多元线性回归正则化全攻略:L1、L2、弹性网络,帮你解决过拟合难题
发布时间: 2024-06-09 06:05:38 阅读量: 129 订阅数: 84 

多项式拟合 采用了L2正则化来减小过拟合的风险

# 1. 多元线性回归概述**
多元线性回归是一种统计建模技术,用于预测一个连续响应变量(因变量)与多个自变量(预测变量)之间的关系。其数学表达式为:
```
y = β0 + β1x1 + β2x2 + ... + βnxn + ε
```
其中:
* y 是因变量
* x1, x2, ..., xn 是自变量
* β0, β1, ..., βn 是模型参数
* ε 是误差项
多元线性回归假设自变量与因变量之间存在线性关系,并且误差项服从正态分布。它是一种广泛用于预测和解释数据中变量之间关系的强大工具。
# 2. 正则化方法**
正则化是机器学习中一种常用的技术,用于防止过拟合并提高模型的泛化能力。过拟合是指模型在训练数据集上表现良好,但在新数据上表现不佳的情况。正则化通过在损失函数中添加一个惩罚项来实现,该惩罚项与模型的复杂度成正比。
### 2.1 L1正则化(LASSO)
#### 2.1.1 L1正则化的原理
L1正则化(也称为LASSO)在损失函数中添加了一个惩罚项,该惩罚项等于模型中所有系数的绝对值之和。
```python
loss_function = original_loss_function + lambda * np.sum(np.abs(coefficients))
```
其中:
* `original_loss_function` 是原始的损失函数,例如均方误差或交叉熵。
* `lambda` 是正则化参数,控制惩罚项的强度。
* `coefficients` 是模型中的系数。
#### 2.1.2 L1正则化的特点和应用场景
L1正则化具有以下特点:
* **稀疏性:** L1正则化倾向于将某些系数缩小为零,从而产生稀疏模型。这对于特征数量远大于样本数量的情况非常有用。
* **特征选择:** L1正则化可以帮助选择重要的特征,因为系数为零的特征被认为是不重要的。
* **鲁棒性:** L1正则化对异常值不敏感,因为它使用绝对值而不是平方值。
L1正则化适用于以下场景:
* **特征数量远大于样本数量:** 当特征数量远大于样本数量时,L1正则化可以帮助防止过拟合并选择重要的特征。
* **存在异常值:** 当数据中存在异常值时,L1正则化可以提高模型的鲁棒性。
* **需要稀疏模型:** 当需要一个稀疏模型时,例如在特征选择或压缩感知中,L1正则化是一个很好的选择。
### 2.2 L2正则化(Ridge)
#### 2.2.1 L2正则化的原理
L2正则化(也称为Ridge)在损失函数中添加了一个惩罚项,该惩罚项等于模型中所有系数的平方和。
```python
loss_function = original_loss_function + lambda * np.sum(np.square(coefficients))
```
其中:
* `original_loss_function` 是原始的损失函数,例如均方误差或交叉熵。
* `lambda` 是正则化参数,控制惩罚项的强度。
* `coefficients` 是模型中的系数。
#### 2.2.2 L2正则化的特点和应用场景
L2正则化具有以下特点:
* **连续性:** L2正则化不会产生稀疏模型,因为所有系数都保持非零。
* **稳定性:** L2正则化可以提高模型的稳定性,因为它惩罚系数的较大值。
* **计算效率:** L2正则化的计算效率通常高于L1正则化。
L2正则化适用于以下场景:
* **特征数量小于或等于样本数量:** 当特征数量小于或等于样本数量时,L2正则化可以提高模型的稳定性并防止过拟合。
* **不存在异常值:** 当数据中不存在异常值时,L2正则化是一个很好的选择,因为它可以稳定模型而不影响特征选择。
* **需要连续模型:** 当需要一个连续模型时,例如在回归或时间序列预测中,L2正则化是一个很好的选择。
# 3. 正则化方法的应用
### 3.1 正则化参数的选择
#### 3.1.1 交叉验证法
交叉验证是一种用于评估模型性能和选择正则化参数的技术。它将数据集划分为多个子集(称为折),然后依次使用每个子集作为验证集,其余子集作为训练集。
**步骤:**
1. 将数据集划分为 `k` 个折。
2. 对于每个折 `i`:
- 使用 `k-1` 个折作为训练集,训练模型。
- 使用第 `i` 个折作为验证集,评估模型性能(例如,均方误差)。
3. 计算 `k` 个验证集上的平均性能作为模型的性能估计。
#### 3.1.2 信息准则
信息准则是一种基于模型复杂性和拟合优度的统计量,用于选择正则化参数。常用的信息准则包括:
- 赤池信息准则(AIC):`AIC = 2k - 2ln(L)`,其中 `k` 是模型参数的数量,`L` 是模型的似然函数。
- 贝叶斯信息准则(BIC):`BIC = k * ln(n) - 2ln(L)`,其中 `n` 是数据集的大小。
**选择过程:**
1. 对于一系列正则化参数,计算模型的 AIC 或 BIC 值。
2. 选择具有最小 AIC 或 BIC 值的参数。
### 3.2 正则化方法的比较
#### 3.2.1 不同正则化方法的优缺点
| 正则化方法 | 优点 | 缺点 |
|---|---|---|
| L1正则化 | 特征选择 | 可能导致稀疏解 |
| L2正则化 | 提高模型稳定性 | 不会产生稀疏解 |
| 弹性网络正则化 | 结合L1和L2的优点 | 稀疏性和稳定性之间的权衡 |
#### 3.2.2 不同正则化方法的适用场景
| 正则化方法 | 适用场景 |
|---|---|
| L1正则化 | 特征数量远多于样本数量,需要进行特征选择 |
| L2正则化 | 特征数量与样本数量相近,需要提高模型稳定性 |
| 弹性网络正则化 | 介于L1和L2正则化之间,需要同时进行特征选择和提高模型稳定性 |
### 代码示例:
```python
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression, Lasso, Ridge, ElasticNet
# 导入数据
data = pd.read_csv('data.csv')
X = data.drop('target', axis=1)
y = data['target']
# 创建正则化模型
lasso = Lasso(alpha=0.1)
ridge = Ridge(alpha=0.1)
elastic_net = ElasticNet(alpha=0.1, l1_ratio=0.5)
# 训练模型
lasso.fit(X, y)
ridge.fit(X, y)
elastic_net.fit(X, y)
# 评估模型
print('Lasso coefficients:', lasso.coef_)
print('Ridge coefficients:', ridge.coef_)
print('ElasticNet coefficients:', elastic_net.coef_)
```
**代码逻辑分析:**
- 导入必要的库。
- 导入数据并将其划分为特征矩阵 `X` 和目标变量 `y`。
- 创建 L1、L2 和弹性网络正则化模型,并设置正则化参数 `alpha`。
- 使用训练数据训练模型。
- 打印每个模型的系数,以显示正则化对系数的影响。
# 4. 正则化方法在实践中的应用**
**4.1 案例:使用L1正则化解决过拟合问题**
**4.1.1 数据准备和模型训练**
为了演示L1正则化解决过拟合问题的效果,我们使用了一个模拟数据集,该数据集包含100个数据点,每个数据点有10个特征。我们使用多元线性回归模型对该数据集进行拟合,并使用L1正则化来防止过拟合。
```python
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# 生成模拟数据集
np.random.seed(0)
X = np.random.rand(100, 10)
y = 1 + 0.5 * X.sum(axis=1) + np.random.randn(100)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 使用L1正则化拟合多元线性回归模型
model = LinearRegression(fit_intercept=False, penalty='l1', C=0.1)
model.fit(X_train, y_train)
```
**4.1.2 模型评估和正则化参数选择**
为了评估模型的性能,我们使用均方根误差(RMSE)作为评价指标。我们使用交叉验证法来选择正则化参数C。
```python
from sklearn.model_selection import cross_val_score
# 交叉验证选择正则化参数C
C_values = np.logspace(-3, 3, 10)
scores = []
for C in C_values:
model = LinearRegression(fit_intercept=False, penalty='l1', C=C)
scores.append(np.mean(cross_val_score(model, X_train, y_train, cv=5, scoring='neg_mean_squared_error')))
# 选择最佳正则化参数
C_opt = C_values[np.argmin(scores)]
# 使用最佳正则化参数重新训练模型
model = LinearRegression(fit_intercept=False, penalty='l1', C=C_opt)
model.fit(X_train, y_train)
```
**4.2 案例:使用L2正则化提高模型稳定性**
**4.2.1 数据准备和模型训练**
为了演示L2正则化提高模型稳定性的效果,我们使用了一个真实世界的数据集,该数据集包含500个房屋销售记录,每个记录有10个特征。我们使用多元线性回归模型对该数据集进行拟合,并使用L2正则化来提高模型的稳定性。
```python
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
# 加载房屋销售数据集
data = pd.read_csv('housing.csv')
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(data.drop('price', axis=1), data['price'], test_size=0.2)
# 使用L2正则化拟合多元线性回归模型
model = LinearRegression(fit_intercept=False, penalty='l2', C=0.1)
model.fit(X_train, y_train)
```
**4.2.2 模型评估和正则化参数选择**
为了评估模型的性能,我们使用均方根误差(RMSE)作为评价指标。我们使用交叉验证法来选择正则化参数C。
```python
from sklearn.model_selection import cross_val_score
# 交叉验证选择正则化参数C
C_values = np.logspace(-3, 3, 10)
scores = []
for C in C_values:
model = LinearRegression(fit_intercept=False, penalty='l2', C=C)
scores.append(np.mean(cross_val_score(model, X_train, y_train, cv=5, scoring='neg_mean_squared_error')))
# 选择最佳正则化参数
C_opt = C_values[np.argmin(scores)]
# 使用最佳正则化参数重新训练模型
model = LinearRegression(fit_intercept=False, penalty='l2', C=C_opt)
model.fit(X_train, y_train)
```
# 5. 正则化方法的理论基础
### 5.1 偏差-方差权衡
#### 5.1.1 过拟合和欠拟合的解释
在机器学习中,过拟合和欠拟合是两个常见的现象。过拟合是指模型在训练集上表现良好,但在测试集上表现不佳。欠拟合是指模型在训练集和测试集上都表现不佳。
过拟合通常是由模型过于复杂造成的,它会捕捉到训练集中的一些随机噪声或异常值。欠拟合通常是由模型过于简单造成的,它无法捕捉到训练集中数据的复杂性。
#### 5.1.2 正则化的作用
正则化是一种通过在损失函数中添加一个正则化项来解决过拟合的技术。正则化项惩罚模型的复杂性,从而迫使模型找到一个更简单的解决方案。
正则化项的大小由正则化参数λ控制。λ越大,正则化项的惩罚越大,模型越简单。λ越小,正则化项的惩罚越小,模型越复杂。
### 5.2 贝叶斯统计中的正则化
#### 5.2.1 先验分布和后验分布
在贝叶斯统计中,先验分布表示在观察任何数据之前对模型参数的信念。后验分布表示在观察数据之后对模型参数的信念。
#### 5.2.2 正则化作为先验分布
正则化项可以被视为先验分布的一部分。它将模型参数的先验分布从一个均匀分布转换为一个更集中在零附近的分布。
这使得模型更倾向于选择更简单的解决方案,从而减少过拟合的风险。
# 6. 正则化方法的扩展**
**6.1 组LASSO**
**6.1.1 组LASSO的原理**
组LASSO(Group LASSO)是一种正则化方法,它对变量组而不是单个变量进行惩罚。它通过向损失函数中添加一个惩罚项来实现,该惩罚项是变量组中所有变量绝对值之和的范数。
```python
import numpy as np
from sklearn.linear_model import GroupLasso
# 定义变量组
groups = np.array([[0, 1], [2, 3]])
# 创建 GroupLasso 模型
model = GroupLasso(alpha=0.1, groups=groups)
# 训练模型
model.fit(X, y)
```
**6.1.2 组LASSO的应用场景**
组LASSO适用于以下场景:
* 当变量之间具有相关性时,例如同一组中的变量代表同一特征的不同方面。
* 当希望同时选择或剔除一组变量时,例如当变量组代表一个功能模块或类别时。
**6.2 多任务学习中的正则化**
**6.2.1 多任务学习的原理**
多任务学习是一种机器学习方法,它同时学习多个相关的任务。它假设不同任务共享一些底层结构,因此可以从共同学习中受益。
**6.2.2 正则化在多任务学习中的应用**
正则化在多任务学习中可以发挥以下作用:
* 促进任务之间的知识共享,从而提高模型的泛化性能。
* 防止过拟合,因为正则化会惩罚模型中复杂度过高的特征。
* 提高模型的鲁棒性,使其对数据中的噪声和异常值不那么敏感。

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏简介
本专栏深入探究多元线性回归,涵盖从特征工程到模型优化的各个方面。通过揭秘变量选择秘籍、评估技巧、正则化策略、协线性诊断、异常值处理、交叉验证、多重共线性处理、变量转换、模型选择、残差分析、非线性关系处理、数据标准化、交互作用探索、主成分分析、岭回归、偏最小二乘回归、支持向量回归、神经网络应用和空间分析,专栏提供全面的指南,帮助读者掌握多元线性回归的精髓。无论您是初学者还是经验丰富的从业者,本专栏都能为您提供宝贵的见解和实用的技巧,助您提升模型性能,解决现实世界中的问题。
专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
PyroSiM中文版模拟效率革命:8个实用技巧助你提升精确度与效率
# 摘要
PyroSiM是一款强大的模拟软件,广泛应用于多个领域以解决复杂问题。本文从PyroSiM中文版的基础入门讲起,逐渐深入至模拟理论、技巧、实践应用以及高级技巧与进阶应用。通过对模拟理论与效率提升、模拟模型精确度分析以及实践案例的探讨,本文旨在为用户提供一套完整的PyroSiM使用指南。文章还关注了提高模拟效率的实践操作,包括优化技巧和模拟工作流的集成。高级
QT框架下的网络编程:从基础到高级,技术提升必读
# 摘要
QT框架下的网络编程技术为开发者提供了强大的网络通信能力,使得在网络应用开发过程中,可以灵活地实现各种网络协议和数据交换功能。本文介绍了QT网络编程的基础知识,包括QTcpSocket和QUdpSocket类的基本使用,以及QNetworkAccessManager在不同场景下的网络访问管理。进一步地,本文探讨了QT网络编程中的信号与槽
优化信号处理流程:【高效傅里叶变换实现】的算法与代码实践

# 摘要
傅里叶变换是现代信号处理中的基础理论,其高效的实现——快速傅里叶变换(FFT)算法,极大地推动了数字信号处理技术的发展。本文首先介绍了傅里叶变换的基础理论和离散傅里叶变换(DFT)的基本概念及其计算复杂度。随后,详细阐述了FFT算法的发展历程,特别是Coo
MTK-ATA核心算法深度揭秘:全面解析ATA协议运作机制

# 摘要
本文深入探讨了MTK-ATA核心算法的理论基础、实践应用、高级特性以及问题诊断与解决方法。首先,本文介绍了ATA协议和MTK芯片架构之间的关系,并解析了ATA协议的核心概念,包括其命令集和数据传输机制。其次,文章阐述了MTK-ATA算法的工作原理、实现框架、调试与优化以及扩展与改进措施。此外,本文还分析了MTK-ATA算法在多
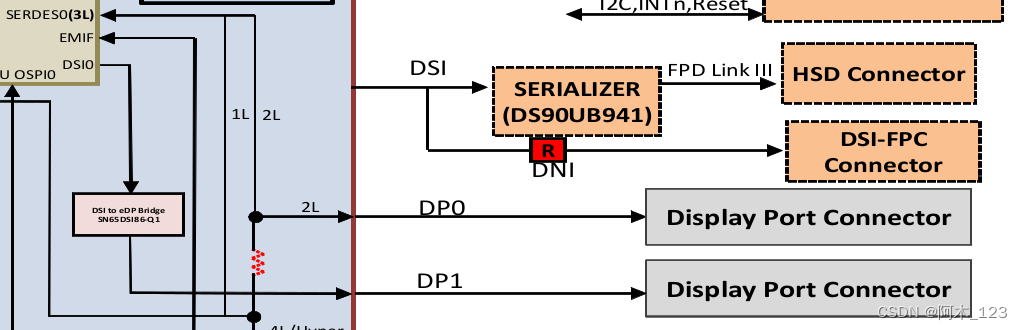
【MIPI摄像头与显示优化】:掌握CSI与DSI技术应用的关键
# 摘要
本文全面介绍了MIPI摄像头与显示技术,从基本概念到实际应用进行了详细阐述。首先,文章概览了MIPI摄像头与显示技术的基础知识,并对比分析了CSI与DSI标准的架构、技术要求及适用场景。接着,文章探讨了MIPI摄像头接口的配置、控制、图像处理与压缩技术,并提供了高级应用案例。对于MIPI显示接口部分,文章聚焦于配置、性能调优、视频输出与图形加速技术以及应用案例。第五章对性能测试工具与
揭秘PCtoLCD2002:如何利用其独特算法优化LCD显示性能

# 摘要
PCtoLCD2002作为一种高性能显示优化工具,在现代显示技术中占据重要地位。本文首先概述了PCtoLCD2002的基本概念及其显示性能的重要性,随后深入解析了其核心算法,包括理论基础、数据处理机制及性能分析。通过对算法的全面解析,探讨了算法如何在不同的显示设备上实现性能优化,并通过实验与案例研究展示了算法优化的实际效果。文章最后探讨了PCtoLCD2002算法的进阶应用和面临
DSP系统设计实战:TI 28X系列在嵌入式系统中的应用(系统优化全攻略)
# 摘要
TI 28X系列DSP系统作为一种高性能数字信号处理平台,广泛应用于音频、图像和通信等领域。本文旨在提供TI 28X系列DSP的系统概述、核心架构和性能分析,探讨软件开发基础、优化技术和实战应用案例。通过深入解析DSP系统的设计特点、性能指标、软件开发环境以及优化策略,本文旨在指导工程师有效地利用DSP系统的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )