Python Interpreter Configuration Guide: Selecting and Configuring the Best Interpreter in PyCharm
发布时间: 2024-09-14 21:39:15 阅读量: 55 订阅数: 33 
# 1. An Overview of the Python Interpreter
The Python interpreter is the core component of the Python programming language, responsible for executing Python code. It translates source code into bytecode, which is then run by the virtual machine. The interpreter provides the fundamental features of the Python language, including variables, data types, control flow, and functions.
The interpreter can also be extended through modules and packages, allowing users to access a variety of libraries and tools. These libraries offer a wealth of functionality, ranging from data processing and machine learning to networking and GUI development. Understanding the capabilities of the Python interpreter is crucial for effectively utilizing the Python language.
# 2. Configuring the Python Interpreter in PyCharm
### 2.1 Selecting a Python Interpreter
In PyCharm, you can choose to use a local interpreter or an interpreter within a virtual environment.
**2.1.1 Local Interpreter**
A local interpreter is a Python interpreter installed on your computer. PyCharm automatically detects interpreters installed on your system.
**2.1.2 Virtual Environment**
A virtual environment is an isolated Python environment, separate from other interpreters on your system. This helps manage different project dependencies and prevents conflicts.
### 2.2 Configuring Interpreter Settings
**2.2.1 Interpreter Path**
Ensure that the correct interpreter path is configured in PyCharm. You can do this by following these steps:
1. Open PyCharm.
2. Go to "File" > "Settings" > "Project" > "Python Interpreter".
3. Select the interpreter you wish to use.
**2.2.2 Environment Variables**
Environment variables are used to define the interpreter path and dependencies. You can configure environment variables by following these steps:
1. Open PyCharm.
2. Go to "File" > "Settings" > "Project" > "Python Interpreter".
3. Click on the "Environment Variables" tab.
4. Add or modify environment variables.
**2.2.3 Project Interpreter**
You can specify a particular interpreter for each project. This allows you to use different Python versions or virtual environments in different projects.
1. Open PyCharm.
2. Open the project you wish to configure.
3. Go to "File" > "Settings" > "Project" > "Python Interpreter".
4. Select the interpreter you wish to use.
### Code Example: Configuring a Local Interpreter
```python
import sys
# Get the current interpreter path
interpreter_path = sys.executable
# Check if the interpreter path is correct
if interpreter_path != "/usr/bin/python3":
# Update the interpreter path
sys.executable = "/usr/bin/python3"
```
**Code Logic Analysis:**
* Import the `sys` module to access system information.
* Retrieve the current interpreter path and store it in the `interpreter_path` variable.
* Check if `interpreter_path` matches the expected interpreter path.
* If the path is incorrect, use `sys.executable` to update the interpreter path.
### Code Example: Configuring a Virtual Environment
```python
import venv
# Create a virtual environment
venv.create("my_virtual_env")
# Activate the virtual environment
venv.activate("my_virtual_env")
```
**Code Logic Analysis:**
* Import the `venv` module to create and activate virtual environments.
* Use `venv.create()` to create a virtual environment named "my_virtual_env".
* Use `venv.activate()` to activate the virtual environment.
# 3.1 Virtual Environment Management
**3.1.1 Creating and Activating Virtual Environments**
Virtual environments are Python environments independent of the system environment, allowing users to use different Python versions and packages in various projects without affecting others. To create a virtual environment, use the following command:
```python
python -m venv venv_name
```
Where `venv_name` is the name of the virtual environment you wish to create. After creating the virtual environment, activate it using the following command:
```python
source venv_name/bin/activate
```
To exit a virtual environment, use the following command:
```python
deactivate
```
**3.1.2 Managing Virtual Environment Packages**
When installing packages in a virtual environment, they are only installed in that environment and do not affect the system environment. To install a package, use the following command:
```python
pip install package_name
```
To uninstall a package, use the following command:
```python
pip uninstall package_name
```
To view the list of packages installed in a virtual environment, use the following command:
```python
pip list
```
### 3.2 Enhancing Interpreter Performance
**3.2.1 Enabling Multiprocessing**
Multiprocessing allows the Python interpreter to execute tasks using multiple CPU cores simultaneously, which can significantly improve the performance of certain types of applications. To enable multiprocessing, use the following code in your Python script:
```python
import multiprocessing
def worker(num):
print(f"Worker {num} is running")
if __name__ == "__main__":
jobs = []
for i in range(5):
p = multiprocessing.Process(target=worker, args=(i,))
jobs.append(p)
p.start()
```
In the example above, the `worker()` function will run simultaneously in 5 different processes.
**3.2.2 Using a JIT Compiler**
A JIT (Just-In-Time) compiler translates Python bytecode into machine code, thereby increasing the execution speed of the interpreter. To use a JIT compiler, use the following code in your Python script:
```python
import sys
sys.settrace(sys.gettrace() or lambda *args, **kwargs: None)
```
The JIT compiler will automatically enable and compile bytecode when needed.
# 4. Advanced Configuration of the Python Interpreter
### 4.1 Debugging the Interpreter
Debugging the interpreter is essential for finding and fixing errors in your code. PyCharm provides powerful debugging features that allow developers to step through code, inspect variable values, and identify exceptions.
#### 4.1.1 Using the pdb Debugger
pdb (Python Debugger) is a built-in module for interactive debugging. It allows developers to set breakpoints in the code and pause the program during execution.
```python
import pdb
def my_function():
pdb.set_trace() # Set a breakpoint
print("Hello, world!")
my_function()
```
When this code is executed, the program will pause at the `pdb.set_trace()` line. Developers can use pdb commands (such as `n` (next), `s` (step), `l` (list)) to inspect variable values and debug the code.
#### 4.1.2 Remote Debugging
Remote debugging allows developers to debug code on a remote machine. PyCharm supports remote debugging and can connect to a remote interpreter via SSH or a Remote Python Debugger (RPD).
**Using SSH for Remote Debugging**
1. Start an SSH server on the remote machine.
2. In PyCharm, go to "Run" > "Debug Configurations".
3. Create a new Python remote debugging configuration.
4. Enter the IP address of the remote machine in the "Host" field.
5. Enter the SSH port (usually 22) in the "Port" field.
6. Select the remote interpreter in the "Interpreter" field.
**Using RPD for Remote Debugging**
1. Install RPD on the remote machine.
2. In PyCharm, go to "Run" > "Debug Configurations".
3. Create a new Python remote debugging configuration.
4. Enter the IP address of the remote machine in the "Host" field.
5. Enter the RPD port (usually 5678) in the "Port" field.
6. Select the remote interpreter in the "Interpreter" field.
### 4.2 Extending Interpreter Capabilities
Beyond its core capabilities, the Python interpreter can be extended by installing third-party libraries and creating custom interpreters.
#### 4.2.1 Installing Third-Party Libraries
Third-party libraries offer a wide range of functionality, from data analysis to machine learning. Third-party libraries can be installed using the `pip` command.
```
pip install numpy
```
After installation, you can import the library and use its features.
```python
import numpy as np
arr = np.array([1, 2, 3])
print(arr.mean())
```
#### 4.2.2 Creating Custom Interpreters
Developers can create custom interpreters to extend the core functionality of the interpreter. This can be achieved by subclassing the `PathFinder` class within `sys.meta_path`.
```python
class MyPathFinder(sys.meta_path):
def find_module(self, fullname, path=None):
# Custom module lookup logic
# Add the custom path finder to sys.meta_path
sys.meta_path.append(MyPathFinder())
```
By creating a custom interpreter, developers can add new features, such as custom module loading or code optimization.
# 5. Best Practices for the Python Interpreter
### 5.1 Maintaining Interpreter Versions
Keeping the Python interpreter version up-to-date is crucial for ensuring security and functionality.
#### 5.1.1 Updating Python Versions
Regularly check the Python official website for the latest Python version. It is recommended to use package managers like pip or conda to update Python versions.
```
pip install --upgrade pip
pip install --upgrade python
```
#### 5.1.2 Managing Multiple Python Versions
If you need to use multiple Python versions, you can use virtual environments or containers to isolate different environments. Virtual environments allow you to install and manage multiple Python versions on the same system, while containers provide an isolated environment with all necessary dependencies.
### 5.2 Ensuring Interpreter Security
Protecting the Python interpreter from malware and security vulnerabilities is critical.
#### 5.2.1 Avoid Using Unsecure Interpreters
Do not download or install Python interpreters from unofficial sources. Always obtain interpreters from the official website or trusted repositories.
#### 5.2.2 Limiting Interpreter Permissions
Limit the permissions of the Python interpreter to prevent the execution of malicious code. Use tools like setuptools or wheel to create executables with limited permissions.
```
python setup.py build
python setup.py install --user
```
# 6. Frequently Asked Questions About the Python Interpreter
### 6.1 Interpreter Not Found
**Problem Description:**
An "interpreter not found" error occurs when running a Python script in PyCharm.
**Solution:**
**6.1.1 Check Interpreter Path**
* Open the "Settings" menu in PyCharm.
* Under "Project" > "Python Interpreter", check if the path of the selected interpreter is correct.
* If the path is incorrect, click the "Add" button and select the correct interpreter.
**6.1.2 Ensure Environment Variables Are Correct**
* Check if the PATH environment variable in the operating system includes the path to the Python interpreter.
* If not, add the interpreter path, for example:
```
Windows: PATH=%PATH%;C:\Python39
macOS/Linux: export PATH=$PATH:/usr/local/bin/python3.9
```
### 6.2 Incorrect Interpreter Version
**Problem Description:**
The interpreter version displayed in PyCharm does not match the actual installed version.
**Solution:**
**6.2.1 Update PyCharm**
* Check for any available updates for PyCharm.
* If there are any, update PyCharm and restart.
**6.2.2 Reinstall Python**
* Uninstall the currently installed Python version.
* Download and reinstall the desired Python version from the official website.
* Restart PyCharm and reconfigure the interpreter.

 百万级
高质量VIP文章无限畅学
百万级
高质量VIP文章无限畅学
 千万级
优质资源任意下载
千万级
优质资源任意下载
 C知道
免费提问 ( 生成式Al产品 )
C知道
免费提问 ( 生成式Al产品 )
0
0
相关推荐

专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )
最新推荐
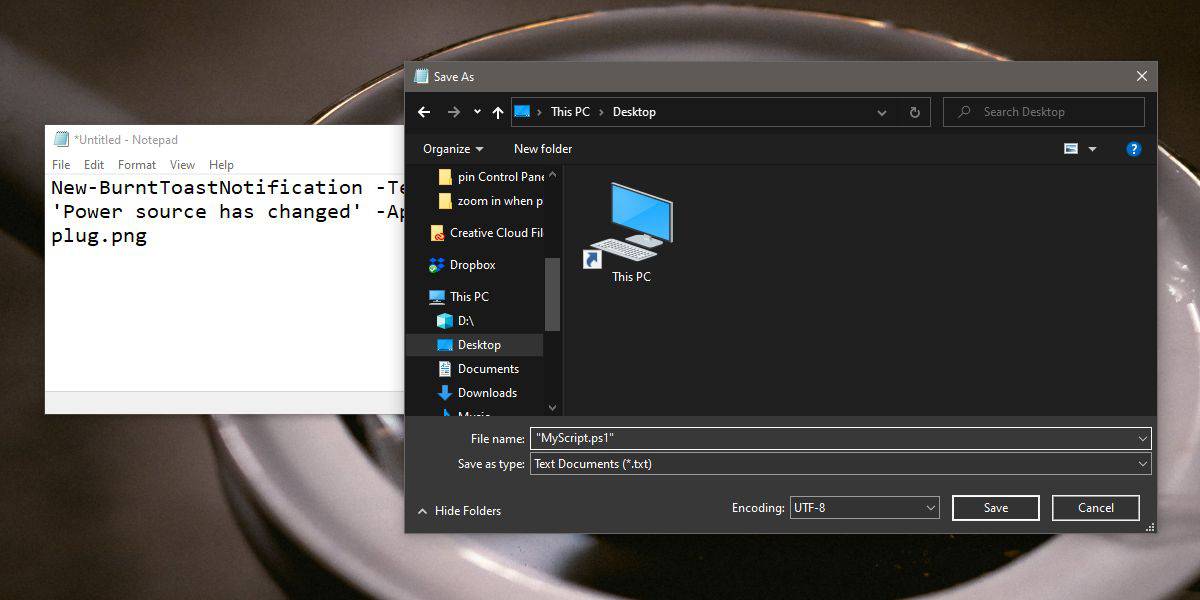
【Python新手必学】:20分钟内彻底解决Scripts文件夹缺失的烦恼!
# 摘要
Python作为一种流行的编程语言,其脚本的编写和环境设置对于初学者和专业开发者都至关重要。本文从基础概念出发,详细介绍了Python脚本的基本结构、环境配置、调试与执行技巧,以及进阶实践和项目实战策略。重点讨论了如何通过模块化、包管理、利用外部库和自动化技术来提升脚本的功能性和效率。通过对Python脚本从入门到应用的系统性讲解,本文
【热传导模拟深度解析】:揭秘板坯连铸温度分布的关键因素

# 摘要
热传导模拟作为理解和优化工业过程中温度分布的重要工具,在板坯连铸等制造技术中起着至关重要的作用。本文首先阐述了热传导模拟的理论基础和板坯连铸过程中的热动力学原理,深入分析了热传导在连铸过程中的关键作用和温度场分布的影响因素。通过数学建模和数值方法的介绍,本文探讨了如何利用现代软件工具进行热传导模拟,并对模拟结果进行了验证和敏感性分析。随后,文章通过具体的模拟案例,展
【Nginx权限与性能】:根目录迁移的正确打开方式,避免安全与性能陷阱

# 摘要
本文深入探讨了Nginx在权限管理、性能优化以及根目录迁移方面的实践与策略。文章首先概述了Nginx权限与性能的重要性,然后详细阐述了权限管理的基础知识、性能优化的关键参数以及根目录迁移的技术细节。重点介绍了如何通过合理配置用户和组、文件权限,调整工作进程和连接数以及利用缓存机
RJ-CMS内容发布自动化:编辑生产力提升30%的秘诀

# 摘要
本文全面介绍了RJ-CMS内容管理系统,从内容发布流程的理论基础到自动化实践和操作技巧,详细解析了RJ-CMS的自动化功能以及如何提升内容发布的效率和安全性。文中详细阐述了自动化在内容发布中的重要性,包括自动化特性、框架的扩展性、工作流的优化、安全风险的预防策略。此外,本文还探讨了RJ-CMS与外部系统的集成策略、扩展模块的开发以及其在内容发布自动化方面的效果评估,
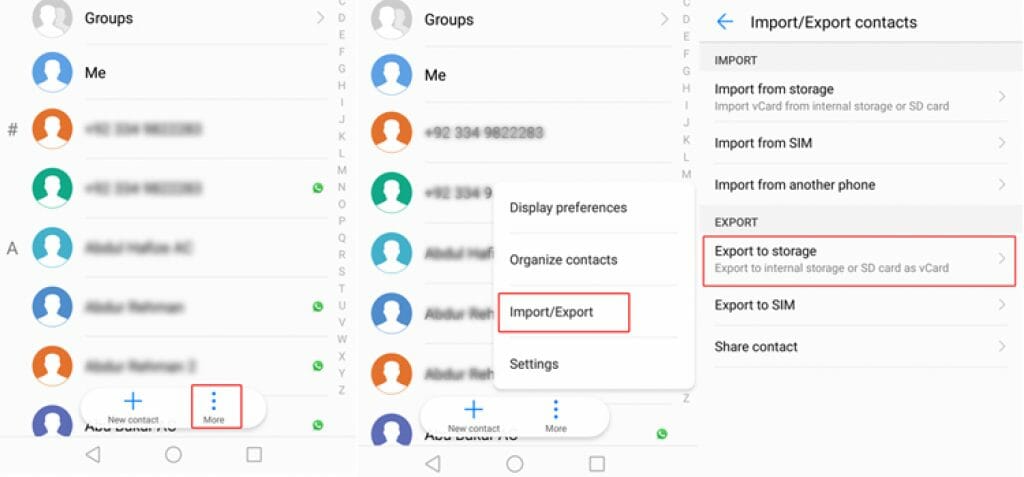
【通讯录备份系统构建秘籍】:一步到位打造高效备份解决方案
# 摘要
随着通讯录数据量的不断增长和对数据安全性的高要求,构建一个可靠且高效的通讯录备份系统变得尤为重要。本文首先概述了通讯录备份系统构建的必要性和基本框架,然后深入分析了通讯录数据的结构,并探讨了备份系统设计的基本原则,包括系统可靠性和数据一致性保证机制。接着,本文详细介绍了实践操作流程,包括环境搭建、功能模块的开发与集成以及系统的测试与部署。最后,本文着重讨
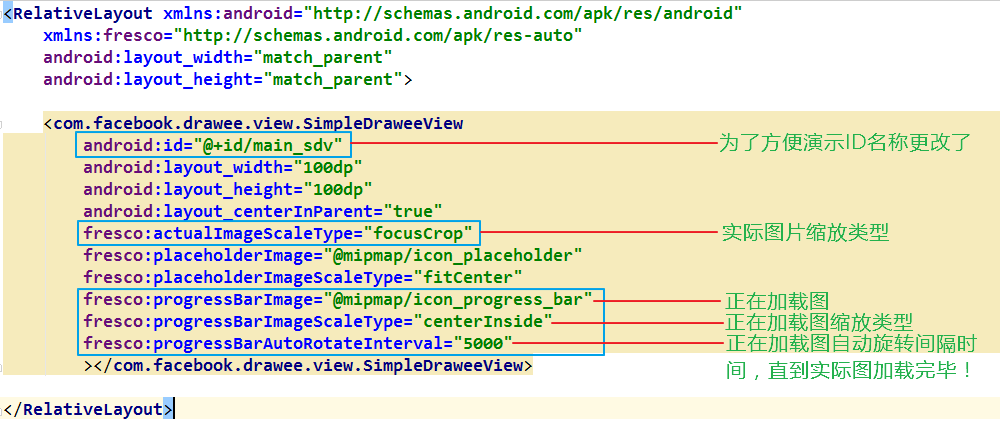
【Android图形绘制秘籍】:5大技巧高效实现公交路线自定义View
# 摘要
本文全面探讨了Android平台下图形绘制技术的核心概念、自定义View的创建和优化,以及针对公交路线自定义View的理论与实践应用。文章首先介绍了图形绘制的基础知识,包括View的工作原理和创建流程。接着深入讲解了性能优化的关键技巧,如渲染优化原则和绘图缓存技术。然后,文章详细阐述了公交路线图的绘制原理、方法和动态交互实现,提供了高效实现公交路线自定义View的五个技巧。最后,通过案例分析与应用拓展,讨论了公交路线图绘制的实践案例和集成公交站点选择器的方法
餐饮管理系统后端深度剖析:高效数据处理技巧

# 摘要
随着信息技术的发展,餐饮管理系统的后端设计与实施越来越复杂,本文系统性地分析了餐饮管理系统后端设计中的高效数据处理、实践技巧、高级数据处理技术以及安全与维护策略。文章首先介绍了餐饮管理系统后端的基本概念和数据处理理论基础,重点讨论了数据结构和算法的选择与优化,数据库查询优化
【Proteus仿真高级技术】:实现高效汉字滚动显示的关键(专家版解析)

# 摘要
本论文详细探讨了在Proteus仿真环境中实现汉字滚动显示的技术。首先从基础理论出发,涵盖了汉字显示原理、点阵字模生成、Proteus仿真环境搭建及滚动技术理论分析。随后,通过对基础实践和进阶技巧的操作,包括7段显示器应用、字模提取、动态更新和多级缓冲区策略,深入讲解了汉字滚动显示的实践操作。高级技术章节分析了自适应滚动速度算法、面向对象的仿真建模方法以及硬件
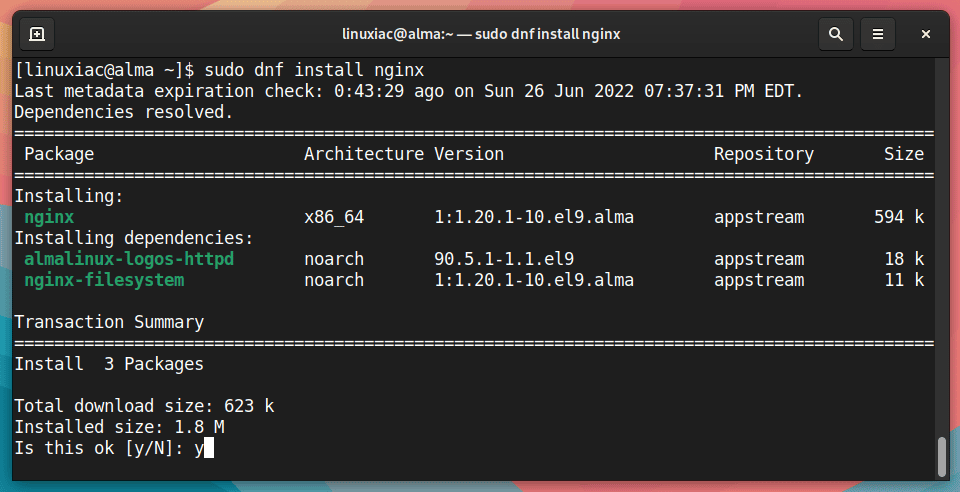
【Nginx虚拟主机部署秘籍】:实现一机多站的不二法门
# 摘要
Nginx作为高性能的HTTP和反向代理服务器,在虚拟主机配置方面提供了灵活多样的选项。本文全面介绍了Nginx虚拟主机的配置技巧,包括基于域名、端口和IP的虚拟主机配置方法,着重分析了各种配置的细节和性能考量。同时,文章还探讨了SSL/TLS的应用、URL重写规则的使用以及高级安全配置,以增强虚拟主
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


专栏目录
最低0.47元/天 解锁专栏
买1年送3月
百万级
高质量VIP文章无限畅学
千万级
优质资源任意下载
C知道
免费提问 ( 生成式Al产品 )