MATLAB Matrix Singular Value Decomposition (SVD): Exploring Low-Rank Approximations with 4 Application Scenarios
发布时间: 2024-09-15 01:27:20 阅读量: 25 订阅数: 25 
# 1. Singular Value Decomposition (SVD) Overview
Singular Value Decomposition (SVD) is a powerful linear algebra technique used to factorize a matrix into the product of three matrices: a left singular vector matrix, a singular value matrix, and a right singular vector matrix. SVD is widely applied across various fields, including data science, image processing, and natural language processing.
The essence of SVD is to decompose a matrix into a set of singular values and singular vectors. Singular values represent the variance in the data within the matrix, while singular vectors indicate the distribution of the data across different dimensions. Through matrix decomposition, SVD can uncover the latent structure and patterns within the data.
# 2. Theoretical Foundations of SVD
**2.1 Singular Values and Singular Vectors**
Singular Value Decomposition (SVD) is a mathematical technique that decomposes a matrix into singular values and corresponding singular vectors. Singular values are non-negative real numbers that are the square roots of the eigenvalues of the matrix, while singular vectors are the eigenvectors corresponding to these singular values.
For an m×n matrix A, its SVD can be represented as:
```
A = UΣV^T
```
Where:
* U is an m×m unitary matrix whose column vectors are the left singular vectors of A.
* Σ is an m×n diagonal matrix whose diagonal elements are the singular values of A, arranged in descending order.
* V is an n×n unitary matrix whose column vectors are the right singular vectors of A.
**2.2 Geometric Interpretation of SVD**
SVD can be understood geometrically as decomposing matrix A into a series of orthogonal transformations.
***Left Singular Vectors U:** Project the row space of A onto an m-dimensional unit hyperplane.
***Singular Values Σ:** Describe the lengths of the projected row vectors, with larger singular values indicating longer projected row vectors.
***Right Singular Vectors V:** Project the column space of A onto an n-dimensional unit hyperplane.
**2.3 Computational Methods for SVD**
Common methods for computing SVD include:
***Jacobi Method:** Diagonalize the matrix through a series of orthogonal transformations.
***QR Algorithm:** Decompose the matrix into a product of a series of unitary matrices using QR decomposition.
***Singular Value Decomposition Theorem:** Factorize the matrix into the product of singular values and corresponding singular vectors using the SVD theorem.
**Code Block:**
```python
import numpy as np
# Using NumPy to compute the SVD of matrix A
A = np.array([[1, 2], [3, 4]])
U, S, Vh = np.linalg.svd(A, full_matrices=False)
# Print singular values and singular vectors
print("Singular values:", S)
print("Left singular vectors:", U)
print("Right singular vectors:", Vh)
```
**Logical Analysis:**
This code uses NumPy's `linalg.svd()` function to compute the SVD of matrix A. The parameter `full_matrices=False` specifies that the reduced U and Vh matrices should be returned, containing only the columns corresponding to the non-zero singular values.
**Parameter Explanation:**
* `A`: The matrix to be decomposed.
* `full_matrices`: If True, return the full U and Vh matrices; if False, return the reduced U and Vh matrices.
# 3.1 Low-Rank Approximation
**3.1.1 Singular Value Truncation**
Singular value truncation is a low-rank approximation technique that approximates the original matrix by truncating smaller singular values. Specifically, for an m×n matrix A, its singular value decomposition is:
```
A = UΣV^T
```
Where U is an m×m orthogonal matrix, Σ is an m×n diagonal matrix with the singular values of A on its diagonal, and V is an n×n orthogonal matrix.
The idea behind singular value truncation is that smaller singular values correspond to singular vectors that contribute less to A. Therefore, we can truncate these smaller singular values to obtain a low-rank approximation matrix:
```
A_k = UΣ_kV^T
```
Where Σ_k is an m×n diagonal matrix that retains only the first k singular values.
**3.1.2 Compressed Sensing**
Compressed sensing is a technique for reconstructing signals from undersampled data. It leverages the sparsity of the signal, meaning that most of the signal's energy is concentrated in a few components.
In compressed sensing, the original signal is represented as a matrix A, whose SVD is:
```
A = UΣV^T
```
If A is sparse, then most of the singular values in Σ will be zero. Therefore, we can use singular value truncation to approximate A and recover the original signal from the undersampled data.
**Code Block:**
```python
import numpy as np
from scipy.linalg import svd
# Original matrix
A = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
# Singular value decomposition
U, S, Vh = svd(A, full_matrices=False)
# Singular value truncation
k = 2
A_k = np.dot(U[:, :k], np.dot(np.diag(S[:k]), Vh[:k, :]))
# Print the original matrix and the low-rank approximation matrix
print("Original matrix:")
print(A)
print("Low-rank approximati
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【特征工程稀缺技巧】:标签平滑与标签编码的比较及选择指南
# 1. 特征工程简介
## 1.1 特征工程的基本概念
特征工程是机器学习中一个核心的步骤,它涉及从原始数据中选取、构造或转换出有助于模型学习的特征。优秀的特征工程能够显著提升模型性能,降低过拟合风险,并有助于在有限的数据集上提炼出有意义的信号。
## 1.2 特征工程的重要性
在数据驱动的机器学习项目中,特征工程的重要性仅次于数据收集。数据预处理、特征选择、特征转换等环节都直接影响模型训练的效率和效果。特征工程通过提高特征与目标变量的关联性来提升模型的预测准确性。
## 1.3 特征工程的工作流程
特征工程通常包括以下步骤:
- 数据探索与分析,理解数据的分布和特征间的关系。
- 特
【统计学意义的验证集】:理解验证集在机器学习模型选择与评估中的重要性
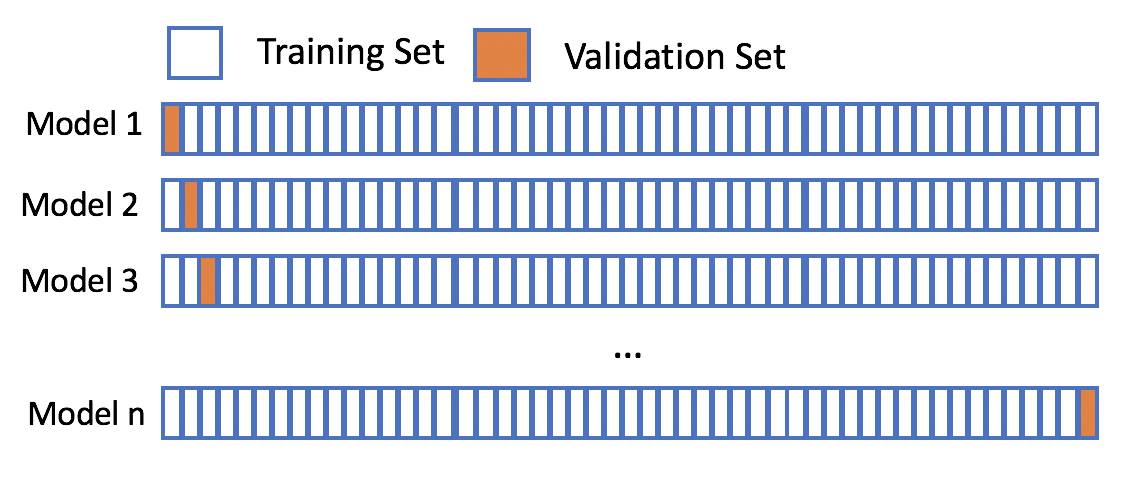
# 1. 验证集的概念与作用
在机器学习和统计学中,验证集是用来评估模型性能和选择超参数的重要工具。**验证集**是在训练集之外的一个独立数据集,通过对这个数据集的预测结果来估计模型在未见数据上的表现,从而避免了过拟合问题。验证集的作用不仅仅在于选择最佳模型,还能帮助我们理解模型在实际应用中的泛化能力,是开发高质量预测模型不可或缺的一部分。
```markdown
## 1.1 验证集与训练集、测试集的区
【PCA算法优化】:减少计算复杂度,提升处理速度的关键技术

# 1. PCA算法简介及原理
## 1.1 PCA算法定义
主成分分析(PCA)是一种数学技术,它使用正交变换来将一组可能相关的变量转换成一组线性不相关的变量,这些新变量被称为主成分。
## 1.2 应用场景概述
PCA广泛应用于图像处理、降维、模式识别和数据压缩等领域。它通过减少数据的维度,帮助去除冗余信息,同时尽可能保
过拟合的统计检验:如何量化模型的泛化能力

# 1. 过拟合的概念与影响
## 1.1 过拟合的定义
过拟合(overfitting)是机器学习领域中一个关键问题,当模型对训练数据的拟合程度过高,以至于捕捉到了数据中的噪声和异常值,导致模型泛化能力下降,无法很好地预测新的、未见过的数据。这种情况下的模型性能在训练数据上表现优异,但在新的数据集上却表现不佳。
## 1.2 过拟合产生的原因
过拟合的产生通常与模
【交互特征的影响】:分类问题中的深入探讨,如何正确应用交互特征

# 1. 交互特征在分类问题中的重要性
在当今的机器学习领域,分类问题一直占据着核心地位。理解并有效利用数据中的交互特征对于提高分类模型的性能至关重要。本章将介绍交互特征在分类问题中的基础重要性,以及为什么它们在现代数据科学中变得越来越不可或缺。
## 1.1 交互特征在模型性能中的作用
交互特征能够捕捉到数据中的非线性关系,这对于模型理解和预测复杂模式至关重要。例如
欠拟合影响深度学习?六大应对策略揭秘

# 1. 深度学习中的欠拟合现象
在机器学习领域,尤其是深度学习,欠拟合现象是指模型在训练数据上表现不佳,并且也无法在新的数据上作出准确预测。这通常
自然语言处理中的独热编码:应用技巧与优化方法
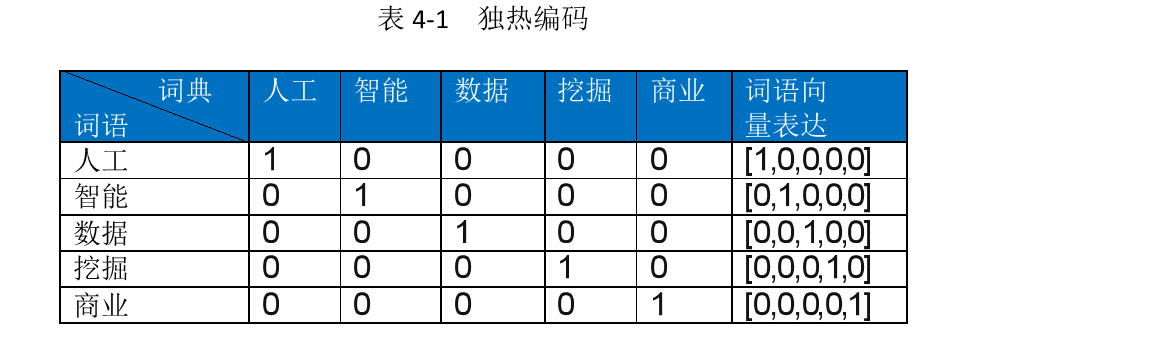
# 1. 自然语言处理与独热编码概述
自然语言处理(NLP)是计算机科学与人工智能领域中的一个关键分支,它让计算机能够理解、解释和操作人类语言。为了将自然语言数据有效转换为机器可处理的形式,独热编码(One-Hot Encoding)成为一种广泛应用的技术。
## 1.1 NLP中的数据表示
在NLP中,数据通常是以文本形式出现的。为了将这些文本数据转换为适合机器学习模型的格式,我们需要将单词、短语或句子等元
【时间序列分析】:如何在金融数据中提取关键特征以提升预测准确性

# 1. 时间序列分析基础
在数据分析和金融预测中,时间序列分析是一种关键的工具。时间序列是按时间顺序排列的数据点,可以反映出某
探索性数据分析:训练集构建中的可视化工具和技巧
# 1. 探索性数据分析简介
在数据分析的世界中,探索性数据分析(Exploratory Dat
测试集在兼容性测试中的应用:确保软件在各种环境下的表现

# 1. 兼容性测试的概念和重要性
## 1.1 兼容性测试概述
兼容性测试确保软件产品能够在不同环境、平台和设备中正常运行。这一过程涉及验证软件在不同操作系统、浏览器、硬件配置和移动设备上的表现。
## 1.2 兼容性测试的重要性
在多样的IT环境中,兼容性测试是提高用户体验的关键。它减少了因环境差异导致的问题,有助于维护软件的稳定性和可靠性,降低后
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )