数据挖掘中的自组织映射(SOM):挖掘数据背后的宝藏
发布时间: 2024-08-21 06:30:39 阅读量: 33 订阅数: 50 
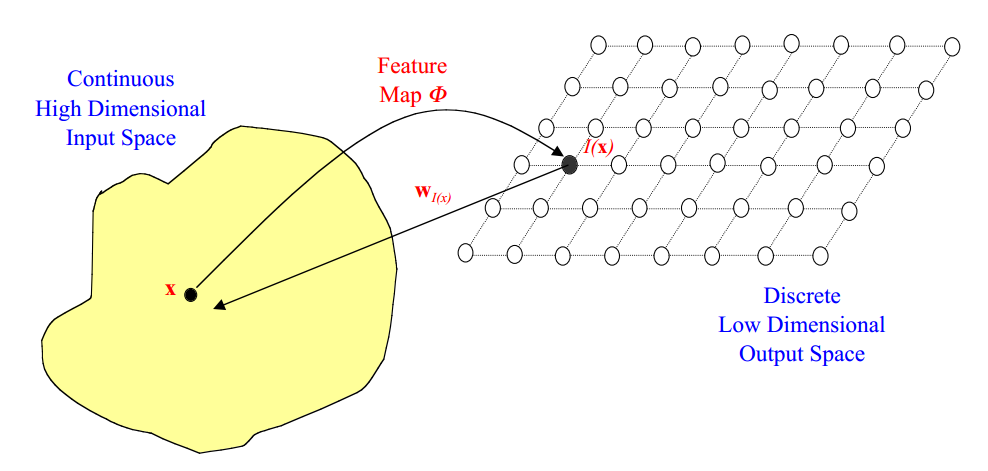
# 1. 自组织映射(SOM)简介**
自组织映射(SOM)是一种无监督神经网络算法,它能够将高维数据映射到低维空间,同时保留输入数据的拓扑结构。SOM的独特之处在于其自组织特性,它可以自动发现数据中的模式和关系,而无需人工干预。
SOM算法最初由芬兰神经科学家Teuvo Kohonen于1982年提出。它是一种非线性投影算法,能够将高维输入数据映射到低维输出空间,通常为二维或三维。SOM网络由一个神经元阵列组成,每个神经元都与输入数据中的一个特征向量相关联。
# 2. SOM算法原理**
**2.1 SOM神经网络结构**
自组织映射(SOM)神经网络是一种非监督学习算法,其结构类似于生物神经网络。SOM网络由一个二维网格状的节点组成,每个节点都与一个权重向量相关联。权重向量的大小与输入数据的维度相同。
**2.2 SOM学习算法**
SOM学习算法是一个迭代过程,包括以下三个主要步骤:
**2.2.1 初始化**
1. 随机初始化每个节点的权重向量。
2. 设置学习率α和邻域半径σ。
**2.2.2 竞争学习**
1. 从训练数据中随机选择一个输入向量x。
2. 对于网络中的每个节点i,计算节点权重向量wi与输入向量x之间的欧氏距离。
3. 找到与x距离最小的节点,称为获胜节点。
**2.2.3 权重更新**
1. 更新获胜节点及其邻域内节点的权重向量:
```
w_i(t+1) = w_i(t) + α(t) * (x(t) - w_i(t))
```
其中:
* t表示当前迭代次数
* α(t)是学习率,随时间衰减
* σ(t)是邻域半径,随时间衰减
2. 邻域内的节点权重更新幅度随着与获胜节点的距离而减小。
**代码块:**
```python
import numpy as np
class SOM:
def __init__(self, input_dim, map_size, learning_rate=0.1, radius=1):
self.input_dim = input_dim
self.map_size = map_size
self.weights = np.random.rand(map_size[0], map_size[1], input_dim)
self.learning_rate = learning_rate
self.radius = radius
def train(self, data, epochs=100):
for epoch in range(epochs):
for x in data:
# 竞争学习
winner = np.argmin(np.linalg.norm(self.weights - x, axis=2))
winner_row, winner_col = winner // self.map_size[1], winner % self.map_size[1]
# 权重更新
for i in range(self.map_size[0]):
for j in range(self.map_size[1]):
distance = np.linalg.norm([i - winner_row, j - winner_col])
if distance <= self.radius:
self.weights[i, j] += self.learning_rate * (x - self.weights[i, j])
# 学习率和邻域半径衰减
self.learning_rate *= 0.9
self.radius *= 0.9
```
**逻辑分析:**
* `__init__`方法初始化SOM网络,包括权重、学习率和邻域半径。
* `train`方法对数据进行训练,包括竞争学习和权重更新。
* 竞争学习通过计算输入向量与每个节点权重向

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
自组织映射(SOM)技术专栏深入探讨了这一强大的机器学习算法,重点关注其在数据可视化、图像处理、文本分析、金融、医疗、生物信息学、异常检测、模式识别、聚类分析、降维、非监督学习等领域的广泛应用。专栏文章详细阐述了 SOM 算法的原理、实现和应用,并提供了实际项目中的成功案例。此外,专栏还对 SOM 的优缺点进行了全面评估,并将其与其他机器学习算法进行了比较,帮助读者选择最适合其需求的算法。最后,专栏提供了 SOM 的最佳实践和常见问题解答,帮助读者提升模型性能并解决常见困惑。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
SENT协议故障诊断不求人:SAE J2716标准常见问题速解

# 摘要
SENT协议与SAE J2716标准是汽车电子领域内广泛应用的技术,用于传感器数据传输。本文首先概述了SENT协议和SAE J2716标准的基本概念和应用场景,随后深入分析了SENT协议的工作原理、数据包结构以及故障诊断的基础方法。文章接着详细探讨了SAE J2716标准的技术要求、测试验证以及故障诊断实践,进阶技术部分则侧重于SENT协
从零开始:EP4CE10教程带你走进FPGA编程的世界

# 摘要
本文介绍了FPGA(现场可编程门阵列)的基础知识及其在EP4CE10芯片上的应用。从开发环境的搭建、基础编程理论到复杂逻辑设计及优化技巧,本文逐步深入讲解了FPGA开发的各个方面。同时,通过数字时钟和简易计算器的实战项目,阐述了理论知识的实
PADS高级设计技巧揭秘:提升PCB效率的5大关键步骤

# 摘要
本文综述了PADS软件在电路设计中的高级技巧和应用。首先概述了PADS高级设计技巧,然后详细探讨了原理图设计与优化、PCB布局与布线技巧、设计仿真与分析,以及制造准备与后期处理的策略和方法。通过深入分析原理图和PCB设计中常见问题的解决方法,提出提高设计效率的实用技巧。本文还强调了设计仿真对于确保电路设计质量的重要性,并探讨了如
深入浅出DevOps文化:7个秘诀打造极致高效IT团队

# 摘要
DevOps作为一种文化和实践,着重于打破传统开发与运营之间的壁垒,以提升软件交付的速度、质量和效率。本文首先概述了DevOps文化及其核心原则,包括其定义、起源、核心价值观和实践框架。随后,深入探讨了DevOps实践中关键工具和技术的应用,如持续集成与持续部署、配置管理、基础设施自动化、监控与日志管理。文中进一步分析了DevOps在团队建设与管理中的重要性,以及如何在不同行业中落地实施。最后,展望了Dev
【TDC-GP21手册常见问题解答】:行业专家紧急排错,疑难杂症秒解决
# 摘要
TDC-GP21手册是针对特定设备的操作与维护指南,涵盖了从基础知识到深度应用的全方位信息。本文首先对TDC-GP21手册进行了概览,并详细介绍了其主要功能和特点,以及基本操作指南,包括操作流程和常见问题的解决方法。随后,文章探讨了TDC-GP21手册在实际工作中的应用情况和应用效果评估,以及手册高级
Allwinner A133应用案例大揭秘:成功部署与优化的不传之秘
# 摘要
本文全面介绍了Allwinner A133芯片的特点、部署、应用优化策略及定制案例,并展望了其未来技术发展趋势和市场前景。首先概述了A133芯片的基本架构和性能,接着详细探讨了基于A133平台的硬件选择、软件环境搭建以及初步部署测试方法。随后,本文深入分析了针对Allwinner A133的系统级性能调优和应用程序适配优化,包括内核调整、文件系统优化、应用性能分析以及能耗管理等方面。在深度定制案例方面,文章探讨了定制化操作系统构建、多媒体和AI功能集成以及安全隐私保护措施。最后,文章展望了Allwinner A133的技术进步和行业挑战,并讨论了社区与开发者支持的重要性。
# 关键
宇视EZVMS数据安全战略:备份与恢复的最佳实践
# 摘要
随着信息技术的快速发展,数据安全成为了企业和组织管理中的核心议题。宇视EZVMS作为一个成熟的视频管理系统,在数据备份与恢复方面提供了全面的技术支持和实践方案。本文首先概述了数据安全的重要性,并对宇视EZVMS的备份技术进行了理论探讨与实际操作分析。接着,本文深入讨论了数据恢复的重要性、挑战以及实际操作步骤,并提出了高级备份与恢复策略。通过案例分析,本文分享了宇视
【AD与DA转换终极指南】:数字与模拟信号转换的全貌解析
# 摘要
本文系统性地介绍了模数转换(AD)和数模转换(DA)的基础理论、实践应用及性能优化,并展望了未来的发展趋势与挑战。首先,概述了AD和DA转换的基本概念,随后深入探讨了AD转换器的理论与实践,包括其工作原理、类型及其特点,以及在声音和图像信号数字化中的应用。接着,详细分析了DA转换器的工作原理、分类和特点,以及其在数字音频播放和数字控制系统中的应用。第四章重点讨论了AD与DA转换在现代技术中
Innovus用户必读:IEEE 1801标准中的DRC与LVS高级技巧
# 摘要
本文详细介绍了IEEE 1801标准的概况,深入探讨了设计规则检查(DRC)的基础知识和高级技巧,并展示了如何优化DRC规则的编写和维护。文章还分析了布局与验证(LVS)检查的实践应用,以及如何在DRC和LVS之间实现协同验证。此外,本文阐述了在Innovus工具中采用的多核并行处理、层次化设计验证技术以及故障排除和性能调优的策略。最后,通过具体案例分析
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )