【Comparison Between SGD and BGD】: Comparison and Selection of Stochastic Gradient Descent and Batch Gradient Descent
发布时间: 2024-09-14 18:02:39 阅读量: 18 订阅数: 34 
# 1. Introduction: Comparing SGD and BGD
In the realm of machine learning, optimization algorithms play a pivotal role in the training and performance of models. Gradient descent is one of the commonly used optimization methods, and among them, Batch Gradient Descent (BGD) and Stochastic Gradient Descent (SGD) are two typical representatives. This chapter will introduce the comparison of these two methods, helping readers to better understand their similarities and differences, and to choose between them in practical applications.
Understanding when to use BGD and when to use SGD is crucial for achieving good training results. Next, we will delve into BGD and SGD, helping readers to fully understand their principles, pros and cons, and applicable scenarios, so that they can be better applied to actual machine learning tasks.
# 2.1 Overview and Principle Analysis of BGD
Batch Gradient Descent (BGD) is an optimization algorithm used to find the minimum value of a function, especially for training machine learning models. In this section, we will explore the overview and principles of BGD in depth.
### 2.1.1 What is Gradient Descent?
Gradient descent is an optimization algorithm that iteratively reduces the numerical value of the objective function. It uses the gradient information of the objective function to guide the search direction, thereby finding the minimum value of the function.
### 2.1.2 Principles of the Batch Gradient Descent Algorithm
The core idea of BGD is to use the gradient of all samples when updating model parameters to calculate the adjustment amount for the parameters. Specifically, for model parameter **θ**, the update formula is as follows:
```python
θ = θ - α * ∇J(θ)
```
Where, α represents the learning rate, and ∇J(θ) represents the gradient of the loss function J(θ) with respect to θ.
### 2.1.3 The Relationship Between BGD and the Method of Least Squares
BGD is closely related to the method of least squares. In the method of least squares, model parameters are solved by minimizing the sum of squared errors between actual and predicted values. BGD can be considered as a numerical optimization algorithm and is one of the common methods for solving parameters in the method of least squares.
## 2.2 Analysis of Advantages and Disadvantages of BGD
In practice, BGD, as a classic optimization algorithm, has certain advantages and disadvantages. We will analyze them in detail next.
### 2.2.1 Advantages: Guarantee of Global Optimum
Since BGD uses all data samples for gradient computation, it can guarantee convergence to a global optimum under reasonable conditions, especially for optimization problems of convex functions.
### 2.2.2 Disadvantages: Large Computation and Slow Convergence
Although BGD can converge globally, in the case of large datasets, computing the gradient of all samples leads to large computation and slow convergence, especially in high-dimensional feature spaces.
### 2.2.3 The Application of BGD on Large Datasets
On large datasets, the disadvantages of BGD become more pronounced, with long computation times and low efficiency. Therefore, in scenarios with large datasets, optimization algorithms such as Stochastic Gradient Descent (SGD) are usually considered to speed up training.
With the introduction of the above sections, we have a preliminary understanding of the concept, principles, and pros and cons of BGD. In the following sections, we will delve into the Stochastic Gradient Descent (SGD) algorithm to further complete our understanding of different gradient descent algorithms.
# 3. In-depth Understanding of Stochastic Gradient Descent (SGD)
Stochastic Gradient Descent (SGD) is an optimization algorithm that, compared to Batch Gradient Descent (BGD), is more suitable for large datasets. The following will delve into the principles, pros and cons analysis, and comparison with Mini-batch gradient descent of SGD.
### 3.1 Overview and Principle Analysis of SGD
#### 3.1.1 What is Stochastic Gradient Descent?
Stochastic Gradient Descent is an optimization method that updates parameters using only one sample per iteration, estimating the overall gradient descent direction by randomly selecting small batches of data, ultimately finding the optimal solution.
#### 3.1.2 Principles of the Stochastic Gradient Descent Algorithm
- Initialize model parameters
- Randomly select a sample
- Calculate the gradient of the sample
- Update model parameters based on the gradient
- Repeat the above steps until convergence conditions are met
#### 3.1.3 Comparison Between SGD and Mini-batch Gradient Descent
SGD is similar to Mini-batch gradient descent, the difference being that Mini-batch selects a small portion of data for gradient computation, while SGD selects only one data point each time. The advantage of SGD is that each iteration is fast, making it suitable for large datasets.
### 3.2 Analysis of Advantages and Disadvantages of SGD
#### 3.2.1 Advantages: Fast Computation and Suitability for Large Datasets
- Advantage One: Since SGD only needs to compute one sample per iteration, it is faster.
- Advantage Two: For large datasets, SGD is computationally efficient and can find local optima more quickly.
#### 3.2.2 Disadvantages: Unstable Convergence and Likelihood of Local Optima
- Disadvantage One: Due to using only one sample per iteration, SGD has a high degree of randomness in the update directi

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
R语言tm包中的文本聚类分析方法:发现数据背后的故事

# 1. 文本聚类分析的理论基础
## 1.1 文本聚类分析概述
文本聚类分析是无监督机器学习的一个分支,它旨在将文本数据根据内容的相似性进行分组。文本数据的无结构特性导致聚类分析在处理时面临独特挑战。聚类算法试图通过发现数据中的自然分布来形成数据的“簇”,这样同一簇内的文本具有更高的相似性。
## 1.2 聚类分
R语言中的数据可视化工具包:plotly深度解析,专家级教程

# 1. plotly简介和安装
Plotly是一个开源的数据可视化库,被广泛用于创建高质量的图表和交互式数据可视化。它支持多种编程语言,如Python、R、MATLAB等,而且可以用来构建静态图表、动画以及交互式的网络图形。
## 1.1 plotly简介
Plotly最吸引人的特性之一
文本挖掘中的词频分析:rwordmap包的应用实例与高级技巧

# 1. 文本挖掘与词频分析的基础概念
在当今的信息时代,文本数据的爆炸性增长使得理解和分析这些数据变得至关重要。文本挖掘是一种从非结构化文本中提取有用信息的技术,它涉及到语言学、统计学以及计算技术的融合应用。文本挖掘的核心任务之一是词频分析,这是一种对文本中词汇出现频率进行统计的方法,旨在识别文本中最常见的单词和短语。
词频分析的目的不仅在于揭
【R语言qplot深度解析】:图表元素自定义,探索绘图细节的艺术(附专家级建议)

# 1. R语言qplot简介和基础使用
## qplot简介
`qplot` 是 R 语言中 `ggplot2` 包的一个简单绘图接口,它允许用户快速生成多种图形。`qplot`(快速绘图)是为那些喜欢使用传统的基础 R 图形函数,但又想体验 `ggplot2` 绘图能力的用户设
模型结果可视化呈现:ggplot2与机器学习的结合
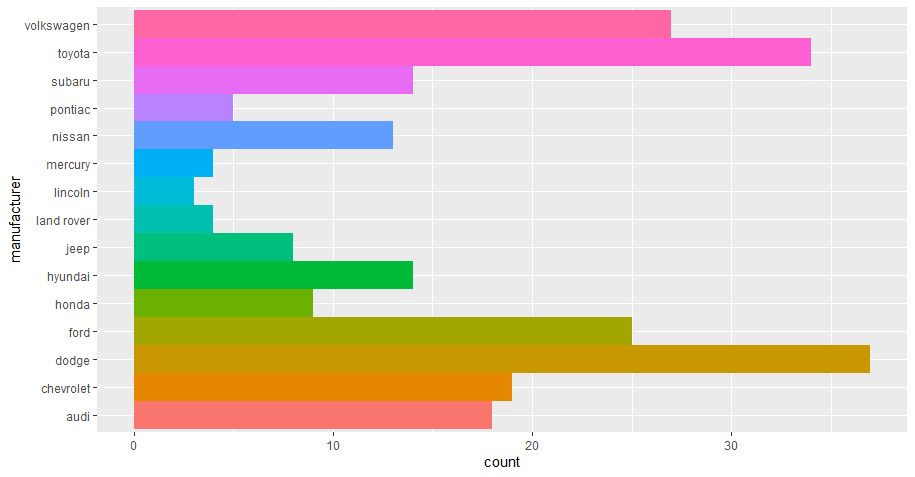
# 1. ggplot2与机器学习结合的理论基础
ggplot2是R语言中最受欢迎的数据可视化包之一,它以Wilkinson的图形语法为基础,提供了一种强大的方式来创建图形。机器学习作为一种分析大量数据以发现模式并建立预测模型的技术,其结果和过程往往需要通过图形化的方式来解释和展示。结合ggplot2与机器学习,可以将复杂的数据结构和模型结果以视觉友好的形式展现
【Tau包自定义函数开发】:构建个性化统计模型与数据分析流程

# 1. Tau包自定义函数开发概述
在数据分析与处理领域, Tau包凭借其高效与易用性,成为业界流行的工具之一。 Tau包的核心功能在于能够提供丰富的数据处理函数,同时它也支持用户自定义函数。自定义函数极大地提升了Tau包的灵活性和可扩展性,使用户可以针对特定问题开发出个性化的解决方案。然而,要充分利用自定义函数,开发者需要深入了解其开发流程和最佳实践。本章将概述Tau包自定义函数开发的基本概
R语言动态图形:使用aplpack包创建动画图表的技巧
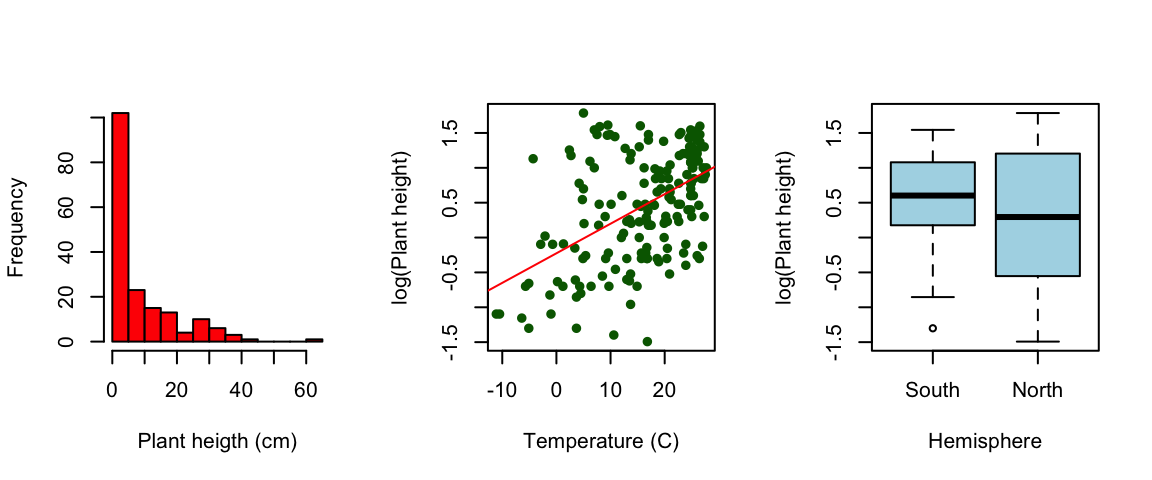
# 1. R语言动态图形简介
## 1.1 动态图形在数据分析中的重要性
在数据分析与可视化中,动态图形提供了一种强大的方式来探索和理解数据。它们能够帮助分析师和决策者更好地追踪数据随时间的变化,以及观察不同变量之间的动态关系。R语言,作为一种流行的统计计算和图形表示语言,提供了丰富的包和函数来创建动态图形,其中apl
【R语言数据包安全编码实践】:保护数据不受侵害的最佳做法

# 1. R语言基础与数据包概述
## R语言简介
R语言是一种用于统计分析、图形表示和报告的编程语言和软件环境。它在数据科学领域特别受欢迎,尤其是在生物统计学、生物信息学、金融分析、机器学习等领域中应用广泛。R语言的开源特性,加上其强大的社区
ggmap包技巧大公开:R语言精确空间数据查询的秘诀
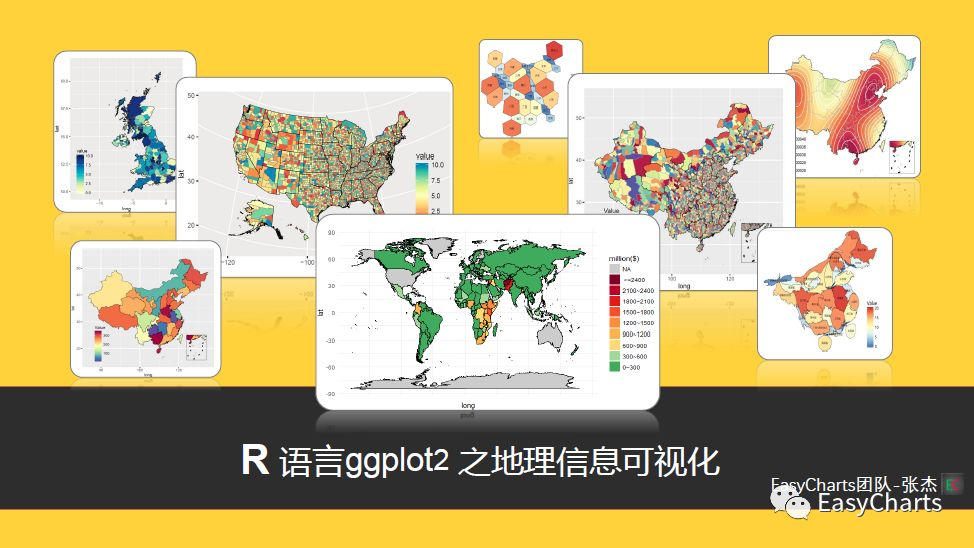
# 1. ggmap包简介及其在R语言中的作用
在当今数据驱动
【lattice包与其他R包集成】:数据可视化工作流的终极打造指南

# 1. 数据可视化与R语言概述
数据可视化是将复杂的数据集通过图形化的方式展示出来,以便人们可以直观地理解数据背后的信息。R语言,作为一种强大的统计编程语言,因其出色的图表绘制能力而在数据科学领域广受欢迎。本章节旨在概述R语言在数据可视化中的应用,并为接下来章节中对特定可视化工具包的深入探讨打下基础。
在数据科学项目中,可视化通
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )