【MapReduce中间数据压缩技术】:存储效率提升与资源消耗降低技巧
发布时间: 2024-11-01 01:13:37 阅读量: 23 订阅数: 30 

18_尚硅谷大数据之MapReduce_Hadoop数据压缩1
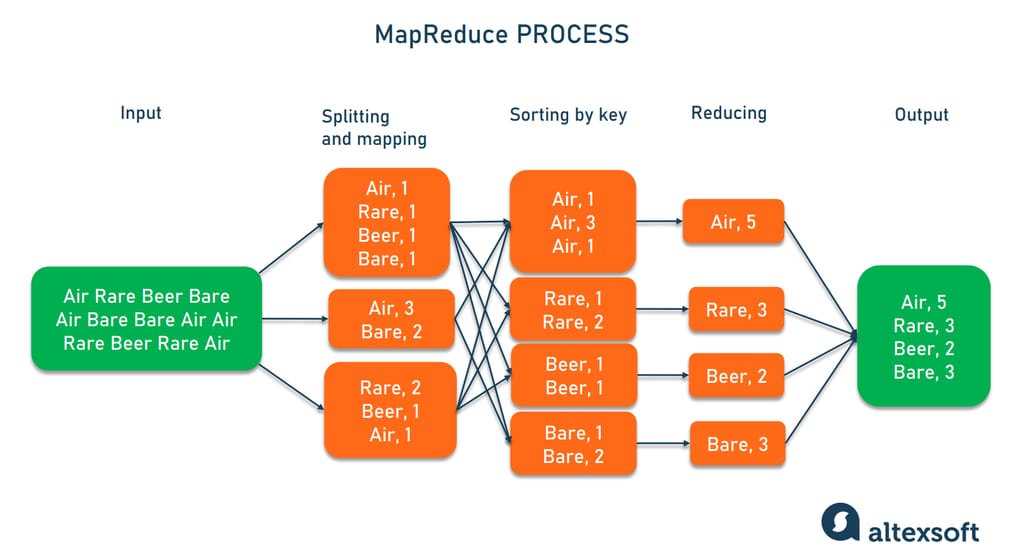
# 1. MapReduce中间数据压缩技术概述
## MapReduce中间数据压缩技术的价值
在大数据处理领域,MapReduce模型凭借其高效、可靠和可扩展的特点,成为处理海量数据的核心技术之一。然而,随着数据量的持续增长,如何有效管理中间数据成为了一个挑战。中间数据压缩技术应运而生,它能够在不牺牲计算性能的前提下,大幅度减少磁盘I/O操作,降低网络传输的数据量,从而提升整体处理效率和存储空间的利用率。
## 压缩技术在MapReduce中的应用
中间数据压缩技术在MapReduce框架中的应用,不仅涉及到Map和Reduce过程中的数据流处理,还包括与Hadoop生态系统中其他组件的交互。例如,使用Hadoop的SequenceFile和MapFile格式,或者利用Snappy和LZ4等压缩库来实现数据的压缩与解压缩。
## 对数据处理效率的提升
中间数据压缩技术在数据处理流程中的应用,可以显著提升数据处理的效率。通过压缩技术,我们可以有效地减少磁盘I/O次数,降低网络传输的负载,缩短数据读写和传输时间,这对于需要处理大量中间数据的MapReduce作业来说,无疑是一个巨大的优化。此外,压缩技术还能够提高数据处理的吞吐量,加速整个作业的完成速度,使得大数据处理更加高效。
```
// 示例代码:使用Snappy进行数据压缩
import org.xerial.snappy.Snappy;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.util.zip.DataFormatException;
public class SnappyExample {
public static void main(String[] args) throws IOException, DataFormatException {
byte[] originalData = "Some data to compress".getBytes("UTF-8");
ByteArrayOutputStream compressedData = new ByteArrayOutputStream();
// 压缩数据
***press(originalData, compressedData);
// 输出压缩后的数据大小,展示压缩效果
System.out.println("Original data size: " + originalData.length);
System.out.println("Compressed data size: " + compressedData.size());
}
}
```
通过上述代码块,我们可以看到如何使用Snappy库对数据进行压缩。在MapReduce作业中,这样的压缩过程会帮助我们优化中间数据的存储和传输,提升整体处理流程的效率。接下来的章节将进一步探讨中间数据压缩的理论基础和技术实践。
# 2. 中间数据压缩理论基础
## 2.1 MapReduce工作原理
### 2.1.1 Map阶段的数据处理
MapReduce计算框架中的Map阶段是分布式数据处理的关键步骤之一,其主要负责接收输入数据,并将其分割成独立的数据块进行并行处理。在这一阶段,用户定义的Mapper函数会对每个输入数据块进行处理,通常包括数据过滤、转换等操作。输出结果为键值对(key-value pairs),这些键值对将成为Reduce阶段的输入数据。
一个典型的Map任务流程通常包括以下几个步骤:
1. **数据切分**:首先,输入数据会被系统自动分割成可以独立处理的数据块。
2. **任务调度**:然后,这些数据块会被分配到集群中的不同节点上执行。
3. **并行处理**:每个节点上的Map任务执行用户定义的Mapper函数,对数据块进行处理。
4. **输出排序与分组**:Map任务完成后,输出的键值对会根据键进行排序,并按照键的值分组,为后续的Reduce阶段做准备。
一个简单的Mapper函数伪代码示例如下:
```python
def map(document):
# 用户自定义逻辑处理数据,例如:
for word in document:
emit_intermediate(word, 1)
```
### 2.1.2 Reduce阶段的数据处理
Reduce阶段的任务是处理Map阶段的输出结果,它负责汇总相同键(key)对应的所有值(value),并产生最终结果。在这一过程中,用户定义的Reducer函数会对Map任务输出的键值对进行合并或聚合操作。Reduce任务通常接收到的是按键排序后的数据集,这有助于在某些操作中实现高效的并行处理。
Reduce阶段的关键步骤包括:
1. **数据合并**:Reduce任务获取所有Map任务输出的相同键值对数据。
2. **用户处理**:调用用户定义的Reducer函数处理合并后的键值对数据。
3. **输出结果**:最终输出为一系列键值对,可以是原始数据形式,也可以是经过聚合后的形式。
一个简单的Reducer函数伪代码示例如下:
```python
def reduce(key, values):
# 用户自定义逻辑处理键和对应的值列表,例如:
result = 0
for value in values:
result += value
emit(key, result)
```
## 2.2 数据压缩技术简介
### 2.2.1 压缩算法的基本原理
数据压缩是一种减少数据所需存储空间和传输带宽的技术,它通过特定算法消除数据中的冗余信息,从而达到压缩数据的目的。基本原理可以总结为以下几点:
1. **消除冗余**:去除数据中重复出现的部分。
2. **编码转换**:使用更短的代码替代原始数据中的长代码。
3. **字典编码**:用字典中的索引来替换重复出现的字符串序列。
4. **预测编码**:通过预测下一个数据点来减少数据的大小。
5. **熵编码**:采用基于数据概率分布的编码方法,如霍夫曼编码。
### 2.2.2 常见的数据压缩算法对比
在数据压缩领域,多种算法被广泛使用,以下是几种常见的压缩算法对比:
- **霍夫曼编码(Huffman Coding)**:基于字符出现频率进行编码,频率高的字符使用较短的编码,反之亦然。
- **LZ77和LZ78**:通过字典的方式替换字符串重复出现的部分,广泛应用于文件压缩如GZIP。
- **Deflate**:结合了LZ77算法和霍夫曼编码,是GZIP和PNG图像格式所使用的算法。
- **Brotli**:一种较新的压缩算法,比传统的GZIP有更好的压缩比。
每种算法各有优劣,选择合适的压缩算法需要考虑数据的特性,比如数据的大小、类型、以及压缩与解压缩时的性能要求等因素。
## 2.3 中间数据压缩的重要性
### 2.3.1 存储效率与数据规模的关系
在大数据处理的背景下,中间数据的压缩显得尤为重要。存储效率直接关联到数据规模,大规模数据集通常包含大量重复数据和冗余信息,这为压缩提供了空间。压缩数据可以大大减少存储空间需求,降低硬件成本,同时还能提高数据处理和

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探讨了 MapReduce 作业执行过程中中间数据的存储机制。它涵盖了中间数据存储在内存和磁盘中的方式,以及如何优化内存使用以提高性能。此外,还提供了有关内存和磁盘交互、中间数据压缩、持久化和生命周期管理的见解。通过深入了解 MapReduce 中间数据存储,读者可以获得优化作业执行和提高数据处理效率所需的知识和技巧。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PLECS专家养成:版本4.1全方位提升攻略

# 摘要
PLECS软件作为电力电子系统建模与仿真的先进工具,随着版本的迭代不断强化其功能与性能。本文首先介绍了PLECS的基本操作和界面,随后深入解析了PLECS 4.1版本的新功能,包括用户界面的改进、高级仿真技术的引入、性能提升及兼容性的增强,以及用户自定义功能的扩展。接着,本文探讨了PLECS在仿真技术方面的深入应用,如仿真模型的构建、优化、结果分析处理,以及实际应用案例研究
【性能调优秘籍】:揭秘SINUMERIK_840D_810D高级调试技术
# 摘要
本论文详细探讨了SINUMERIK 840D/810D数控系统的性能调优。首先,本文介绍了性能调优的理论基础,包括性能瓶颈的识别、性能指标的设定以及系统资源的配置管理。进而深入分析了高级调试工具和技术的应用,并通过案例研究展示了提高加工效率、延长设备寿命以及实现可持续生产的具体实践。最后,论文展望了新技术如人工智能和物联网对性能调优带来的影响,并预测了数控系统智能化和调优工作标准化的未来趋势。
# 关键字
SINUMERIK 840D/810D;性能调优;高级调试工具;数据分析;智能生产;设备寿命管理
参考资源链接:[西门子SINUMERIK 810D/840D系统调试手册](h
Abaqus安装常见问题汇总及解决方法

# 摘要
本文围绕Abaqus软件的安装、配置及问题解决展开深入探讨。首先,本文详细介绍了Abaqus的基础安装要求和系统配置,为用户提供了安装环境的准备指南。然后,针对安装过程中可能出现的环境配置、文件获取与验证、错误解决等问题,给出了具体的问题分析和解决步骤。接着,文章强调了安装后环境变量的配置与验证的重要性,并通过实际案例验证安装的成功与否。高级诊断与问题解决章节阐述
【图书管理系统的数据库构建】:从零开始,打造高效安全的信息库

# 摘要
本文全面介绍图书管理系统的数据库设计与实践操作,从理论基础到实际应用,系统地阐述了数据库的构建和管理过程。首先,概述了图书管理系统的基本概念及其需求,然后深入探讨了关系型数据库的基本理论、设计原则和数据库的构建实践,包括数据库的安装、配置、表结构设计以及安全性设置。接着,重点介绍了图书管理系统中数据库操作的实
【技术深度解析】:深度学习如何革新乒乓球旋转球预测技术?

# 摘要
随着深度学习技术的迅速发展,其在体育领域,如乒乓球旋转球预测方面的应用日益广泛。本文首先介绍了乒乓球旋转球的基础知识,包括其定义、分类、物理原理以及旋转球预测所面临的挑战。然后,深入探讨了深度学习在旋转球预测中的理论基础、模型构建、训练、性能评估和实际应用。文中还涵盖了深度学习模型在实战演练中的数据采集与处理技术、模型部署和实时性能优化,并对旋转球预测的未来展望进
【机器人通信协议详解】:掌握RoboTeam软件中的网络通信

# 摘要
随着机器人技术的发展,机器人通信协议的重要性日益凸显。本文首先概述了机器人通信协议的基础,介绍了RoboTeam软件的网络通信机制,包括其架构、通信模型及消息传递协议。随后深入探讨了机器人通信协议的理论基础,包括不同类型协议的比较和实现原理,以及在RoboTeam中的优化策略。通过具体实践案例分析,本文展示了点对点通信、多机器人协作通信以及实时监控与远程控制的应
【CST仿真实战】:波导端口离散端口信号处理全解析,从理论到实践
# 摘要
本文全面介绍CST仿真实战在波导端口信号处理中的应用。首先,对波导端口信号的基础理论进行了概述,包括电磁波的产生与传播、电磁场分布、端口信号的分类及其频谱分析。随后,文中详细阐述了如何在CST软件中进行波导端口的模拟操作,包括软件界面功能简介、仿真实例创建以及离散端口信号仿真流程。进而,本文针对波导端口信号的分析与处理进行了实践探讨,涉及到信号的模拟分析、信号处理技术的应用以及仿真结果的实际应用分析。最后,文章对波导端口信号处理的高级主题进行了探讨,涵盖高频波导端口的信号完整性分析、多端口系统的信号耦合处理以及波导端口信号处理领域的最新进展。本文旨在为相关领域的研究者和工程师提供一个
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )