Batch Normalization and Multilayer Perceptrons (MLPs): Enhancing Training Stability, Accelerating Convergence, and Optimizing Model Performance
发布时间: 2024-09-15 08:07:17 阅读量: 31 订阅数: 31 

Batch Normalization:Accelerating Deep Network Training
# 1. Batch Normalization Overview
Batch Normalization (BN) is a regularization technique designed to stabilize the training process of deep neural networks. By normalizing the data of each batch, it reduces internal covariate shift, thus enhancing the training stability of the model. BN is widely applied in deep neural networks such as Multi-Layer Perceptrons (MLPs), effectively boosting the model's convergence speed and performance.
# 2. Batch Normalization Principles and Implementation
### 2.1 Mathematical Foundations of Batch Normalization
Batch Normalization is a commonly used regularization technique in deep learning that aims to mitigate the impact of Internal Covariate Shift (ICS) by normalizing the mean and variance of each mini-batch of data, thereby enhancing the model's stability and convergence speed.
**Mean and Variance Normalization**
In Batch Normalization, for a given mini-batch of data, the mean and variance are calculated as follows:
```
μ_B = 1/m * ∑(x_i - μ)
σ_B^2 = 1/m * ∑(x_i - μ)^2
```
Where:
* μ_B is the mean of the mini-batch data
* σ_B^2 is the variance of the mini-batch data
* m is the size of the mini-batch
* x_i is the i-th data point in the mini-batch
* μ is the overall mean of the mini-batch data
**Normalization Transformation**
After calculating the mean and variance, the mini-batch data undergoes a normalization transformation, which is expressed as:
```
y_i = (x_i - μ_B) / √(σ_B^2 + ε)
```
Where:
* y_i is the normalized data point
* ε is a small constant to prevent division by zero
The data points after normalization have zero mean and unit variance, which helps reduce the impact of ICS.
### 2.2 Batch Normalization Algorithm Flow
The Batch Normalization algorithm flow is as follows:
1. **Compute the mean and variance of the mini-batch data**: Calculate the mean μ_B and variance σ_B^2 of the mini-batch data using the formulas.
2. **Normalize the mini-batch data**: Normalize the mini-batch data using the normalization transformation formula to obtain the normalized data y_i.
3. **Scaling and Translation Transformations**: To restore the expressive power of the data distribution, perform scaling and translation transformations on the normalized data, which are expressed as:
```
z_i = γ * y_i + β
```
Where:
* z_i is the data point after scaling and translation transformations
* γ and β are learnable parameters
### 2.3 Variants and Extensions of Batch Normalization
In addition to the standard Batch Normalization, there are various variants and extensions, including:
**Group Normalization**: Divides the mini-batch data into multiple groups and normalizes each group separately.
**Layer Normalization**: Normalizes each neural network layer instead of the mini-batch data.
**Instance Normalization**: Normalizes each data point instead of the mini-batch data.
**Weight Normalization**: Normalizes the weight matrix instead of the activation values.
# 3. Batch Normalization Application in Multi-Layer Perceptrons
### 3.1 Enhancement of MLP Training Stability through Batch Normalization
Batch Normalization can enhance the stability of MLP training by reducing internal covariate shift. In multi-layer neural networks, the input distribution of each layer changes as training progresses, which can lead to gradient vanishing or exploding problems. Batch Normalization fixes the input distribution to a standard normal distribution with mean 0 and variance 1 by normalizing the activations of each laye

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
XJC-CF3600F效率升级秘诀
# 摘要
本文对XJC-CF3600F打印机进行了全面的概述,深入探讨了其性能优化理论,包括性能指标解析、软件配置与优化、打印材料与环境适应性等方面。在实践应用优化方面,本文详细讨论了用户交互体验的提升、系统稳定性的提高及故障排除方法,以及自动化与集成解决方案的实施。此外,本文还探
【C++编程精进秘籍】:17个核心主题的深度解答与实践技巧
# 摘要
本文全面探讨了C++编程语言的核心概念、高级特性及其在现代软件开发中的实践应用。从基础的内存管理到面向对象编程的深入探讨,再到模板编程与泛型设计,文章逐层深入,提供了系统化的C++编程知识体系。同时,强调了高效代码优化的重要性,探讨了编译器优化技术以及性能测试工具的应用。此外,本文详细介绍了C++标准库中容器和算法的高级用法,以及如何处理输入输出和字符串。案例分析部分则
【自动化调度系统入门】:零基础理解程序化操作
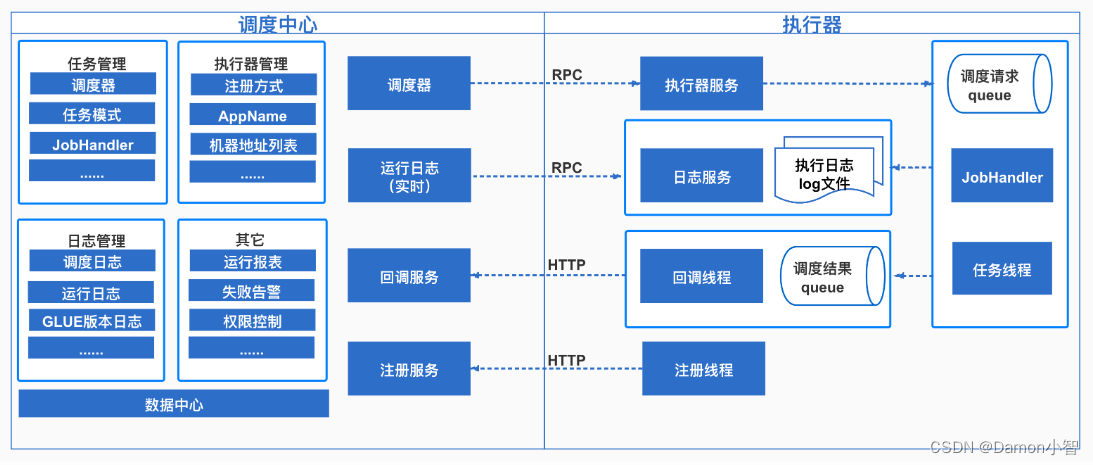
# 摘要
自动化调度系统是现代信息技术中的核心组件,它负责根据预定义的规则和条件自动安排和管理任务和资源。本文从自动化调度系统的基本概念出发,详细介绍了其理论基础,包括工作原理、关键技术、设计原则以及日常管理和维护。进一步,本文探讨了如何在不同行业和领域内搭建和优化自动化调度系统的实践环境,并分析了未来技术趋势对自动化调度系统的影响。文章通过案例分析展示了自动化调度系统在提升企业流程效率、成本控制
打造低延迟无线网络:DW1000与物联网的无缝连接秘籍
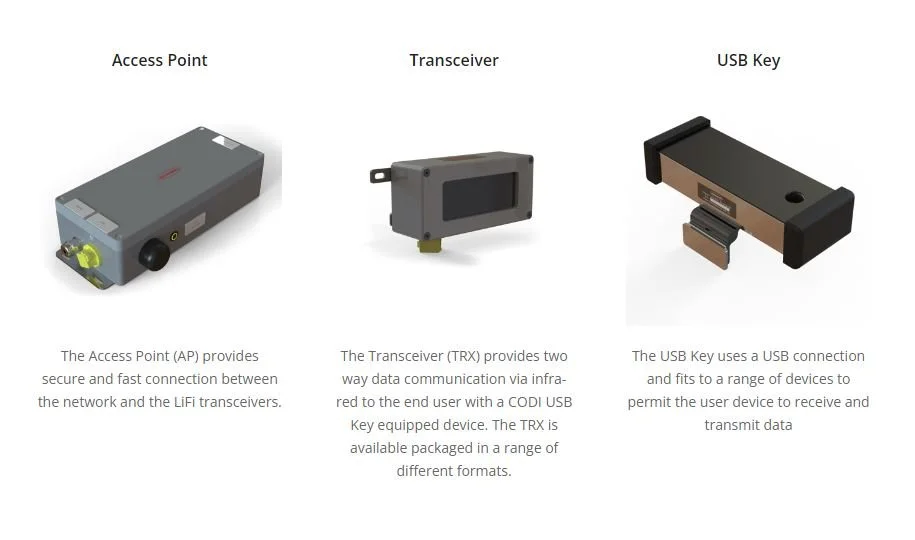
# 摘要
本文深入探讨了无线网络与物联网的基本概念,并重点介绍了DW1000无线通信模块的原理与特性。通过对DW1000技术规格、性能优势以及应用案例的分析,阐明了其在构建低延迟无线网络中的关键作用。同时,文章详细阐述了DW1000与物联网设备集成的方法,包括硬件接口设计、软件集成策略和安全性
【C#打印流程完全解析】:从预览到输出的高效路径
# 摘要
本文系统地介绍了C#中打印流程的基础与高级应用。首先,阐释了C#打印流程的基本概念和打印预览功能的实现,包括PrintPreviewControl控件的使用、自定义设置及编程实现。随后,文章详细讨论了文档打印流程的初始化、文档内容的组织与布局、执行与监控方法。文章继续深入到打印流程的高级应用,探讨了打印作业的管理、打印服务的交互以及打印输出的扩展功能。最后,提出了C#打印流程的调试技巧、性能优化策略和最佳实践,旨在帮助开发者高效地实现高质量的打印功能。通过对打印流程各个层面的详细分析和优化方法的介绍,本文为C#打印解决方案的设计和实施提供了全面的理论和实践指导。
# 关键字
C#打
LaTeX排版秘籍:美化文档符号的艺术

# 摘要
本文系统介绍了LaTeX排版系统的全面知识,涵盖符号排版、数学公式处理、图表与列表设置、文档样式定制及自动化优化五个主要方面。首先,本文介绍了
OpenProtocol-MTF6000通讯协议深度解析:掌握结构与应用
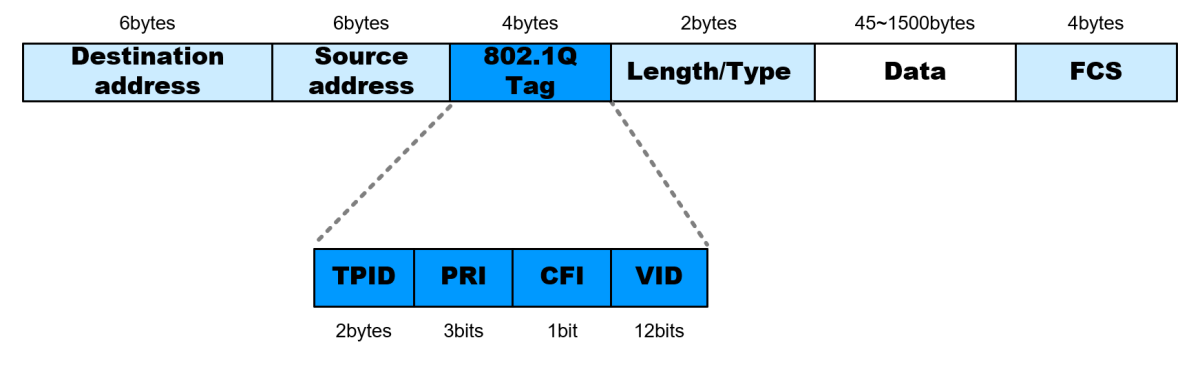
# 摘要
本文全面介绍了OpenProtocol-MTF6000通讯协议,涵盖了协议的基本概念、结构、数据封装、实践应用以及高级特性和拓展。首先,概述了OpenProtocol-MTF6000协议的框架、数据封装流程以及数据字段的解读和编码转换。其次,探讨了协议在工业自动化领域的应用,包括自动化设备通信实例、通信效率和可
【Android性能优化】:IMEI码获取对性能影响的深度分析
# 摘要
随着智能手机应用的普及和复杂性增加,Android性能优化变得至关重要。本文首先概述了Android性能优化的必要性和方法,随后深入探讨了IMEI码获取的基础知识及其对系统性能的潜在影响。特别分析了IMEI码获取过程中资源消耗问题,以及如何通过优化策略减少这些负面影响。本文还探讨了性能优化的最佳实践,包括替代方案和案例研究,最后展望了Android性能优化的未来趋势,特别是隐私保护技术的发展和深度学习在
【后端性能优化】:架构到代码的全面改进秘籍
# 摘要
随着互联网技术的快速发展,后端性能优化已成为提升软件系统整体效能的关键环节。本文从架构和代码两个层面出发,详细探讨了性能优化的多种策略和实践方法。在架构层面,着重分析了负载均衡、高可用系统构建、缓存策略以及微服务架构的优化;在代码层面,则涉及算法优化、数据结构选择、资源管理、异步处理及并发控制。性能测试与分析章节提供了全面的测试基础理论和实
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )