MATLAB Genetic Algorithm vs. Conventional Methods: A Deep Comparative Study Revealing Advantages
发布时间: 2024-09-15 04:03:51 阅读量: 70 订阅数: 40 
# Genetic Algorithms vs Traditional Methods: A Comprehensive Comparative Study Revealing Advantages
## 1. Introduction to Genetic Algorithms and MATLAB Overview
Genetic algorithms are heuristic search algorithms that simulate the processes of natural selection and genetics. As a global optimization technique, they demonstrate significant capability in solving optimization problems in areas such as combinatorial optimization, machine learning, and many others.
### 1.1 A Brief Introduction to Genetic Algorithms
Proposed by John Holland and his students and colleagues in 1975, genetic algorithms have seen rapid development. Their core idea is based on a population-based search strategy that evolves optimal solutions through selection, crossover, and mutation operations within the potential solution space.
### 1.2 An Overview of MATLAB and Its Role in Algorithm Implementation
MATLAB is a high-performance numerical computing and visualization software platform widely used in engineering, scientific research, and education. Its powerful matrix computation capabilities and extensive function libraries make MATLAB one of the preferred tools for implementing and researching genetic algorithms.
The following chapter will delve into the fundamental concepts of genetic algorithms and MATLAB's role in their implementation.
# 2. Theoretical Foundations of Genetic Algorithms
## 2.1 How Genetic Algorithms Work
### 2.1.1 Origins and Development of Genetic Algorithms
Genetic algorithms (GAs) are search and optimization algorithms inspired by the processes of natural selection and genetic mechanisms. Originating in the 1970s, they were proposed by Professor John Holland and further developed by his students and colleagues. The inspiration for GAs comes from Darwin's theory of evolution and Mendel's principles of genetics.
The fundamental idea behind GAs is to continuously select, crossover, and mutate within a set of candidate solutions by simulating the process of natural selection, thereby gradually optimizing the quality of solutions. They require no specific mathematical model of the problem, possess global search capabilities, and are particularly suited for handling complex problems that traditional optimization methods struggle with.
Since their inception, genetic algorithms have been applied in many fields, including engineering optimization, machine learning, and data mining. As research deepens and computational power increases, GAs have seen significant theoretical and practical advancements. Today, GAs have become an important branch of computational intelligence and evolutionary computation, providing effective tools for solving various complex optimization problems.
### 2.1.2 Key Components of Genetic Algorithms
Genetic algorithms consist of several crucial parts:
- **Encoding**: In genetic algorithms, the first step is to encode the potential solutions to a problem into a suitable data structure, typically binary strings (chromosomes).
- **Initial Population**: Randomly generate a set of solutions in the search space to form the initial population.
- **Fitness Function**: Evaluate the ability of each individual to adapt to the environment, which corresponds to the quality of the solution.
- **Selection**: Based on the results of the fitness function, select superior individuals from the current population to produce a new generation.
- **Crossover**: Simulate the recombination process of biological genes by exchanging parts of the genes between two individuals to produce new offspring.
- **Mutation**: Randomly change parts of an individual's genes with a small probability to maintain the diversity of the population.
- **Termination Condition**: Define when the algorithm should stop, such as reaching a preset number of iterations or when the quality of a solution surpasses a certain threshold.
These components collectively form the basic framework of genetic algorithms and interact during the execution process, driving the algorithm's continuous evolution until an optimal or satisfactory solution to the problem is found.
## 2.2 Mathematical Models of Genetic Algorithms
### 2.2.1 Mathematical Explanation of Selection, Crossover, and Mutation Operations
#### Selection Operation
The selection operation aims to simulate the principle of survival of the fittest in nature, ***mon selection methods include roulette wheel selection and tournament selection.
**Roulette Wheel Selection** is a probability-based selection method where the probability of an individual being selected is proportional to its fitness. The mathematical expression can be represented as:
\[ P_i = \frac{f_i}{\sum_{j=1}^{N} f_j} \]
Where \(P_i\) is the probability of the \(i^{th}\) individual being selected, \(f_i\) is the fitness of individual \(i\), and \(N\) is the number of individuals in the population.
#### Crossover Operation
The crossover operation is used to produce new individuals and is the primary me***mon crossover strategies include single-point crossover, multi-point crossover, and uniform crossover.
Mathematically, single-point crossover can be understood as cutting a chromosome at a certain point and exchanging the segments on one side of the cut point. If the crossover point is set as \(c\), then the two parts of the chromosome can be combined as follows:
\[ C_{new} = \{C_{1[:c]} + C_{2[c:]}\} \]
Here \(C_1\) and \(C_2\) are the two chromosomes participating in the crossover, \(C_{1[:c]}\) represents the segment of \(C_1\) from the start to point \(c\), and \(C_{2[c:]}\) represents the segment of \(C_2\) from point \(c\) to the end.
#### Mutation Operation
The mutation operation increases the diversity of the population by randomly changing parts of an individual's genes to prevent the algorithm from converging on local optima. Mutation probabilities are typically low and mathematically represented as:
\[ P_{mutation} = \frac{1}{L} \]
Where \(P_{mutation}\) is the mutation probability, and \(L\) is the length of the chromosome.
Mutation can be simply expressed as:
\[ C_{mutated} = C \oplus \Delta \]
Where \(C_{mutated}\) represents the mutated chromosome, \(C\) is the original chromosome, and \(\Delta\) represents the mutation operation applied to the chromosome.
### 2.2.2 Analysis of Population Diversity and Algorithm Convergence
Population diversity refers to the diversity of individual genes within a population, which is crucial for genetic algorithms to avoid premature convergence and maintain exploration capabilities. Population diversity can be measured using gene diversity indices, entropy, and other metrics.
The analysis of algorithm convergence focuses on the probability of the algorithm finding the global optimum and the speed at which it reaches this solution. In theory, a good genetic algorithm should be able to guide the population towards the optimal solution while ensuring population diversity.
Analyzing the convergence of genetic algorithms requires considering the following aspects:
- **Fitness Landscape**: Reflects the characteristics of the problem's solution space. An ideal fitness landscape should have fewer local optima to facilitate the algorithm finding the global optimum.
- **Selection Pressure**: Determines the degree to which the algorithm favors individual fitness during the selection process. If the selection pressure is too high, the algorithm may converge on local optima quickly; if it's too low, it may result in slow convergence.
- **Crossover and Mutation Strategies**: These are the primary means of maintaining population diversity. Crossover strategies affect the diversity of offspring, while mutation strategies somewhat determine the algorithm's ability to escape local optima.
From a mathematical perspective, the convergence of genetic algorithms can be analyzed using Markov chain theory. If the algorithm's state is represented by the current population and the state transition probability is determined by the selection, crossover, and mutation strategies, theoretical analysis suggests that genetic algorithms can be considered a non-stationary Markov process. The global convergence of the algorithm can be proven using the properties of Markov chains.
In summary, population diversity and convergence analysis are important issues in genetic algorithm research and provide significant guidance for designing efficient genetic algorithms.
# 3. Applications of MATLAB in Genetic Algorithms
## 3.1 MATLAB Genetic Algorithm Toolbox
### 3.1.1 Installation and Configuration of the Toolbox
The MATLAB Genetic Algorithm Toolbox (GA Toolbox) is a specialized toolbox for genetic algorithm programming within the MA

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【特征工程稀缺技巧】:标签平滑与标签编码的比较及选择指南
# 1. 特征工程简介
## 1.1 特征工程的基本概念
特征工程是机器学习中一个核心的步骤,它涉及从原始数据中选取、构造或转换出有助于模型学习的特征。优秀的特征工程能够显著提升模型性能,降低过拟合风险,并有助于在有限的数据集上提炼出有意义的信号。
## 1.2 特征工程的重要性
在数据驱动的机器学习项目中,特征工程的重要性仅次于数据收集。数据预处理、特征选择、特征转换等环节都直接影响模型训练的效率和效果。特征工程通过提高特征与目标变量的关联性来提升模型的预测准确性。
## 1.3 特征工程的工作流程
特征工程通常包括以下步骤:
- 数据探索与分析,理解数据的分布和特征间的关系。
- 特
【特征选择工具箱】:R语言中的特征选择库全面解析

# 1. 特征选择在机器学习中的重要性
在机器学习和数据分析的实践中,数据集往往包含大量的特征,而这些特征对于最终模型的性能有着直接的影响。特征选择就是从原始特征中挑选出最有用的特征,以提升模型的预测能力和可解释性,同时减少计算资源的消耗。特征选择不仅能够帮助我
p值在机器学习中的角色:理论与实践的结合

# 1. p值在统计假设检验中的作用
## 1.1 统计假设检验简介
统计假设检验是数据分析中的核心概念之一,旨在通过观察数据来评估关于总体参数的假设是否成立。在假设检验中,p值扮演着决定性的角色。p值是指在原
【时间序列分析】:如何在金融数据中提取关键特征以提升预测准确性

# 1. 时间序列分析基础
在数据分析和金融预测中,时间序列分析是一种关键的工具。时间序列是按时间顺序排列的数据点,可以反映出某
【复杂数据的置信区间工具】:计算与解读的实用技巧
# 1. 置信区间的概念和意义
置信区间是统计学中一个核心概念,它代表着在一定置信水平下,参数可能存在的区间范围。它是估计总体参数的一种方式,通过样本来推断总体,从而允许在统计推断中存在一定的不确定性。理解置信区间的概念和意义,可以帮助我们更好地进行数据解释、预测和决策,从而在科研、市场调研、实验分析等多个领域发挥作用。在本章中,我们将深入探讨置信区间的定义、其在现实世界中的重要性以及如何合理地解释置信区间。我们将逐步揭开这个统计学概念的神秘面纱,为后续章节中具体计算方法和实际应用打下坚实的理论基础。
# 2. 置信区间的计算方法
## 2.1 置信区间的理论基础
### 2.1.1
自然语言处理中的独热编码:应用技巧与优化方法
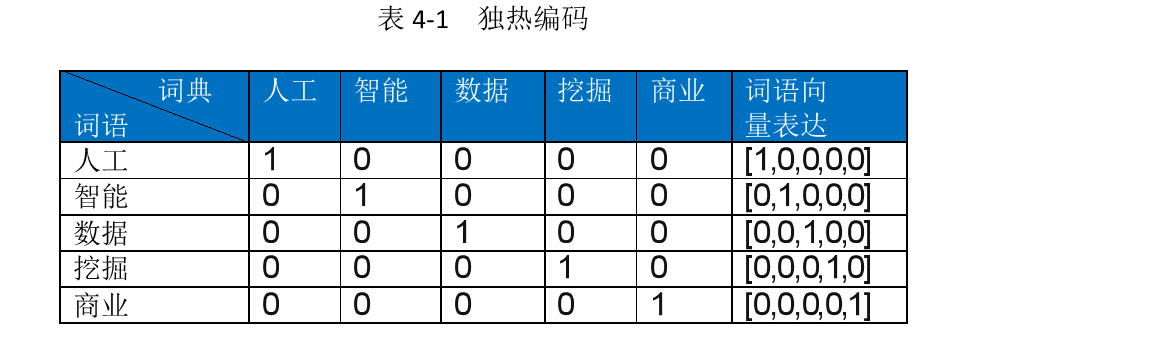
# 1. 自然语言处理与独热编码概述
自然语言处理(NLP)是计算机科学与人工智能领域中的一个关键分支,它让计算机能够理解、解释和操作人类语言。为了将自然语言数据有效转换为机器可处理的形式,独热编码(One-Hot Encoding)成为一种广泛应用的技术。
## 1.1 NLP中的数据表示
在NLP中,数据通常是以文本形式出现的。为了将这些文本数据转换为适合机器学习模型的格式,我们需要将单词、短语或句子等元
训练集大小对性能的影响:模型评估的10大策略

# 1. 模型评估的基础知识
在机器学习与数据科学领域中,模型评估是验证和比较机器学习算法表现的核心环节。本章节将从基础层面介绍模型评估的基本概念和重要性。我们将探讨为什么需要评估模型、评估模型的目的以及如何选择合适的评估指标。
## 1.1 评估的重要性
模型评估是为了确定模型对未知数据的预测准确性与可靠性。一个训练好的模型,只有在独立的数据集上表现良好,才能够
大样本理论在假设检验中的应用:中心极限定理的力量与实践

# 1. 中心极限定理的理论基础
## 1.1 概率论的开篇
概率论是数学的一个分支,它研究随机事件及其发生的可能性。中心极限定理是概率论中最重要的定理之一,它描述了在一定条件下,大量独立随机变量之和(或平均值)的分布趋向于正态分布的性
【交互特征的影响】:分类问题中的深入探讨,如何正确应用交互特征

# 1. 交互特征在分类问题中的重要性
在当今的机器学习领域,分类问题一直占据着核心地位。理解并有效利用数据中的交互特征对于提高分类模型的性能至关重要。本章将介绍交互特征在分类问题中的基础重要性,以及为什么它们在现代数据科学中变得越来越不可或缺。
## 1.1 交互特征在模型性能中的作用
交互特征能够捕捉到数据中的非线性关系,这对于模型理解和预测复杂模式至关重要。例如
【PCA算法优化】:减少计算复杂度,提升处理速度的关键技术

# 1. PCA算法简介及原理
## 1.1 PCA算法定义
主成分分析(PCA)是一种数学技术,它使用正交变换来将一组可能相关的变量转换成一组线性不相关的变量,这些新变量被称为主成分。
## 1.2 应用场景概述
PCA广泛应用于图像处理、降维、模式识别和数据压缩等领域。它通过减少数据的维度,帮助去除冗余信息,同时尽可能保
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )