【实战演练】异常检测实战:使用Scikit-learn进行网络入侵检测
发布时间: 2024-06-24 17:32:57 阅读量: 88 订阅数: 132 

# 2.1.1 孤立森林算法原理
孤立森林算法是一种无监督异常检测算法,其基本原理是通过构建一组隔离树来隔离异常点。在隔离树中,每个节点都随机选择一个特征和一个分割点,将数据样本划分为左右两个子节点。这个过程递归进行,直到满足停止条件(例如,达到最大深度或数据样本数量太少)。
在构建隔离树的过程中,算法会记录每个样本被隔离到叶节点所需的路径长度。正常样本通常需要较长的路径才能被隔离,而异常样本往往会在较短的路径中被隔离。因此,通过比较样本的路径长度,可以识别出异常样本。
# 2. Scikit-learn异常检测算法
在Scikit-learn库中,提供了多种异常检测算法,包括孤立森林算法、支持向量机算法和局部异常因子算法。这些算法各有其优点和缺点,适用于不同的异常检测场景。
### 2.1 孤立森林算法
#### 2.1.1 算法原理
孤立森林算法是一种基于隔离度的异常检测算法。其基本思想是:正常数据点通常更容易被孤立,而异常数据点则更难被孤立。因此,算法通过随机生成一组树,将数据点不断分割成更小的子集,直到每个数据点被孤立为止。
算法的具体步骤如下:
1. 从训练数据中随机抽取一个样本,并随机选择一个特征。
2. 根据所选特征的值将样本分割成两个子集。
3. 重复步骤1和2,直到每个样本都被孤立。
4. 计算每个样本的隔离度,即被孤立所需的平均分割次数。
#### 2.1.2 算法参数
孤立森林算法的主要参数包括:
- **n_estimators:** 随机生成的树的数量,默认值为100。
- **max_samples:** 每个树中使用的最大样本数,默认值为训练数据样本数的25%。
- **contamination:** 异常样本在训练数据中所占的比例,默认值为0.1。
### 2.2 支持向量机算法
#### 2.2.1 算法原理
支持向量机算法是一种基于分类的异常检测算法。其基本思想是:在高维特征空间中,将正常数据点和异常数据点用一个超平面分隔开,使得超平面与两类数据点的距离最大。
算法的具体步骤如下:
1. 将数据点映射到高维特征空间。
2. 找到一个超平面,将正常数据点和异常数据点分隔开。
3. 计算每个数据点到超平面的距离。
4. 将距离超平面最远的少数数据点标记为异常数据点。
#### 2.2.2 算法参数
支持向量机算法的主要参数包括:
- **kernel:** 核函数类型,常用的核函数包括线性核、多项式核和高斯核。
- **gamma:** 核函数中的系数,用于控制核函数的形状。
- **C:** 正则化参数,用于控制模型的复杂度。
### 2.3 局部异常因子算法
#### 2.3.1 算法原理
局部异常因子算法是一种基于局部密度的异常检测算法。其基本思想是:正常数据点通常位于高密度区域,而异常数据点则位于低密度区域。因此,算法通过计算每个数据点的局部密度,将异常数据点识别出来。
算法的具体步骤如下:
1. 计算每个数据点与其他所有数据点的距离。
2. 对于每个数据点,计算其k近邻的平均距离。
3. 计算每个数据点的局部密度,即k近邻平均距离的倒数。
4. 将局部密度最小的少数数据点标记为异常数据点。
#### 2.3.2 算法参数
局部异常因子算法的主要参数包括:
- **n_neighbors:** k近邻的数量,默认值为5。
- **contamination:** 异常样本在训练数据中所占的比例,默认值为0.1。
# 3.1 数据预处理
#### 3.1.1 数据清洗
数据清洗是数据预处理的重要步骤,它可以去除数据中的噪声、缺失值和异常值,从而提高模型的训练效果。对于网络入侵检测,数据清洗通常涉及以下步骤:
1. **去除重复数据:**重复数据的存在会影响模型的训练结果,因此需要将其去除。可以使用`pandas.DataFrame.drop_duplicates()`方法或`SQL`语句`DELETE FROM table_name WHERE id IN (SELECT id FROM table_name GROUP BY id HAVING COUNT(*) > 1)`来去除重复数据。
2. **处理缺失值:**缺失值会影响模型的训练,因此需要将其处理。可以采用以下几种方法:
- **删除缺失值:**如果缺失值较少,可以直接将其删除。可以使用`pandas.DataFrame.dropn

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏汇集了丰富的 Python 科学计算资源,涵盖基础和进阶篇,旨在为读者提供全面深入的科学计算知识和技能。
基础篇从 Python 科学计算库概述和安装开始,循序渐进地介绍 NumPy、SciPy、Pandas、Matplotlib 等核心库的基础知识和应用,包括多维数组操作、线性代数运算、数据处理、数据可视化等。
进阶篇则深入探讨了这些库的高级功能和应用,如广播机制、性能优化、优化算法、稀疏矩阵处理、数据挖掘、时间序列分析、图像处理、数值模拟等。此外,还提供了实战演练,指导读者运用这些库解决实际问题,如数据降维、销售数据分析、股票数据可视化、情感分析、图像处理、销售预测、异常检测、数据聚类等。
通过阅读本专栏,读者可以掌握 Python 科学计算的全面技能,并将其应用于各种科学、工程和数据分析领域。
专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
优化你的虚拟化环境:AMI VeB性能提升策略全解析
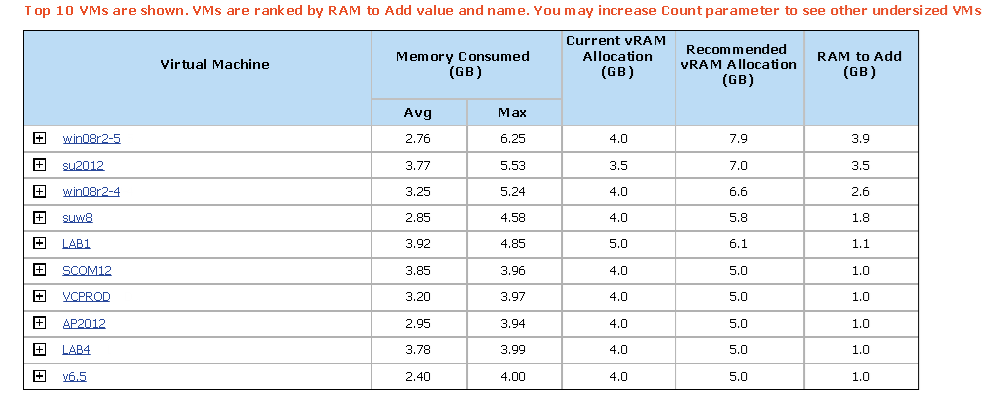
参考资源链接:[VeB白皮书:AMIVisual eBIOS图形固件开发环境详解](https://wenku.csdn.net/doc/6412b5cabe7fbd1778d44684?spm=1055.2635.3001.10343)
# 1. 虚拟化技术与性能挑战
在现代IT环境中,虚拟化技术已经变得不可或缺,它允许在单个物理硬件上运行多个虚拟机(VMs),从而提高
Calibre XRC:2023年最新指南,确保你的设计质量和效率在行业内遥遥领先

参考资源链接:[Calibre XRC:寄生参数提取与常用命令详解](https://wenku.csdn.net/doc/6412b4d3be7fbd1778d40f58?spm=1055.2635.3001.10343)
# 1. Calibre XRC概述与行业地位
## 1.1 Calibre XRC简介
【74HC154引脚使用技巧:设计调试的黄金法则】:关键注意事项大揭秘
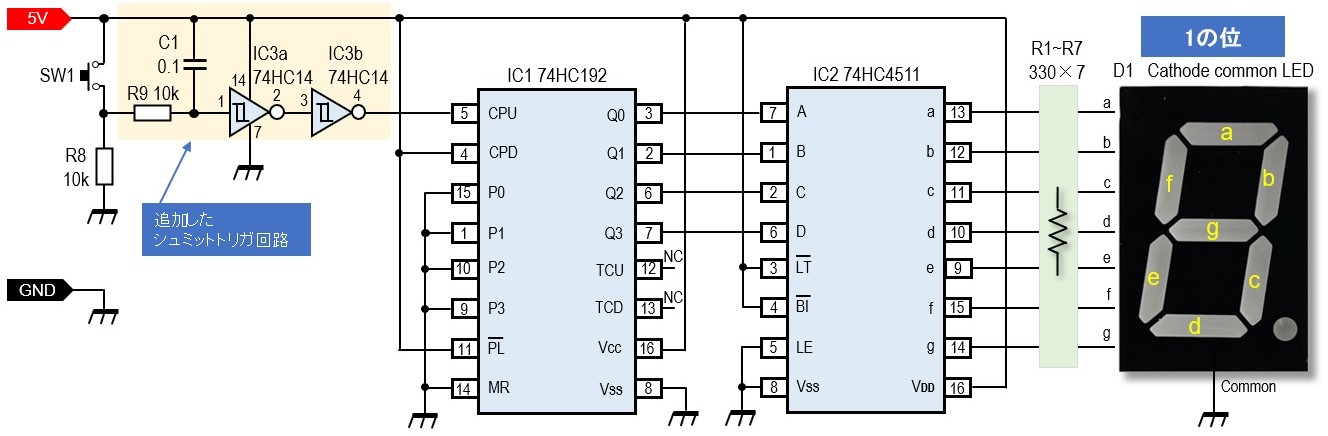
参考资源链接:[74HC154详解:4线-16线译码器的引脚功能与应用](https://wenku.csdn.net/doc/32hp07jvry?spm=1055.2635.3001.10343)
# 1. 74HC154引脚概述
数字逻辑电路设计是电子工程领域中不可或缺的一部分,而74HC154作为一款高性能的4到16线解码器/多路选择器,在设计中扮演着重要的角色。本章节将对74HC154的各个引脚进行概述,为后续章节的内容奠定基础。
74HC154
环境化学研究新工具:Avogadro模拟污染物行为实操

参考资源链接:[Avogadro中文教程:分子建模与可视化全面指南](https://wenku.csdn.net/doc/6b8oycfkbf?spm=1055.2635.3001.10343)
# 1. 环境化学研究中模拟工具的重要性
环境化学研究中,模拟工具已成为不可
【彩色文档打印无能?解决方法大公开】:奔图打印机彩印问题,专家支招

参考资源链接:[奔图打印机故障排除指南:卡纸、颜色浅、斑点与重影问题解析](https://wenku.csdn.net/doc/647841b8d12cbe7ec32e0260?spm=1055.2635.3001.10343)
# 1. 彩色文档打印的重要性与挑战
在现代商业环境中,彩色文档的打印已经变得不可或缺。随着技术的进步,彩色打印在营销、教育和日常办公中扮演着越来越重要的角色。它不
虚拟现实集成:3DSource零件库设计体验的新维度

参考资源链接:[3DSource零件库在线版:CAD软件集成的三维标准件库](https://wenku.csdn.net/doc/6wg8wzctvk?spm=1055.2635.3001.10343)
# 1. 虚拟现实技术与3D Source概述
## 虚拟现实技术基础
虚拟现实(VR)技术通过创造三维的计算机模拟环境,让用户能够沉浸在一个与现实世界完全不同的空间。随着硬件设备
V90 EPOS模式回零适应性:极端环境下的稳定运行分析

参考资源链接:[V90 EPOS模式下增量/绝对编码器回零方法详解](https://wenku.csdn.net/doc/6412b48abe7fbd1778d3ff04?spm=1055.2635.3001.10343)
# 1. V90 EPOS模式回零的原理与必要性
## 1.1 EPOS模式回零的基本概念
EPOS(电子位置设定)模式回零是指在电子控制系统中,自动或手动将设备的位置设定到初始的或预定的位置。这种机
【Python pip安装包的版本控制】:精确管理依赖版本的专家指南

参考资源链接:[Python使用pip安装报错ModuleNotFoundError: No module named ‘pkg_resources’的解决方法](https://wenku.csdn.net/doc/6412b4a3be7fbd1778d4049f?spm=1055.2635.3001.10343)
# 1. Python pip安装包管理概述
P
PLS UDE UAD扩展功能探索:插件与模块使用深度解析
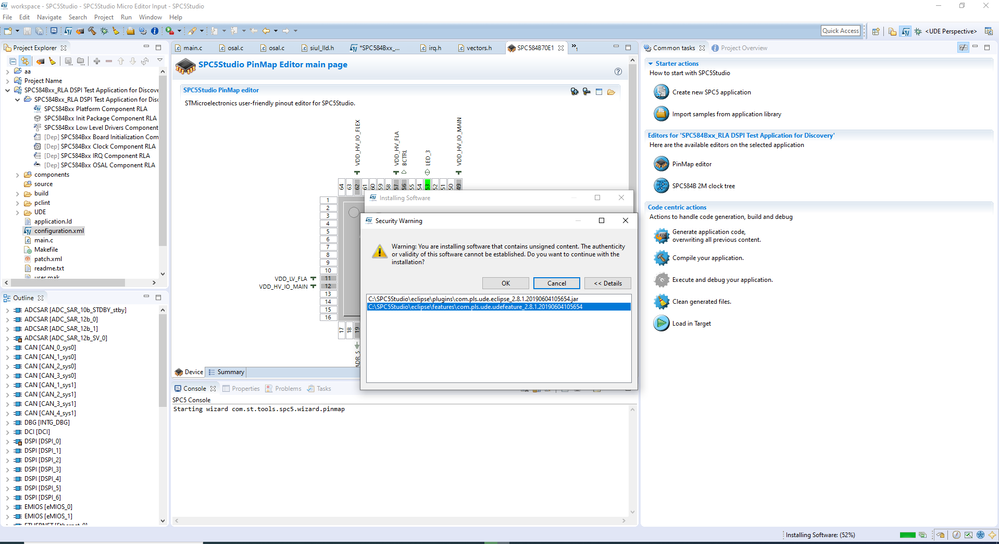
参考资源链接:[UDE入门:Tricore多核调试详解及UAD连接步骤](https://wenku.csdn.net/doc/6412b6e5be7fbd1778d485ca?spm=1055.2635.3001.10343)
# 1. PLS UDE UAD基础介绍
在当今充满活力的信息技术领域,PLS UDE
GrblController教育应用指南:培育未来工程师的创新平台

参考资源链接:[GrblController安装与使用教程](https://wenku.csdn.net/doc/6412b792be7fbd1778d4ac76?spm=1055.2635.3001.10343)
# 1. GrblController概述与教育意义
GrblController作
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送1年
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )