揭秘多元线性回归变量选择秘籍:从特征工程到模型优化
发布时间: 2024-06-09 06:01:23 阅读量: 211 订阅数: 84 

多元线性回归分析

# 1. 多元线性回归简介**
多元线性回归是一种统计模型,用于预测一个连续型因变量(目标变量)与多个自变量(特征)之间的线性关系。它假设因变量与自变量之间存在线性相关性,并且可以通过一条直线来拟合数据。
多元线性回归的公式如下:
```
y = b0 + b1x1 + b2x2 + ... + bnxn + ε
```
其中:
* y 是因变量
* x1, x2, ..., xn 是自变量
* b0 是截距
* b1, b2, ..., bn 是自变量的系数
* ε 是误差项
# 2. 特征工程
### 2.1 特征选择的重要性
#### 2.1.1 过拟合与欠拟合问题
在机器学习中,过拟合和欠拟合是常见的两个问题:
- **过拟合:**模型在训练集上表现良好,但在新数据上表现不佳。这是因为模型学习了训练集中的噪声和异常值,而不是学习数据的底层模式。
- **欠拟合:**模型在训练集和新数据上都表现不佳。这是因为模型没有从数据中学习到足够的模式。
#### 2.1.2 特征选择的作用
特征选择通过选择与目标变量最相关的特征,可以帮助解决过拟合和欠拟合问题。通过减少特征数量,特征选择可以:
- 减少噪声和异常值的影响,从而降低过拟合的风险。
- 提高模型的泛化能力,从而降低欠拟合的风险。
- 加快训练时间,因为模型需要处理的特征更少。
### 2.2 特征选择方法
特征选择方法可分为三类:
#### 2.2.1 过滤式方法
过滤式方法根据特征的统计属性(如相关性、方差)对特征进行评分和排序。常见的方法包括:
- **皮尔逊相关系数:**衡量特征与目标变量之间的线性相关性。
- **信息增益:**衡量特征将目标变量分类的能力。
- **卡方检验:**衡量特征与目标变量之间的非线性相关性。
```python
import pandas as pd
from sklearn.feature_selection import SelectKBest, chi2
# 加载数据
data = pd.read_csv('data.csv')
# 使用卡方检验选择特征
selector = SelectKBest(chi2, k=10)
selector.fit(data.drop('target', axis=1), data['target'])
# 输出选择的特征
print(selector.get_support())
```
#### 2.2.2 包裹式方法
包裹式方法使用机器学习模型来评估特征子集的性能。常见的方法包括:
- **向前选择:**逐个添加特征,直到模型性能不再提高。
- **向后选择:**逐个删除特征,直到模型性能不再下降。
- **递归特征消除:**反复训练模型并删除对模型影响最小的特征。
```python
from sklearn.feature_selection import RFE
from sklearn.linear_model import LinearRegression
# 加载数据
data = pd.read_csv('data.csv')
# 使用递归特征消除选择特征
selector = RFE(LinearRegression(), n_features_to_select=10)
selector.fit(data.drop('target', axis=1), data['target'])
# 输出选择的特征
print(selector.get_support())
```
#### 2.2.3 嵌入式方法
嵌入式方法将特征选择作为模型训练过程的一部分。常见的方法包括:
- **L1 正则化(LASSO):**通过惩罚特征系数的绝对值来选择特征。
- **L2 正则化(岭回归):**通过惩罚特征系数的平方值来选择特征。
- **树形模型:**如决策树和随机森林,通过分裂特征来选择特征。
```python
from sklearn.linear_model import Lasso
# 加载数据
data = pd.read_csv('data.csv')
# 使用 L1 正则化选择特征
model = Lasso(alpha=0.1)
model.fit(data.drop('target', axis=1), data['target'])
# 输出选择的特征
print(model.coef_)
```
**mermaid流程图:**
```mermaid
graph LR
subgraph 特征选择
A[过滤式方法] --> B[包裹式方法]
A --> C[嵌入式方法]
end
subgraph 模型选择
B --> D[交叉验证]
C --> D
end
subgraph 模型优化
D --> E[梯度下降算法]
D --> F[超参数调优]
end
```
# 3.1 模型评估指标
#### 3.1.1 均方根误差(RMSE)
均方根误差(RMSE)是衡量模型预测值与真实值之间差异程度的常用指标。其计算公式为:
```python
RMSE = sqrt(mean((y_true - y_pred)**2))
```
其中:
- `y_true` 为真实值
- `y_pred` 为预测值
RMSE 的值越小,表示模型的预测精度越高。
#### 3.1.2 决定系数(R²)
决定系数(R²)反映了模型预测值与真实值之间的相关性。其计算公式为:
```python
R² = 1 - (sum((y_true - y_pred)**2) / sum((y_true - mean(y_true))**2))
```
R² 的取值范围为 0 到 1。R² 越接近 1,表示模型预测值与真实值之间的相关性越强。
#### 3.1.3 调整决定系数(Adjusted R²)
调整决定系数(Adjusted R²)是对决定系数的修正,考虑了模型的复杂度。其计算公式为:
```python
Adjusted R² = 1 - (1 - R²) * (n - 1) / (n - p - 1)
```
其中:
- `n` 为样本数量
- `p` 为模型中自变量的数量
调整决定系数的取值范围也为 0 到 1。与决定系数不同,调整决定系数会随着模型复杂度的增加而减小。因此,在选择模型时,应优先考虑调整决定系数较高的模型。
### 3.2 模型选择策略
#### 3.2.1 交叉验证
交叉验证是一种用于评估模型泛化能力的技术。其基本原理是将数据集划分为多个子集,依次使用其中一个子集作为测试集,其余子集作为训练集,并计算模型在测试集上的评估指标。
交叉验证可以有效防止模型过拟合,并得到模型在不同数据集上的平均性能。常用的交叉验证方法包括:
- **K 折交叉验证:**将数据集划分为 K 个子集,依次使用每个子集作为测试集,其余子集作为训练集。
- **留一法交叉验证:**将数据集划分为 N 个子集(N 为样本数量),依次使用每个子集作为测试集,其余子集作为训练集。
#### 3.2.2 正则化
正则化是一种用于防止模型过拟合的技术。其基本原理是向模型的损失函数中添加一个惩罚项,以限制模型的复杂度。
常用的正则化方法包括:
- **L1 正则化:**惩罚模型中权重的绝对值之和。
- **L2 正则化:**惩罚模型中权重的平方和。
正则化可以通过减小模型权重的幅度来降低模型的复杂度,从而防止过拟合。
# 4.1 梯度下降算法
### 4.1.1 梯度下降的基本原理
梯度下降算法是一种迭代优化算法,用于寻找函数的最小值或最大值。其基本原理是:
1. **初始化:**选择一个初始点 **w**,表示模型参数。
2. **计算梯度:**计算函数 **f(w)** 在当前点 **w** 处的梯度 **∇f(w)**,它表示函数在该点处的变化率。
3. **更新参数:**根据梯度下降公式更新模型参数:
```
w = w - α * ∇f(w)
```
其中,**α** 是学习率,控制更新步长。
4. **重复步骤 2-3:**重复计算梯度和更新参数,直到满足终止条件(例如,梯度接近于零或达到最大迭代次数)。
### 4.1.2 梯度下降的变种
基本梯度下降算法存在一些缺点,例如收敛速度慢、容易陷入局部最优。为了解决这些问题,提出了多种梯度下降变种:
- **动量梯度下降 (Momentum):**引入动量项,使更新方向更加平滑,加速收敛。
- **RMSProp:**自适应学习率算法,根据梯度历史值调整学习率,提高收敛速度。
- **Adam:**结合动量和 RMSProp 的优点,是一种高效且稳定的优化算法。
**代码块:**
```python
import numpy as np
def gradient_descent(f, gradient, w0, alpha, max_iter=1000):
"""梯度下降算法
Args:
f: 待优化函数
gradient: 函数梯度
w0: 初始参数
alpha: 学习率
max_iter: 最大迭代次数
Returns:
最优参数
"""
w = w0
for i in range(max_iter):
grad = gradient(w)
w = w - alpha * grad
return w
```
**代码逻辑逐行解读:**
1. 导入 NumPy 库。
2. 定义 `gradient_descent` 函数,接受待优化函数 `f`、函数梯度 `gradient`、初始参数 `w0`、学习率 `alpha` 和最大迭代次数 `max_iter`。
3. 初始化参数 `w` 为 `w0`。
4. 进入迭代循环,最大迭代次数为 `max_iter`。
5. 计算当前参数 `w` 处的梯度 `grad`。
6. 根据梯度下降公式更新参数 `w`。
7. 返回最优参数 `w`。
# 5. 案例实践
### 5.1 房价预测案例
#### 5.1.1 数据预处理
房价预测案例的数据集包含了美国波士顿地区 506 套房屋的各种特征,包括犯罪率、房屋年龄、房间数量等。在进行建模之前,需要对数据进行预处理,包括缺失值处理、异常值处理和特征缩放。
#### 5.1.2 特征选择
特征选择是房价预测中至关重要的一步。通过剔除不相关的或冗余的特征,可以提高模型的性能和泛化能力。本案例中,使用过滤式特征选择方法,根据相关系数和方差阈值选择特征。
```python
# 导入相关库
import pandas as pd
from sklearn.feature_selection import SelectKBest, f_regression
# 加载数据
data = pd.read_csv('boston_housing.csv')
# 特征选择
selector = SelectKBest(f_regression, k=10)
selector.fit(data.drop('MEDV', axis=1), data['MEDV'])
# 输出选择的特征
print(data.columns[selector.get_support()])
```
#### 5.1.3 模型训练与评估
特征选择后,使用线性回归模型进行训练。为了评估模型的性能,使用交叉验证和多种评估指标,包括均方根误差(RMSE)、决定系数(R²)和调整决定系数(Adjusted R²)。
```python
# 导入相关库
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
# 模型训练
model = LinearRegression()
model.fit(data.drop('MEDV', axis=1), data['MEDV'])
# 交叉验证
scores = cross_val_score(model, data.drop('MEDV', axis=1), data['MEDV'], cv=10)
# 输出评估指标
print('RMSE:', np.mean(scores))
print('R²:', model.score(data.drop('MEDV', axis=1), data['MEDV']))
print('Adjusted R²:', 1 - (1 - model.score(data.drop('MEDV', axis=1), data['MEDV'])) * (len(data) - 1) / (len(data) - model.n_features - 1))
```
### 5.2 销量预测案例
#### 5.2.1 数据预处理
销量预测案例的数据集包含了某零售商过去一年的销售数据,包括产品类别、促销活动、季节性等特征。在进行建模之前,需要对数据进行预处理,包括缺失值处理、异常值处理和特征编码。
#### 5.2.2 特征选择
销量预测中,特征选择同样至关重要。本案例中,使用包裹式特征选择方法,以决策树模型为基础,通过递归特征消除(RFE)选择特征。
```python
# 导入相关库
from sklearn.tree import DecisionTreeClassifier
from sklearn.feature_selection import RFE
# 加载数据
data = pd.read_csv('sales_data.csv')
# 特征选择
selector = RFE(DecisionTreeClassifier(), n_features_to_select=10)
selector.fit(data.drop('销量', axis=1), data['销量'])
# 输出选择的特征
print(data.columns[selector.get_support()])
```
#### 5.2.3 模型训练与评估
特征选择后,使用逻辑回归模型进行训练。为了评估模型的性能,使用交叉验证和多种评估指标,包括准确率、召回率和 F1 得分。
```python
# 导入相关库
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score
# 模型训练
model = LogisticRegression()
model.fit(data.drop('销量', axis=1), data['销量'])
# 交叉验证
scores = cross_val_score(model, data.drop('销量', axis=1), data['销量'], cv=10)
# 输出评估指标
print('准确率:', np.mean(scores))
print('召回率:', model.score(data.drop('销量', axis=1), data['销量']))
print('F1 得分:', 2 * model.score(data.drop('销量', axis=1), data['销量']) * (1 - model.score(data.drop('销量', axis=1), data['销量'])) / (model.score(data.drop('销量', axis=1), data['销量']) + (1 - model.score(data.drop('销量', axis=1), data['销量']))))
```
# 6. 总结与展望**
**多元线性回归变量选择的总结**
多元线性回归变量选择是一个至关重要的过程,它可以有效地提高模型的性能,避免过拟合和欠拟合问题。本文从特征工程和模型优化的角度,全面介绍了多元线性回归变量选择的方法和策略。
**特征工程**
特征选择是特征工程的关键步骤,它可以去除冗余和无关的特征,从而提高模型的泛化能力。过滤式方法、包裹式方法和嵌入式方法是三种常用的特征选择方法,它们各有优缺点。
**模型优化**
模型优化是提高模型性能的另一个重要方面。梯度下降算法是多元线性回归模型优化的核心算法,其变种包括批量梯度下降、随机梯度下降和动量梯度下降。超参数调优可以通过网格搜索或贝叶斯优化等方法进行,以找到模型的最佳超参数。
**未来研究方向**
多元线性回归变量选择是一个不断发展的领域,未来研究方向包括:
- 开发新的特征选择算法,提高特征选择效率和准确性。
- 探索新的模型优化方法,提高模型的泛化能力和鲁棒性。
- 将多元线性回归变量选择与其他机器学习技术相结合,构建更强大的预测模型。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探究多元线性回归,涵盖从特征工程到模型优化的各个方面。通过揭秘变量选择秘籍、评估技巧、正则化策略、协线性诊断、异常值处理、交叉验证、多重共线性处理、变量转换、模型选择、残差分析、非线性关系处理、数据标准化、交互作用探索、主成分分析、岭回归、偏最小二乘回归、支持向量回归、神经网络应用和空间分析,专栏提供全面的指南,帮助读者掌握多元线性回归的精髓。无论您是初学者还是经验丰富的从业者,本专栏都能为您提供宝贵的见解和实用的技巧,助您提升模型性能,解决现实世界中的问题。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
【16位加法器设计秘籍】:全面揭秘高性能计算单元的构建与优化

# 摘要
本文对16位加法器进行了全面的研究和分析。首先回顾了加法器的基础知识,然后深入探讨了16位加法器的设计原理,包括二进制加法基础、组成部分及其高性能设计考量。接着,文章详细阐述
三菱FX3U PLC编程:从入门到高级应用的17个关键技巧

# 摘要
三菱FX3U PLC是工业自动化领域常用的控制器之一,本文全面介绍了其编程技巧和实践应用。文章首先概述了FX3U PLC的基本概念、功能和硬件结构,随后深入探讨了
【Xilinx 7系列FPGA深入剖析】:掌握架构精髓与应用秘诀
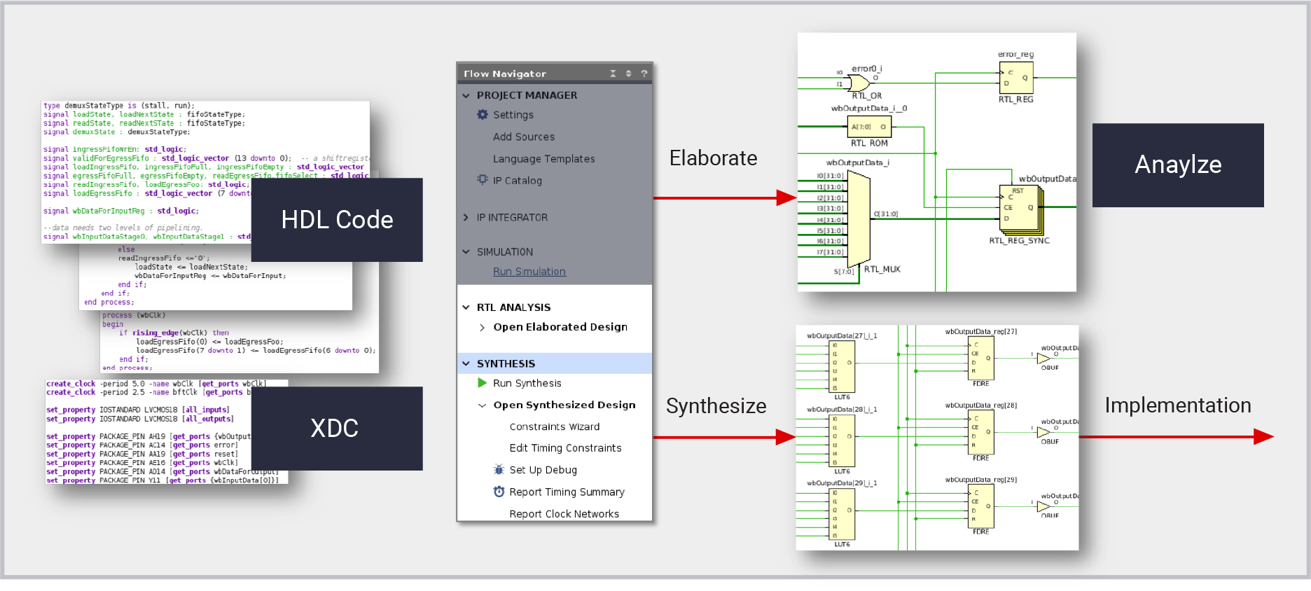
# 摘要
本文详细介绍了Xilinx 7系列FPGA的关键特性及其在工业应用中的广泛应用。首先概述了7系列FPGA的基本架构,包括其核心的可编程逻辑单元(PL)、集成的块存储器(BRAM)和数字信号处理(DSP)单元。接着,本文探讨了使用Xilinx工具链进行FPGA编程与配置的流程,强调了设计优化和设备配置的重要性。文章进一步分析了7系列FPGA在
【图像技术的深度解析】:Canvas转JPEG透明度保护的终极策略

# 摘要
随着Web技术的不断发展,图像技术在前端开发中扮演着越来越重要的角色。本文首先介绍了图像技术的基础和Canvas绘
【MVC标准化:肌电信号处理的终极指南】:提升数据质量的10大关键步骤与工具
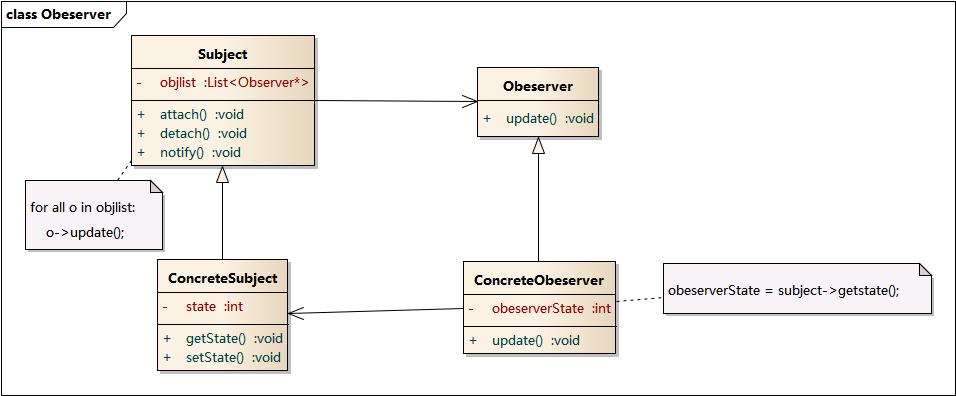
# 摘要
MVC标准化是肌电信号处理中确保数据质量的重要步骤,它对于提高测量结果的准确性和可重复性至关重要。本文首先介绍肌电信号的生理学原理和MVC标准化理论,阐述了数据质量的重要性及影响因素。随后,文章深入探讨了肌电信号预处理的各个环节,包括噪声识别与消除、信号放大与滤波技术、以及基线漂移的校正方法。在提升数据质量的关键步骤部分,本文详细描述了信号特征提取、MVC标准化的实施与评估,并讨论了数据质量评估与优化工具。最后,本文通过实验设计和案例分析,展示了MVC标准化在实践应用中的具
ISA88.01批量控制:电子制造流程优化的5大策略

# 摘要
本文首先概述了ISA88.01批量控制标准,接着深入探讨了电子制造流程的理论基础,包括原材料处理、制造单元和工作站的组成部分,以及流程控制的理论框架和优化的核心原则。进一步地,本文实
【Flutter验证码动画效果】:如何设计提升用户体验的交互

# 摘要
随着移动应用的普及和安全需求的提升,验证码动画作为提高用户体验和安全性的关键技术,正受到越来越多的关注。本文首先介绍Flutter框架下验证码动画的重要性和基本实现原理,涵盖了动画的类型、应用场景、设计原则以及开发工具和库。接着,文章通过实践篇深入探讨了在Flutter环境下如何具体实现验证码动画,包括基础动画的制作、进阶技巧和自定义组件的开发。优化篇
ENVI波谱分类算法:从理论到实践的完整指南
# 摘要
ENVI软件作为遥感数据处理的主流工具之一,提供了多种波谱分类算法用于遥感图像分析。本文首先概述了波谱分类的基本概念及其在遥感领域的重要性,然后介绍了ENVI软件界面和波谱数据预处理的流程。接着,详细探讨了ENVI软件中波谱分类算法的实现方法,通过实践案例演示了像元级和对象级波谱分类算法的操作。最后,文章针对波谱分类的高级应用、挑战及未来发展进行了讨论,重点分析了高光谱数据分类和深度学习在波谱分类中的应用情况,以及波谱分类在土地覆盖制图和农业监测中的实际应用。
# 关键字
ENVI软件;波谱分类;遥感图像;数据预处理;分类算法;高光谱数据
参考资源链接:[使用ENVI进行高光谱分
【天线性能提升密籍】:深入探究均匀线阵方向图设计原则及案例分析
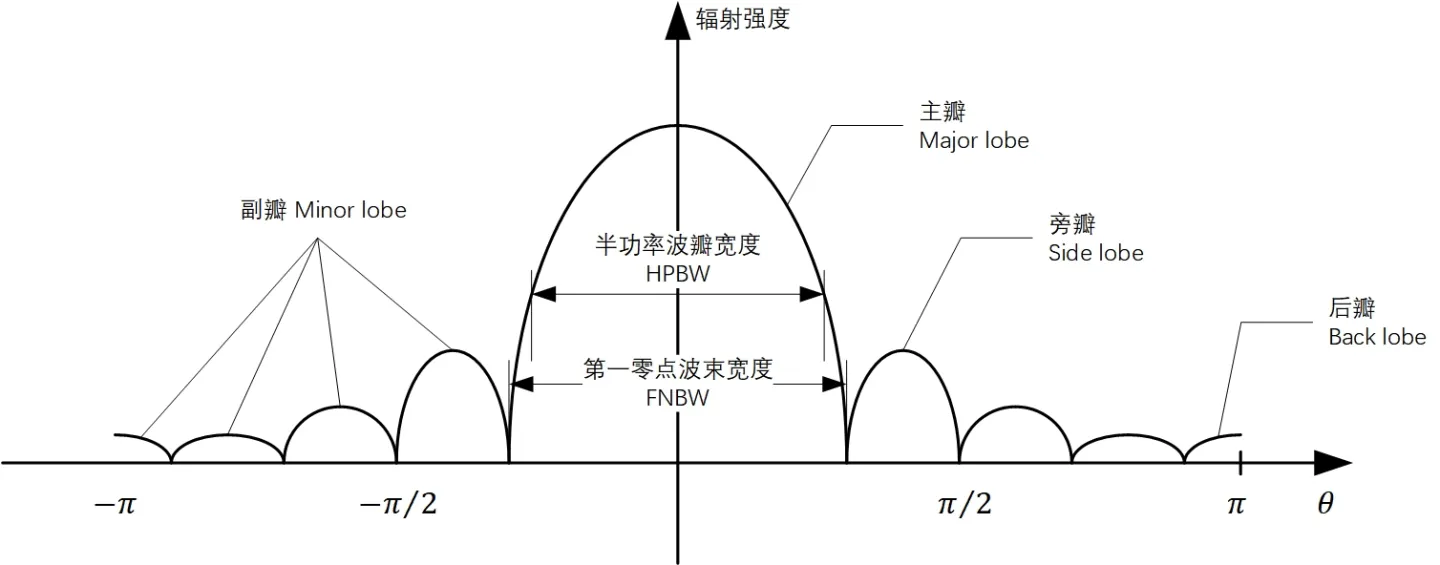
# 摘要
本文深入探讨了均匀线阵天线的基础理论及其方向图设计,旨在提升天线系统的性能和应用效能。文章首先介绍了均匀线阵及方向图的基本概念,并阐述了方向图设计的理论基础,包括波束形成与主瓣及副瓣特性的控制。随后,论文通过设计软件工具的应用和实际天线系统调试方法,展示了方向图设计的实践技巧。文中还包含了一系列案例分析,以实证研究验证理论,并探讨了均匀线阵性能
【兼容性问题】快解决:专家教你确保光盘在各设备流畅读取
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2021/L/w/I3DfXKTAmrqNi0rGtG5A/2014-06-24-cd-dvd-bluray.png)
# 摘要
光盘作为一种传统的数据存储介质,其兼容性问题长
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )