【Variable Selection Techniques】: Feature Engineering and Variable Selection Methods in Linear Regression
发布时间: 2024-09-14 17:44:11 阅读量: 35 订阅数: 22 

Linear regression with one variable
# 1. Introduction
In the field of machine learning, feature engineering and variable selection are key steps in building efficient models. Feature engineering aims to optimize data features to improve model performance, while variable selection helps to reduce model complexity and enhance predictive accuracy. This article will systematically introduce feature engineering and variable selection methods in linear regression, helping readers fully understand how to apply these techniques in actual projects to improve model performance and efficiency. By delving into the basics of linear regression and practical case studies, readers will explore how to conduct data preprocessing, feature selection, and variable optimization to build more reliable linear regression models.
# 2. Basics of Linear Regression
### 2.1 Overview of Linear Regression
Linear regression is a statistical model used to establish linear relationships between variables. It is commonly used for predicting the relationship between a continuous dependent variable (or response variable) and one or more independent variables (or predictor variables). The linear regression model can be represented as: $y = β0 + β1x1 + β2x2 + ... + βnxn + ε$, where y is the dependent variable, x1 to xn are the independent variables, β0 to βn are the coefficients, and ε is the error term.
### 2.2 Principles of Linear Regression
#### 2.2.1 Fitting a Line
In linear regression, the goal of fitting a line is to find a straight line that best fits the data points. The most common method is least squares, which determines the values of the coefficients by minimizing the sum of squared residuals, thus making the distance between the fitted line and the actual data points as small as possible.
#### 2.2.2 Least Squares Method
The least squares method is a commonly used fitting method in linear regression, which estimates parameters by minimizing the sum of the squared residuals between the observed values and the fitted values. Mathematically, the least squares method solves a system of equations where the partial derivatives of the parameters are zero to obtain the optimal solution, thereby determining the regression coefficients that minimize the sum of squared residuals between the fitted values and the actual observed values.
#### 2.2.3 Residual Analysis
Residuals are the differences between the actual values and the predicted values for each observation. Residual analysis is one method of assessing the goodness of model fit, ***mon residual analysis methods include checking the normality, independence, and homoscedasticity of residuals.
In the next chapter, we will delve into the importance of feature engineering and related methods.
# 3. Feature Engineering
### 3.1 Introduction to Feature Engineering
Feature engineering is a crucial aspect of machine learning, involving the collection, cleaning, transformation, and integration of data to provide high-quality input features for machine learning algorithms. In practice, good feature engineering can significantly improve model performance.
### 3.2 Data Preprocessing
Data preprocessing is the first step in feature engineering, aiming to clean and prepare raw data for model training. Data preprocessing includes two key parts: handling missing values and data standardization.
#### 3.2.1 Handling Missing Va***
***mon methods for dealing with missing values include deleting missing values, mean imputation, median imputation, and mode imputation.
```python
# Using mean imputation for missing values
data['column_name'].fillna(data['column_name'].mean(), inplace=True)
```
#### 3.2.2 Data Standardization
Data standardization is the process of transforming data features of different scales into a unified standard distribution, ***mon data standardization methods include Min-Max normalization and Z-Score normalization.
```python
# Using Min-Max standardization
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data_scaled = scaler.fit_transform(data)
```
### 3.3 Feature Selection Methods
Feature selection is the process of selecting features from the original features that have predictive power for the target variable, to reduce the complexity of the model and improve the model's generalization ability. Feature selection methods include filter feature selection, wrapper feature selection, and embedded feature selection.
#### 3.3.1 Filter Feature Selection
Filter feature selection is based on the statistical relationship between features and the target variable, with common indicators including correlation coefficients, chi-square tests, etc.
```python
# Using correlation coefficients for feature selection
correlation_matrix = data.corr()
selected_features = correlation_matrix[abs(correlation_matrix['target']) > 0.5].index
```
#### 3.3.2 Wrapper Feature Selection
Wrapper feature selection evaluates the importance of features by trying different combinations of features, with common methods including Recursive Feature Elimination (RFE), etc.
```python
# Using Recursive Feature Elimination for feature selection
from sklearn.feature_selection import RFE
from sklearn.linear_model import LinearRegression
selector = RFE(estimator=LinearRegression(), n_features_to_select=5)
selected_features = selector.fit(X, y).ranking_
```
#### 3.3.3 Embedded Feature Selection
Embedded feature selection integrates the feature selection process into model training, with common methods including Lasso regression, Ridge regression, etc.
```python
# Using Lasso regression for feature selection
from sklearn.linear_model import Lasso
lasso = Lasso(alpha=0.1)
lasso.fit(X, y)
selected_features = lasso.coef_.nonzero()[0]
```
In feature engineering, data preprocessing and feature selection are very important steps that can effectively improve model performance. Through proper feature engineering, models with better interpretability and generalization ability can be obtained.
# 4. Variable Selection Methods
In linear regression models, variable selection is a crucial step in model construction and optimization. Selecting the appropriate variables can improve the model's predictive performance and interpretability, avoid overfitting, and enhance the model's generalization ability. This chapter will introduce the significance of variable selection, basic variable selection methods, and som

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
专家指南:Origin图表高级坐标轴编辑技巧及实战应用
# 摘要
Origin是一款强大的科学绘图和数据分析软件,广泛应用于科学研究和工程领域。本文首先回顾了Origin图表的基础知识,然后深入探讨了高级坐标轴编辑技巧,包括坐标轴类型选择、刻度与标签调整、标题与单位设置以及复杂数据处理。接着,通过实战应用案例,展
【MATLAB 3D绘图专家教程】:meshc与meshz深度剖析与应用案例
# 摘要
本文系统介绍了MATLAB中用于3D数据可视化的meshc与meshz函数。首先,本文概述了这两
【必看】域控制器重命名前的系统检查清单及之后的测试验证
# 摘要
本文详细阐述了域控制器重命名的操作流程及其在维护网络系统稳定性中的重要性。在开始重命名前,本文强调了进行域控制器状态评估、制定备份策略和准备用户及应用程序的必要性。接着,介绍了具体的重命名步骤,包括系统检查、执行重命名操作以及监控整个过程。在重命名完成后,文章着重于如何通过功能性测试
HiLink SDK高级特性详解:提升设备兼容性的秘籍

# 摘要
本文对HiLink SDK进行全面介绍,阐述其架构、组件、功能以及设备接入流程和认证机制。深入探讨了HiLink SDK的网络协议与数据通信机制,以及如何提升设备的兼容性和优化性能。通过兼容性问题诊断和改进策略,提出具体的设备适配与性能优化技术。文章还通过具体案例分析了HiL
【ABAQUS与ANSYS终极对决】:如何根据项目需求选择最合适的仿真工具
# 摘要
本文系统地分析了仿真工具在现代工程分析中的重要性,并对比了两大主流仿真软件ABAQUS与ANSYS的基础理论框架及其在不同工程领域的应用。通过深入探讨各自的优势与特点,本文旨在为工程技术人员提供关于软件功能、操作体验、仿真精度和结果验证的全面视角。文章还对软件的成本效益、技术支持与培训资源进行了综合评估,并分享了用户成功案例。最后,展望了仿真技术的未来发展
【备份策略】:构建高效备份体系的关键步骤
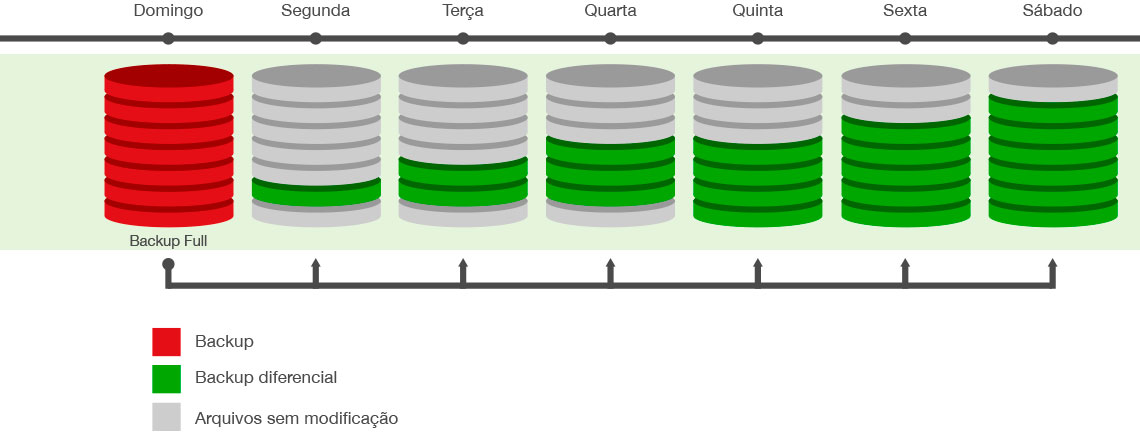
# 摘要
备份策略是确保数据安全和业务连续性的核心组成部分。本文从理论基础出发,详细讨论了备份策略的设计、规划与执行,并对备份工具的选择和备份环境的搭建进行了分析。文章探讨了不同
【脚本自动化教程】:Xshell批量管理Vmware虚拟机的终极武器
# 摘要
本文全面概述了Xshell与Vmware脚本自动化技术,从基础知识到高级技巧再到实践应用,详细介绍了如何使用Xshell脚本与Vmware命令行工具实现高效的虚拟机管理。章节涵盖Xshell脚本基础语法、Vmware命令行工具的使用、自动化脚本的高级技巧、以及脚本在实际环境中的应用案例分析。通过深入探讨条件控制、函数模块化编程、错误处理与日
【增量式PID控制算法的高级应用】:在温度控制与伺服电机中的实践

# 摘要
增量式PID控制算法作为一种改进型的PID控制方法,在控制系统中具有广泛应用前景。本文首先概述了增量式PID控制算法的基本概念、理论基础以及与传统PID控制的比较,进而深入探讨了其在温度控制系统和伺服电机控制系统的具体应用和性能评估。随后,文章介绍了增量式PID控制算法的高级优化技术
【高级应用】MATLAB在雷达测角技术中的创新策略

# 摘要
MATLAB作为一种强大的工程计算软件,其在雷达测角技术领域具有广泛的应用。本文系统地探讨了MATLAB在雷达信号处理、测角方法、系统仿真以及创新应用中的具体实现和相关技术。通过分析雷达信号的采集、预处理、频谱分析以及目标检测算法,揭示了MATLAB在提升信号处理效率和准确性方面的关键作用。进一步,本文探讨了MATLAB在雷达测角建模、算法实现与性能评估中的应用,并提供了基于机器
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )