Multilayer Perceptrons (MLP) in Natural Language Processing: Text Analysis and Understanding, NLP Empowering the Text World
发布时间: 2024-09-15 07:58:53 阅读量: 34 订阅数: 31 
# 1. Overview of Natural Language Processing (NLP)
Natural Language Processing (NLP) is a field of computer science that focuses on enabling computers to understand, interpret, and generate human language. The goal of NLP is to build computer systems capable of interacting naturally with humans, and handling various forms of text and linguistic data.
NLP involves a wide range of techniques and methodologies, including:
***Linguistics:** Studies the structure, meaning, and usage of language.
***Computer Science:** Provides algorithms, data structures, and computational models.
***Statistics:** Used for dealing with uncertainty and extracting patterns from data.
***Machine Learning:** Used to train computer systems to perform tasks without explicit programming.
# 2. Theoretical Foundations of Multilayer Perceptrons (MLP)
### 2.1 Basic Principles and Structure of MLPs
A Multilayer Perceptron (MLP) is a type of feedforward neural network consisting of an input layer, one or more hidden layers, and an output layer. Its fundamental principle is to map input data onto the output space layer by layer through weighted connections.
The structure of MLP is typically represented as:
```
Input Layer -> Hidden Layer 1 -> Hidden Layer 2 -> ... -> Output Layer
```
Each hidden layer contains multiple neurons that r***mon activation functions include sigmoid, tanh, and ReLU.
### 2.2 Training Algorithms and Optimization Methods for MLPs
Training of MLPs generally employs the backpropagation algorithm, which calculates the gradient of the loss function and updates the network weights using gradient descent.
To optimize the training process, the following methods can be utilized:
- **Gradient Descent Algorithms:** SGD, Adam, RMSProp
- **Regularization Techniques:** L1 Regularization, L2 Regularization, Dropout
- **Learning Rate Adjustment:** Learning Rate Decay, Learning Rate Scheduling
### 2.3 Performance Evaluation and Parameter Tuning Techniques for MLPs
The performance of MLPs is typically evaluated using the following metrics:
- **Accuracy:** The ratio of the number of correctly predicted samples to the total number of samples
- **Recall:** The ratio of the number of correctly predicted positive instances to the total number of actual positive instances
- **F1 Score:** The harmonic mean of precision and recall
Parameter tuning techniques include:
- **Number of Hidden Layers and Neurons:** Affects network capacity and complexity
- **Activation Functions:** Different activation functions have varying impacts on network performance
- **Learning Rate:** Influences training speed and convergence
- **Regularization Parameters:** Control the degree of overfitting
# 3. Practical Applications of MLPs in Text Analysis
### 3.1 Text Classification and Sentiment Analysis
#### 3.1.1 Principles and Methods of Text Classification
Text classification is the task of assigning text documents to predefined categories. MLPs are widely used in text classification, and their principles are as follows:
- **Text Representation:***mon methods include Bag of Words (BoW) and word embeddings.
- **Feature Extraction:** MLPs extract features from the input vectors that represent the topics, sentiments, and styles of the text.
- **Classification:** MLPs use the extracted features to classify the text. It learns a mapping function during training that maps input vectors to target categories.
#### 3.1.2 Models and Evaluation of Sentiment Analysis
Sentiment analysis aims to identify and understand the sentiment expressed in text. MLPs can be used in sentiment analysis for:
- **Sentiment Classification:** Classifying text documents as positive, negative, or neutral.
- **Sentiment Intensity Prediction:** Predicting the intensity of sentiment in the text.
Evaluation metrics for sentiment analysis models include accuracy, recall, and the F1 score.
### 3.2 Text Generation and Translation
#### 3.2.1 Models and Techniques for Text Generation
Text generation refers to the automatic generation of text that resembles human language. MLPs can be used for:
- **Language Models:** Learning the probability distribution of te

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
E5071C高级应用技巧大揭秘:深入探索仪器潜能(专家级操作)
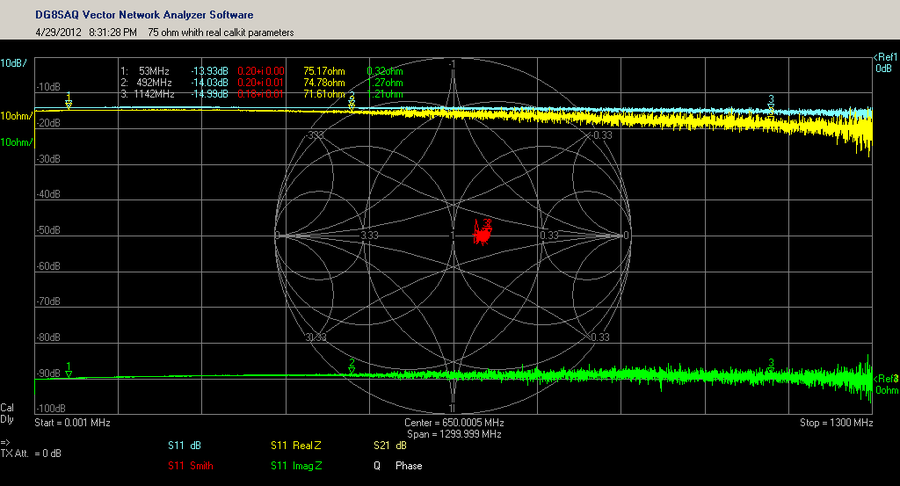
# 摘要
本文详细介绍了E5071C矢量网络分析仪的使用概要、校准和测量基础、高级测量功能、在自动化测试中的应用,以及性能优化与维护。章节内容涵盖校准流程、精确测量技巧、脉冲测量与故障诊断、自动化测试系统构建、软件集成编程接口以及仪器性能优化和日常维护。案例研究与最佳实践部分分析了E5071C在实际应用中的表现,并分享了专家级的操作技巧和应用趋势,为用户提供了一套完整的学习和操作指南。
# 关键字
【模糊控制规则的自适应调整】:方法论与故障排除

# 摘要
本文综述了模糊控制规则的基本原理,并深入探讨了自适应模糊控制的理论框架,涵盖了模糊逻辑与控制系统的关系、自适应调整的数学模型以及性能评估方法。通过分析自适应模糊控
DirectExcel开发进阶:如何开发并集成高效插件

# 摘要
DirectExcel作为一种先进的Excel操作框架,为开发者提供了高效操作Excel的解决方案。本文首先介绍DirectExcel开发的基础知识,深入探讨了DirectExcel高效插件的理论基础,包括插件的核心概念、开发环境设置和架构设计。接着,文章通过实际案例详细解析了DirectExcel插件开发实践中的功能实现、调试
【深入RCD吸收】:优化反激电源性能的电路设计技巧
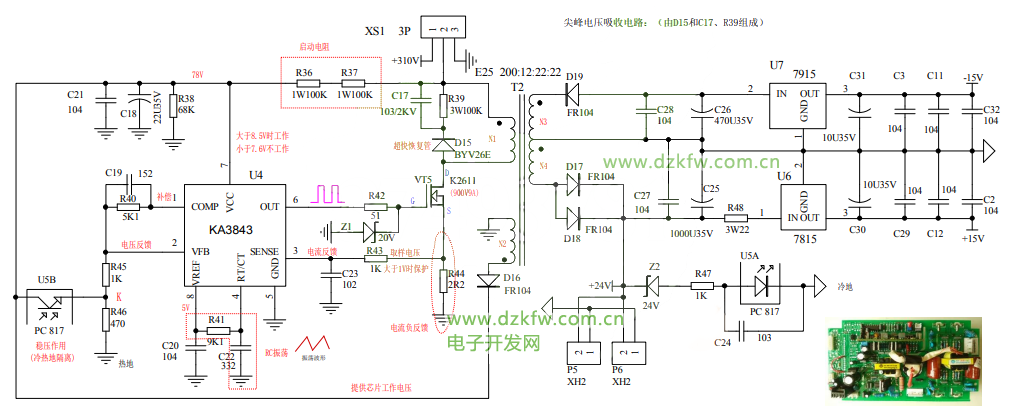
# 摘要
本文详细探讨了反激电源中RCD吸收电路的理论基础和设计方法。首先介绍了反激电源的基本原理和RCD吸收概述,随后深入分析了RCD吸收的工作模式、工作机制以及关键参数。在设计方面,本文提供了基于理论计算的设计过程和实践考量,并通过设计案例分析对性能进行测试与优化。进一步地,探讨了RCD吸收电路的性能优化策略,包括高效设计技巧、高频应用挑战和与磁性元件的协同设计。此外,本文还涉及了RCD
【进阶宝典】:宝元LNC软件高级功能深度解析与实践应用!

# 摘要
本文全面介绍了宝元LNC软件的综合特性,强调其高级功能,如用户界面的自定义与交互增强、高级数据处理能力、系统集成的灵活性和安全性以及性能优化策略。通过具体案例,分析了软件在不同行业中的应用实践和工作流程优化。同时,探讨了软件的开发环境、编程技巧以及用户体验改进,并对软件的未来发展趋势和长期战略规划进行了展望。本研究旨在为宝元LNC软件的用户和开发者提供深入的理解和指导,以支持其在不
51单片机数字时钟故障排除:系统维护与性能优化
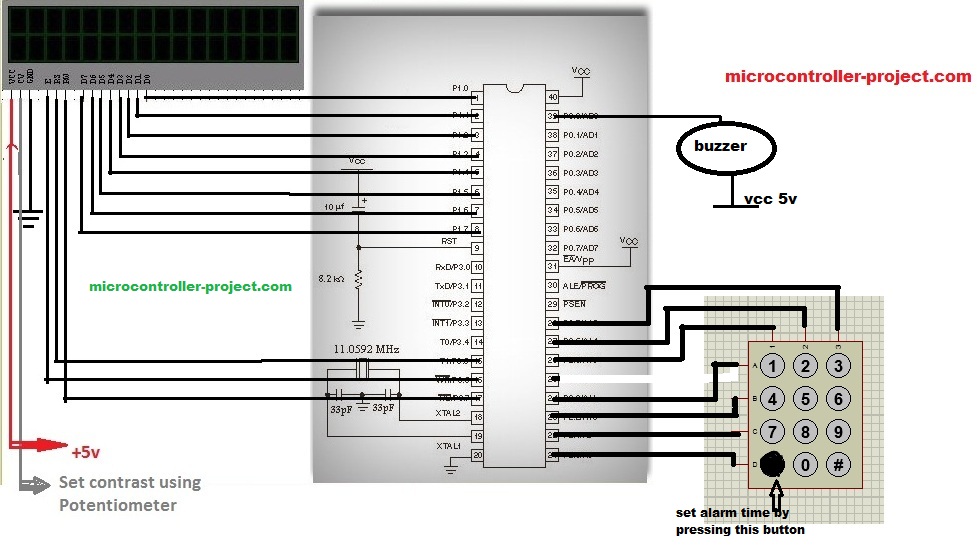
# 摘要
本文全面介绍了51单片机数字时钟系统的设计、故障诊断、维护与修复、性能优化、测试评估以及未来趋势。首先概述了数字时钟系统的工作原理和结构,然后详细分析了故障诊断的理论基础,包括常见故障类型、成因及其诊断工具和技术。接下来,文章探讨了维护和修复的实践方法,包括快速检测、故障定位、组件更换和系统重置,以及典型故障修复案例。在性能优化部分,本文提出了硬件性能提升和软
ISAPI与IIS协同工作:深入探究5大核心策略!
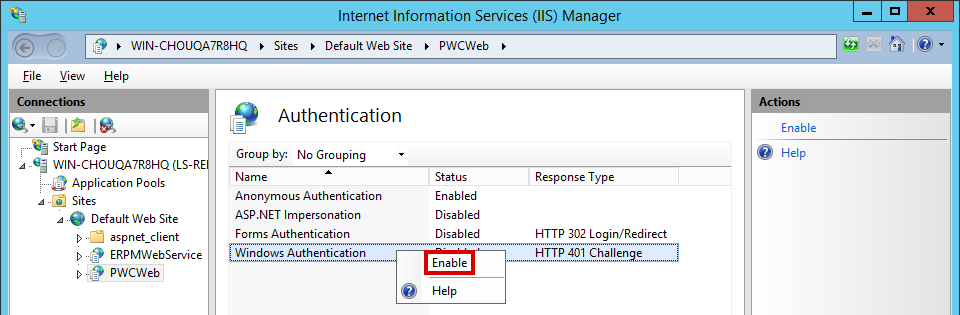
# 摘要
本文深入探讨了ISAPI与IIS协同工作的机制,详细介绍了ISAPI过滤器和扩展程序的高级策略,以及IIS应用程序池的深入管理。文章首先阐述了ISAPI过滤器的基础知识,包括其生命周期、工作原理和与IIS请求处理流程的相互作用。接着,文章探讨了ISAPI扩展程序的开发与部
【APK资源优化】:图片、音频与视频文件的优化最佳实践
# 摘要
随着移动应用的普及,APK资源优化成为提升用户体验和应用性能的关键。本文概述了APK资源优化的重要性,并深入探讨了图片、音频和视频文件的优化技术。文章分析了不同媒体格式的特点,提出了尺寸和分辨率管理的最佳实践,以及压缩和加载策略。此外,本文介绍了高效资源优
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )