【Discussion on Gradient Descent Algorithm】: Application of Gradient Descent Algorithm in Linear Regression Optimization
发布时间: 2024-09-14 18:01:17 阅读量: 21 订阅数: 44 

白色卡通风格响应式游戏应用商店企业网站模板.zip
# 1. In-depth Understanding of Gradient Descent Algorithm
The gradient descent algorithm is a pivotal component in the realm of optimization algorithms, characterized by its simplicity and robust power. Widely utilized in machine learning to seek the optimal solution for loss functions, the fundamental concept involves iteratively updating parameters in the direction of the descending gradient of the objective function, gradually approaching the optimal solution. There are various variants of gradient descent, such as batch gradient descent, stochastic gradient descent, and mini-batch gradient descent, each suited to different scenarios.
### Learning Objectives:
- Understand the basic principles of gradient descent.
- Master the characteristics and应用场景of different gradient descent algorithms.
- Deeply analyze the relationship between gradient descent and linear regression optimization.
This chapter will guide you through an in-depth study of the gradient descent algorithm, laying a solid theoretical foundation for subsequent linear regression optimization.
# 2. Linear Regression Fundamentals
### 2.1 Understanding Linear Regression Principles
#### 2.1.1 Linear Regression Model
Linear regression is a fundamental method of regression analysis, used to describe the linear relationship between independent variables and dependent variables. Its mathematical expression is as follows:
y = β_0 + β_1*x_1 + β_2*x_2 + ... + β_n*x_n
Where y is the dependent variable, x_i (i=1,2,...,n) are independent variables, and β_i are the corresponding coefficients for the independent variables.
#### 2.1.2 Least Squares Method Solution
The least squares method is a common parameter estimation technique that fits model parameters by minimizing the sum of squared residuals between actual observed values and model predicted values. The specific formula is as follows:
\underset{\beta}{\min} \sum_{i=1}^{n}(y_i - \beta_0 - \sum_{j=1}^{p}\beta_j*x_{ij})^2
#### 2.1.3 Regression Evaluation Metrics
Common evaluation metrics in linear regression tasks include Mean Squared Error (MSE), Root Mean Squared Error (RMSE), and Coefficient of Determination (R^2), which are used to measure the goodness of model fit.
### 2.2 Linear Regression Practice
#### 2.2.1 Data Preparation and Feature Engineering
When undertaking a linear regression task, data preparation and feature engineering are the first steps. This includes data cleaning, feature selection, feature transformation, etc., to enhance the model's accuracy and generalization capabilities.
#### 2.2.2 Model Training and Evaluation
Next, input the prepared data into the linear regression model for training and evaluation. Fit model parameters using training data, then use test data to assess model performance, obtaining evaluation metrics for comparative analysis.
#### 2.2.3 Result Analysis and Optimization
Finally, based on the results of model training and evaluation, perform result analysis and optimization measures. The linear regression model can be optimized by adjusting features, trying different optimization algorithms, and tweaking hyperparameters, thereby enhancing the model's predictive and generalization abilities.
Through the above practical operations, you can better understand the basic principles of the linear regression model and apply it to real-world problems.
# 3. Principles of the Gradient Descent Algorithm
The gradient descent algorithm plays a crucial role in the field of machine learning, capable of effectively optimizing model parameters and serving as the foundation for many optimization algorithms. In this chapter, we will delve into the principles of the gradient descent algorithm, including the concept of gradients, batch gradient descent, stochastic gradient descent, and the specifics of mini-batch gradient descent algorithms.
### 3.1 Concept of Gradient
#### 3.1.1 Definition of Gradient
In mathematics, the gradient is a vector composed of a set of partial derivatives, representing the direction derivative of a function at a point in all directions. For the objective function J(θ), the gradient ∇J(θ) can be expressed as:
∇J(θ) = \begin{pmatrix} \dfrac{\partial J}{\partial \theta_1} \\ \dfrac{\partial J}{\partial \theta_2} \\ \vdots \\ \dfrac{\partial J}{\partial \theta_n} \end{pmatrix}
#### 3.1.2 Direction of Gradient Descent
The gradient descent algorithm updates parameters in the opposite direction of the gradient to gradually approach the optimal value of the objective function. The update rule is:
θ = θ - α ∇J(θ)
#### 3.1.3 Selection of Learning Rate
The learning rate α determines the step size of parameter updates; too large may cause oscillation, and too small may lead to slow convergence. Choosing an appropriate learning rate is crucial for the algorithm's performance.
### 3.2 Batch Gradient Descent
#### 3.2.1 Steps of Batch Gradient Descent Algorithm
Batch gradient descent computes the gradient using all samples and updates the parameters. Algorithm steps include:
1. Calculate the gradient of the entire training set;
2. Update parameters based on the gradient;
3. Repeat the above steps until convergence.
#### 3.2.2 Advantages and Disadvantages of

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【Scrapy项目构建术】:一步步打造完美爬虫架构

# 摘要
Scrapy是一个开源且高效的网络爬虫框架,广泛应用于数据提取和抓取。本文首先对Scrapy项目的基础知识进行了介绍,然后深入探讨了其设计理念、核心架构,包括中间件的应用和Item Pipeline机制。在实践部署与优化方面,文中详述了创建Scrapy项目、数据抓取、性能优化及异常处理的策略。进一步,针对复杂场景下的应用,如分布式爬虫的实现、高级数据处理技术以及安全性
从头到尾理解IEEE 24 RTS:揭示系统数据的7大关键特性

# 摘要
本文详细介绍了IEEE 24 RTS标准的关键特性和在系统中的应用。首先,我们概述了IEEE 24 RTS标准及其在时间同步、事件排序、因果关系以及报文传输可靠性方面的关键特性。随后,文章分析了该标准在工业控制系统中的作用,包括控制指令同步和数据完整性的保障,并探讨了其在通信网络中提升效率和数据恢复能力的表现。进一步地,本文通过案例研究,展示了IEEE 24 RTS标准的实际应用、优化
控制系统的可靠性设计:提高系统的健壮性的6个实用策略
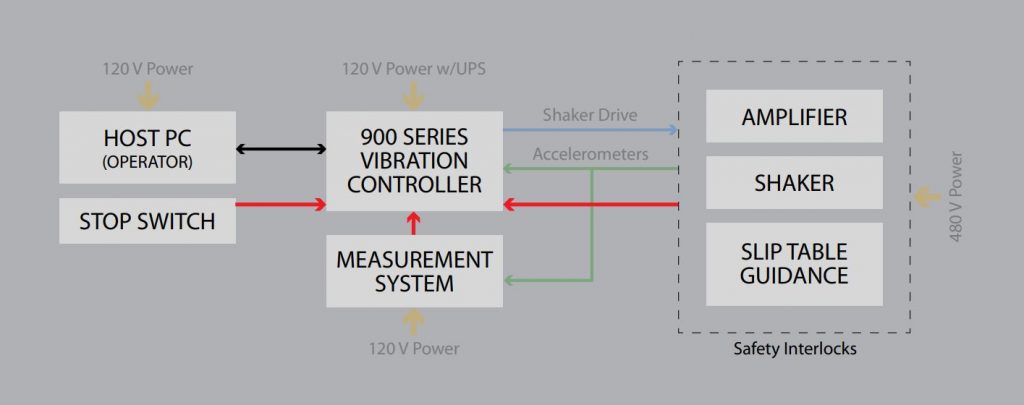
# 摘要
控制系统可靠性是确保系统安全、稳定运行的关键。本文首先介绍了控制系统可靠性的基础概念,然后深入探讨了提高系统可靠性的理论基础,包括可靠性理论、故障模式与影响分析(FMEA),以及冗余设计与多样性设计。接着,文章提出了提高系统健壮性的实用策略,如软件容错技术和硬件可靠性优化,以及系统更新与维护的重要性。通过分析工业自动化、交通控制和航空航天控制系统的案例,本文展示
鼎甲迪备操作员高级性能调优:挖掘更多潜能的5个技巧
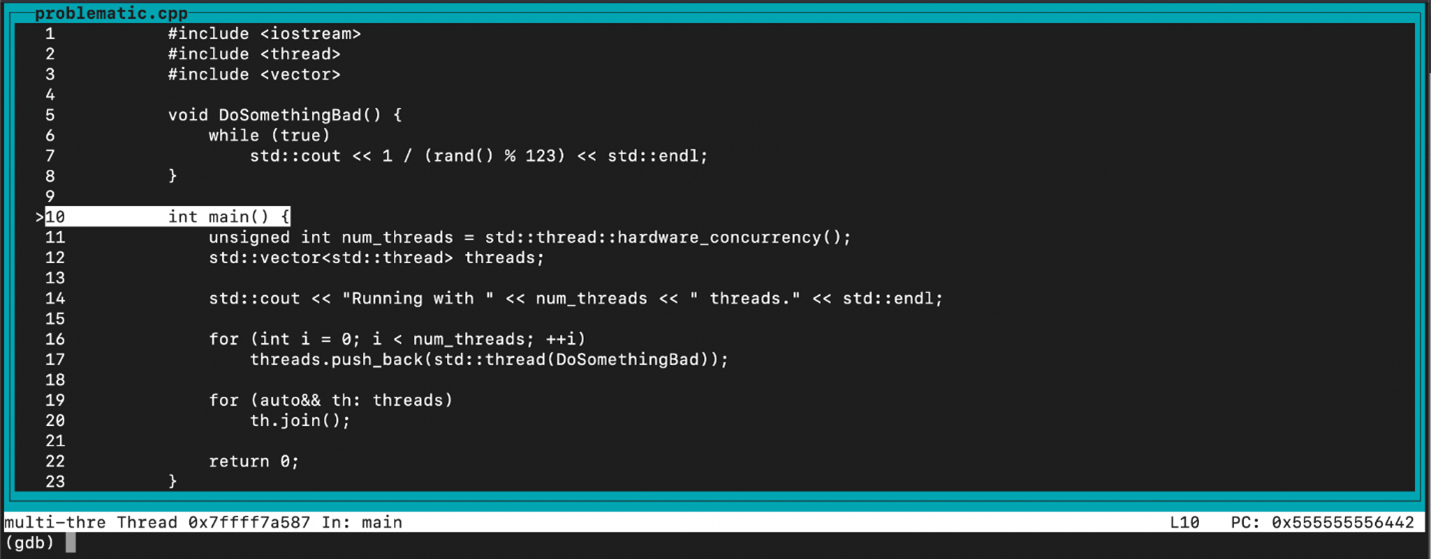
# 摘要
本文全面探讨了性能调优的策略和实践,涵盖了从系统监测到软硬件资源优化的各个方面。首先,文章介绍了性能调优的基本概念,并强调了系统监测工具选择和应用的重要性。接着,深入探讨了CPU、内存和存储等硬件资源的优化方法,以及如何通过调整数据库索引和应用程序代码来提升软件性能。文章还着重讨论了自动化性能测试的重要性和在持续集成/持续部署(CI/CD)流程中的集成策略。通过这些策略,能够有效提
STM32F407资源管理新境界:FreeRTOS信号量应用案例剖析
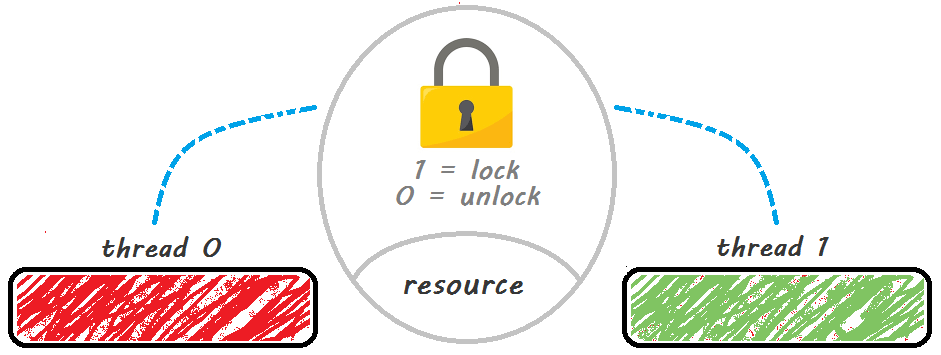
# 摘要
本文探讨了STM32F407微控制器与FreeRTOS实时操作系统相结合时,信号量的融合应用。首先介绍了FreeRTOS信号量的基本知识,包括其定义、功能、类型、用法,以及创建和销毁的API。随后,通过实际案例详细阐述了信号量在任务同步、资源互斥和事件通知中的具体应用。在此基础上,文章进一步讨论了信号量的高级应用,如优先级继承和
【NumPy实用技巧】:用Python高效生成3维数据的方法(数据生成秘籍)
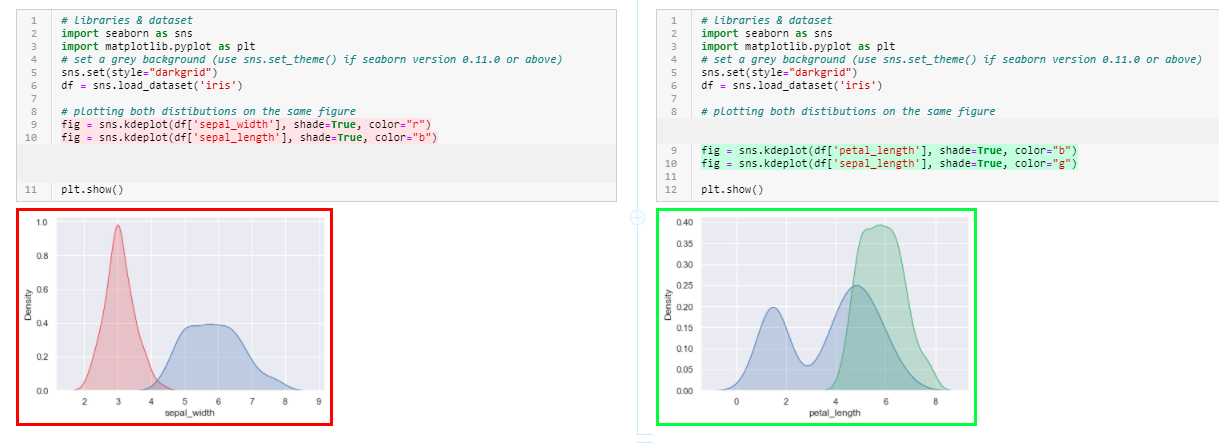
# 摘要
本文全面介绍了NumPy库,一个在数据科学领域广泛使用的Python库,特别强调了其在处理和操作数组方面的强大功能。文章首先概述了NumPy的基本概念及其在数据科学中的重要性,接着深入探讨了NumPy数组的基础知识,包括数组的创建、数据类型、索引和切片方法。进一步,本文阐述了高效生成和操作三维数据的NumPy技巧,强调了结构化数组和数组生成函数的应用。在高级应用方面,本文探讨了3维数据处理中的广播机制、向
电路板设计:ODB++错误检查与校验机制详解
# 摘要
本文全面介绍了ODB++格式,这是一种用于电路板设计数据交换的行业标准格式。文章首先概述了ODB++的格式和数据结构,深入分析了其文件组成、关键数据元素及其逻辑关系。其次,探讨了ODB++的错误检查机制,包括基本概念、常见错误类型及其定位和修复策略。第三部分着重讨论了校验机制的应用实践,以及校验流程、结果分析和工具的有效利用。最后,文章深入
【创新文化建设】:BSC在激发企业创新中的作用
# 摘要
创新文化建设对于企业的长期成功和市场竞争力至关重要。本文首先阐述了创新文化的重要性,并介绍了平衡计分卡(BSC)作为一种战略管理工具的基本原理。接着,本文详细探讨了BSC在企业创新活动中的具体应用,包括如何借助BSC确定创新目标、与创新流程协同以及在知识管理中扮演的角色。通过分析实践案例,本文揭示了BSC在不同行业中的创新应用,并总结了成功实施BSC的策略与所面临的挑战。最后,本文展望了BSC与新兴技术融合的未来趋势,并讨论了如何借助BSC推动企业文化创新的长远目标。
# 关键字
创新文化;平衡计分卡;战略管理;知识管理;案例分析;企业创新
参考资源链接:[绘制企业战略地图:从财
【WPE封包实战演练】:从零开始封包与解包过程解析

# 摘要
WPE封包技术是网络数据交互中常用的一种技术手段,它涉及到封包与解包的理论基础和实战技巧。本文从基础概览入手,深入探讨了封包技术的原理、网络协议封包格式及相应工具。随后,本文提供了一系列WPE封包操作的实战技巧,并分析了实战案例,以帮助理解和应用封包技术。在解包方面,本文介绍了基本流程、数据处理及安全性与法律考量。最后,本文探讨了封包技术的进阶应用,包括自动化优化、高级技术和未来发展
【VISA事件处理机制】:深入理解与优化技巧揭秘
# 摘要
VISA作为虚拟仪器软件架构,其事件处理机制在自动化测试与仪器控制领域发挥着关键作用。本文首先概述了VISA事件处理机制的基本概念和理论基础,包括VISA体系结构的核心组件和事件模型,之后详细介绍了VISA事件处理实践操作,以及在调试与优化方面的技巧。特别地,本文强调了在自动化测试框架中集成VISA以及实现并发模型的重要性。最后,本文探讨了VISA标准的未来发展趋势和新技术的融合可能性,提供了
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )