LSTM 模型在文本生成任务中的实践技巧
发布时间: 2024-05-01 23:00:43 阅读量: 8 订阅数: 27 

# 2.1 LSTM模型的文本生成原理
### 2.1.1 语言模型与生成式模型
**语言模型**是一种概率分布,它描述了给定一组单词的序列中下一个单词出现的概率。语言模型可以用来预测文本序列中的下一个单词,从而生成新的文本。
**生成式模型**是一种概率模型,它可以生成新的数据样本。LSTM模型是一种生成式模型,它可以生成文本序列。
### 2.1.2 LSTM模型的架构与原理
LSTM模型是一种循环神经网络(RNN),它专门设计用于处理序列数据。LSTM模型的架构包括一个输入层、一个隐藏层和一个输出层。
* **输入层**接收输入文本序列。
* **隐藏层**包含一个循环单元,它可以存储过去的信息。
* **输出层**生成下一个单词的概率分布。
LSTM模型的循环单元包含三个门:
* **输入门**:控制新信息的流入。
* **遗忘门**:控制过去信息的遗忘。
* **输出门**:控制输出信息的生成。
LSTM模型通过循环单元逐个处理输入文本序列,并生成下一个单词的概率分布。通过对概率分布进行采样,LSTM模型可以生成新的文本序列。
# 2. 文本生成中的LSTM模型应用
### 2.1 LSTM模型的文本生成原理
#### 2.1.1 语言模型与生成式模型
**语言模型**:给定一个文本序列的前缀,预测下一个词的概率分布。
**生成式模型**:从给定的概率分布中生成新的文本序列。
#### 2.1.2 LSTM模型的架构与原理
LSTM(Long Short-Term Memory)是一种循环神经网络,具有记忆长期依赖关系的能力。其架构包括:
* **输入门**:控制信息流入记忆单元。
* **忘记门**:控制信息从记忆单元流出。
* **输出门**:控制信息从记忆单元流出并输出。
* **记忆单元**:存储长期依赖关系。
LSTM模型通过循环处理输入序列,逐步更新记忆单元,并根据记忆单元生成输出。
### 2.2 LSTM模型在文本生成中的实践技巧
#### 2.2.1 数据预处理与特征工程
* **分词**:将文本分解为单词或字符。
* **向量化**:将单词或字符转换为数字向量。
* **序列截断**:将长序列截断为固定长度。
#### 2.2.2 模型训练与超参数优化
* **损失函数**:交叉熵损失函数。
* **优化器**:Adam优化器。
* **超参数优化**:使用网格搜索或贝叶斯优化。
#### 2.2.3 模型评估与结果分析
* **生成质量**:BLEU、ROUGE等指标。
* **多样性**:DIST-1、DIST-2等指标。
* **流畅性**:人类评估。
### 代码示例:文本生成LSTM模型
```python
import tensorflow as tf
class TextGeneratorLSTM(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, hidden_dim, num_layers):
super().__init__()
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.lstm = tf.keras.layers.LSTM(hidden_dim, return_sequences=True, num_layers=num_layers)
self.dense = tf.keras.layers.Dense(vocab_size)
def call(self, inputs):
x = self.embedding(inputs)
x = self.lstm(x)
x = self.dense(x)
return x
```
 最低0.47元/天 解锁专栏
最低0.47元/天 解锁专栏 VIP年卡限时特惠
 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐
专栏简介
《LSTM模型实战全面解析》专栏深入解析了LSTM模型的方方面面,包括模型介绍、原理、数据集选择、数据预处理、超参数调优、过拟合问题、特征工程、注意力机制、正向反向传播算法、情感分析、股票预测、文本生成、机器翻译、视频分析、推荐系统、与CNN和Transformer模型的比较、梯度消失问题、滞后效应、实时在线学习、图像描述生成、医疗应用、情景记忆、残差连接、多层堆叠、音乐生成、异常检测、生产环境部署等。该专栏旨在为读者提供全面的LSTM模型实战指南,帮助读者掌握LSTM模型的原理、应用和优化策略。
专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入了解MATLAB开根号的最新研究和应用:获取开根号领域的最新动态

# 1. MATLAB开根号的理论基础
开根号运算在数学和科学计算中无处不在。在MATLAB中,开根号可以通过多种函数实现,包括`sqrt()`和`nthroot()`。`sqrt()`函数用于计算正实数的平方根,而`nt
MATLAB符号数组:解析符号表达式,探索数学计算新维度

# 1. MATLAB 符号数组简介**
MATLAB 符号数组是一种强大的工具,用于处理符号表达式和执行符号计算。符号数组中的元素可以是符
MATLAB柱状图在信号处理中的应用:可视化信号特征和频谱分析

# 1. MATLAB柱状图概述**
MATLAB柱状图是一种图形化工具,用于可视化数据中不同类别或组的分布情况。它通过绘制垂直条形来表示每个类别或组中的数据值。柱状图在信号处理中广泛用于可视化信号特征和进行频谱分析。
柱状图的优点在于其简单易懂,能够直观地展示数据分布。在信号处理中,柱状图可以帮助工程师识别信号中的模式、趋势和异常情况,从而为信号分析和处理提供有价值的见解。
# 2. 柱状图在信号处理中的应用
柱状图在信号处理
MATLAB在图像处理中的应用:图像增强、目标检测和人脸识别
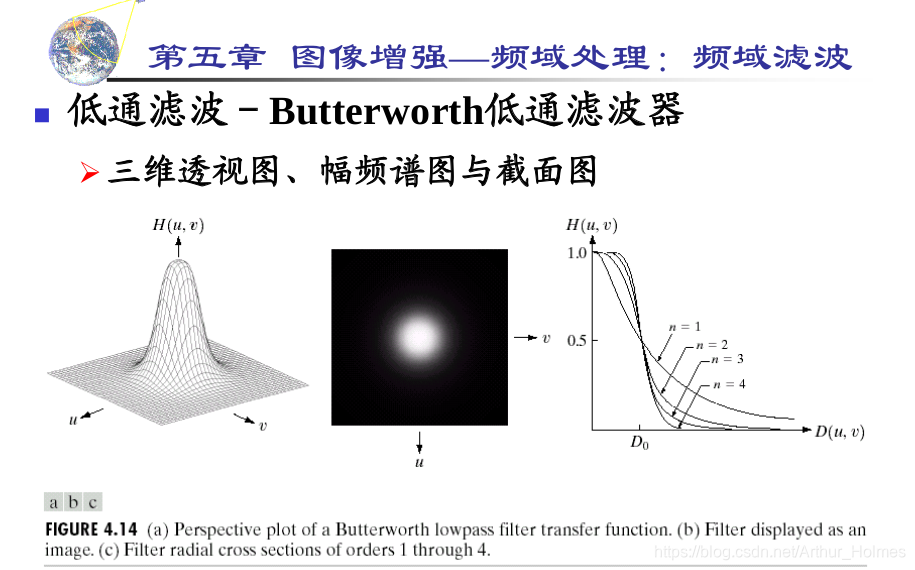
# 1. MATLAB图像处理概述
MATLAB是一个强大的技术计算平台,广泛应用于图像处理领域。它提供了一系列内置函数和工具箱,使工程师
MATLAB求平均值在社会科学研究中的作用:理解平均值在社会科学数据分析中的意义

# 1. 平均值在社会科学中的作用
平均值是社会科学研究中广泛使用的一种统计指标,它可以提供数据集的中心趋势信息。在社会科学中,平均值通常用于描述人口特
MATLAB字符串拼接与财务建模:在财务建模中使用字符串拼接,提升分析效率

# 1. MATLAB 字符串拼接基础**
字符串拼接是 MATLAB 中一项基本操作,用于将多个字符串连接成一个字符串。它在财务建模中有着广泛的应用,例如财务数据的拼接、财务公式的表示以及财务建模的自动化。
MATLAB 中有几种字符串拼接方法,包括 `+` 运算符、`strcat` 函数和 `sprintf` 函数。`+` 运算符是最简单的拼接
MATLAB散点图:使用散点图进行信号处理的5个步骤
# 1. MATLAB散点图简介
散点图是一种用于可视化两个变量之间关系的图表。它由一系列数据点组成,每个数据点代表一个数据对(x,y)。散点图可以揭示数据中的模式和趋势,并帮助研究人员和分析师理解变量之间的关系。
在MATLAB中,可以使用`scatter`函数绘制散点图。`scatter`函数接受两个向量作为输入:x向量和y向量。这些向量必须具有相同长度,并且每个元素对(x,y)表示一个数据点。例如,以下代码绘制
MATLAB平方根硬件加速探索:提升计算性能,拓展算法应用领域

# 1. MATLAB 平方根计算基础**
MATLAB 提供了 `sqrt()` 函数用于计算平方根。该函数接受一个实数或复数作为输入,并返回其平方根。`sqrt()` 函数在 MATLAB 中广泛用于各种科学和工程应用中,例如信号处理、图像处理和数值计算。
**代码块:**
```matlab
% 计算实数的平方根
x = 4;
sqrt_x = sqrt(x);
%
图像处理中的求和妙用:探索MATLAB求和在图像处理中的应用

# 1. 图像处理简介**
图像处理是利用计算机对图像进行各种操作,以改善图像质量或提取有用信息的技术。图像处理在各个领域都有广泛的应用,例如医学成像、遥感、工业检测和计算机视觉。
图像由像素组成,每个像素都有一个值,表示该像素的颜色或亮度。图像处理操作通常涉及对这些像素值进行数学运算,以达到增强、分
NoSQL数据库实战:MongoDB、Redis、Cassandra深入剖析
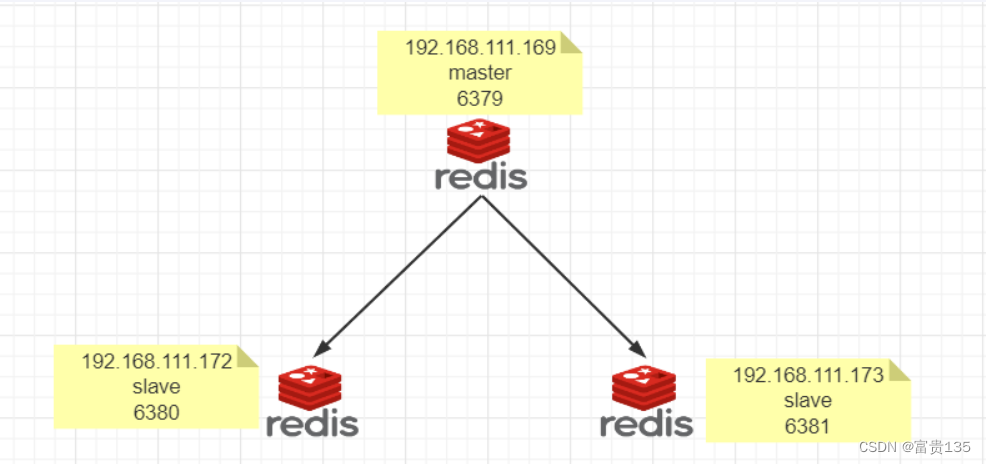
# 1. NoSQL数据库概述
**1.1 NoSQL数据库的定义**
NoSQL(Not Only SQL)数据库是一种非关系型数据库,它不遵循传统的SQL(结构化查询语言)范式。NoSQL数据库旨在处理大规模、非结构化或半结构化数据,并提供高可用性、可扩展性和灵活性。
**1.2 NoSQL数据库的类型**
NoSQL数据库根据其数据模型和存储方式分为以下
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
VIP年卡限时特惠
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )