cosh函数的渐近展开:理解函数在大值或小值时的行为,提升函数分析能力
发布时间: 2024-07-04 08:34:06 阅读量: 79 订阅数: 90 

基本初等函数图像 大全-专业指导文档类资源
# 1. cosh函数的定义和性质
cosh函数,又称双曲余弦函数,是双曲函数族中的一个重要函数。其定义为:
```
cosh(x) = (e^x + e^(-x)) / 2
```
cosh函数具有以下性质:
* 奇偶性:cosh函数是偶函数,即cosh(-x) = cosh(x)。
* 单调性:cosh函数在整个实数范围内单调递增。
* 范围:cosh函数的取值范围为[1, ∞)。
# 2. cosh函数的渐近展开
### 2.1 渐近展开的原理和方法
渐近展开是一种数学技术,用于将一个函数表示为一个无穷级数,该级数的每一项都包含一个函数的导数。当自变量趋于无穷大或无穷小时,渐近展开可以提供函数行为的渐近估计。
渐近展开的原理是基于泰勒展开,泰勒展开将一个函数表示为其在某一点处的导数的无穷级数。渐近展开与泰勒展开的区别在于,渐近展开的级数项包含自变量的幂次,而泰勒展开的级数项包含自变量与某一点之差的幂次。
### 2.2 cosh函数的渐近展开式
cosh函数的渐近展开式为:
```
cosh(x) ~ \frac{e^x}{2} + \frac{e^{-x}}{2} + \frac{e^x}{12x^2} - \frac{e^{-x}}{12x^2} - \frac{e^x}{360x^4} + \frac{e^{-x}}{360x^4} - \cdots
```
### 2.3 渐近展开式的应用
cosh函数的渐近展开式在以下方面有广泛的应用:
- **大自变量近似:**当自变量x很大时,渐近展开式的前面几项可以提供cosh(x)的良好近似值。
- **小自变量近似:**当自变量x很小时,渐近展开式的后面几项可以提供cosh(x)的良好近似值。
- **级数加速:**渐近展开式可以用来加速cosh(x)的收敛级数,例如泰勒级数。
- **积分近似:**渐近展开式可以用来近似cosh(x)的积分。
**代码示例:**
```python
import numpy as np
def cosh_approx(x, n):
"""
计算cosh(x)的渐近展开近似值。
参数:
x: 自变量
n: 展开项数
返回:
cosh(x)的渐近展开近似值
"""
approx = (np.exp(x) + np.exp(-x)) / 2
for i in range(1, n):
approx += (np.exp(x) - np.exp(-x)) / (2 * (2*i + 1) * x**(2*i))
return approx
x = 10
n = 5
print(f"cosh({x})的渐近展开近似值为:{cosh_approx(x, n)}")
```
**代码逻辑分析:**
* `cosh_approx`函数接受自变量x和展开项数n作为参数。
* 首先计算渐近展开式的前面两项,即cosh(x) = (e^x + e^-x) / 2。
* 然后使用一个循环添加渐近展开式的后续项,直到达到展开项数n。
* 最后返回渐近展开近似值。
# 3. cosh函数的应用
### 3.1 概率论中的应用
cosh函数在概率论中有着广泛的应用,特别是在正态分布和泊松分布的分析中。
**正态分布:**
正态分布的概率密度函数为:
```
f(x) = (1 / (σ√(2π))) * exp(-(x - μ)² / (2σ²))
```
其中,μ为均值,σ为标准差。
cosh函数可以通过以下方式应用于正态分布:
- **概率计算:**cosh函数可以用来计算正

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏全面解析了双曲余弦函数 (cosh),从其定义、导数、积分到图像和性质,深入探讨了其在信号处理、物理学、数学建模等领域的应用。专栏还介绍了 cosh 函数的泰勒级数展开、逆函数、复数域扩展、级数表示、积分表示、微分方程、渐近展开、数值计算、特殊值、极限与连续性、单调性和极值、奇偶性和周期性、拉普拉斯变换等高级概念。通过深入浅出的讲解和丰富的例题,专栏帮助读者掌握 cosh 函数的精髓,提升微积分、信号处理、物理学和数学建模能力。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【PX4飞行控制深度解析】:ECL EKF2算法全攻略及故障诊断
# 摘要
本文对PX4飞行控制系统中的ECL EKF2算法进行了全面的探讨。首先,介绍了EKF2算法的基本原理和数学模型,包括核心滤波器的架构和工作流程。接着,讨论了EKF2在传感器融合技术中的应用,以及在飞行不同阶段对算法配置与调试的重要性。文章还分析了EKF2算法在实际应用中可能遇到的故障诊断问题,并提供了相应的优化策略和性能提升方法。最后,探讨了EKF2算法与人工智能结合的前景、在新平台上的适应性优化,以及社区和开
【电子元件检验工具:精准度与可靠性的保证】:行业专家亲授实用技巧
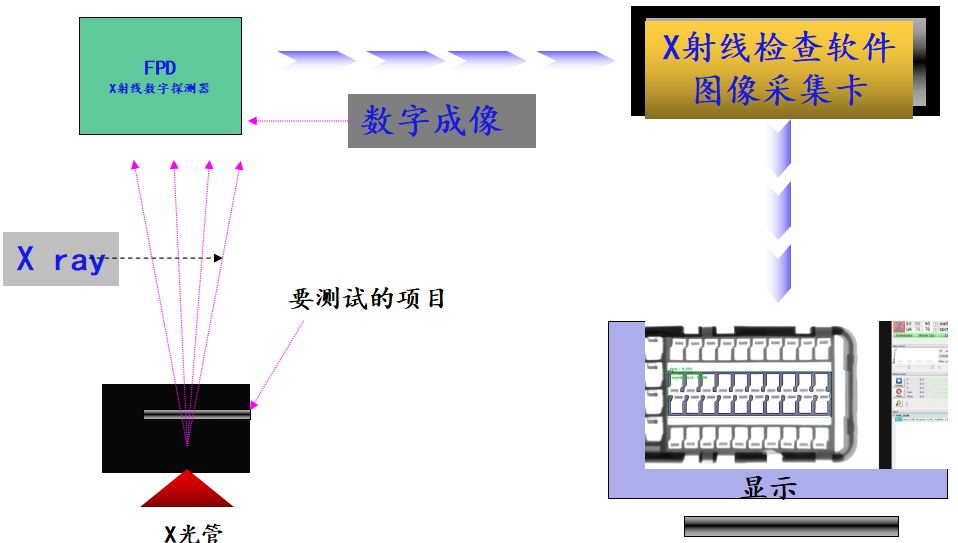
# 摘要
电子元件的检验在现代电子制造过程中扮演着至关重要的角色,确保了产品质量与性能的可靠性。本文系统地探讨了电子元件检验工具的重要性、基础理论、实践应用、精准度提升以及维护管理,并展望了未来技术的发展趋势。文章详细分析了电子元件检验的基本原则、参数性能指标、检验流程与标准,并提供了手动与自动化检测工具的实践操作指导。同时,重点阐述了校准、精确度提
Next.js状态管理:Redux到React Query的升级之路

# 摘要
本文全面探讨了Next.js应用中状态管理的不同方法,重点比较了Redux和React Query这两种技术的实践应用、迁移策略以及对项目性能的影响。通过详细分析Next.js状态管理的理论基础、实践案例,以及从Redux向React Query迁移的过程,本文为开发者提供了一套详细的升级和优化指南。同时,文章还预测了状态管理技术的未来趋势,并提出了最
【802.3BS-2017物理层详解】:如何应对高速以太网的新要求

# 摘要
随着互联网技术的快速发展,高速以太网成为现代网络通信的重要基础。本文对IEEE 802.3BS-2017标准进行了全面的概述,探讨了高速以太网物理层的理论基础、技术要求、硬件实现以及测试与验证。通过对物理层关键技术的解析,包括信号编码技术、传输介质、通道模型等,本文进一步分析了新标准下高速以太网的速率和距离要求,信号完整性与链路稳定性,并讨论了功耗和环境适应性问题。文章还介绍了802.3
【CD4046锁相环实战指南】:90度移相电路构建的最佳实践(快速入门)

# 摘要
本文对CD4046锁相环的基础原理、关键参数设计、仿真分析、实物搭建调试以及90度移相电路的应用实例进行了系统研究。首先介绍了锁相环的基本原理,随后详细探讨了影响其性能的关键参数和设计要点,包括相位噪声、锁定范围及VCO特性。此外,文章还涉及了如何利用仿真软件进行锁相环和90度移相电路的测试与分析。第四章阐述了CD
数据表分析入门:以YC1026为例,学习实用的分析方法

# 摘要
随着数据的日益增长,数据分析变得至关重要。本文首先强调数据表分析的重要性及其广泛应用,然后介绍了数据表的基础知识和YC1026数据集的特性。接下来,文章深入探讨数据清洗与预处理的技巧,包括处理缺失值和异常值,以及数据标准化和归一化的方法。第四章讨论了数据探索性分析方法,如描述性统计分析、数据分布可视化和相关性分析。第五章介绍了高级数据表分析技术,包括高级SQL查询
Linux进程管理精讲:实战解读100道笔试题,提升作业控制能力
# 摘要
Linux进程管理是操作系统核心功能之一,对于系统性能和稳定性至关重要。本文全面概述了Linux进程管理的基本概念、生命周期、状态管理、优先级调整、调度策略、进程通信与同步机制以及资源监控与管理。通过深入探讨进程创建、终止、控制和优先级分配,本文揭示了进程管理在Linux系统中的核心作用。同时,文章也强调了系统资源监控和限制的工具与技巧,以及进程间通信与同步的实现,为系统管理员和开
STM32F767IGT6外设扩展指南:硬件技巧助你增添新功能
# 摘要
本文全面介绍了STM32F767IGT6微控制器的硬件特点、外设扩展基础、电路设计技巧、软件驱动编程以及高级应用与性
【精密定位解决方案】:日鼎伺服驱动器DHE应用案例与技术要点

# 摘要
本文详细介绍了精密定位技术的概览,并深入探讨了日鼎伺服驱动器DHE的基本概念、技术参数、应用案例以及技术要点。首先,对精密定位技术进行了综述,随后详细解析了日鼎伺服驱动器DHE的工作原理、技术参数以及
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )