MATLAB Matrix Singular Value Decomposition (SVD) Application Guide: From Dimensionality Reduction to Image Processing, 5 Practical Cases
发布时间: 2024-09-15 01:38:53 阅读量: 46 订阅数: 39 
# Guide to Singular Value Decomposition (SVD) Applications in MATLAB: From Dimensionality Reduction to Image Processing, 5 Practical Cases
## 1. Introduction to Singular Value Decomposition (SVD)
Singular Value Decomposition (SVD) is a powerful linear algebra technique used to factorize a matrix into the product of three matrices: an orthogonal matrix U, a diagonal matrix Σ, and another orthogonal matrix V. The form of SVD is as follows:
```
A = UΣV^T
```
where:
* A is the original matrix
* U is the matrix of left singular vectors
* Σ is the singular value matrix
* V is the matrix of right singular vectors
The singular values in SVD represent a measure of importance of the matrix A, i.e., the larger the singular value, the more important the corresponding column or row is in the matrix. SVD is widely applied in dimensionality reduction, image processing, signal processing, and many other fields.
## 2. Application of SVD in Dimensionality Reduction
### 2.1 Principal Component Analysis (PCA)
**Definition:**
Principal Component Analysis (PCA) is a dimensionality reduction technique that projects high-dimensional data into a lower-dimensional space through a linear transformation while preserving the maximum amount of data variance.
**Principle:**
The principle of PCA is to find the eigenvectors of the data covariance matrix, which represent the main directions of the data. The larger the sum of the eigenvalues corresponding to the first k eigenvectors as a proportion of the total eigenvalues, the more information is retained in the reduced data.
**Steps:**
1. Center the data by subtracting the mean of each column.
2. Calculate the data covariance matrix.
3. Perform eigendecomposition on the covariance matrix to obtain eigenvalues and eigenvectors.
4. Select the eigenvectors corresponding to the first k eigenvalues as the basis vectors for the reduced data.
5. Project the data onto the subspace spanned by the basis vectors to obtain the reduced data.
**Code Example:**
```matlab
% Data
data = randn(100, 10);
% Centering
data = data - mean(data);
% Covariance matrix
cov_matrix = cov(data);
% Eigendecomposition
[eigenvectors, eigenvalues] = eig(cov_matrix);
% Dimensionality reduction
reduced_data = data * eigenvectors(:, 1:2);
```
**Logical Analysis:**
* `randn(100, 10)` generates a random matrix with 100 rows and 10 columns.
* `mean(data)` calculates the mean of each column.
* `cov(data)` calculates the covariance matrix.
* `eig(cov_matrix)` performs eigendecomposition to obtain eigenvalues and eigenvectors.
* `eigenvectors(:, 1:2)` selects the first two eigenvectors.
* `data * eigenvectors(:, 1:2)` projects the data onto the subspace spanned by the basis vectors.
### 2.2 Linear Discriminant Analysis (LDA)
**Definition:**
Linear Discriminant Analysis (LDA) is a supervised dimensionality reduction technique that projects high-dimensional data into a lower-dimensional space through a linear transformation, maximizing the distance between classes and minimizing the distance within classes.
**Principle:**
The principle of LDA is to find a linear projection matrix that maximizes the distance between the centroids of different classes and minimizes the distance between the centroids within the same class after projection.
**Steps:**
1. Calculate the within-class scatter matrix and the between-class scatter matrix.
2. Perform eigendecomposition on the between-class scatter matrix to obtain eigenvalues and eigenvectors.
3. Select the eigenvectors corresponding to the first k eigenvalues as the basis vectors for the reduced data.
4. Project the data onto the subspace spanned by the basis vectors to obtain the reduced data.
**Code Example:**
```matlab
% Data
data = [randn(50, 10); randn(50, 10) + 5];
labels = [ones(50, 1); ones(50, 1) * 2];
% Within-class scatter matrix
Sw = zeros(size(data, 2));
for i = 1:max(labels)
Sw = Sw + cov(data(labels == i, :));
end
% Between-class scatter matrix
Sb = zeros(size(data, 2));
for i = 1:max(labels)
Sb = Sb + (mean(data(labels == i, :)) - mean(data))' * (mean(data(labels == i, :)) - mean(data));
end
% Eigendecomposition
[eigenvectors, eigenvalues] = eig(Sb, Sw);
% Dimensionality reduction
reduced_data = data * eigenvectors(:, 1:2);
```
**Logical Analysis:**
* `randn(50, 10)` generates two random matrices with 50 rows and 10 columns each, representing two classes of data.
* `ones(50, 1)` generates a matrix with 50 rows and 1 column, with all elements set to 1, as labels for the first class.
* `ones(50, 1) * 2` generates a matrix with 50 rows and 1 column, with all elements set to 2, as labels for the second class.
* `cov(data(labels == i, :))` calculates the within-class scatter matrix for each class.
* `mean(data(labels == i, :))` calculates the centroid for each class.
* `eig(Sb, Sw)` performs eigendecomposition on the between-class scatter matrix and the within-class scatter matrix.
* `eigenvectors(:, 1:2)` selects the first two eigenvectors.
* `data * eigenvectors(:, 1:2)` projects the data onto the subspace spanned by the basis vectors.
### 2.3 Non-negative Matrix Factorization (NMF)
**Definition:**
Non-negative Matrix Factorization (NMF) is a technique f

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
深入揭秘:欧姆龙E5CZ温控表的五大核心工作原理及特性
# 摘要
本文全面介绍了欧姆龙E5CZ温控表的设计原理、操作特性以及在实际应用中的表现。首先,文章从硬件架构和关键传感器工作原理的角度,阐述了欧姆龙E5CZ的核心工作原理。接着,通过分析温度检测原理和控制算法模型,深入探讨了其控制流程,包括系统初始化、监控与调整。文章重点说明了E5CZ的主要特性,如用户界面设计、精确控制、稳定性和网络通信能力。在高级应用方面,本文讨论了自适应与预测控制技术,故障诊断与预防性维护策略,以及智能化功能的改进和行业特定解决方案。最后,提供安装调试的实践操作指导和案例研究,分享了行业应用经验和用户反馈,为读者提供改进建议和未来应用的展望。
# 关键字
欧姆龙E5CZ
【Lustre文件系统性能提升秘籍】:专家解析并行I_O与集群扩展
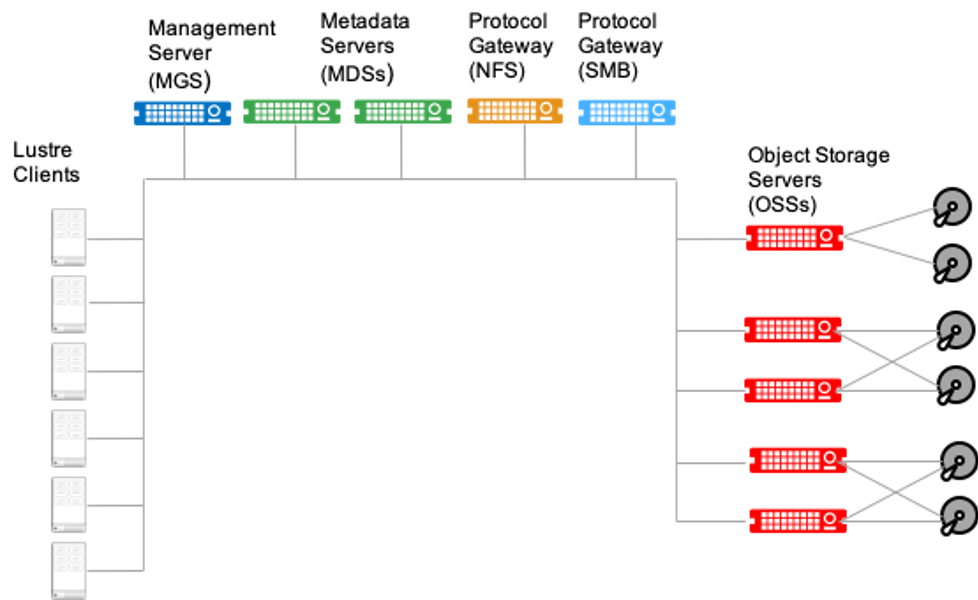
# 摘要
本文全面探讨了Lustre文件系统的基本概念、并行I/O的原理及其在Lustre中的实现,集群扩展的策略与实践,以及性能监控和调优技巧。在并行I/O部分,文章深入解析了并行I/O的定义、关键特性和性能影响因素。接着,文中详细介绍了集群扩展的基本概念,重点讨论了Lustre集群扩展的方法以及优化技巧。性能监控和调优章节则提供了实
Element UI表格头部合并教程】:打造响应式界面的关键步骤与代码解析
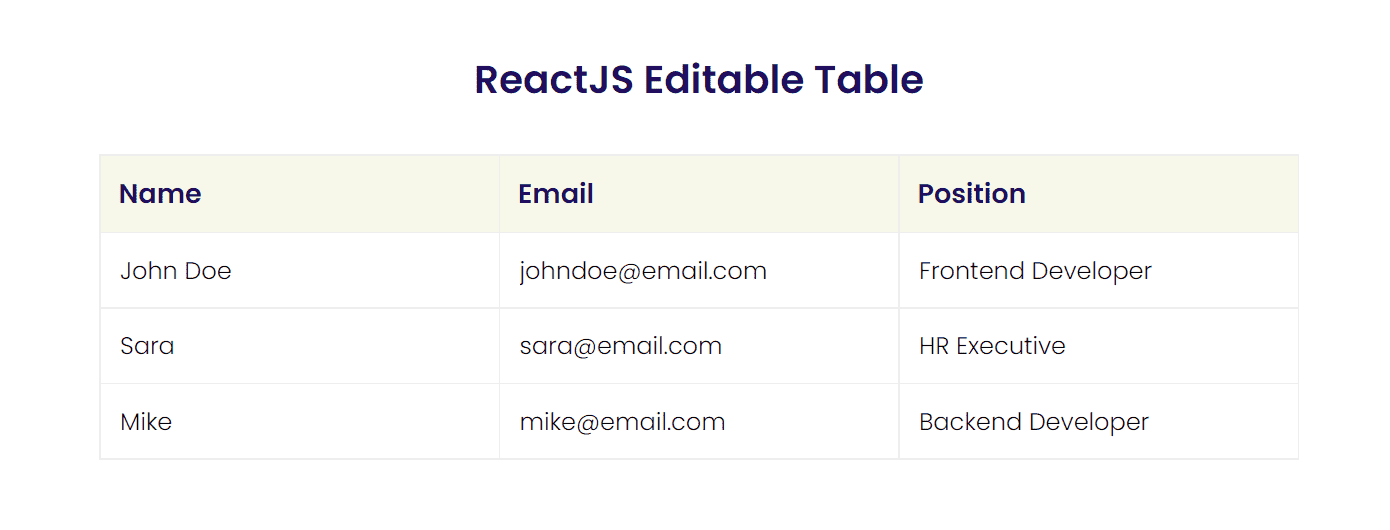
# 摘要
本文系统地探讨了Element UI表格头部合并的基础知识、理论基础、实践操作以及高级技巧,并通过综合案例分析来深入研究其在实际项目中的应用。文章首先介绍了响应式界面的理论基础,包括响应式设计的重要性和常用布局技术,同时阐述了Element UI框架的设计原则和组件库概述。随后,文章详细讲解了Ele
SAP安全审计核心:常用表在数据访问控制中的关键作用

# 摘要
随着企业信息化的深入发展,SAP系统作为企业资源规划的核心,其安全审计变得尤为重要。本文首先介绍了SAP安全审计的核心概念和常用数据表,阐述了数据表结构和数据访问控制的基础。通过具体案例分析,探讨了审计中数据表的应用和数据访问控制策略的制定与实施。同时,本文还提出了高级数据分析技术的应用,优化审计流程并提升安全审计的效果。最后,本文探讨了SAP安全
Cadence 16.2 库管理秘籍:最佳实践打造高效设计环境
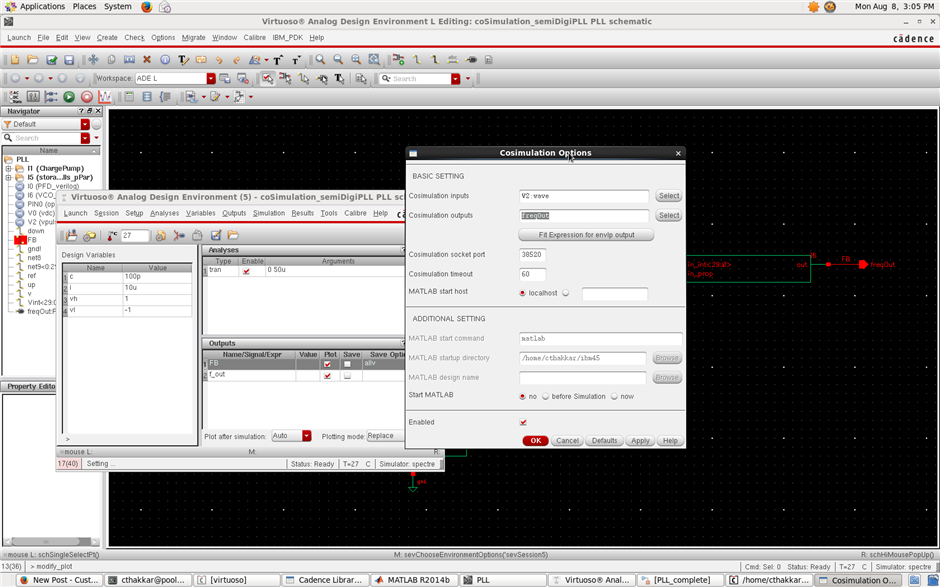
# 摘要
本文全面介绍了Cadence 16.2版本的库管理功能和实践技巧。首先概述了库管理的基本概念和Cadence库的结构,包括设计数据的重要性、库管理的目标与原则、库的类型和层次结构等。接着,详细探讨了库文件的操作、版本控制、维护更新、安全备份以及数据共享与协作
H3C交换机SSH配置全攻略:精炼步骤、核心参数与顶级实践

# 摘要
随着网络安全要求的提高,H3C交换机的SSH配置变得尤为重要。本文旨在全面概述H3C交换机SSH配置的各个方面,包括SSH协议的基础知识、配置前的准备工作、详细配置步骤、核心参数解析,以及配置实践案例。通过理解SSH协议的安全通信原理和加密认证机制,介绍了确保交换机SSH安全运行的必要配置,如系统时间同步、本地用户管理、密钥生成和配置等。本文还分析了SSH
【CentOS 7 OpenSSH密钥管理】:密钥生成与管理的高级技巧

# 摘要
本文系统地介绍了OpenSSH的使用及其安全基础。首先概述了OpenSSH及其在安全通信中的作用,然后深入探讨了密钥生成的理论与实践,包括密钥对生成原理和OpenSSH工具的使用步骤。文章接着详细讨论了密钥管理的最佳实践、密钥轮换和备份策略,以及如何
【EMAC接口深度应用指南】:如何在AT91SAM7X256_128+中实现性能最大化
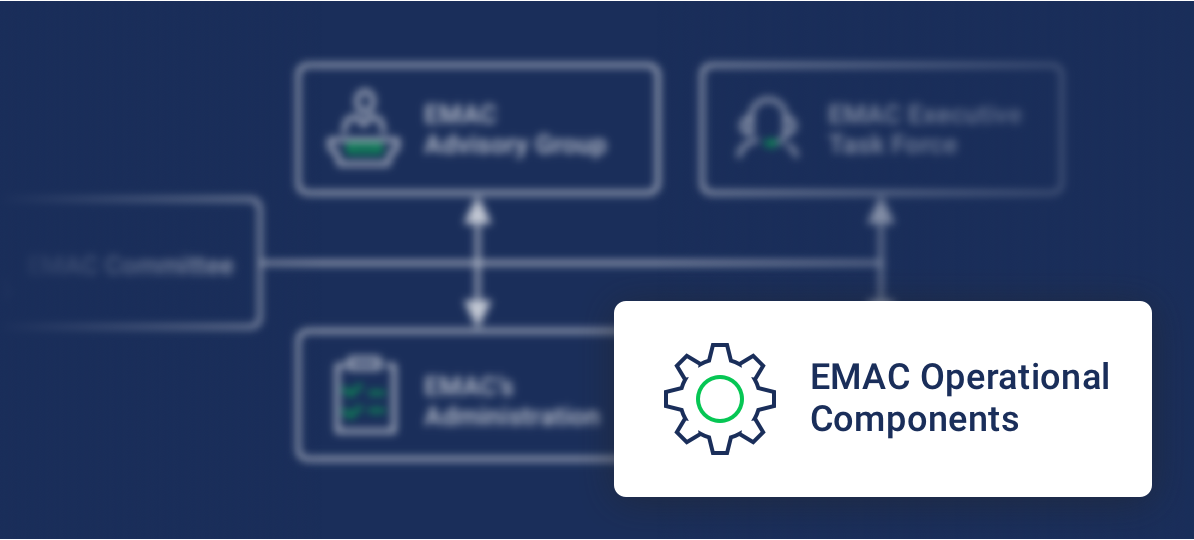
# 摘要
本文针对EMAC接口的基础知识、硬件配置、初始化过程以及网络性能调优进行了全面的探讨。首先介绍了EMAC接口基础和AT91SAM7X256_128+微控制器的相关特性。接着详细阐述了EMAC接口的硬件配置与初始化,包括接口信号、固件设置、驱动加载和初始化关键配置项。在此基础上,本文深入分析了网络性能调优策略,包括MAC地址配置、流控制、DMA传输优化、中断管理及实时性能提升。此外,还探讨了EMAC接口在多通道、QoS
viliv S5电池续航大揭秘:3个技巧最大化使用时间
# 摘要
本文针对viliv S5的电池续航能力进行了深入分析,并探讨了提高其电池性能的基础知识和实践技巧。文章首先介绍了电池的工作原理及影响viliv S5电池续航的关键因素,然后从硬件与软件优化两个层面阐述了电池管理策略。此外,本文提供了多种实践技巧来调整系统设置、应用管理及网络连接,以延长电池使用时间。文章还探讨了viliv S5电池续航的高级优化方法,包括硬件升级、第三方软件监控和电池保养维护的最佳实践。通过综合运用这些策略和技巧,用户可以显著提升viliv S5设备的电池续航能力,并优化整体使用体验。
# 关键字
电池续航;电池工作原理;电源管理;系统优化;硬件升级;软件监控
参
【回归分析深度解析】:SPSS 19.00高级统计技术,专家级解读
# 摘要
回归分析是统计学中用来确定两种或两种以上变量间相互依赖关系的统计分析方法。本文首先介绍了回归分析的基本概念及其在不同领域中的应用,接着详细说明了SPSS软件的操作界面和数据导入流程。进一步深入探讨了线性回归和多元回归分析的理论基础和实践技巧,包括模型假设、参数估计、模型诊断评估以及SPSS操作流程。最后,文章拓展到了非线性回归及其他高级回归技术的应用,展示了非线
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )