MATLAB Genetic Algorithm: A Deep Dive into Bio-inspired Heuristic Optimization Techniques
发布时间: 2024-09-14 20:46:47 阅读量: 22 订阅数: 42 

a-mazer-genetic-algorithm:使用遗传算法的A-Mazer求解器
# 1. Overview of MATLAB Genetic Algorithm
## 1.1 Introduction to Genetic Algorithms
Genetic algorithms are heuristic search algorithms that mimic the process of biological evolution in nature. They search for the optimal solution within candidate solutions through operations such as selection, crossover, and mutation. They are widely used in optimization and search fields due to their global search capabilities and low demands on the problem domain.
## 1.2 Genetic Algorithms in MATLAB
MATLAB offers a robust genetic algorithm toolbox that encapsulates a series of genetic algorithm functionalities. This allows researchers and engineers to quickly implement steps such as encoding, initialization, selection, crossover, and mutation of problems. It supports complex fitness function design and flexible parameter adjustments, helping users to easily carry out research and applications of genetic algorithms.
# 2. Theoretical Foundations of Genetic Algorithms
### 2.1 Origin and Definition of Genetic Algorithms
#### 2.1.1 Relationship Between Biological Evolution and Genetic Algorithms
Genetic algorithms (GAs) are search algorithms inspired by Darwin's theory of biological evolution. They simulate the genetic and natural selection mechanisms in the evolutionary process of organisms in nature. In biology, evolution refers to the phenomenon of gradual changes in the genetic characteristics of species over time, while natural selection is an important driver of the evolutionary process.
GAs use the principle of "survival of the fittest, elimination of the unfit" to iteratively search for the optimal or near-optimal solution within the given search space. The core idea of the algorithm is to start with an initial population (a set of possible solutions), and through operations such as selection, crossover (hybridization), and mutation, continuously generate a new generation of populations, with the expectation of iterating towards better solutions.
#### 2.1.2 Core Components and Characteristics of Genetic Algorithms
Genetic algorithms mainly consist of the following core components:
- **Encoding**: Representing the solution to a problem as a chromosome, usually in binary strings, but can also be in other forms such as integer strings, real number strings, or permutations.
- **Fitness Function**: Defines the individual's ability to adapt to the environment, which is the degree of goodness of a solution.
- **Initial Population**: A set of randomly generated solutions when the algorithm starts.
- **Selection**: Choosing superior individuals based on the fitness function to participate in the production of offspring.
- **Crossover**: Combining parts of two parent chromosomes to produce new offspring.
- **Mutation**: Randomly changing certain genes in the chromosome with a certain probability to maintain the diversity of the population.
- **Termination Condition**: Usually stops after a certain number of iterations or when the solutions in the population no longer show significant changes.
Characteristics of genetic algorithms include:
- **Global Search Capability**: It does not search along a single path but simultaneously explores multiple potential solutions.
- **Parallelism**: Since multiple individuals exist in the population simultaneously, genetic algorithms can perform parallel computation.
- **Information Utilization**: The algorithm does not require gradient information of the problem; it uses the fitness function to guide the search process.
- **Robustness**: The algorithm has good versatility for different types of problems and a certain tolerance for noise and uncertainty factors.
### 2.2 Operational Principles of Genetic Algorithms
#### 2.2.1 Coding Mechanism of Genetic Algorithms
In genetic algorithms, the coding mechanism is the process of mapping the solution to a problem onto the ***mon coding methods include:
- **Binary Coding**: The simplest coding method, applicable to various types of problems.
- **Integer Coding**: Suitable for discrete optimization problems, where each integer represents a parameter of the problem.
- **Real Number Coding**: For continuous optimization problems, real numbers can be used directly to represent solutions.
- **Permutation Coding**: Used when problems involve sequences or permutations, such as the Traveling Salesman Problem (TSP).
Choosing the correct coding mechanism is crucial for the performance of genetic algorithms and the quality of the final solution. Coding affects not only the representation of solutions and the implementation of crossover and mutation operations but also the search efficiency of the algorithm and the diversity of solutions.
#### 2.2.2 Analysis of Selection, Crossover, and Mutation Processes
Selection, crossover, and mutation are the three basic operations in genetic algorithms. They act on the individuals in the population, promoting the algorithm's evolution towards better solutions.
- **Selection**: ***mon selection methods include roulette wheel selection and tournament selection. Roulette wheel selection assigns selection probabilities to individuals based on their fitness, with higher fitness individuals having a greater chance of being selected. Tournament selection randomly selects a few individuals and then selects the best individual from them as the parent of the next generation.
```matlab
function selected = rouletteWheelSelection(fitnessValues, popSize)
% Normalization of fitness values
normalizedValues = fitnessValues / sum(fitnessValues);
% Cumulative probability
cumulativeProb = cumsum(normalizedValues);
% Roulette wheel selection
selected = zeros(1, popSize);
for i = 1:popSize
r = rand();
for j = 1:length(cumulativeProb)
if r <= cumulativeProb(j)
selected(i) = j;
break;
end
end
end
end
```
- **Crossover**: The crossove***mon crossover methods include single-point crossover, multi-point crossover, and uniform crossover. Single-point crossover selects a random crossover point and then exchanges the gene sequences of the two parents after that point. Single-point crossover is simple and easy to implement but may lead to information loss.
```matlab
function children = singlePointCrossover(parent1, parent2, crossoverRate)
% Determine whether to perform crossover based on crossover rate
if rand() < crossoverRate
crossoverPoint = randi(length(parent1) - 1);
child1 = [parent1(1:crossoverPoint), parent2(crossoverPoint+1:end)];
child2 = [parent2(1:crossoverPoint), parent1(crossoverPoint+1:end)];
children = [child1; child2];
else
children = [parent1; parent2];
end
end
```
- **Mutation**: The mutation operation maintains the diversity of the population and prev***mon mutation methods include basic site mutation and inversion mutation. Basic site mutation simply randomly changes the value of a gene locus, while inversion mutation randomly selects two gene loci and then exchanges the gene sequences between these two points.
```matlab
function mutated = basicMutation(individual, mutationRate)
mutated = individual;
for i = 1:length(individual)
if rand() < mutationRate
mutated(i) = randi([0, 1]); % Assuming binary coding
end
end
end
function mutated = inversionMutation(individual, inversionRate)
mutated = individual;
if rand() < inversionRate
inversionPoints = sort(randperm(length(individual), 2));
mutated(inversionPoints(1):inversionPoints(2)) = ...
mutated(inversionPoints(2):-1:inversionPoints(1));
end
end
```
#### 2.2.3 Termination Conditions and Convergence of Genetic ***
***mon termination conditions include:
- **Reaching the predetermined number of iterations**: The algorithm stops after executing the preset number of generations.
- **Fitness convergence**: The change in fitness among individuals in the population is very small, indicating that the algorithm has converged.
- **Reaching the predetermined solution quality**: The algorithm stops after finding a solution that meets specific quality requirements.
Convergence is an important indicator for evaluating the performance of genetic algorithms. It describes whether the algorithm can converge to the optimal solution within a reasonable time. A good genetic algorithm design should ensure the diversity of the population and the exploration ability of the algorithm, while quickly converging to high-quality solutions.
### 2.3 Key Technologies of Genetic Algorithms
#### 2.3.1 Design of Fitness Functions
The fitness function is the core of genetic algorithms, determining the probability of individuals being selected as parents. Designing an appropriate fitness function is crucial because a good fitness function can guide the algorithm towards the optimal or near-optimal solution in the search space.
- **Goal Consistency**: The design of the fitness function must be consistent with the goal of the problem and accurately reflect the quality of solutions.
- **Discriminability**: The function values should effectively distinguish the quality differences between different solutions.
- **Simplicity and Efficiency**: The calculation of fitness should not be too complex, or it will reduce the efficiency of the algorithm.
The design of the fitness function needs to be analyzed according to specific problems. Sometimes, penalty functions need to be introduced to handle constraints to ensure that the algorithm is not misled by infeasible solutions.
#### 2.3.2 Balancing Population Diversity and Selection Pressure
In genetic algorithms, population diversity is crucial for avoiding premature convergence (convergence to local optima rather than global optima). If individuals in the population are too similar, the algorithm may not be able to escape local optimum traps.
- **Diversity Maintenance**: Introduce diversity maintenance mechanisms, such as elitist retention strategies, mutation strategies, or diversity-promoting mechanisms.
- **Selection Pressure**: Selection pressure refers to the degree to which the algorithm tends to select individuals with higher fitness as parents. High selection pressure can lead to premature convergence, while low selection pressure may result in low algorithm search efficiency.
Balancing the population's diversity and selection pressure is a challenge in the design of genetic algorithms. This usually requires experience and multiple experiments to find the optimal balance point.
#### 2.3.3 Parameter Settings and Adjustments for Genetic Operations
The performance of genetic algorithms largely depends on the settings of its operational parameters, such as population size, crossover rate, and mutation rate.
- **Population Size**: A larger population can provide better exploration of the solution space, but it also increases computational costs.
- **Crossover Rate and Mutation Rate**: These two parameters need to be carefully adjusted to ensure the algorithm balances exploration and exploitation.
- **Crossover Rate**: A lower crossover rate can protect excellent gene combinations from being destroyed, while a higher crossover rate helps produce new gene combinations.
- **Mutation Rate**: A higher mutation rate can introduce new gene mutations and increase population diversity, but too high may destroy excellent gene combinations.
Parameter adjustment usually depends on specific problems and experimental results, and sometimes parameter self-adaptive techniques are needed to allow the algorithm to dynamically adjust parameters based on the current search situation.
```mermaid
graph LR
A[Problem Definition] --> B[Encoding Mechanism Design]
B --> C[Initial Population Generation]
C --> D[Selection Operation]
D --> E[Crossover Operation]
E --> F[Mutation Operation]
F --> G[Fitness Calculation]
G --> H[New Generation Population Formation]
H --> I[Terminal Condition Judgment]
I -->|Not Met| D
I -->|Met| J[Output of the Optimal Solution]
```
In this chapter, we have explored the theoretical foundations of genetic algorithms, including their origin and definition, operational principles, and key technical points. By understanding the encoding mechanism, selection, crossover, and mutation operations of genetic algorithms, as well as the design of fitness functions

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PyQt5界面布局全实战:QStackedLayout的高级应用秘籍
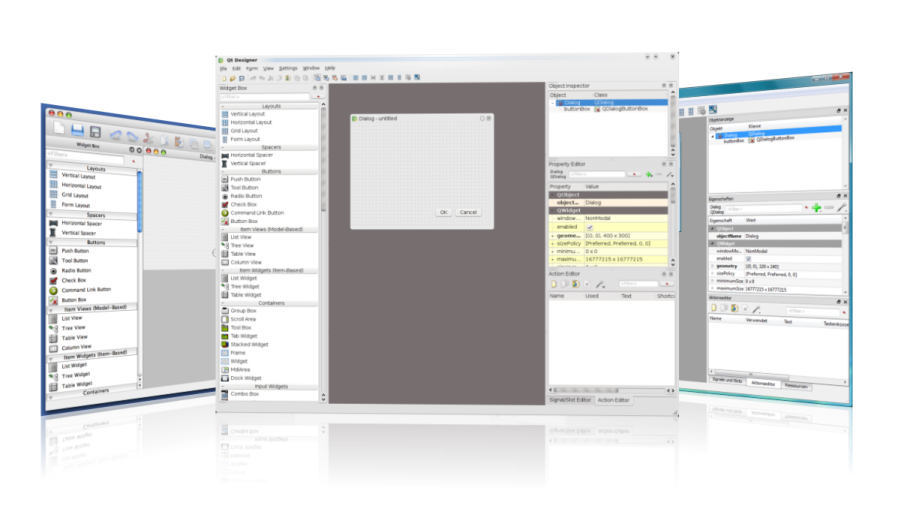
# 摘要
PyQt5的QStackedLayout是一种强大的界面布局管理工具,它允许开发者通过堆叠的方式管理多个界面元素,从而创建出具有多视图和动态交互的复杂应用程序。本文首先介绍了PyQt5和QStackedLayout的基础知识,随后深入探讨了QStackedLayout的布局原理、界面设计原则及高级特性。通过实战案例,本文展示了如何在具体项目中应用QStackedLayout,包括界
递归功能在MySQL中的扩展:自定义函数的全面解析
# 摘要
本文全面介绍了MySQL中的递归功能,从理论基础到实际应用,详细阐述了递归的概念、重要性以及递归模型的实现和性能考量。文章深入分析了自定义函数在MySQL中的实现方式,结合递归逻辑的设计原则和高级特性,为构建复杂的树状结构和图数据提供了具体的应用案例。同时,本文还探讨了递归功能的性能优化和安全维护的最佳实践,并对未来递归功能和自定义函数的发展趋势进行了展望。
# 关键字
MySQL;递归查询;自定义函数;性能优化;树状结构;图数据处理
参考资源链接:[MySQL自定义函数实现无限层级递归查询](https://wenku.csdn.net/doc/6412b537be7fbd17
日常监控与调整:提升 MATRIX加工中心性能的黄金法则
# 摘要
加工中心性能的提升对于制造业的效率和精度至关重要。本文首先介绍了监控与调整的重要性,并阐述了加工中心的基本监控原理,包括监控系统的分类和关键性能指标的识别。其次,文中探讨了提升性能的实践策略,涉及机床硬件升级、加工参数优化和软件层面的性能提升。本文还探讨了高级监控技术的应用,如自动化监控系统的集成、数据分析和与ERP系统的整合。案例研究部分深入分析了成功实施性能提升的策略与效果。最后,本文展望了加工中心技术的发展趋势,并提出创新思路,包括智能制造的影响、监控技术的新方向以及长期性能管理的策略。
# 关键字
加工中心性能;监控系统;性能优化;自动化监控;数据分析;智能制造
参考资源
【用户体验评测】:如何使用UXM量化5GNR网络性能

# 摘要
本文探讨了5GNR网络下的用户体验评测理论和实践,重点阐述了用户体验的多维度理解、5GNR关键技术对用户体验的影响,以及评测方法论。文章介绍了UXM工具的功能、特点及其在5GNR网络性能评测中的应用,并通过实际评测场景的搭建和评测流程的实施,深入分析了性能评测结果,识别性能瓶颈,并提出了优化建议。最后,探讨了网络性能优化策略、UXM评测工具的发展趋势以及5GNR网络技术的未来展望,强调了用户体验评测在5G
【Oracle 12c新功能】:升级前的必备功课,确保你不会错过

# 摘要
Oracle 12c作为一款先进的数据库管理系统,引入了多项创新功能来提升数据处理能力、优化性能以及增强安全性。本文从新功能概览开始,深度解析了其革新性的多租户架构、性能管理和安全审计方面的改进。通过对新架构(CDB/PDB)、自适应执行计划的优化和透明数据加密(TDE)等功能的详细剖析,展示了Oracle 12c如何
【数控车床维护关键】:马扎克MAZAK-QTN200的细节制胜法

# 摘要
本文全面介绍了马扎克MAZAK-QTN200数控车床的维护理论与实践。文章从数控车床的工作原理和维护基本原则讲起,强调了预防性维护和故障诊断的重要性。接着,文章深入探讨了日常维护、定期深度维护以及关键部件保养的具体流程和方法。在专项维护章节中,重点介绍了主轴、刀塔、进给系统、导轨以及传感器与测量系统的专项维护技术。最后
无人机航测数据融合与分析:掌握多源数据整合的秘诀
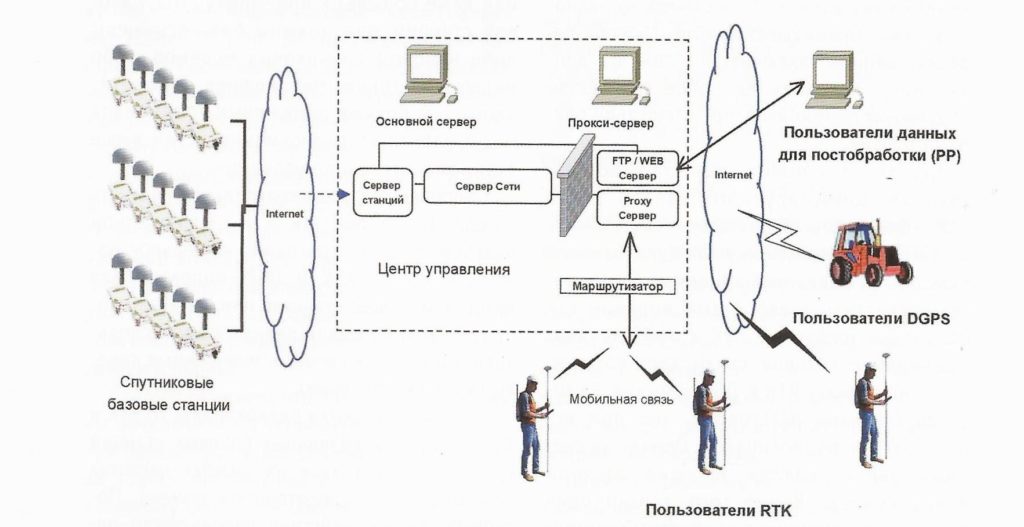
# 摘要
无人机航测数据融合与分析是遥感技术发展的关键领域,该技术能够整合多源数据,提高信息提取的精确度与应用价值。本文从理论基础出发,详述了数据融合技术的定义、分类及方法,以及多源数据的特性、处理方式和坐标系统的选择。进而,文章通过实践层面,探讨了无人机航测数据的预处理、标准化,融合算法的选择应用以及融合效果的评估与优化。此外,本文还介绍了一系列无人机航测数据分析方法,
【性能调优技巧】:Oracle塑性区体积计算实战篇
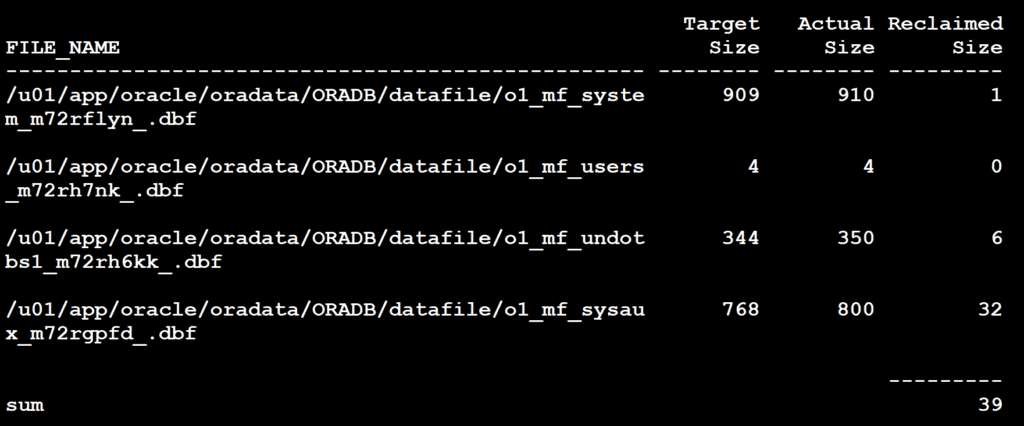
# 摘要
本论文详细探讨了Oracle数据库中塑性区体积计算的基础知识与高级调优技术。首先,介绍了塑性区体积计算的基本理论和实践方法,随后深入研究了Oracle性能调优的理论基础,包括系统资源监控和性能指标分析。文章重点论述了数据库设计、SQL性能优化、事务和锁管理的策略,以及内存管理优化、CPU和I/O资源调度技术。通过案例研究,本文分析了真实
现代测试方法:电气机械性能评估与质量保证,全面指南
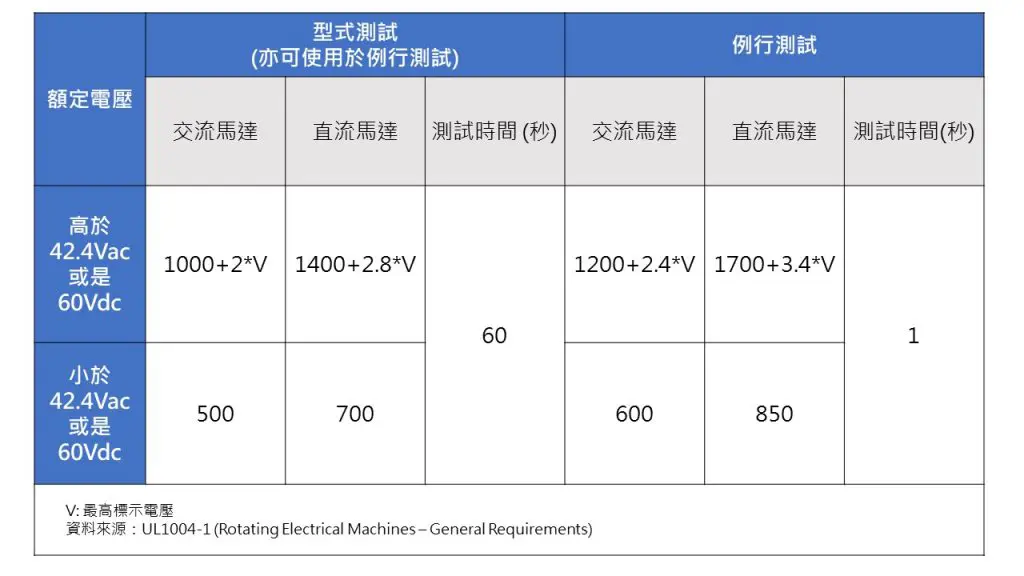
# 摘要
本文从电气机械性能评估的基础知识出发,详细探讨了电气性能与机械性能测试的方法与实践,包括理论基础、测试程序、以及案例分析。文章进一步阐述了电气与机械性能的联合评估理论框架及其重要性,并通过测试案例展示如何设计与执行联合性能测试,强调了数据采集与处理的关键性。最后,文章介绍了质量保证体系在电气机械评估中的应用,并探讨了质量改进策略与实施。通过对未来趋势的
软件工程可行性分析中的风险评估与管理

# 摘要
软件工程中的可行性分析和风险管理是确保项目成功的关键步骤。本文首先概述了软件工程可行性分析的基本概念,随后深入探讨风险评估的理论基础,包括风险的定义、分类、评估目标与原则,以及常用的风险识别方法和工具。接着,文章通过实际案例,分析了风险识别过程及其在软件工程项目中的实践操作,并探讨了风险评估技术的应用。此外,本文还讨论
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )