图算法在Python中的精讲:深度与广度优先搜索原理及应用
发布时间: 2024-09-09 20:20:24 阅读量: 146 订阅数: 48 

python基础编程:python实现树的深度优先遍历与广度优先遍历详解
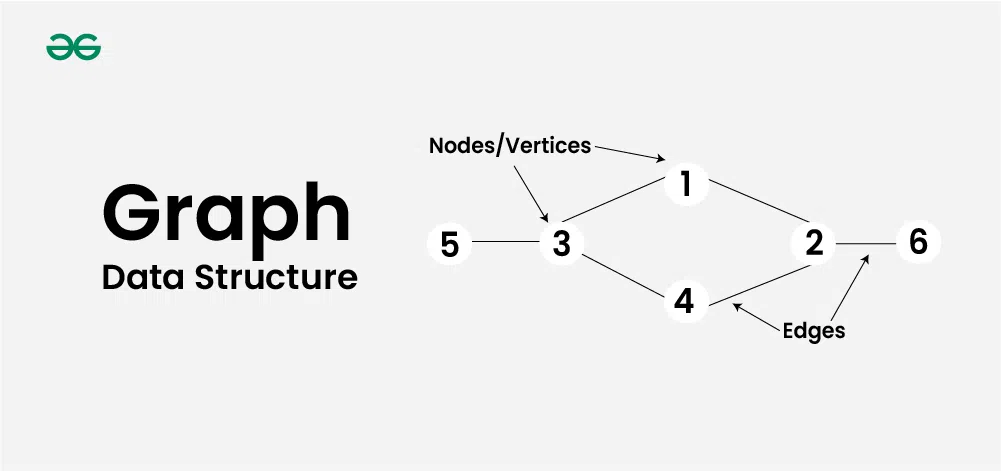
# 1. 图算法基础
图作为计算机科学中的一种基础数据结构,广泛应用于解决实际问题。它由一系列节点(或称为顶点)和连接这些节点的边组成。理解图算法的基本概念,是掌握更高级算法如深度优先搜索(DFS)和广度优先搜索(BFS)的前提。
## 1.1 图的基本概念
图可以是无向的,也可以是有向的,根据边的特性可进一步分类为加权或非加权图。无向图中,节点间的连接是双向的;有向图中,边则具有方向性,连接从一个节点指向另一个节点。
在图论中,路径是指一系列顶点和连接它们的边。如果一个顶点序列中每对相邻顶点之间都存在边,则称这个序列是一个简单路径。环是路径的一种特殊情况,其起点和终点是同一个顶点。
## 1.2 图的表示方法
图可以通过多种方式表示,常见的有邻接矩阵和邻接表:
- 邻接矩阵是一个二维数组,每行每列分别代表一个顶点,其元素表示顶点之间的连接关系(有连接则为1,无连接则为0)。
- 邻接表是一个数组和链表的组合,每个索引位置对应一个顶点,其链表存储了所有与该顶点直接相连的顶点。
在实际应用中,选择哪种表示方法取决于图的大小和图的稀疏程度。
通过下一章节的深度优先搜索(DFS)和广度优先搜索(BFS),我们将深入探讨图的遍历和搜索策略。
# 2. 深度优先搜索(DFS)理论与实现
## 2.1 深度优先搜索的基本概念
### 2.1.1 图的遍历与搜索
在深入探讨深度优先搜索(DFS)算法之前,我们需要了解图遍历的基本概念。图是一种数据结构,由一组顶点(nodes)以及连接这些顶点的边(edges)组成。在计算机科学中,图用于表示复杂的网络关系,如社交网络、网页链接、运输网络等。
图的搜索算法主要任务是访问图中的每一个顶点,确保每个顶点仅被访问一次。图搜索算法分为两大类:深度优先搜索(DFS)和广度优先搜索(BFS)。DFS 从初始顶点开始,探索尽可能远离初始顶点的分支,直到该分支的末端,然后回溯并探索其他分支。
### 2.1.2 深度优先搜索的工作原理
深度优先搜索通过递归或栈的数据结构来实现。在DFS中,算法会尽可能沿着图的分支深入,直到达到最深的节点,然后开始回溯。每次访问一个新的节点时,DFS会检查该节点的所有未访问的邻居,并对其中一个邻居进行递归调用。
使用递归实现DFS时,算法将从一个初始节点开始,并且每遇到一个新节点,就将其相邻的未访问节点放入递归调用堆栈。非递归实现则使用显式的栈来保存将要访问的节点。
## 2.2 深度优先搜索的算法实现
### 2.2.1 递归实现DFS
以下是使用Python编写的DFS递归实现的一个简单例子:
```python
# 假设图以邻接表形式存储,graph是一个字典,键是节点,值是相邻节点的列表。
graph = {
'A': ['B', 'C'],
'B': ['D', 'E'],
'C': ['F'],
'D': [],
'E': ['F'],
'F': []
}
# 使用全局变量来跟踪访问过的节点
visited = set()
def dfs(visited, graph, node): # 传入已访问节点集合、图、当前节点
if node not in visited:
print(node)
visited.add(node)
for neighbour in graph[node]:
dfs(visited, graph, neighbour)
# 调用函数
dfs(visited, graph, 'A')
```
这段代码将输出从节点 'A' 开始的DFS遍历序列。
### 2.2.2 非递归实现DFS与栈的使用
使用显式栈的DFS实现与递归实现类似,但避免了函数调用的开销。以下是使用栈实现DFS的Python代码示例:
```python
def dfs_iterative(graph, start):
visited = set()
stack = [start]
while stack:
vertex = stack.pop() # 弹出栈顶元素
if vertex not in visited:
print(vertex)
visited.add(vertex)
stack.extend(reversed(graph[vertex])) # 将邻居添加到栈中,反转列表以保持遍历顺序
# 调用函数
dfs_iterative(graph, 'A')
```
这段代码同样会输出从节点 'A' 开始的DFS遍历序列。
## 2.3 深度优先搜索的应用案例
### 2.3.1 拓扑排序
拓扑排序是深度优先搜索在有向无环图(DAG)上的一个应用。它将有向图的顶点排成一个线性序列,使得对于每一条有向边(u, v),顶点u都排在v之前。
拓扑排序不是唯一的,但在DFS遍历结束时,我们可以通过将顶点添加到列表中来得到一个有效的拓扑排序。以下是一个拓扑排序的DFS实现:
```python
def topological_sort(graph):
visited = set()
stack = []
def dfs(node):
visited.add(node)
for neighbour in graph[node]:
if neighbour not in visited:
dfs(neighbour)
stack.insert(0, node) # 将节点插入到栈顶
for node in graph:
if node not in visited:
dfs(node)
return stack # 返回拓扑排序
# 示例图
graph = {
'A': ['B', 'D'],
'B': ['C'],
'C': [],
'D': ['C']
}
print(topological_sort(graph))
```
### 2.3.2 检测图中的环
深度优先搜索也常被用来检测有向图中是否存在环。如果在DFS过程中,我们遇到一个已经访问过的节点,且该节点不是当前节点的直接后继节点,那么这个图中就存在一个环。
以下是使用DFS检测图中环的Python代码示例:
```python
def has_cycle(graph):
visited = set()
rec_stack = set()
def is_cyclic_util(node, parent):
visited.add(node)
rec_stack.add(node)
# 递归访问所有邻居
for neighbour in graph[node]:
if neighbour not in visited:
if is_cyclic_util(neighbour, node):
return True
elif neighbour != parent:
return True
rec_stack.remove(node)
return False
for node in graph:
if node not in visited:
if is_cyclic_util(node, -1):
return True
return False
# 示例图,包含一个环
graph = {
'A': ['B', 'C'],
'B': ['D'],
'C': ['B'],
'D': ['C']
}
print(has_cycle(graph)) # 输出结果将是True,表明存在环
```
通过这些应用案例,我们可以看到深度优先搜索不仅是一种强大的搜索策略,它还在许多图算法中扮演着核心角色。
# 3. 广度优先搜索(BFS)理论与实现
## 3.1 广度优先搜索的基本概念
### 3.1.1 队列与层次遍历
在深入广度优先搜索(BFS)的实现之前,理解队列数据结构的重要性是关键。队列是一种先进先出(FIFO)的数据结构,它在BFS中的应用是维持访问节点的顺序,确保我们能够按照距离起始点的层次进行遍历。
图论中的节点可以被想象为一个城市的各个地点,而边则可以视作连接这些地点的道路。在使用BFS遍历一个图时,我们从起始节点开始,首先访问所有与起始节点相邻的节点。这就像从城市的一个地点出发,首先访问所有步行可达的其他地点。接下来,我们再访问这些新节点的相邻节点,但要排除已经在之前步骤中访问过的节点。这一步骤不断重复,直到访问完图中所有可达的节点。
队列在这一过程中扮演了核心角色。我们将刚访问的节点放入队列中,并在每一层遍历完成后,从队列中取出一个节点,再将其所有未访问过的相邻节点加入队列。这样,我们就能保证访问顺序的正确性,按照从近到远的顺序逐层推进。
### 3.1.2 广度优先搜索的工作原理
BFS的原理是基于上述的层次遍历,通过逐步扩展搜索范围,直至覆盖整个图或找到目标节点。与深度优先搜索(DFS)不同,BFS不深入一条路径,而是尝试探索所有可能的路径。
在BFS中,我们使用一个队列来维护待访问节点的列表。算法开始时,仅将起始节点加入队列。在每一步中,我们从队列中取出队首元素,访问它,并将其所有未访问的邻居节点加入队列。这一过程重复进行,直到队列为空,此时所有可达节点都已被访问。
为了防止重复访问同一个节点,我们通常使用一个标记数组(或集合)来记录哪些节点已经被访问过。当一个节点被取出队列并访问后,我们将它加入到已访问集合中。这样,即使之后的节点再次被发现,我们也能通过检查已访问集合,避免重复处理。
在BFS中,一旦发现目标节点,搜索过程立即停止,这确保了在最短路径问题中,我们能够找到距离起始节点最近的目标节点。
## 3.2 广度优先搜索的算法实现
### 3.2.1 使用队列实现BFS
实现BFS算法的关键在于合理使用队列数据结构。下面是一个使用Python实现BFS算法的基本示例:
```python
from collections import deque
de
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
欢迎来到 Python 数据结构和算法专栏!本专栏旨在从基础到进阶,全面提升您的算法思维和数据结构应用能力。我们涵盖了广泛的主题,包括:
* 数据结构基础:列表、元组、递归、排序、图算法
* 算法优化:分治、动态规划、堆、字符串处理
* 链表、队列、二叉树、算法面试必备技巧
* 贪心、回溯、并查集、哈希表、大数据算法
* 深度优先搜索、图论等算法在 Python 中的应用
无论您是数据结构和算法的新手,还是希望提升您的技能,本专栏都能为您提供全面的指导和深入的见解。通过循序渐进的讲解、丰富的示例和实战练习,我们将帮助您掌握数据结构和算法的精髓,提升您的编程能力和问题解决技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【深度分析】:Windows 11非旺玖PL2303驱动问题的终极解决之道
# 摘要
随着Windows 11操作系统的推出,PL2303芯片及其驱动程序的兼容性问题逐渐浮出水面,成为技术维护的新挑战。本文首先概述了Windows 11中的驱动问题,随后对PL2303芯片的功能、工作原理以及驱动程序的重要性进行了理论分析。通过实例研究,本文深入探讨了旺玖PL2303驱动问题的具体案例、更新流程和兼容性测试,并提出了多种解决和优化方案。文章最后讨论了预防措施和对Windows 11驱动问题未来发展的展望,强调了系统更新、第三方工具使用及长期维护策略的重要性。
# 关键字
Windows 11;PL2303芯片;驱动兼容性;问题分析;解决方案;预防措施
参考资源链接:
【Chem3D个性定制教程】:打造独一无二的氢原子与孤对电子视觉效果

# 摘要
Chem3D软件作为一种强大的分子建模工具,在化学教育和科研领域中具有广泛的应用。本文首先介绍了Chem3D软件的基础知识和定制入门,然后深入探讨了氢原子模型的定制技巧,包括视觉定制和高级效果实现。接着,本文详细阐述了孤对电子视觉效果的理论基础、定制方法和互动设计。最后,文章通过多个实例展示了Chem3D定制效果在实践应用中的重要性,并探讨了其在教学和科研中的
【网格工具选择指南】:对比分析网格划分工具与技术
# 摘要
本文全面综述了网格划分工具与技术,首先介绍了网格划分的基本概念及其在数值分析中的重要作用,随后详细探讨了不同网格类型的选择标准和网格划分算法的分类。文章进一步阐述了网格质量评估指标以及优化策略,并对当前流行的网格划分工具的功能特性、技术特点、集成兼容性进行了深入分析。通过工程案例的分析和性能测试,本文揭示了不同网格划分工具在实际应用中的表现与效率。最后,展望了网格划分技术的未来发展趋势,包括自动
大数据分析:处理和分析海量数据,掌握数据的真正力量

# 摘要
大数据是现代信息社会的重要资源,其分析对于企业和科学研究至关重要。本文首先阐述了大数据的概念及其分析的重要性,随后介绍了大数据处理技术基础,包括存储技术、计算框架和数据集成的ETL过程。进一步地,本文探讨了大数据分析方法论,涵盖了统计分析、数据挖掘以及机器学习的应用,并强调了可视化工具和技术的辅助作用。通过分析金融、医疗和电商社交媒体等行
内存阵列设计挑战
# 摘要
内存阵列技术是现代计算机系统设计的核心,它决定了系统性能、可靠性和能耗效率。本文首先概述了内存阵列技术的基础知识,随后深入探讨了其设计原理,包括工作机制、关键技术如错误检测与纠正技术(ECC)、高速缓存技术以及内存扩展和多通道技术。进一步地,本文关注性能优化的理论和实践,提出了基于系统带宽、延迟分析和多级存储层次结构影响的优化技巧。可靠性和稳定性设计的策略和测试评估方法也被详细分析,以确保内存阵列在各
【网络弹性与走线长度】:零信任架构中的关键网络设计考量

# 摘要
网络弹性和走线长度是现代网络设计的两个核心要素,它们直接影响到网络的性能、可靠性和安全性。本文首先概述了网络弹性的概念和走线长度的重要性,随后深入探讨了网络弹性的理论基础、影响因素及设
天线技术实用解读:第二版第一章习题案例实战分析

# 摘要
本论文回顾了天线技术的基础知识,通过案例分析深入探讨了天线辐射的基础问题、参数计算以及实际应用中的问题。同时,本文介绍了天
音频处理中的阶梯波发生器应用:技术深度剖析与案例研究

# 摘要
阶梯波发生器作为电子工程领域的重要组件,广泛应用于音频合成、信号处理和测试设备中。本文从阶梯波发生器的基本原理和应用出发,深入探讨了其数学定义、工作原理和不同实现方法。通过对模拟与数字电路设计的比较,以及软件实现的技巧分析,本文揭示了在音频处理领域中阶梯波独特的应用优势。此外,本文还对阶梯波发生器的
水利工程中的Flac3D应用:流体计算案例剖析

# 摘要
本文深入探讨了Flac3D在水利工程中的应用,详细介绍了Flac3D软件的理论基础、模拟技术以及流体计算的实践操作。首先,文章概述了Flac3D软件的核心原理和基本算法,强调了离散元方法(DEM)在模拟中的重要性,并对流体计算的基础理论进行了阐述。其次,通过实际案例分析,展示了如何在大坝渗流、地下水流动及渠道流体动力学等领域中建立模型、进行计算
【Quartus II 9.0功耗优化技巧】:降低FPGA功耗的5种方法

# 摘要
随着高性能计算需求的不断增长,FPGA因其可重构性和高性能成为众多应用领域的首选。然而,FPGA的功耗问题也成为设计与应用中的关键挑战。本文从FPGA功耗的来源和影响因素入手,详细探讨了静态功耗和动态功耗的类型、设计复杂性与功耗之间的关系,以及功耗与性能之间的权衡。本文着重介绍并分析了Quartus II功耗分析工具的使用方法,并针对降低FPGA功耗提出了一系列优化技巧。通过实证案
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )