Multi-layer Perceptrons (MLP) in the Medical Field: Applications and Practice, Empowering Medical Diagnostics, Enhancing Medical Standards
发布时间: 2024-09-15 08:17:16 阅读量: 24 订阅数: 31 

Multi-Layer-Perceptrons:我的AI模块未完成的工作
# Multilayer Perceptron (MLP) in the Medical Field: Applications and Practices, Empowering Medical Diagnostics, Enhancing Medical Quality
## 1. Fundamentals of Multilayer Perceptron (MLP)
Multilayer Perceptron (MLP) is a feedforward neural network consisting of an input layer, an output layer, and multiple hidden layers. Neurons in each hidden layer are connected to neurons in the preceding layer through weights and biases. MLP is capable of learning complex nonlinear relationships, making it a powerful tool for various tasks in the medical field.
The training process of MLP involves using the backpropagation algorithm to minimize the loss function. The loss function measures the difference between the model's predictions and the true labels. Through iterative adjustments to the weights and biases, MLP can gradually reduce the loss and improve its predictive accuracy.
The architecture and hyperparameters of MLP, such as the number of layers, the number of neurons, and the activation function, are crucial to the model's performance. Optimizing these parameters requires careful hyperparameter tuning and cross-validation to find the best configuration.
## 2. Applications of MLP in Medical Diagnostics
### 2.1 Disease Diagnosis
Multilayer Perceptron (MLP) plays a crucial role in medical diagnostics by analyzing clinical data and medical images of patients to assist doctors in making more accurate diagnoses.
### 2.1.1 Cardiovascular Disease Diagnosis
MLP has been widely applied in the diagnosis of cardiovascular diseases, such as heart attacks, heart failure, and arrhythmias. By analyzing patient data, including electrocardiograms (ECG) and echocardiograms (ECHO), MLP can identify abnormal cardiac patterns and predict the risk of diseases.
```python
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
# Load cardiovascular disease dataset
data = pd.read_csv('heart_disease.csv')
# Split dataset into training set and test set
X_train, X_test, y_train, y_test = train_test_split(data.drop('target', axis=1), data['target'], test_size=0.2)
# Create MLP classifier
mlp = MLPClassifier(hidden_layer_sizes=(128, 64), max_iter=1000)
# Train MLP classifier
mlp.fit(X_train, y_train)
# Evaluate MLP classifier
score = mlp.score(X_test, y_test)
print('MLP classifier accuracy:', score)
```
### 2.1.2 Cancer Diagnosis
MLP can also be used for cancer diagnosis, such as breast cancer, lung cancer, and colorectal cancer. By analyzing patient pathology images, genomic data, and clinical features, MLP can help doctors distinguish between benign and malignant tumors and predict the prognosis of the disease.
### 2.2 Medical Image Analysis
MLP has a wide range of applications in medical image analysis, including medical image classification and segmentation.
### 2.2.1 Medical Image Classification
MLP can be used to classify medical images, such as X-rays, CT scans, and MRI images. By extracting features from the images, MLP can identify different anatomical structures, lesions, and abnormalities.
```python
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications import VGG16
from tensorflow.keras.layers import Dense, GlobalAveragePooling2D
from tensorflow.keras.models import Model
# Load VGG16 pretrained model
base_model = VGG16(include_top=False, weights='imagenet', input_shape=(224, 224, 3))
# Add fully connected layers and global average pooling layer
x = base_model.output
x = GlobalAveragePooling2D()(x)
x = Dense(256, activation='relu')(x)
predictions = Dense(1, activation='sigmoid')(x)
# Create model
model = Model(inputs=base_model.input, outputs=predictions)
# ***
***pile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Load medical image dataset
train_datagen = ImageDataGenerator(rescale=1./255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True)
train_generator = train_datagen.flow_from_directory('medical_images/train', target_size=(224, 224), batch_size=32, class_mode='binary')
# Train model
model.fit(train_generator, epochs=10)
```
### 2.2.2 Medical Image Segmentation
MLP can also be used for medical image segmentation, such as segmenting tumors, organs, and blood vessels. By learning the spatial relationships within the images, MLP can generate precise segmentation masks to assist doctors in diagnostics and treatment planning.
```python
import torch
from torch import nn
from torch.nn import functional
```

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
XJC-CF3600F效率升级秘诀
# 摘要
本文对XJC-CF3600F打印机进行了全面的概述,深入探讨了其性能优化理论,包括性能指标解析、软件配置与优化、打印材料与环境适应性等方面。在实践应用优化方面,本文详细讨论了用户交互体验的提升、系统稳定性的提高及故障排除方法,以及自动化与集成解决方案的实施。此外,本文还探
【C++编程精进秘籍】:17个核心主题的深度解答与实践技巧
# 摘要
本文全面探讨了C++编程语言的核心概念、高级特性及其在现代软件开发中的实践应用。从基础的内存管理到面向对象编程的深入探讨,再到模板编程与泛型设计,文章逐层深入,提供了系统化的C++编程知识体系。同时,强调了高效代码优化的重要性,探讨了编译器优化技术以及性能测试工具的应用。此外,本文详细介绍了C++标准库中容器和算法的高级用法,以及如何处理输入输出和字符串。案例分析部分则
【自动化调度系统入门】:零基础理解程序化操作
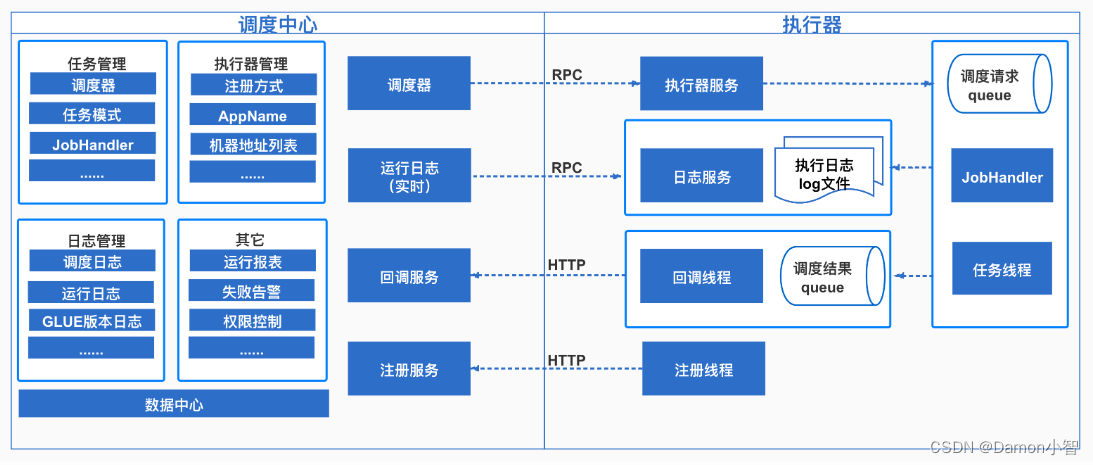
# 摘要
自动化调度系统是现代信息技术中的核心组件,它负责根据预定义的规则和条件自动安排和管理任务和资源。本文从自动化调度系统的基本概念出发,详细介绍了其理论基础,包括工作原理、关键技术、设计原则以及日常管理和维护。进一步,本文探讨了如何在不同行业和领域内搭建和优化自动化调度系统的实践环境,并分析了未来技术趋势对自动化调度系统的影响。文章通过案例分析展示了自动化调度系统在提升企业流程效率、成本控制
打造低延迟无线网络:DW1000与物联网的无缝连接秘籍
# 摘要
本文深入探讨了无线网络与物联网的基本概念,并重点介绍了DW1000无线通信模块的原理与特性。通过对DW1000技术规格、性能优势以及应用案例的分析,阐明了其在构建低延迟无线网络中的关键作用。同时,文章详细阐述了DW1000与物联网设备集成的方法,包括硬件接口设计、软件集成策略和安全性
【C#打印流程完全解析】:从预览到输出的高效路径
# 摘要
本文系统地介绍了C#中打印流程的基础与高级应用。首先,阐释了C#打印流程的基本概念和打印预览功能的实现,包括PrintPreviewControl控件的使用、自定义设置及编程实现。随后,文章详细讨论了文档打印流程的初始化、文档内容的组织与布局、执行与监控方法。文章继续深入到打印流程的高级应用,探讨了打印作业的管理、打印服务的交互以及打印输出的扩展功能。最后,提出了C#打印流程的调试技巧、性能优化策略和最佳实践,旨在帮助开发者高效地实现高质量的打印功能。通过对打印流程各个层面的详细分析和优化方法的介绍,本文为C#打印解决方案的设计和实施提供了全面的理论和实践指导。
# 关键字
C#打
LaTeX排版秘籍:美化文档符号的艺术

# 摘要
本文系统介绍了LaTeX排版系统的全面知识,涵盖符号排版、数学公式处理、图表与列表设置、文档样式定制及自动化优化五个主要方面。首先,本文介绍了
OpenProtocol-MTF6000通讯协议深度解析:掌握结构与应用
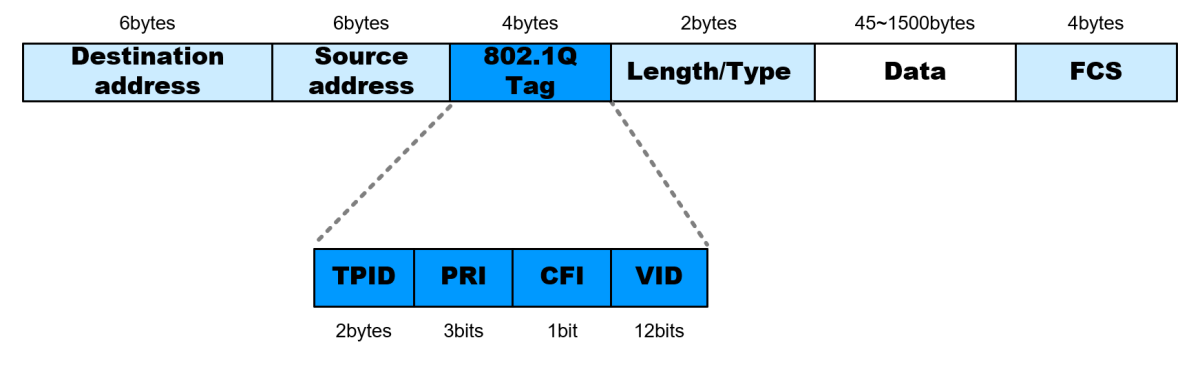
# 摘要
本文全面介绍了OpenProtocol-MTF6000通讯协议,涵盖了协议的基本概念、结构、数据封装、实践应用以及高级特性和拓展。首先,概述了OpenProtocol-MTF6000协议的框架、数据封装流程以及数据字段的解读和编码转换。其次,探讨了协议在工业自动化领域的应用,包括自动化设备通信实例、通信效率和可
【Android性能优化】:IMEI码获取对性能影响的深度分析
# 摘要
随着智能手机应用的普及和复杂性增加,Android性能优化变得至关重要。本文首先概述了Android性能优化的必要性和方法,随后深入探讨了IMEI码获取的基础知识及其对系统性能的潜在影响。特别分析了IMEI码获取过程中资源消耗问题,以及如何通过优化策略减少这些负面影响。本文还探讨了性能优化的最佳实践,包括替代方案和案例研究,最后展望了Android性能优化的未来趋势,特别是隐私保护技术的发展和深度学习在
【后端性能优化】:架构到代码的全面改进秘籍
# 摘要
随着互联网技术的快速发展,后端性能优化已成为提升软件系统整体效能的关键环节。本文从架构和代码两个层面出发,详细探讨了性能优化的多种策略和实践方法。在架构层面,着重分析了负载均衡、高可用系统构建、缓存策略以及微服务架构的优化;在代码层面,则涉及算法优化、数据结构选择、资源管理、异步处理及并发控制。性能测试与分析章节提供了全面的测试基础理论和实
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )