GPU Acceleration Issues in MATLAB Crashes: Exploring and Resolving Graphics Processing Faults to Unleash GPU Potential
发布时间: 2024-09-13 14:30:15 阅读量: 24 订阅数: 28 
# 1. Overview of GPU Acceleration**
GPU (Graphics Processing Unit) acceleration is a technique that utilizes the parallel computing capabilities of GPUs to speed up MATLAB computations. By assigning computational tasks to the GPU, performance can be significantly improved, especially in applications that involve a large amount of parallel computing.
The principle behind GPU acceleration lies in the GPU's possession of a large number of parallel processing units (CUDA cores), capable of executing multiple computational tasks simultaneously. This is in contrast to the CPU, which typically has only a few cores and can only execute tasks sequentially. Therefore, for applications that require processing vast amounts of data, GPUs can provide a significant performance advantage.
# 2. Theoretical Foundations of GPU Acceleration
### 2.1 Principles of GPU Parallel Computing
A **GPU (Graphics Processing Unit)** is a hardware device specifically designed for processing graphics and video data. Unlike a CPU (Central Processing Unit), a GPU has a massively parallel processing capability, making it well-suited for tasks that require a large amount of parallel computation.
The principle of GPU parallel computing involves breaking down tasks into many smaller subtasks, which are then executed simultaneously on multiple processing cores. This parallel processing approach can significantly increase computing efficiency, especially when dealing with large datasets.
**CUDA (Compute Unified Device Architecture)** is a parallel computing platform developed by NVIDIA, designed for programming GPUs. CUDA allows programmers to write code in the C language and leverage the parallel processing capabilities of GPUs to accelerate computations.
### 2.2 GPU Memory Model and Optimization
GPUs have their own dedicated memory, known as **GPU memory**. Unlike CPU memory, GPU memory has higher bandwidth and lower latency. However, GPU memory is also more limited compared to CPU memory.
The **GPU memory model** consists of several parts:
- **Global Memory:** Shared memory accessible by all threads.
- **Shared Memory:** Shared memory accessible by threads within the same thread block.
- **Local Memory:** Private memory unique to each thread.
Optimizing **GPU memory usage** is crucial for enhancing the performance of GPU acceleration. Here are some optimization tips:
- **Reduce Global Memory Access:** Try to use shared memory or local memory to store data to minimize accesses to global memory.
- **Use Texture Memory:** For tasks such as image processing that require a large amount of texture data, using texture memory can improve performance.
- **Avoid Memory Fragmentation:** Allocate memory wisely to avoid memory fragmentation and improve memory utilization.
**Code Block:**
```c
__global__ void kernel(int *a, int *b, int *c) {
int tid = threadIdx.x;
int blockIdx = blockIdx.x;
int blockDim = blockDim.x;
int gridDim = gridDim.x;
// Calculate each thread's index
int index = blockIdx * blockDim + tid;
// Access global memory
a[index] += b[index];
// Synchronize threads
__syncthreads();
// Access shared memory
c[tid] = a[index];
}
```
**Code Logic Analysis:**
This code block is a CUDA kernel function designed for parallel computation of the sum of two arrays, a and b, and storing the result in array c.
***tid:** Thread ID, representing the current thread's index within the block.
***blockIdx:** Block ID, indicating the current block's index in the grid.
***blockDim:** Block size, representing the number of threads in each block.
***gridDim:** Grid size, representing the number of blocks in the grid.
The kernel function first calculates each thread's index and then uses this index to access the a and b arrays in global memory. It then uses the __syncthreads() function to synchronize threads, ensuring all threads complete their access to global memory before accessing shared memory. Finally, it stores the computed result in the c array located in shared memory.
**Parameter Explanation:**
***a:** Input array 1
***b:** Input array 2
***c:** Output array
# 3.1 Basic MATLAB GPU Programming
**GPU Programming Paradigm**
GPU programming in MATLAB follows the Single Instruction, Multiple Data (SIMD) paradigm, meaning that

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【统计学意义的验证集】:理解验证集在机器学习模型选择与评估中的重要性
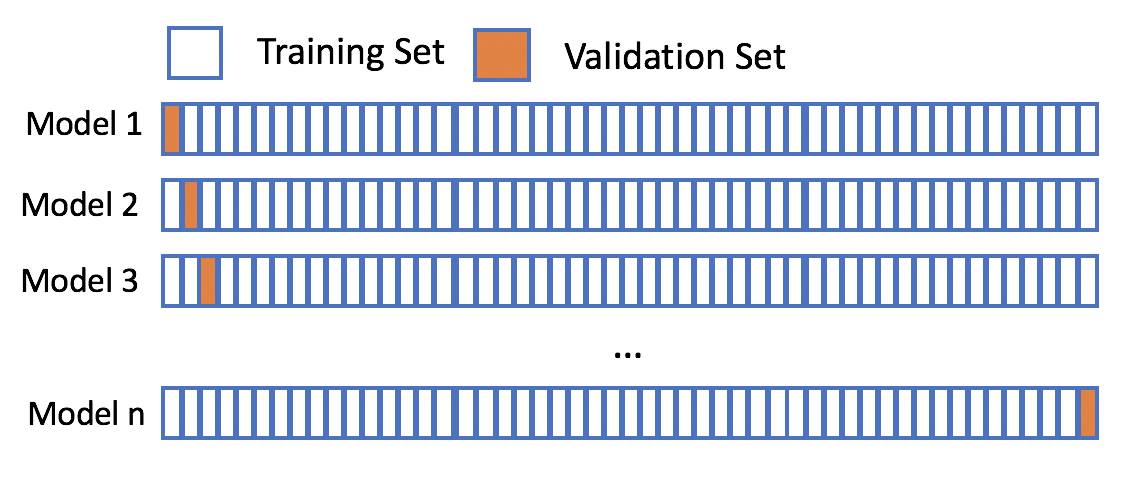
# 1. 验证集的概念与作用
在机器学习和统计学中,验证集是用来评估模型性能和选择超参数的重要工具。**验证集**是在训练集之外的一个独立数据集,通过对这个数据集的预测结果来估计模型在未见数据上的表现,从而避免了过拟合问题。验证集的作用不仅仅在于选择最佳模型,还能帮助我们理解模型在实际应用中的泛化能力,是开发高质量预测模型不可或缺的一部分。
```markdown
## 1.1 验证集与训练集、测试集的区
自然语言处理中的独热编码:应用技巧与优化方法
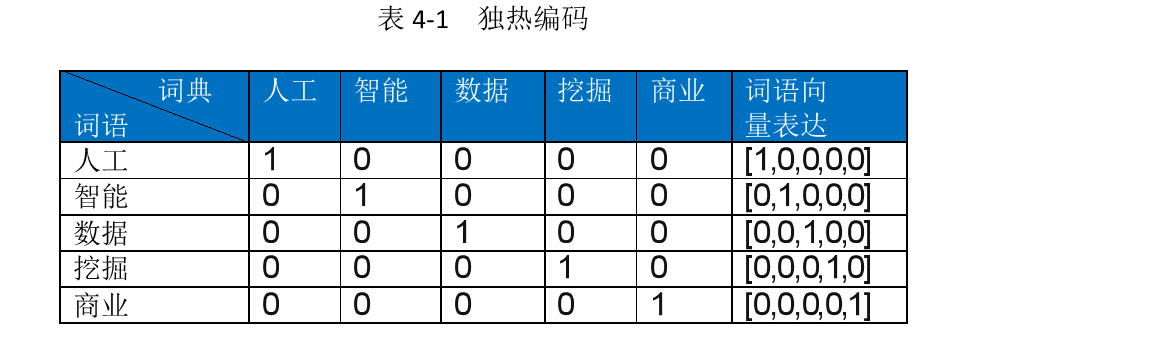
# 1. 自然语言处理与独热编码概述
自然语言处理(NLP)是计算机科学与人工智能领域中的一个关键分支,它让计算机能够理解、解释和操作人类语言。为了将自然语言数据有效转换为机器可处理的形式,独热编码(One-Hot Encoding)成为一种广泛应用的技术。
## 1.1 NLP中的数据表示
在NLP中,数据通常是以文本形式出现的。为了将这些文本数据转换为适合机器学习模型的格式,我们需要将单词、短语或句子等元
测试集在兼容性测试中的应用:确保软件在各种环境下的表现

# 1. 兼容性测试的概念和重要性
## 1.1 兼容性测试概述
兼容性测试确保软件产品能够在不同环境、平台和设备中正常运行。这一过程涉及验证软件在不同操作系统、浏览器、硬件配置和移动设备上的表现。
## 1.2 兼容性测试的重要性
在多样的IT环境中,兼容性测试是提高用户体验的关键。它减少了因环境差异导致的问题,有助于维护软件的稳定性和可靠性,降低后
过拟合的统计检验:如何量化模型的泛化能力

# 1. 过拟合的概念与影响
## 1.1 过拟合的定义
过拟合(overfitting)是机器学习领域中一个关键问题,当模型对训练数据的拟合程度过高,以至于捕捉到了数据中的噪声和异常值,导致模型泛化能力下降,无法很好地预测新的、未见过的数据。这种情况下的模型性能在训练数据上表现优异,但在新的数据集上却表现不佳。
## 1.2 过拟合产生的原因
过拟合的产生通常与模
【特征工程稀缺技巧】:标签平滑与标签编码的比较及选择指南
# 1. 特征工程简介
## 1.1 特征工程的基本概念
特征工程是机器学习中一个核心的步骤,它涉及从原始数据中选取、构造或转换出有助于模型学习的特征。优秀的特征工程能够显著提升模型性能,降低过拟合风险,并有助于在有限的数据集上提炼出有意义的信号。
## 1.2 特征工程的重要性
在数据驱动的机器学习项目中,特征工程的重要性仅次于数据收集。数据预处理、特征选择、特征转换等环节都直接影响模型训练的效率和效果。特征工程通过提高特征与目标变量的关联性来提升模型的预测准确性。
## 1.3 特征工程的工作流程
特征工程通常包括以下步骤:
- 数据探索与分析,理解数据的分布和特征间的关系。
- 特
【交互特征的影响】:分类问题中的深入探讨,如何正确应用交互特征

# 1. 交互特征在分类问题中的重要性
在当今的机器学习领域,分类问题一直占据着核心地位。理解并有效利用数据中的交互特征对于提高分类模型的性能至关重要。本章将介绍交互特征在分类问题中的基础重要性,以及为什么它们在现代数据科学中变得越来越不可或缺。
## 1.1 交互特征在模型性能中的作用
交互特征能够捕捉到数据中的非线性关系,这对于模型理解和预测复杂模式至关重要。例如
【时间序列分析】:如何在金融数据中提取关键特征以提升预测准确性

# 1. 时间序列分析基础
在数据分析和金融预测中,时间序列分析是一种关键的工具。时间序列是按时间顺序排列的数据点,可以反映出某
探索性数据分析:训练集构建中的可视化工具和技巧
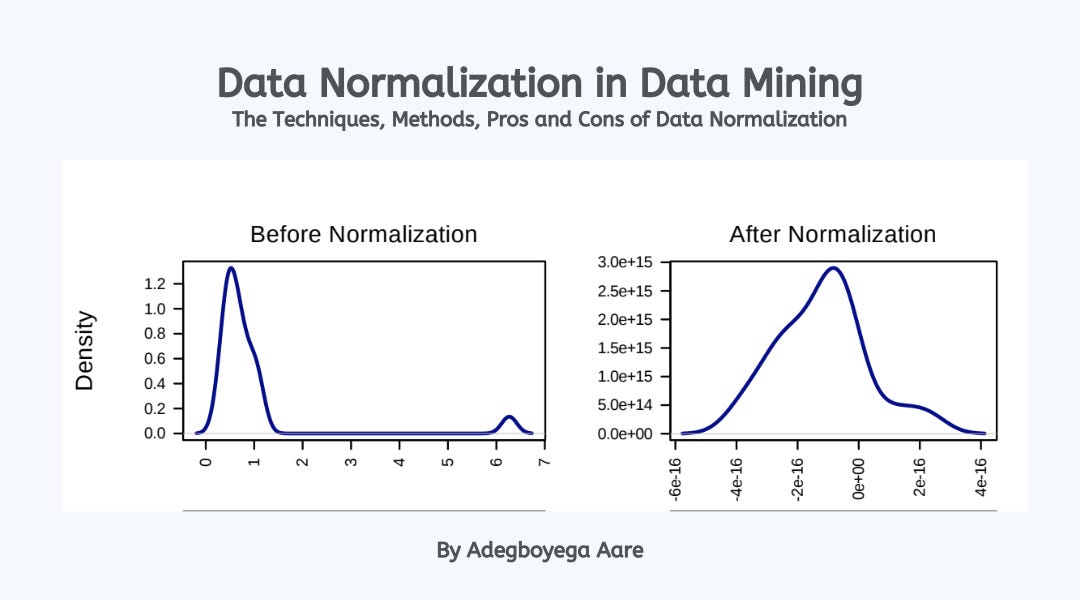
# 1. 探索性数据分析简介
在数据分析的世界中,探索性数据分析(Exploratory Dat
【PCA算法优化】:减少计算复杂度,提升处理速度的关键技术

# 1. PCA算法简介及原理
## 1.1 PCA算法定义
主成分分析(PCA)是一种数学技术,它使用正交变换来将一组可能相关的变量转换成一组线性不相关的变量,这些新变量被称为主成分。
## 1.2 应用场景概述
PCA广泛应用于图像处理、降维、模式识别和数据压缩等领域。它通过减少数据的维度,帮助去除冗余信息,同时尽可能保
【特征选择工具箱】:R语言中的特征选择库全面解析

# 1. 特征选择在机器学习中的重要性
在机器学习和数据分析的实践中,数据集往往包含大量的特征,而这些特征对于最终模型的性能有着直接的影响。特征选择就是从原始特征中挑选出最有用的特征,以提升模型的预测能力和可解释性,同时减少计算资源的消耗。特征选择不仅能够帮助我
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )