【Java高效回文检测秘籍】:掌握7个技巧与算法优化
发布时间: 2024-09-11 00:48:39 阅读量: 43 订阅数: 50 

Java中的“回文数”:探索其魅力与应用.pdf
# 1. 回文检测基础
## 1.1 回文的定义
在计算机科学中,回文是指一个字符串,正读和反读都是一样的,例如“雷达”、“上海自来水来自海上”。回文检测在文本处理、数据校验、网络通信等多个领域都有广泛的应用。了解回文的特性以及检测的基本方法是进行更高级算法研究的基础。
## 1.2 回文检测的重要性
回文检测不仅在字符串处理中有着基础性的作用,在软件开发的其他方面,如代码审计、bug查找、数据清洗等方面也有着重要的应用价值。掌握有效的回文检测方法能够显著提高工作效率,减少错误。
## 1.3 基本检测方法
最简单的回文检测方法是对字符串进行翻转,然后判断翻转后的字符串与原字符串是否相同。但这种方法在性能上并不是最优的,特别是对于长字符串的检测,将会产生较高的时间和空间成本。
```python
# 示例代码:简单的回文检测函数
def is_palindrome(s: str) -> bool:
return s == s[::-1]
# 调用示例
input_string = "madam"
print(is_palindrome(input_string)) # 输出:True
```
检测回文的方法随着对性能要求的提高而不断发展,下文将深入探讨经典回文检测算法及其优化。
# 2. 经典回文检测算法
### 2.1 简单的字符串反转检测法
#### 2.1.1 基本原理
字符串反转检测法是回文检测中最直观也是最简单的方法之一。其基本思想是将原始字符串进行反转,然后与原字符串进行比较。如果两者相同,则说明原字符串是一个回文。这种方法的直观性使其易于理解和实现,但它的时间复杂度较高,因为它需要创建一个新的字符串来完成反转,这在处理较长的字符串时会消耗较多的时间和空间。
#### 2.1.2 实现步骤与代码示例
以下是一个简单的Python代码示例,它展示了如何使用字符串反转检测法来判断一个字符串是否是回文:
```python
def is_palindrome_simple(s):
# 反转字符串
reversed_s = s[::-1]
# 比较反转后的字符串与原字符串
return s == reversed_s
# 测试代码
original_string = "racecar"
print(is_palindrome_simple(original_string)) # 输出: True
original_string = "example"
print(is_palindrome_simple(original_string)) # 输出: False
```
在这个代码示例中,我们使用了Python的切片操作`[::-1]`来反转字符串。这种方法简单,但它的时间复杂度是O(n),其中n是字符串的长度,因为需要创建一个长度与原字符串相同的反转字符串。
### 2.2 双指针技术
#### 2.2.1 指针技术的介绍
双指针技术是一种更加高效的回文检测方法。这种方法的核心思想是使用两个指针从字符串的两端向中心移动,逐渐缩小检查范围。这样可以避免创建新的字符串,从而提高算法的效率。这种方法的时间复杂度是O(n/2),即O(n),但因为它减少了不必要的内存分配,所以通常会比简单的字符串反转检测法更快。
#### 2.2.2 优化后的双指针回文检测算法
下面是一个优化后的双指针回文检测算法的Python代码示例:
```python
def is_palindrome_double_pointers(s):
left, right = 0, len(s) - 1
while left < right:
if s[left] != s[right]:
return False
left += 1
right -= 1
return True
# 测试代码
original_string = "racecar"
print(is_palindrome_double_pointers(original_string)) # 输出: True
original_string = "example"
print(is_palindrome_double_pointers(original_string)) # 输出: False
```
在这个示例中,`left`指针从字符串的起始位置开始,`right`指针从字符串的末尾开始。两个指针向中间移动,比较相应的字符。如果在任何时间点字符不匹配,则字符串不是回文,算法返回False。如果所有字符都匹配,则字符串是回文,算法返回True。
### 2.3 字符串比较法
#### 2.3.1 字符串比较法的原理
字符串比较法是一种基于两个子字符串比较的回文检测算法。该算法将原始字符串从中间分开,然后比较左右两个子字符串是否相等。如果它们相等,则说明原始字符串是回文。这种方法避免了反转整个字符串,从而提高了效率。
#### 2.3.2 算法实现与效率分析
以下是一个字符串比较法的Python代码示例:
```python
def is_palindrome_split_compare(s):
# 获取字符串的长度
length = len(s)
# 比较左右子字符串是否相等
return s[:length//2] == s[length//2 len(s)//2 - 1:-1] if length % 2 == 0 else s[:length//2] == s[length//2 + 1:]
# 测试代码
original_string = "racecar"
print(is_palindrome_split_compare(original_string)) # 输出: True
original_string = "example"
print(is_palindrome_split_compare(original_string)) # 输出: False
```
在上述代码中,我们利用了Python字符串的切片特性来获取左右子字符串。如果字符串长度是奇数,则中间的字符不需要被比较;如果长度是偶数,则比较从中间两个字符分隔开的子字符串。该算法的时间复杂度为O(n/2),因此比简单的字符串反转方法更高效。
### 2.4 分析与比较
回文检测算法的选择取决于具体的应用场景和性能要求。简单字符串反转检测法易于理解,但效率较低;双指针技术提供了更好的时间效率;而字符串比较法则在处理某些情况时更为高效。在选择算法时,开发者应考虑字符串的长度、可用资源以及对性能的具体要求。
# 3. 高级回文检测算法
高级回文检测算法不仅在理论上有其独特的地位,而且在实际应用中也展现出高效性和广泛适用性。本章将深入探讨Manacher算法、字符串哈希技术以及中心扩展法这三种高级算法,并通过实际代码示例和分析,揭示它们如何解决复杂数据结构中回文检测问题。
## 3.1 Manacher算法
Manacher算法是回文检测领域的经典算法之一。它以其线性的时间复杂度闻名,在处理包含大量回文的字符串时显示出惊人的效率。
### 3.1.1 Manacher算法的基本概念
Manacher算法将输入字符串中的每个字符看作是回文串的一部分,并通过引入一个虚拟字符(通常是'#')来填充字符串,消除奇偶长度回文之间的差别。在处理时,算法维护一个中心和一个半径的概念,以此来扩展并记录已知回文的信息。
### 3.1.2 算法流程与代码实现
Manacher算法的实现关键在于正确处理边界条件和有效管理已知回文的信息。以下是算法的核心步骤和代码实现:
- 初始化中心数组和半径数组。
- 遍历字符串,更新中心和半径。
- 根据左右边界调整中心和半径,避免无效的比较。
- 输出最长回文子串。
```python
def manacher(s):
# 处理特殊字符,添加'#'
t = '#'.join(f'^{s}$')
n = len(t)
p = [0] * n # p[i]表示以i为中心的回文半径
c = r = 0 # c是当前最右回文中心,r是对应的右边界
for i in range(1, n-1):
mirr = 2 * c - i # 计算i关于c的对称点mirr
if i < r:
p[i] = min(r - i, p[mirr])
# 尝试扩展回文
while t[i + (1 + p[i])] == t[i - (1 + p[i])]:
p[i] += 1
# 更新c和r
if i + p[i] > r:
c, r = i, i + p[i]
# 寻找最长回文
max_len, center_index = max((n, i) for i, n in enumerate(p))
start = (center_index - max_len) // 2
return s[start:start + max_len]
# 示例使用
s = "abbaeae"
print(manacher(s)) # 输出: abbaeae
```
在上述代码中,`manacher`函数是算法的核心实现,其逻辑分析和参数说明已经嵌入在注释中。函数首先构造了一个辅助字符串`t`,将原字符串`s`转换为一个带有特殊字符的奇数长度字符串。然后初始化中心数组`p`,遍历字符串`t`,逐步计算出每个位置的回文半径。最后,函数返回最长的回文子串。
## 3.2 字符串哈希技术
字符串哈希是一种利用哈希函数处理字符串问题的技术。在回文检测中,它可以帮助快速验证子串是否为回文。
### 3.2.1 字符串哈希的定义
字符串哈希通过为字符串的每个子串分配一个唯一的哈希值,实现快速比较。通常使用的是Rabin-Karp算法中的滚动哈希技术。
### 3.2.2 快速回文检测与验证
快速回文检测的关键在于构建哈希表,并利用哈希值来判断子串是否为回文。
```python
def precompute_hashes(s, p, base, mod):
n = len(s)
h = [0] * (n + 1)
h[0] = 0
for i in range(1, n + 1):
h[i] = (h[i-1] * base + ord(s[i - 1])) % mod
return h
def is_palindrome(s, start, end):
return s[start:end] == s[start:end][::-1]
def string_hash(s, start, end, base, mod, p):
return (hashes[end] - hashes[start] * pow(base, end - start, mod)) % mod
# 使用示例
s = "abccba"
base = 131
mod = 10**9 + 7
p = precompute_hashes(s, p, base, mod)
# 检测以s[i]为中心的回文
for i in range(len(s)):
# 奇数长度回文
odd_hash = string_hash(s, i, i + 1, base, mod, p)
if is_palindrome(s, i, i + 1) and odd_hash == 0:
print(f"奇数长度回文: {s[i:i+1]}")
# 偶数长度回文
even_hash = string_hash(s, i, i + 2, base, mod, p)
if is_palindrome(s, i, i + 2) and even_hash == 0:
print(f"偶数长度回文: {s[i:i+2]}")
```
在示例代码中,`precompute_hashes`函数预计算字符串`s`的所有子串的哈希值,而`string_hash`函数用于获取指定子串的哈希值。通过比较哈希值来快速判断子串是否为回文,避免了频繁的字符串比较。
## 3.3 中心扩展法
中心扩展法是另一种在实际中使用广泛的回文检测技术。它通过从字符串的每个可能的中心开始扩展,直到无法形成回文为止。
### 3.3.1 算法思路与原理
中心扩展法的基本思路是从每一个可能的中心开始,尽可能向两边扩展,直到找到回文子串为止。这种方法的中心可以是单个字符(处理奇数长度的回文)或字符对(处理偶数长度的回文)。
### 3.3.2 代码实现与性能分析
```python
def expand_around_center(s, left, right):
while left >= 0 and right < len(s) and s[left] == s[right]:
left -= 1
right += 1
return s[left + 1:right]
def longest_palindrome(s):
longest = ""
for i in range(len(s)):
# 奇数长度回文
p1 = expand_around_center(s, i, i)
if len(p1) > len(longest):
longest = p1
# 偶数长度回文
p2 = expand_around_center(s, i, i + 1)
if len(p2) > len(longest):
longest = p2
return longest
# 示例使用
s = "babad"
print(longest_palindrome(s)) # 输出: "bab" 或 "aba"
```
在上述代码中,`expand_around_center`函数用于从一个中心开始扩展,直到无法形成回文。`longest_palindrome`函数遍历整个字符串,使用`expand_around_center`来找出最长的回文子串。性能分析表明,中心扩展法的时间复杂度是O(n^2),适用于较短的字符串检测。
在本章节中,我们详细介绍了三种高级回文检测算法:Manacher算法、字符串哈希技术和中心扩展法。每种算法都有其独特的应用场景和性能特点,为不同的问题提供了高效的解决方案。通过实际代码示例和性能分析,我们揭示了它们在实际应用中的优势。这些高级算法不仅扩展了回文检测的边界,也为处理更复杂的字符串问题提供了有力的工具。
# 4. 实践中的回文检测优化
## 4.1 多场景回文检测应用
### 4.1.1 语言处理中的应用
在自然语言处理(NLP)中,回文检测可以应用于文本校对、语言模型训练等多个方面。例如,某些语言模型的训练数据集可能包含错误的回文,这些错误可以通过回文检测技术被识别和修正。在文本校对中,自动检测和标记潜在的回文错误可以提高文本的质量和准确性。
**实现步骤:**
1. **文本预处理:** 对输入的文本进行分词处理,去除无关字符。
2. **检测算法选取:** 根据文本长度和预处理后的结果,选择合适的回文检测算法。
3. **检测并标记:** 对每个单词或句子应用回文检测算法,如果检测到回文,则将其标记为错误。
4. **输出结果:** 将检测到的回文错误以及其上下文输出,供人工审核或自动修正。
**示例代码:**
```python
import re
def preprocess_text(text):
# 移除非字母字符并转换为小写
processed_text = re.sub(r'[^A-Za-z\s]', '', text).lower()
return processed_text
def detect_palindromes(text):
# 遍历文本中的每个单词
words = text.split()
palindromes = []
for word in words:
if word == word[::-1]: # 检测单词是否为回文
palindromes.append(word)
return palindromes
# 示例文本
text = "A man, a plan, a canal, Panama!"
processed_text = preprocess_text(text)
palindromes = detect_palindromes(processed_text)
print("Detected palindromes:", palindromes)
```
### 4.1.2 网络通信中的应用
在网络安全和数据传输中,回文检测可以用来检测数据包是否在传输过程中损坏。例如,可以将一个回文字符串作为数据包的一部分,接收方通过回文检测来验证数据包的完整性。
**实现步骤:**
1. **数据包构造:** 在构造数据包时,加入一个已知的回文字符串。
2. **数据包发送:** 将数据包通过网络发送到目标地址。
3. **回文检测:** 接收方收到数据包后,提取出回文字符串部分并进行检测。
4. **完整性验证:** 如果回文字符串检测正确,则说明数据包未损坏;反之,则需要请求重传数据包。
**示例代码:**
```python
def create_packet_with_palindrome(data):
# 构造数据包,加上回文字符串作为校验
palindrome = "level"
packet = data + palindrome
return packet
def verify_packet_integrity(packet):
# 检测数据包中的回文字符串是否正确
palindrome = "level"
return packet[-len(palindrome):] == palindrome
# 示例数据包
data = "***"
packet = create_packet_with_palindrome(data)
is_intact = verify_packet_integrity(packet)
print("Packet integrity:", "OK" if is_intact else "Damaged")
```
## 4.2 算法时间与空间复杂度分析
### 4.2.1 不同算法的时间复杂度对比
回文检测算法的不同实现对时间复杂度有着显著的影响。以字符串反转检测法、双指针技术和字符串比较法为例,时间复杂度通常为 O(n),其中 n 是字符串的长度。这些算法在平均情况下运行时间差别不大,但在最坏情况下可能会有不同表现。
**对比分析:**
- **字符串反转检测法:** 在最坏情况下时间复杂度为 O(n),因为需要对整个字符串进行反转操作。
- **双指针技术:** 通常时间复杂度为 O(n),因为它只需要两次遍历字符串,一次从头到尾,一次从尾到头。
- **字符串比较法:** 时间复杂度为 O(n),通过比较字符串的前后部分来检测。
### 4.2.2 空间复杂度考量与优化
空间复杂度在回文检测中同样重要,尤其是当处理非常长的字符串时。大多数传统算法的空间复杂度为 O(1),即它们不需要额外的存储空间。然而,某些情况下,算法可能需要额外的内存来存储中间结果。
**优化策略:**
- **就地操作:** 尽量使用就地操作来避免分配额外的内存。
- **数据类型选择:** 使用适当的数据类型可以减少内存占用。
- **批处理:** 对于大数据量的回文检测,可以采用批处理策略,分块处理数据以减少内存占用。
## 4.3 实际案例分析
### 4.3.1 大数据量回文检测策略
在处理大规模数据集时,单机的回文检测可能无法满足性能要求。这种情况下,可以采用分布式处理或并行计算的方法。
**分布式回文检测策略:**
1. **数据分片:** 将大规模数据集分片,每个计算节点处理一部分数据。
2. **并行检测:** 使用多个计算节点并行执行回文检测。
3. **结果汇总:** 各计算节点将检测结果汇总到主节点,进行最终的结果处理。
### 4.3.2 实际问题解决与代码优化实例
在面对实际问题时,通过代码优化可以大幅提升回文检测的性能。以下是一个实际优化的示例:
```python
def optimized_palindrome_detection(text):
# 使用双指针技术进行回文检测
left, right = 0, len(text) - 1
while left < right:
if text[left] != text[right]:
return False
left += 1
right -= 1
return True
# 示例文本
large_text = "A" * 10000 + "level" + "B" * 10000
print("Is palindrome in large text:", optimized_palindrome_detection(large_text))
```
通过使用双指针技术,该代码避免了字符串的额外复制和反转,提高了检测效率。对于大规模数据,可以在多个核心或节点上并行运行检测函数,以进一步提高性能。
# 5. 进阶技巧与未来展望
在本章中,我们将深入了解回文检测技术的进阶技巧,并对未来可能的发展趋势进行预测和探讨。本章将覆盖自动化测试与性能调优、多线程与并行处理的应用,以及人工智能和机器学习在回文检测中的潜力。
## 5.1 自动化测试与性能调优
回文检测算法的性能是衡量其应用效果的重要指标,因此自动化测试与性能调优对于确保算法稳定性和效率至关重要。
### 5.1.1 回文检测的自动化测试方法
自动化测试可以快速验证回文检测算法的正确性和性能指标。我们可以通过编写测试脚本来实现这一目标。
```python
import unittest
def is_palindrome(s):
return s == s[::-1]
class TestPalindrome(unittest.TestCase):
def test_palindromes(self):
self.assertTrue(is_palindrome("radar"))
self.assertTrue(is_palindrome("level"))
self.assertFalse(is_palindrome("hello"))
def test_non_palindromes(self):
self.assertFalse(is_palindrome("random"))
self.assertFalse(is_palindrome("world"))
if __name__ == '__main__':
unittest.main()
```
上面的代码使用Python的`unittest`框架创建了一个测试类`TestPalindrome`,其中包含了两个测试方法,分别用于测试回文和非回文字符串。
### 5.1.2 性能调优技巧与最佳实践
性能调优通常涉及算法优化和硬件加速。例如,可以使用更快的算法,或者在硬件层面使用更快的存储设备,如SSD而不是HDD,以及提高CPU的处理能力。
## 5.2 多线程与并行处理
多线程和并行处理可以显著提高回文检测的效率,特别是在处理大量数据时。
### 5.2.1 多线程回文检测的原理
多线程可以允许回文检测算法同时在多个数据集上运行,从而提高整体的处理速度。
```python
import threading
def check_palindrome(s, results):
results.append(is_palindrome(s))
threads = []
results = []
def create_threads(data_set):
for s in data_set:
t = threading.Thread(target=check_palindrome, args=(s, results))
threads.append(t)
t.start()
for t in threads:
t.join()
data = ["radar", "hello", "level", "world"]
create_threads(data)
print("Palindromes:", [s for s in data if results[data.index(s)]])
```
在这个示例中,我们使用Python的`threading`模块创建了多个线程,每个线程处理数据集中的一个字符串。
### 5.2.2 并行处理在回文检测中的应用
并行处理通过同时执行多个任务来提高效率。现代编程语言和框架都支持并行处理,比如Python的`concurrent.futures`模块。
```python
from concurrent.futures import ThreadPoolExecutor
data = ["radar", "hello", "level", "world"]
with ThreadPoolExecutor() as executor:
results = list(executor.map(is_palindrome, data))
print("Palindromes:", [s for s, r in zip(data, results) if r])
```
上面的代码展示了使用`ThreadPoolExecutor`进行并行处理,从而加快回文检测过程。
## 5.3 未来技术趋势预测
随着技术的发展,我们可以预见到回文检测的未来将融合更多先进的技术,如人工智能和机器学习。
### 5.3.1 新算法的可能发展方向
算法研究的未来方向可能会集中在自适应和学习型算法上。这类算法能够根据数据的特性自动调整处理策略,从而提高效率。
### 5.3.2 人工智能与机器学习在回文检测中的潜力探讨
人工智能和机器学习可以用来识别复杂的非标准回文结构。例如,深度学习模型可以训练识别特定领域的回文模式。
```python
from keras.models import Sequential
from keras.layers import Dense, LSTM
# 示例:LSTM模型的简单构建过程,实际应用中需要更多的数据和预处理
model = Sequential()
model.add(LSTM(50, input_shape=(timesteps, input_dim)))
model.add(Dense(1, activation='sigmoid'))
***pile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型...
```
在上面的代码示例中,我们创建了一个简单的LSTM模型,它可以用于学习和预测序列数据中的回文结构。当然,这只是一个简化的示例,实际应用中需要大量数据和复杂的数据预处理。
在本章中,我们探讨了回文检测技术的高级技巧,并对未来的可能趋势进行了展望。通过多线程和并行处理,我们可以提高算法效率;而人工智能和机器学习技术的应用将为回文检测带来新的可能性。随着技术的不断进步,我们可以期待更多的创新和突破。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 Java 中回文检测的各个方面,提供了全面的技术指南和实战技巧。从基础算法到高级数据结构,从时间复杂度分析到面试准备,涵盖了回文检测的方方面面。专栏中的文章介绍了 7 种高效技巧和算法优化,揭秘了字符串比较的技巧,分析了数据结构的选择和应用,深入理解了时间和空间复杂度,比较了递归和动态规划的优势,探索了 KMP 算法和双指针技术,掌握了回文字符串的生成艺术,提供了字符串相似度比较和高级数据结构的应用,并剖析了递归和动态规划的优化技术。本专栏旨在帮助 Java 开发人员全面掌握回文检测技术,提升代码效率和面试表现。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【PHPWord:自动化交叉引用与目录】:一键生成文档结构

# 摘要
本文详细介绍了PHPWord库在处理Word文档时的基础和高级功能,覆盖了从基础文档结构的概念到自动化文档功能的实现。文章首先阐述了PHPWord的基本使用,包括文档元素的创建与管理,如标题、段落、图片、表格、列表和脚注。随后,深入讨论了自动化交叉引用与目录生成的方法,以及如何在实际项目中运用P
伺服电机调试艺术:三菱MR-JE-A调整技巧全攻略

# 摘要
伺服电机在现代自动化和机器人技术中发挥着核心作用,其性能和稳定性对于整个系统的运行至关重要。本文从伺服电机的基础知识和调试概述开始,详细介绍了三菱MR-JE-A伺服驱动器的安装步骤、
深入STM32 PWM控制:5大策略教你高效实现波形调整
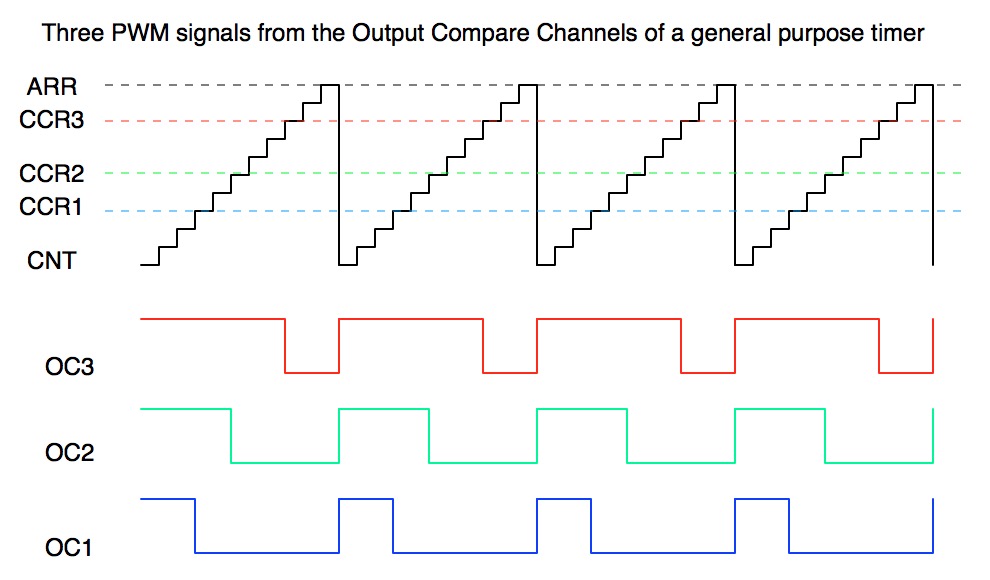
# 摘要
PWM(脉冲宽度调制)控制技术是微控制器应用中一种重要的信号处理方法,尤其在STM32微控制器上得到了广泛应用。本文首先概述了PWM控制的基本概念,介绍了PWM的工作原理、关键参数以及与微控制器的交互方式。接着,本文深入探讨了PWM波形调整的实践技巧,包括硬件定时器配置、软件算法应用,以及调试与优化的策略。文章进一步阐述了PWM控制在进阶应用中的表现,如多通道同步输出
版本控制基础深度解析:项目文档管理演进全攻略
# 摘要
版本控制作为软件开发过程中的核心组成部分,确保了代码的有序管理与团队协作的高效性。本文首先概述了版本控制的重要性,并对其理论基础进行了详细解析,包括核心概念的定义、基本术语、分类选择以及工作流程。随后,文章提供了针对Git、SVN和Mercurial等不同版本控制系统的基础操作指南,进一步深入到高级技巧与应用,如分支管理策
【Flac3D命令进阶技巧】:工作效率提升的7大秘诀,专家级工作流
# 摘要
本文详细探讨了Flac3D命令的高级功能及其在工程建模与分析中的应用。首先,文章介绍了Flac3D命令的基本与高级参数设置,强调了参数定义、使用和效果,以及调试和性能优化的重要性。其次,文章阐述了通过Flac3D命令建立和分析模型的过程,包括模型的建立、修改、分析和优化方法,特别是对于复杂模型的应用。第三部分深入探讨了Flac3D命令的脚本编程、自定义功能和集成应用,以及这些高级应用如何提高工作效率和分析准确性。最后,文章研究了Flac3D命令
【WPS与Office转换PDF实战】:全面提升转换效率及解决常见问题

# 摘要
本文综述了PDF转换技术及其应用实践,涵盖从WPS和Office软件内直接转换到使用第三方工具和自动化脚本的多种方法。文章不仅介绍了基本的转换原理和操作流程,还探讨了批量转换和高级功能的实现,同时关注转换
犯罪地图分析:ArcGIS核密度分析的进阶教程与实践案例

# 摘要
犯罪地图分析是利用地理信息系统(GIS)技术对犯罪数据进行空间分析和可视化的重要方法,它有助于执法机构更有效地理解犯罪模式和分布。本文首先介绍了犯罪地图分析的理论基础及其重要性,然后深入探讨了ArcGIS中的核密度分析技术,包括核密度估计的理论框架、工具操作以及高级设置。随后,文章通过实践应用,展现了如何准备数据、进行核密度分析并应用于实际案例研究中。在此基础上,进一
【Tetgen实用技巧】:提升你的网格生成效率,精通复杂模型处理

# 摘要
Tetgen是一款功能强大的网格生成软件,广泛应用于各类工程和科研领域。本文首先介绍了Tetgen的基本概念、安装配置方法,进而解析了其核心概念,包括网格生成的基础理论、输入输出格式、主要功能模块等。随后,文章提供了提升Tetgen网格生成效率的实用技巧,以及处理复杂模型的策略和高级功能应用。此外,本文还探讨了Tetgen在有限元分析、计算
【MOSFET开关特性】:Fairchild技术如何通过节点分布律优化性能
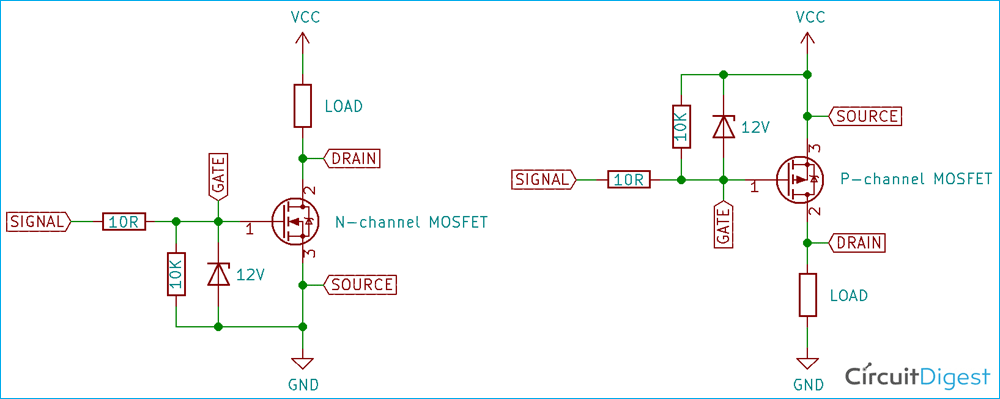
# 摘要
本文深入探讨了MOSFET开关特性的基础理论及其在Fairchild技术中的应用,重点分析了节点分布律在优化MOSFET性能中的作用,包括理论基础和实现方法。通过对比Fairchild技术下的性能数据和实际应用案例研究,本文揭示了节点分布律如何有效提升MOSFET的开关速度与降低功耗。最后,本文展望了MOS
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )