Attention Mechanism and Multilayer Perceptrons (MLP): A New Perspective on Feature Extraction, Unearthing Data Value, and Enhancing Model Comprehension
发布时间: 2024-09-15 08:09:57 阅读量: 28 订阅数: 31 

ATPapers:Worth-reading papers and related resources on attention mechanism, Transformer and pretrained language model (PLM) such as BERT. 值得一读的注意力机制、Transformer和预训练语言模型论文与相关资源集合
# 1. Overview of Attention Mechanism**
The attention mechanism is a neural network technique that allows the model to focus on specific parts of the input data. By assigning weights, the attention mechanism can highlight important features while suppressing irrelevant information.
The benefits of the attention mechanism include:
* Improving the accuracy and efficiency of feature extraction
* Enhancing the model's understanding of relevance in the input data
* Increasing the model's interpretability, allowing researchers to understand the areas that the model focuses on
# 2. Applications of Attention Mechanism in Feature Extraction
The attention mechanism is a neural network technique that allows the model to concentrate on the most important parts of the input data. In feature extraction, the attention mechanism can help the model identify and extract key features relevant to specific tasks from the data.
### 2.1 Self-Attention Mechanism
The self-attention mechanism is a type of attention mechanism that allows the model to focus on different parts of an input sequence. It works by calculating the similarity between each element and all other elements in the sequence. Elements with higher similarity scores are given higher weights, while those with lower similarity scores are given lower weights.
**2.1.1 Principles of Self-Attention Mechanism**
The principles of the self-attention mechanism can be represented by the following formula:
```
Q = W_qX
K = W_kX
V = W_vX
A = softmax(Q^T K / sqrt(d_k))
Output = AV
```
Where:
* X is the input sequence
* Q, K, V are the query, key, and value matrices
* W_q, W_k, W_v are weight matrices
* d_k is the dimension of the key vector
* A is the attention weight matrix
* Output is the weighted sum output
**2.1.2 Applications of Self-Attention Mechanism**
The self-attention mechanism has been successfully applied to various feature extraction tasks, including:
* Text feature extraction: The self-attention mechanism can identify important words and phrases in text sequences.
* Image feature extraction: The self-attention mechanism can identify important regions and objects in images.
* Audio feature extraction: The self-attention mechanism can identify important phonemes and rhythms in audio sequences.
### 2.2 Heterogeneous Attention Mechanism
The heterogeneous attention mechanism is a type of attention mechanism that allows the model to focus on the relationship between an input sequence and another sequence. It works by calculating the similarity between each element in the input sequence and each element in another sequence. Elements with higher similarity scores are given higher weights, while those with lower similarity scores are given lower weights.
**2.2.1 Principles of Heterogeneous Attention Mechanism**
The principles of the heterogeneous attention mechanism can be represented by the following formula:
```
Q = W_qX
K = W_kY
V = W_vY
A = softmax(Q^T K / sqrt(d_k))
Output = AV
```
Where:
* X is the input sequence
* Y is another sequence
* Q, K, V are the query, key, and value matrices
* W_q, W_k, W_v are weight matrices
* d_k is the dimension of the key vector
* A is the attention weight matrix
* Output is the weighted sum output
**2.2.2 Applications of Heterogeneous Attention Mechanism**
The heterogeneous attention mechanism has been successfully applied to various feature extraction tasks, including:
* Machine translation: The heterogeneous attention mechanism can help the model focus on the relationship between the source language sequence and the target language sequence.
* Image caption generation: The heterogeneous attention mechanism can help the model focus on the relationship between images and text descriptions.
* Speech recognition: The heterogeneous attention mechanism can help the model focus on the relationship between audio sequences and text transcripts.
# 3. Overview of Multilayer Perceptrons (MLPs)
**3.1 Architecture of MLPs**
A multilayer perceptron (MLP) is a feedforward neural network composed of multiple fully connected layers. Each fully connected layer consists of a linear transformation followed by a nonlinear activation function. The typical architecture of an MLP is as follows:
```
Input layer -> Hidden layer 1 -> Hidden layer 2 -> ... -> Output layer
```
Where the input layer receives the input data and the output layer produces the final prediction. The hidden layers are responsible for extracting features from the input data and performing nonlinear transformations.
**3.2 Principles of MLPs**
The working principles of MLPs can be summarized as follows:
1. Input data enters the network through the input layer.
2. Each hidden layer performs a linear transformation on the input data, i.e., calculates the weighted sum.
3. The result of the linear transformation goes through a nonlinear activation function, introducing nonlinearity.
4. The output of the nonlinear activation function serves as the input for the next layer.
5. Repeat steps 2-4 until reaching the output layer.
6. The output layer produces the final prediction, usually a probability distribution or continuous values.
**3.3 Activation Functions in MLPs**
Common activation functions used in MLPs include:
***ReLU (Rectified Linear Unit)**: `max(0, x)`
***Sigmoid**: `1 / (1 + exp(-x))`
***Tanh**: `(exp(x) - exp(-x)) / (exp(x) + exp(-x))`
**3.4 Advantages of MLPs**
MLPs have the following advantages:
***Simplicity and ease of use**: The architecture of MLPs is simple and easy to understand and implement.
***Strong generalization ability**: MLPs are capable of learning complex relationships from data, exhibiting strong generalization.
***Good scalability**: MLPs can add or remove hidden layers as needed to accommodate different task complexities.
**3.5 Limitations of MLPs**
MLPs also have some limitations:
***High computational requirements**: The computational load of MLPs increases with the number of hidden layers and neurons.
***Prone to overfitting**: MLPs are prone to overfitting and require careful hyperparameter tuning a

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【51单片机数字时钟案例分析】:深入理解中断管理与时间更新机制
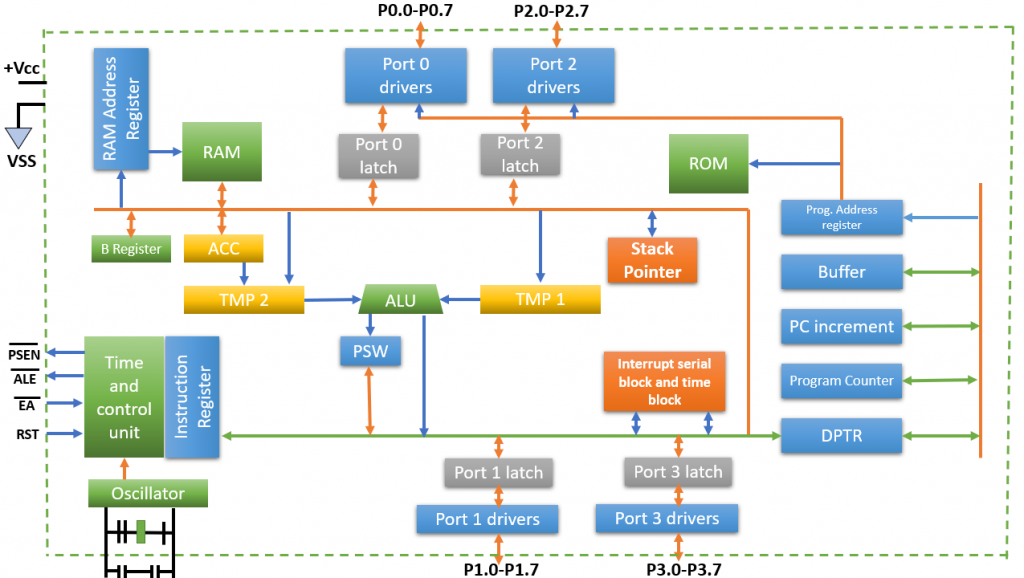
# 摘要
本文详细探讨了基于51单片机的数字时钟设计与实现。首先介绍了数字时钟的基本概念、功能以及51单片机的技术背景和应用领域。接着,深入分析了中断管理机制,包括中断系统原理、51单片机中断系统详解以及中断管理在实际应用中的实践。本文还探讨了时间更新机制的实现,阐述了基础概念、在51单片机下的具体策略以及优化实践。在数字时钟编程与调试章节中,讨论了软件设计、关键功能实现以及调试
【版本升级无忧】:宝元LNC软件平滑升级关键步骤大公开!

# 摘要
宝元LNC软件的平滑升级是确保服务连续性与高效性的关键过程,涉及对升级需求的全面分析、环境与依赖的严格检查,以及升级风险的仔细评估。本文对宝元LNC软件的升级实践进行了系统性概述,并深入探讨了软件升级的理论基础,包括升级策略
【异步处理在微信小程序支付回调中的应用】:C#技术深度剖析

# 摘要
本文首先概述了异步处理与微信小程序支付回调的基本概念,随后深入探讨了C#中异步编程的基础知识,包括其概念、关键技术以及错误处理方法。文章接着详细分析了微信小程序支付回调的机制,阐述了其安全性和数据交互细节,并讨论了异步处理在提升支付系统性能方面的必要性。重点介绍了如何在C#中实现微信支付的异步回调,包括服务构建、性能优化、异常处理和日志记录的最佳实践。最后,通过案例研究,本文分析了构建异步支付回调系统的架构设计、优化策略和未来挑战,为开
内存泄漏不再怕:手把手教你从新手到专家的内存管理技巧

# 摘要
内存泄漏是影响程序性能和稳定性的关键因素,本文旨在深入探讨内存泄漏的原理及影响,并提供检测、诊断和防御策略。首先介绍内存泄漏的基本概念、类型及其对程序性能和稳定性的影响。随后,文章详细探讨了检测内存泄漏的工具和方法,并通过案例展示了诊断过程。在防御策略方面,本文强调编写内存安全的代码,使用智能指针和内存池等技术,以及探讨了优化内存管理策略,包括内存分配和释放的优化以及内存压缩技术的应用。本文不
反激开关电源的挑战与解决方案:RCD吸收电路的重要性
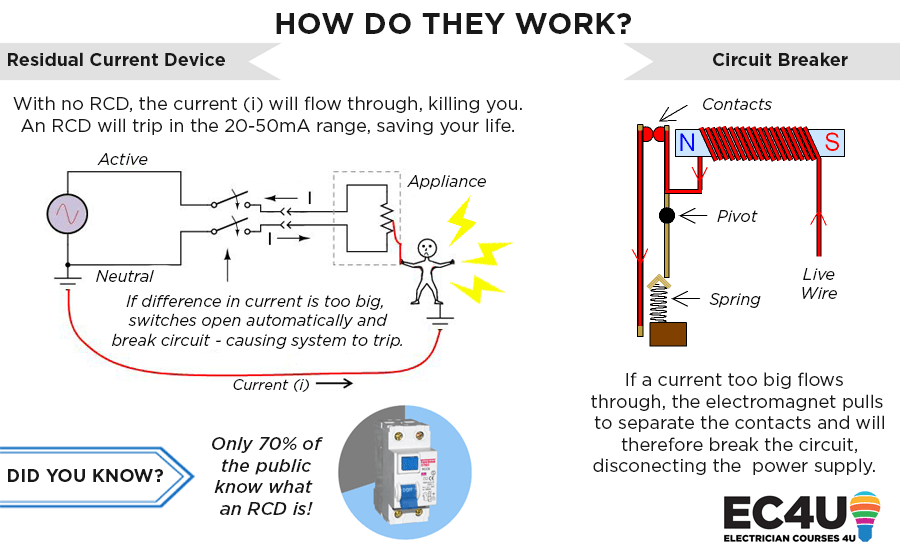
# 摘要
本文系统探讨了反激开关电源的工作原理及RCD吸收电路的重要作用和优势。通过分析RCD吸收电路的理论基础、设计要点和性能测试,深入理解其在电压尖峰抑制、效率优化以及电磁兼容性提升方面的作用。文中还对RCD吸收电路的优化策略和创新设计进行了详细讨论,并通过案例研究展示其在不同应用中的有效性和成效。最后,文章展望了RCD吸收电路在新材料应用
【Android设备标识指南】:掌握IMEI码的正确获取与隐私合规性

# 摘要
IMEI码作为Android设备的唯一标识符,不仅保证了设备的唯一性,还与设备的安全性和隐私保护密切相关。本文首先对IMEI码的概念及其重要性进行了概述,然后详细介绍了获取IMEI码的理论基础和技术原理,包括在不同Android版本下的实践指南和高级处理技巧。文中还讨论了IMEI码的隐私合规性考量和滥用防范策略,并通过案例分析展示了IMEI码在实际应用中的场景。最后,本文探讨了隐私保护技术的发展趋势以及对开发者在合规性
E5071C射频故障诊断大剖析:案例分析与排查流程(故障不再难)
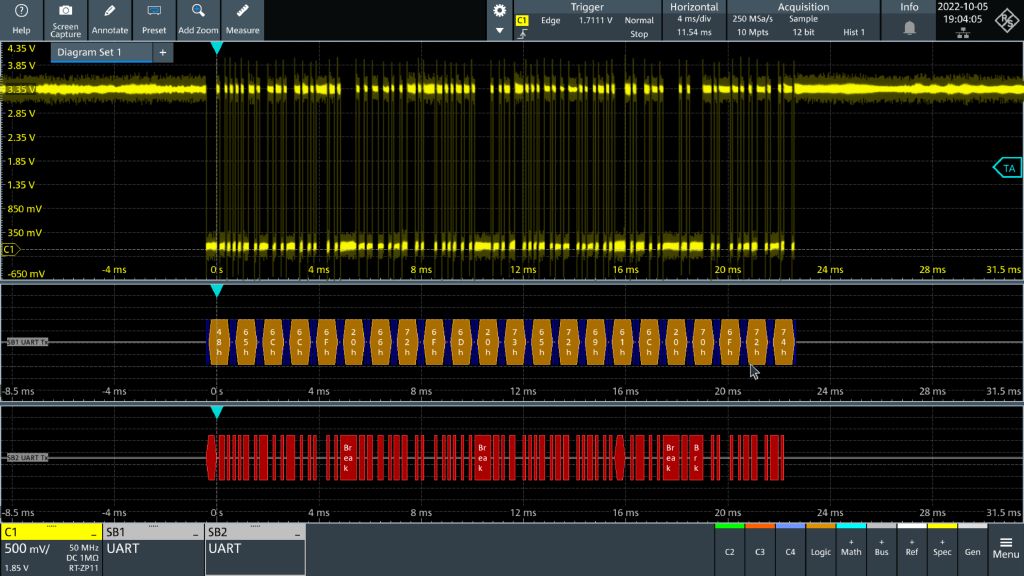
# 摘要
本文对E5071C射频故障诊断进行了全面的概述和深入的分析。首先介绍了射频技术的基础理论和故
【APK网络优化】:减少数据消耗,提升网络效率的专业建议

# 摘要
随着移动应用的普及,APK网络优化已成为提升用户体验的关键。本文综述了APK网络优化的基本概念,探讨了影响网络数据消耗的理论基础,包括数据传输机制、网络请求效率和数据压缩技术。通过实践技巧的讨论,如减少和合并网络请求、服务器端数据优化以及图片资源管理,进一步深入到高级优化策略,如数据同步、差异更新、延迟加载和智能路由选择。最后,通过案例分析展示了优化策略的实际效果,并对5G技
DirectExcel数据校验与清洗:最佳实践快速入门
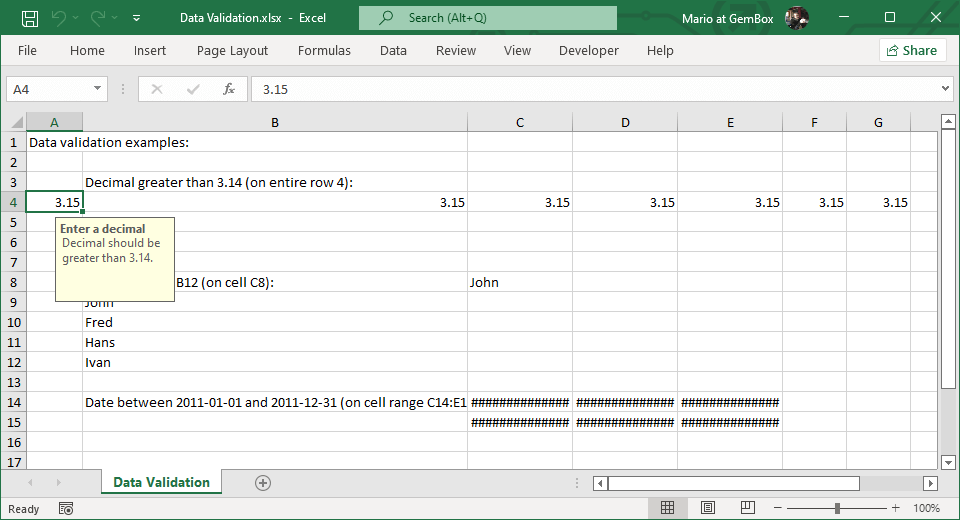
# 摘要
本文旨在介绍DirectExcel在数据校验与清洗中的应用,以及如何高效地进行数据质量管理。文章首先概述了数据校验与清洗的重要性,并分析了其在数据处理中的作用。随后,文章详细阐述了数据校验和清洗的理论基础、核心概念和方法,包括校验规则设计原则、数据校验技术与工具的选择与应用。在实践操作章节中,本文展示了DirectExcel的界面布局、功能模块以及如何创建
【模糊控制规则优化算法】:提升实时性能的关键技术
# 摘要
模糊控制规则优化算法是提升控制系统性能的重要研究方向,涵盖了理论基础、性能指标、优化方法、实时性能分析及提升策略和挑战与展望。本文首先对模糊控制及其理论基础进行了概述,随后详细介绍了基于不同算法对模糊控制规则进行优化的技术,包括自动优化方法和实时性能的改进策略。进一步,文章分析了优化对实时性能的影响,并探索了算法面临的挑战与未
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )