。
LSTM模型由一个输入门、一个遗忘门和一个输出门组成。输入门控制新信息的流入,遗忘门控制旧信息的遗忘,输出门控制输出信息的生成。这些门通过sigmoid激活函数来实现,范围为0到1,其中0表示完全关闭,1表示完全打开。
LSTM模型的记忆单元是一个状态向量,它保存着过去信息的摘要。在每个时间步,LSTM模型都会更新其状态向量,并根据当前输入和状态向量生成输出。这种机制使LSTM模型能够记住长期依赖关系,并对顺序数据进行有效的预测。
# 2. LSTM模型在金融领域的理论应用
### 2.1 LSTM模型在金融预测中的应用
#### 2.1.1 股票价格预测
**应用:**
LSTM模型可用于预测股票价格的未来趋势。通过分析历史价格数据,模型可以识别模式并预测未来的价格走势。
**操作步骤:**
1. 收集历史股票价格数据。
2. 预处理数据,包括归一化、平滑和特征工程。
3. 构建LSTM模型,设置超参数(如层数、隐藏单元数、学习率)。
4. 训练模型,使用历史数据训练LSTM模型预测未来价格。
5. 评估模型性能,使用指标(如均方根误差、平均绝对误差)评估模型预测的准确性。
**代码块:**
```python
import numpy as np
import pandas as pd
import tensorflow as tf
# 加载数据
data = pd.read_csv('stock_prices.csv')
# 预处理数据
data['Price'] = (data['Price'] - data['Price'].min()) / (data['Price'].max() - data['Price'].min())
# 构建LSTM模型
model = tf.keras.models.Sequential([
tf.keras.layers.LSTM(units=100, return_sequences=True, input_shape=(data.shape[1], 1)),
tf.keras.layers.LSTM(units=100),
tf.keras.layers.Dense(units=1)
])
# 训练模型
model.compile(optimizer='adam', loss='mean_squared_error')
model.fit(data[['Price']], data[['Price']], epochs=100)
# 预测未来价格
predictions = model.predict(data[['Price']])
```
**逻辑分析:**
* **加载数据:**从CSV文件中加载股票价格数据。
* **预处理数据:**归一化数据以将其缩放至0到1之间的范围,并删除异常值。
* **构建LSTM模型:**使用两个LSTM层和一个密集层构建LSTM模型。
* **训练模型:**使用均方根误差作为损失函数,使用Adam优化器训练模型。
* **预测未来价格:**使用训练后的模型预测未来股票价格。
#### 2.1.2 经济指标预测
**应用:**
LSTM模型还可用于预测经济指标,例如GDP、通胀和失业率。这些预测对于制定经济政策和投资决策至关重要。
**操作步骤:**
1. 收集历史经济指标数据。
2. 预处理数据,包括缺失值处理、平滑和特征工程。
3. 构建LSTM模型,设置超参数。
4. 训练模型,使用历史数据训练LSTM模型预测未来经济指标。
5. 评估模型性能,使用指标(如均方根误差、平均绝对误差)评估模型预测的准确性。
**代码块:**
```python
import numpy as np
import pandas as pd
import tensorflow as tf
# 加载数据
data = pd.read_csv('economic_indicators.csv')
# 预处理数据
data.fillna(data.mean(), inplace=True)
data = data.diff().dropna()
# 构建LSTM模型
model = tf.keras.models.Sequential([
tf.keras.layers.LSTM(units=100, return_sequences=True, input_shape=(data.shape[1], 1)),
tf.keras.layers.LSTM(units=100),
tf.keras.layers.Dense(units=1)
])
# 训练模型
model.compile(optimizer='adam', loss='mean_squared_error')
model.fit(data, data, epochs=100)
# 预测未来经济指标
predictions = model.predict(data)
```
**逻辑分析:**
* **加载数据:**从CSV文件中加载经济指标数据。
* **预处理数据:**处理缺失值、平滑数据并计算差分。
* **构建LSTM模型:**使用两个LSTM层和一个密集层构建LSTM模型。
* **训练模型:**使用均方根误差作为损失函数,使用Adam优化器训练模型。
* **预测未来经济指标:**使用训练后的模型预测未来经济指标。
### 2.2 LSTM模型在金融风险管理中的应用
#### 2.2.1 信用风险评估
**应用:**
LSTM模型可用于评估借款人的信用风险。通过分析借款人的历史信用数据,模型可以预测借款人违约的可能性。
**操作步骤:**
1. 收集借款人的历史信用数据,包括还款记录、信用评分和债务收入比。
2. 预处理数据,包括缺失值处理、特征工程和数据标准化。
3. 构建LSTM模型,设置超参数。
4. 训练模型,使用历史数据训练LSTM模型预测借款人违约的概率。
5. 评估模型性能,使用指标(如AUC、F1分数)评估模型预测的准确性。
**代码块:**
```python
import numpy as np
import pandas as pd
import tensorflow as tf
# 加载数据
data = pd.read_csv('credit_data.csv')
# 预处理数据
data.fillna(data.mean(), inplace=True)
data = data.drop(['ID'], axis=1)
data = (data - data.min()) / (data.max() - data.min())
# 构建LSTM模型
model = tf.keras.models.Sequential([
tf.keras.layers.LSTM(units=100, return_sequences=True, input_shape=(data.shape[1], 1)),
tf.keras.layers.LSTM(units=100),
tf.keras.layers.Dense(units=1, activation='sigmoid')
])
# 训练模型
model.compile(optimizer='adam', loss='binary_crossentropy')
model.fit(data, data['Default'], epochs=100)
# 预测违约概率
predictions = model.predict(data)
```
**逻辑分析:**
* **加载数据:**从CSV文件中加载信用数据。
* **预处理数据:**处理缺失值、删除ID列、标准化数据。
* **构建LSTM模型:**使用两个LSTM层和一个密集层构建LSTM模型。
* **训练模型:**使用二进制交叉熵作为损失函数,使用Adam优化器训练模型。
* **预测违约概率:**使用训练后的模型预测借款人违约的概率。
#### 2.2.2 市场风险评估
**应用:**
LSTM模型可用于评估市场风险,例如股票市场或外汇市场的波动性。通过分析历史市场数据,模型可以预测未来的市场走势和潜在的风险。
**操作步骤:**
1. 收集
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 赠618次下载
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏简介
《LSTM模型实战全面解析》专栏深入解析了LSTM模型的方方面面,包括模型介绍、原理、数据集选择、数据预处理、超参数调优、过拟合问题、特征工程、注意力机制、正向反向传播算法、情感分析、股票预测、文本生成、机器翻译、视频分析、推荐系统、与CNN和Transformer模型的比较、梯度消失问题、滞后效应、实时在线学习、图像描述生成、医疗应用、情景记忆、残差连接、多层堆叠、音乐生成、异常检测、生产环境部署等。该专栏旨在为读者提供全面的LSTM模型实战指南,帮助读者掌握LSTM模型的原理、应用和优化策略。
专栏目录
最低0.47元/天 解锁专栏
赠618次下载
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
Python字符串删除指定字符:与其他模块集成,拓展代码功能
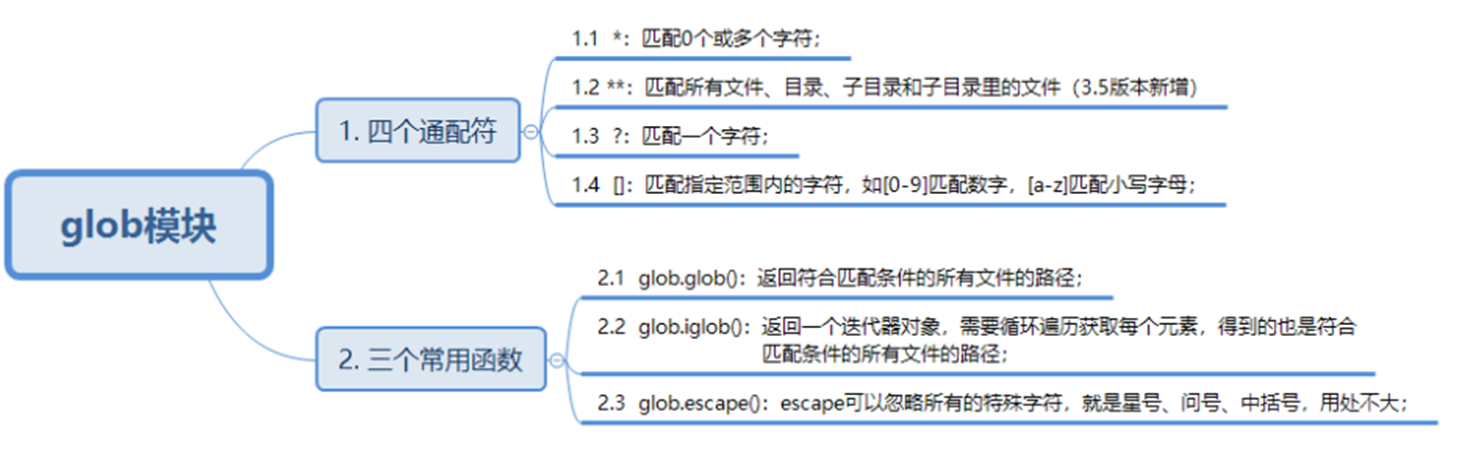
# 1. Python字符串删除指定字符的基础**
字符串是Python中一种基本数据类型,它由一系列字符组成。在某些情况下,我们需要从字符串中删除特定字符。Python提供了多种方法来实现这一目标,本章将介绍字符串删除指定字符的基础知识。
首先,我们可以使用`replace()`函数,它可以将字符串中的一个字符替换为另一个字符。例如,以下代码将字符串中的所有"a"字符
Python读取txt文件中的UTF-8数据:UTF-8数据处理,全球化数据处理

# 1. 基础与原理
UTF-8是一种广泛使用的字符编码,用于表示Unicode字符。它是一种变长编码,这意味着字符可以由不同数量的字节表示。UTF-8编码的第一个字节表示字符的长度,后面的字节表示字符的实际值。
在Python中,可以使用`open()`函数或`codecs`模块来读取UTF-8数据。`open()`函数的`encoding`参数可
Linux系统下MySQL数据库的事务处理:确保数据一致性,打造可靠数据库
# 1. 事务处理概述**
事务处理是数据库系统中一项至关重要的技术,它确保了数据库操作的原子性、一致性、隔离性和持久性(ACID)。事务是一个逻辑操作单元,它将一组相关操作组合在一起,作为一个整体执行。如果事务中的任何一个操作失败,则整个事务将回滚,数据库将恢复到事务开始前的状态。
事务处理的主要优点包括:
* **原子性:**事务中的所
PyCharm Python代码折叠指南:整理代码结构,提升可读性
# 1. PyCharm Python代码折叠概述
代码折叠是PyCharm中一项强大的功能,它允许开发者通过折叠代码块来隐藏不必要的信息,从而提高代码的可读性和可维护性。代码折叠可以应用于各种代码元素,包括函数、类、注释和导入语句。通过折叠代码,开发者可以专注于当前正在处理的代码部分,而不会被其他代码细节分心。
# 2. 代码折叠的理论基
Python enumerate函数与多进程组合:遍历序列的并行处理
# 1. Python enumerate 函数与多进程简介**
**1.1 Python enumerate 函数**
enumerate 函数用于遍历序列,同时返回元素的索引和元素本身。它接受一个可迭代对象作为参数,并返回一个包含元组的迭代器,
PyCharm中Python云集成:轻松部署和管理Python应用到云平台,拥抱云时代

# 1. Python云集成概述**
云集成是指将Python应用程序与云平台连接起来,以利用云计算的优势,如可扩展性、弹性和成本效益。Python云集成提供了一系列好处,包括:
- **可扩展性:**云平台可以根据需要自动扩展或缩小Python应用程序,以满足变化的工作负载
人工智能算法实战:从机器学习到深度学习,构建智能应用

# 1. 人工智能算法基础**
人工智能算法是计算机科学的一个分支,它旨在创建能够执行通常需要人类智能的任务的系统。人工智能算法通常基于数学和统计模型,这
Python执行Linux命令的最佳实践总结:提炼精华,指导实践,提升运维效率
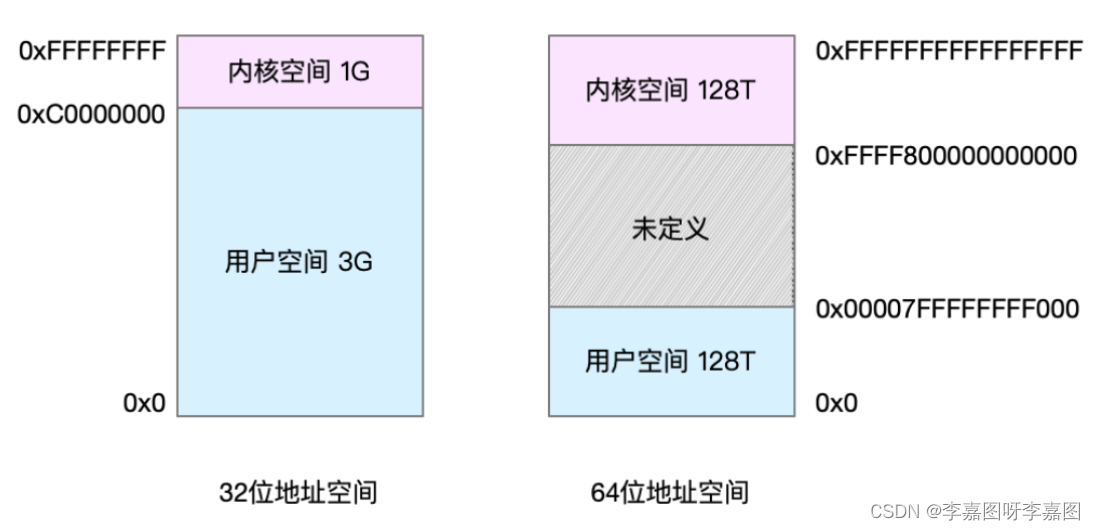
# 1. Python执行Linux命令的理论基础
在计算机科学中,执行Linux命令是自动化任务和管理系统的重要技术。Python作为一门高级编程语言,提供了丰富的库和函数,使开发者能够轻松地执行Linux命令。要理解Python执行Linux命令的原理,需要了解以下基本概念:
* **进程和线程:**进程是操作系统中的独立执行单元,而线程是进程中的轻量级执行单元。Pyth
TensorFlow安装与自动化测试实践:持续集成,确保质量

# 1. TensorFlow简介与安装
### 1.1 TensorFlow简介
TensorFlow是一个开源机器学习库,由谷歌开发,用于创建和训练神经网络模型。它提供了一组用于构建、训练和部署机器学习模型的高级API,使开发人员能够轻松地创建复杂的神经网络。
### 1.2 TensorFlow安装
TensorFlow支持多种平台,包括Windows、Linux和m
PyCharm安装Python:插件与扩展
# 1. PyCharm简介
PyCharm是一款功能强大的Python集成开发环境(IDE),由JetBrains开发。它为Python开发人员提供了全面的工具和功能,包括代码编辑、调试、测试、版本控制集成和代码分析。PyCharm因其用户友好性、可定制性和高效性而受到开发人员的欢迎。
PyCharm支持多种编程语言,包括Python、JavaScript、HTML、CSS和SQL。它还提供对各种框架和库的支
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
赠618次下载
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )